BeatLearning
1.0.0
Have you ever wanted to play a song that wasn't available in your favorite rhythm game? Have you ever wanted to play infinite variations of that song?
This Open Source research project aims to democratize the process of automatic beatmap creation, offering accessible tools and foundation models for game developers, players and enthusiasts alike, paving the way for a new era of creativity and innovation in rhythm gaming.
Examples (more coming soon):
You will first need to install Python 3.12, go to the repository's directory and create a virtual environment via:
python3 -m venv venv
Then call source venv/bin/activate or venvScriptsactivate if you are on a Windows machine.
After the virtual environment has been activated, you can install the required libraries via:
pip3 install -r requirements.txt
You can use Jupyter to access the example notebooks/:
jupyter notebook
You can try the Google Collab version too, as long as you have GPU instances available (the default CPU ones take forever to convert a song).
The pipeline only supports OSU beatmaps at the moment.
This repository is still a WORK IN PROGRESS. The goal is to develop generative models capable of automatically producing beatmaps for a diverse array of rhythm games, regardless of the song. This research is still ongoing, but the aim is to get MVPs out as fast as possible.
All contributions are valued, especially in the form of compute donations for training foundation models. So, if you're interested, feel free to pitch in!
Join us in exploring the endless possibilities of AI-driven beatmap generation and shaping the future of rhythm games!
Model(s) are available on HuggingFace.
Rhythm game beatmaps are initially converted into an intermediate file format, which is then tokenized into 100ms chunks. Each token is capable of encoding up to two different events within this time period (holds and / or hits) quantized to 10ms accuracy. The vocabulary of the tokenizer is precalculated rather than learned from the data to meet this criterion. The context length and vocabulary size are intentionally kept small due to the scarcity of quality training examples in the field.
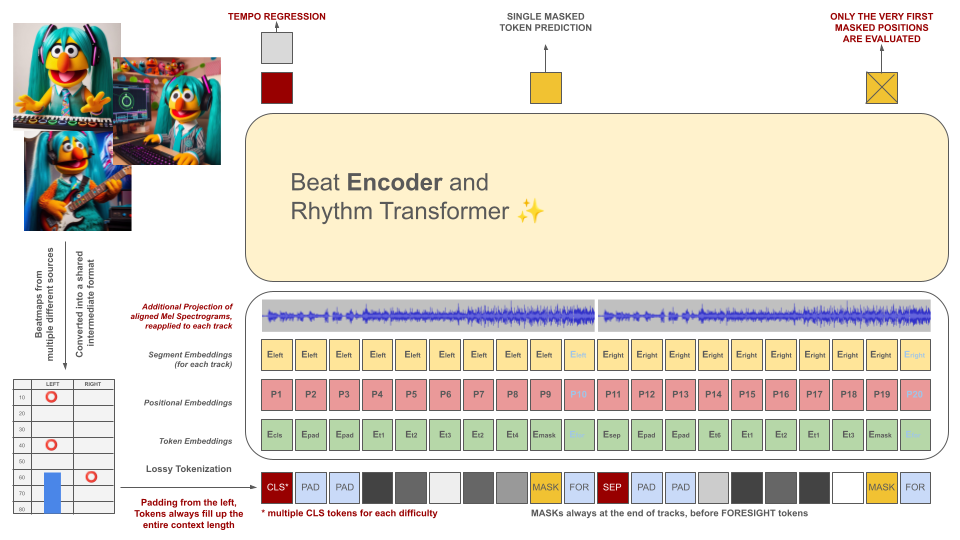 These tokens, along with slices of the audio data (its projected Mel Spectogram aligned with the tokens), serve as inputs for a masked encoder model. Similar to BeRT, the encoder model has two objectives during training: estimating the tempo through a regression task and predicting the masked (next) token(s) via a hearing loss function.
Beatmaps with 1, 2, and 4 tracks are supported. Each token is predicted from left to right, mirroring the generation process of a decoder architecture. However, the masked tokens also have access to additional audio information from the future, denoted as foresight tokens from the right.
These tokens, along with slices of the audio data (its projected Mel Spectogram aligned with the tokens), serve as inputs for a masked encoder model. Similar to BeRT, the encoder model has two objectives during training: estimating the tempo through a regression task and predicting the masked (next) token(s) via a hearing loss function.
Beatmaps with 1, 2, and 4 tracks are supported. Each token is predicted from left to right, mirroring the generation process of a decoder architecture. However, the masked tokens also have access to additional audio information from the future, denoted as foresight tokens from the right.
The AI model's purpose is not to devalue individually crafted beatmaps, but rather:
All generated content must comply with EU regulations and be appropriately labeled, including metadata indicating the involvement of the AI model.
GENERATION OF BEATMAPS FOR COPYRIGHTED MATERIAL IS STRICTLY PROHIBITED! ONLY USE SONGS FOR WHICH YOU POSSESS RIGHTS!
The audio featured in OSU file examples originates from artists listed on the OSU website under the section featured artists and is licensed for use specifically in osu!-related content.
To prevent your beatmap from being utilized as training data in the future, include the following metadata in your beatmap file:
robots: disallow
The project draws inspiration from a previous attempt known as AIOSU.
Besides relying on the OSU's wiki, osu-parser has been instrumental in clarifying beatmap declarations (especially sliders). The transformer model was influenced by NanoGPT and from the pytorch implementation of BeRT.


