GenerativeRL
v0.0.1
English | 简体中文(Simplified Chinese)
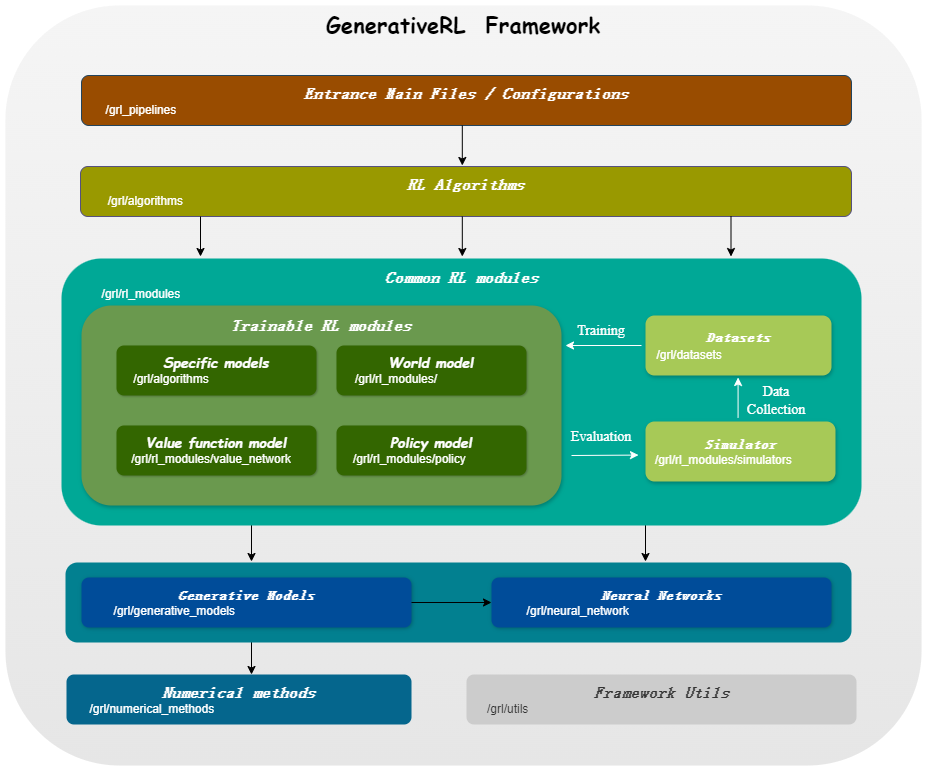
GenerativeRL, short for Generative Reinforcement Learning, is a Python library for solving reinforcement learning (RL) problems using generative models, such as diffusion models and flow models. This library aims to provide a framework for combining the power of generative models with the decision-making capabilities of reinforcement learning algorithms.
| Score Matching | Flow Matching | |
|---|---|---|
| Diffusion Model | ||
| Linear VP SDE | ✔ | ✔ |
| Generalized VP SDE | ✔ | ✔ |
| Linear SDE | ✔ | ✔ |
| Flow Model | ||
| Independent Conditional Flow Matching | ✔ | |
| Optimal Transport Conditional Flow Matching | ✔ |
| Algo./Models | Diffusion Model | Flow Model |
|---|---|---|
| IDQL | ✔ | |
| QGPO | ✔ | |
| SRPO | ✔ | |
| GMPO | ✔ | ✔ |
| GMPG | ✔ | ✔ |
pip install GenerativeRLOr, if you want to install from source:
git clone https://github.com/opendilab/GenerativeRL.git
cd GenerativeRL
pip install -e .Or you can use the docker image:
docker pull opendilab/grl:torch2.3.0-cuda12.1-cudnn8-runtime
docker run -it --rm --gpus all opendilab/grl:torch2.3.0-cuda12.1-cudnn8-runtime /bin/bashHere is an example of how to train a diffusion model for Q-guided policy optimization (QGPO) in the LunarLanderContinuous-v2 environment using GenerativeRL.
Install the required dependencies:
pip install 'gym[box2d]==0.23.1'(The gym version can be from 0.23 to 0.25 for box2d environments, but it is recommended to use 0.23.1 for compatibility with D4RL.)
Download dataset from here and save it as data.npz in the current directory.
GenerativeRL uses WandB for logging. It will ask you to log in to your account when you use it. You can disable it by running:
wandb offlineimport gym
from grl.algorithms.qgpo import QGPOAlgorithm
from grl.datasets import QGPOCustomizedTensorDictDataset
from grl.utils.log import log
from grl_pipelines.diffusion_model.configurations.lunarlander_continuous_qgpo import config
def qgpo_pipeline(config):
qgpo = QGPOAlgorithm(config, dataset=QGPOCustomizedTensorDictDataset(numpy_data_path="./data.npz", action_augment_num=config.train.parameter.action_augment_num))
qgpo.train()
agent = qgpo.deploy()
env = gym.make(config.deploy.env.env_id)
observation = env.reset()
for _ in range(config.deploy.num_deploy_steps):
env.render()
observation, reward, done, _ = env.step(agent.act(observation))
if __name__ == '__main__':
log.info("config: n{}".format(config))
qgpo_pipeline(config)For more detailed examples and documentation, please refer to the GenerativeRL documentation.
The full documentation for GenerativeRL can be found at GenerativeRL Documentation.
We provide several case tutorials to help you better understand GenerativeRL. See more at tutorials.
We offer some baseline experiments to evaluate the performance of generative reinforcement learning algorithms. See more at benchmark.
We welcome contributions to GenerativeRL! If you are interested in contributing, please refer to the Contributing Guide.
@misc{generative_rl,
title={GenerativeRL: A Python Library for Solving Reinforcement Learning Problems Using Generative Models},
author={Zhang, Jinouwen and Xue, Rongkun and Niu, Yazhe and Chen, Yun and Chen, Xinyan and Wang, Ruiheng and Liu, Yu},
publisher={GitHub},
howpublished={url{https://github.com/opendilab/GenerativeRL}},
year={2024},
}GenerativeRL is licensed under the Apache License 2.0. See LICENSE for more details.


