stellar metrics
1.0.0
Code for our paper: Stellar: Systematic Evaluation of Human-Centric Personalized Text-to-Image Methods
Authors: Panos Achlioptas, Alexandros Benetatos, Iordanis Fostiropoulos, Dimitris Skourtis
The codebase is maintained by Iordanis Fostiropoulos. For any questions please reach out.
Before downloading or using any part of the code in this repository, please review and acknowledge the terms and conditions set forth in both the "License Terms" and "Third Party License Terms" included in this repository. Continuing to download and use any part of the code in this repository confirms you agree with these terms and conditions.
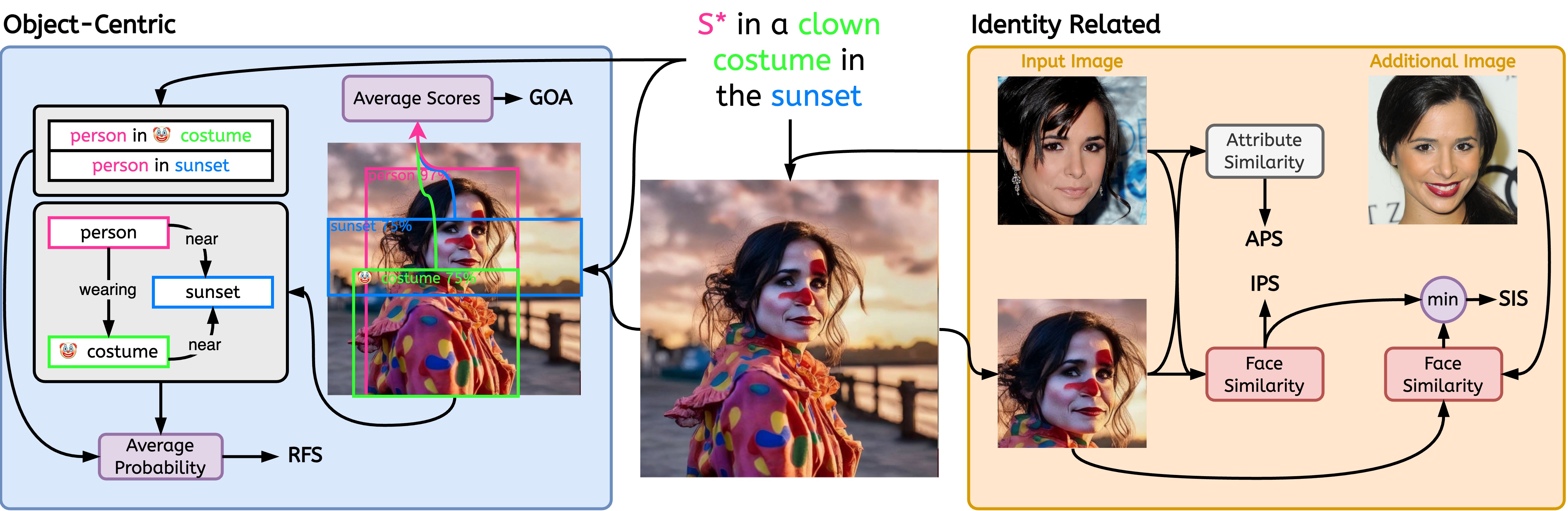 Note: "Input Image" and "Additional Image" shown are found in CELEBMaksHQ dataset.
Note: "Input Image" and "Additional Image" shown are found in CELEBMaksHQ dataset.
This work is based on our technical manuscript Stellar: Systematic Evaluation of Human-Centric Personalized Text-to-Image Methods. We proposed 5 metrics for evaluating human-centric personalization Text-2-Image models. The repository provides the implementation of 8 additional baseline metrics for Text-2-Image and Image-2-Image methods.
There are several metrics provided from literature. We denote with the ones that are introduced by our work.
We provide our own implementation of existing metrics and refer the user to their paper for the technical details of their work.
| Name | Evaluation Type | Code Name | Reference |
|---|---|---|---|
| Aesth. | Image2Image | aesth |
Link |
| Image2Image | clip |
Link | |
| DreamSim | Image2Image | dreamsim |
Link |
| Text2Image | clip |
Link | |
| HPSv1 | Text2Image | hps |
Link |
| HPSv2 | Text2Image | hps |
Link |
| ImageReward | Text2Image | im_reward |
Link |
| PickScore | Text2Image | pick |
Link |
| APS | Personalized Text2Image | aps |
Link |
| GoA | Object-centric | goa |
Link |
| IPS | Personalized Text2Image | ips |
Link |
|
|
Relation-centric | rfs |
Link |
| SIS | Personalized Text2Image | sis |
Link |
pip install git+https://github.com/stellar-gen-ai/stellar-metrics.gitWe want to compute the metric for each individual image. As such it can help diagnose the failure cases of a method.
$ python -m stellar_metrics --metric code_name --stellar-path ./stellar-dataset --syn-path ./model-output --save-dir ./save-dirOptional you can specify --device, --batch-size and --clip-version for the backbone
NOTE there must be one-to-one correspondance between model-output and stellar-dataset. The stellar-dataset is used to calculate some of the metrics, such as identity preservation where the original image is required. Misconfiguration between syn-path and stellar-path can lead to incorrect results.
Calculate IPS
$ python -m stellar_metrics --metric ips --stellar-path ./tests/assets/mock_stellar_dataset --syn-path ./tests/assets/stellar_net --save-dir ./save-dirCalculate CLIP
$ python -m stellar_metrics --metric clip --stellar-path ./tests/assets/mock_stellar_dataset --syn-path ./tests/assets/stellar_net --save-dir ./save-dir$ python -m stellar_metrics.analysis --save-dir ./save-dirAssess the facial resemblance between the input identity and the generated images in a rather coarse but specialized way. Our metric uses a face detector to isolate the identity's face in both input and generated images. It then employs a specialized face detection model to extract facial representation embeddings from the detected regions.
Assess how well the generated images maintain specific fine-grained attributes of the identity in question, such as age, gender, and other invariant facial features (e.g.,~high cheekbones). Leveraging the annotations in Stellar images, we can evaluate these binary facial characteristics.
Serves as a measure for determining the extent of a model's sensitivity to different images of the same individual; further promoting models where the subject's identity is consistently well-captured irrespective of the input's image irrelevant variations (e.g., lighting conditions, subject's pose).
To achieve this goal, SIS necessitates having access to multiple images of the human subject (a condition met in Stellar's dataset by design); and is our only evaluation metric with such a more demanding requirement.
We introduce specialized and interpretable metrics to evaluate two key aspects of the alignment between image and prompt; object representation faithfulness and the fidelity of depicted relationships.
Evaluate the success of representing the desired prompt object-interactions on the generated image. Considering the difficulty of even specialized Scene Graph Generation (SGG) models to understand visual relations, this metric introduces a valuable localized insight into the ability of the personalized model to faithfully depict the prompted relations.


