LLM4Decompile
1.0.0
![]()
Results
| ? Models
| Quick Start
| HumanEval-Decompile
| ? Citation
| Paper
| Colab
|
Reverse Engineering: Decompiling Binary Code with Large Language Models
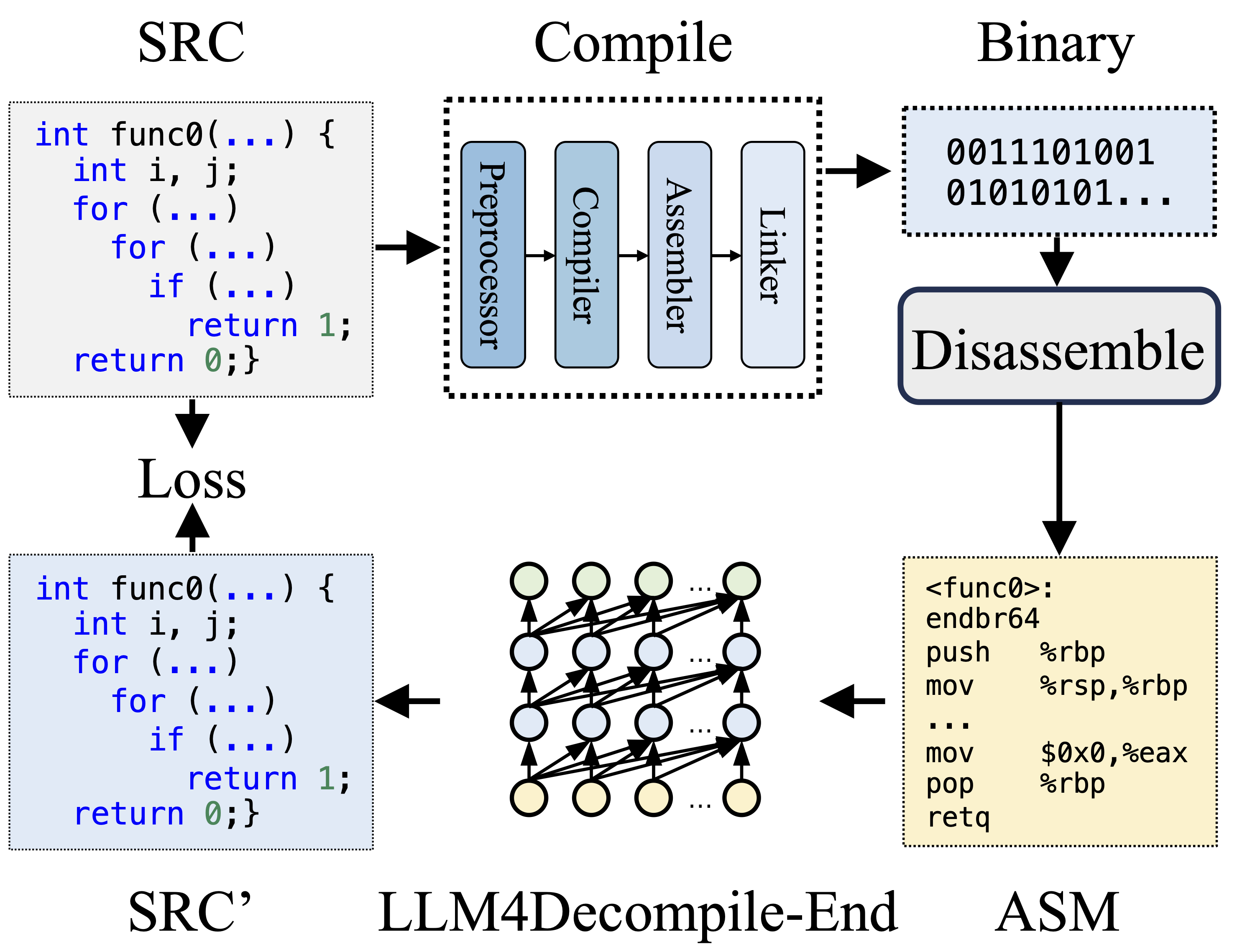
During compilation, the Preprocessor processes the source code (SRC) to eliminate comments and expand macros or includes. The cleaned code is then forwarded to the Compiler, which converts it into assembly code (ASM). This ASM is transformed into binary code (0s and 1s) by the Assembler. The Linker finalizes the process by linking function calls to create an executable file. Decompilation, on the other hand, involves converting binary code back into a source file. LLMs, being trained on text, lack the ability to process binary data directly. Therefore, binaries must be disassembled by Objdump into assembly language (ASM) first. It should be noted that binary and disassembled ASM are equivalent, they can be interconverted, and thus we refer to them interchangeably. Finally, the loss is computed between the decompiled code and source code to guide the training. To assess the quality of the decompiled code (SRC'), it is tested for its functionality through test assertions (re-executability).
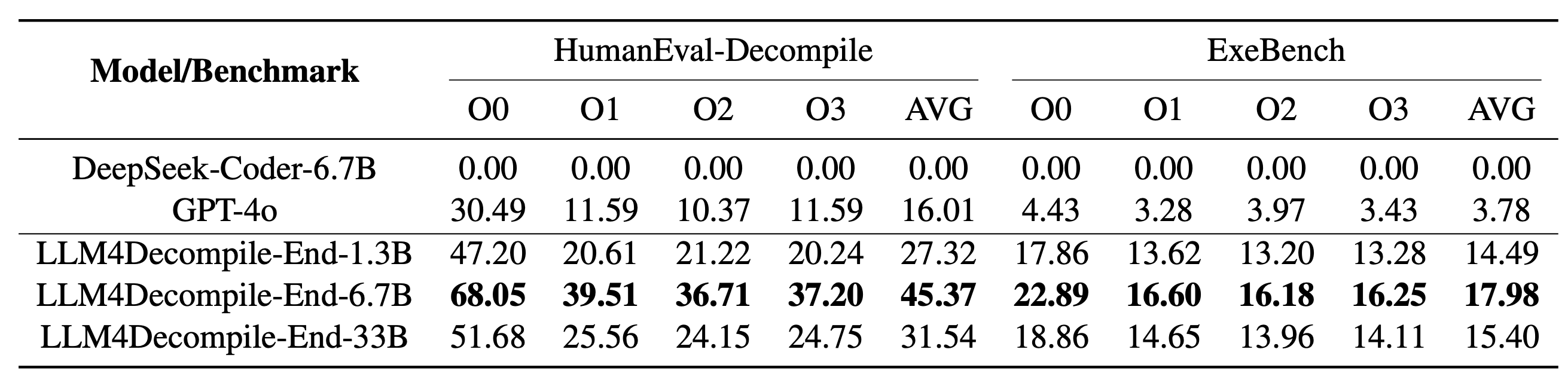
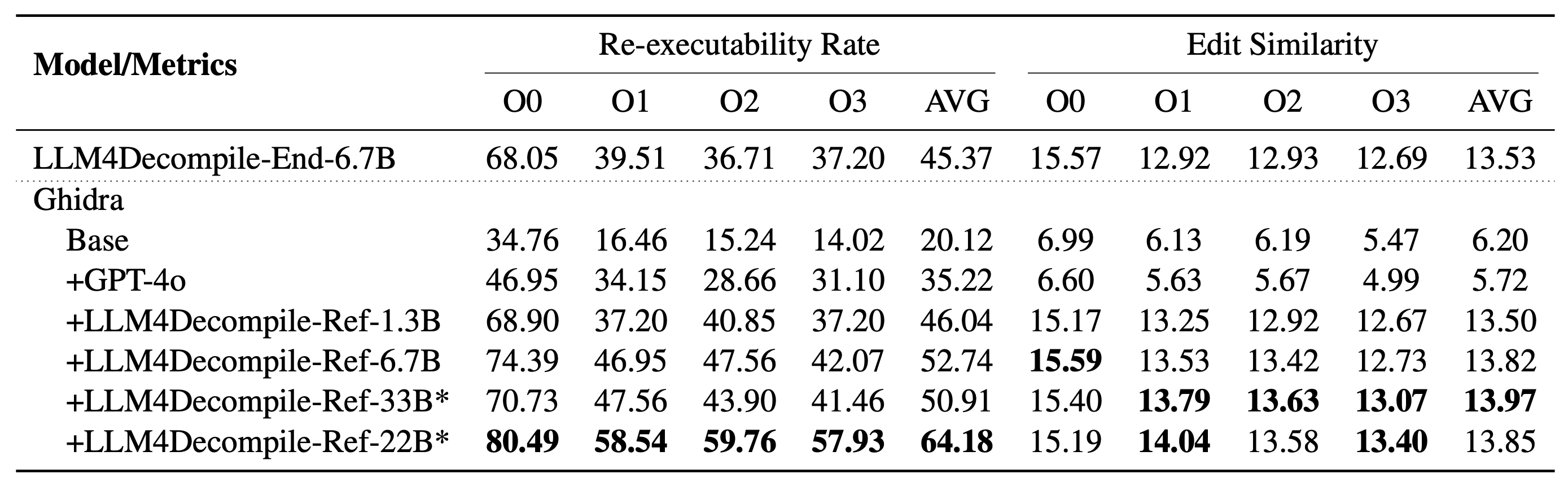
Our LLM4Decompile includes models with sizes between 1.3 billion and 33 billion parameters, and we have made these models available on Hugging Face.
| Model | Checkpoint | Size | Re-executability | Note |
|---|---|---|---|---|
| llm4decompile-1.3b-v1.5 | ? HF Link | 1.3B | 27.3% | Note 3 |
| llm4decompile-6.7b-v1.5 | ? HF Link | 6.7B | 45.4% | Note 3 |
| llm4decompile-1.3b-v2 | ? HF Link | 1.3B | 46.0% | Note 4 |
| llm4decompile-6.7b-v2 | ? HF Link | 6.7B | 52.7% | Note 4 |
| llm4decompile-9b-v2 | ? HF Link | 9B | 64.9% | Note 4 |
| llm4decompile-22b-v2 | ? HF Link | 22B | 63.6% | Note 4 |
Note 3: V1.5 series are trained with a larger dataset (15B tokens) and a maximum token size of 4,096, with remarkable performance (over 100% improvement) compared to the previous model.
Note 4: V2 series are built upon Ghidra and trained on 2 billion tokens to refine the decompiled pseudo-code from Ghidra. Check ghidra folder for details.
Setup: Please use the script below to install the necessary environment.
git clone https://github.com/albertan017/LLM4Decompile.git
cd LLM4Decompile
conda create -n 'llm4decompile' python=3.9 -y
conda activate llm4decompile
pip install -r requirements.txt
Here is an example of how to use our model (Revised for V1.5. For previous models, please check the corresponding model page at HF). Note: Replace the "func0" with the function name you want to decompile.
Preprocessing: Compile the C code into binary, and disassemble the binary into assembly instructions.
import subprocess
import os
func_name = 'func0'
OPT = ["O0", "O1", "O2", "O3"]
fileName = 'samples/sample' #'path/to/file'
for opt_state in OPT:
output_file = fileName +'_' + opt_state
input_file = fileName+'.c'
compile_command = f'gcc -o {output_file}.o {input_file} -{opt_state} -lm'#compile the code with GCC on Linux
subprocess.run(compile_command, shell=True, check=True)
compile_command = f'objdump -d {output_file}.o > {output_file}.s'#disassemble the binary file into assembly instructions
subprocess.run(compile_command, shell=True, check=True)
input_asm = ''
with open(output_file+'.s') as f:#asm file
asm= f.read()
if '<'+func_name+'>:' not in asm: #IMPORTANT replace func0 with the function name
raise ValueError("compile fails")
asm = '<'+func_name+'>:' + asm.split('<'+func_name+'>:')[-1].split('nn')[0] #IMPORTANT replace func0 with the function name
asm_clean = ""
asm_sp = asm.split("n")
for tmp in asm_sp:
if len(tmp.split("t"))<3 and '00' in tmp:
continue
idx = min(
len(tmp.split("t")) - 1, 2
)
tmp_asm = "t".join(tmp.split("t")[idx:]) # remove the binary code
tmp_asm = tmp_asm.split("#")[0].strip() # remove the comments
asm_clean += tmp_asm + "n"
input_asm = asm_clean.strip()
before = f"# This is the assembly code:n"#prompt
after = "n# What is the source code?n"#prompt
input_asm_prompt = before+input_asm.strip()+after
with open(fileName +'_' + opt_state +'.asm','w',encoding='utf-8') as f:
f.write(input_asm_prompt)Assembly instructions should be in the format:
<FUNCTION_NAME>:nOPERATIONSnOPERATIONSn
Typical assembly instructions may look like this:
<func0>:
endbr64
lea (%rdi,%rsi,1),%eax
retq
Decompilation: Use LLM4Decompile to translate the assembly instructions into C:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_path = 'LLM4Binary/llm4decompile-6.7b-v1.5' # V1.5 Model
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path,torch_dtype=torch.bfloat16).cuda()
with open(fileName +'_' + OPT[0] +'.asm','r') as f:#optimization level O0
asm_func = f.read()
inputs = tokenizer(asm_func, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model.generate(**inputs, max_new_tokens=2048)### max length to 4096, max new tokens should be below the range
c_func_decompile = tokenizer.decode(outputs[0][len(inputs[0]):-1])
with open(fileName +'.c','r') as f:#original file
func = f.read()
print(f'original function:n{func}')# Note we only decompile one function, where the original file may contain multiple functions
print(f'decompiled function:n{c_func_decompile}')Data are stored in llm4decompile/decompile-eval/decompile-eval-executable-gcc-obj.json, using JSON list format. There are 164*4 (O0, O1, O2, O3) samples, each with five keys:
task_id: indicates the ID of the problem.type: the optimization stage, is one of [O0, O1, O2, O3].c_func: C solution for HumanEval problem.c_test: C test assertions.input_asm_prompt: assembly instructions with prompts, can be derived as in our preprocessing example.Please check the evaluation scripts.
This code repository is licensed under the MIT and DeepSeek License.
@misc{tan2024llm4decompile,
title={LLM4Decompile: Decompiling Binary Code with Large Language Models},
author={Hanzhuo Tan and Qi Luo and Jing Li and Yuqun Zhang},
year={2024},
eprint={2403.05286},
archivePrefix={arXiv},
primaryClass={cs.PL}
}


