PointLLM
1.0.0
 PointLLM: Empowering Large Language Models to Understand Point Clouds
PointLLM: Empowering Large Language Models to Understand Point Clouds
Runsen Xu
Xiaolong Wang
Tai Wang
Yilun Chen
Jiangmiao Pang*
Dahua Lin
The Chinese University of Hong Kong Shanghai AI Laboratory Zhejiang University

PointLLM is online! Try it at http://101.230.144.196 or at OpenXLab/PointLLM.
You can chat with PointLLM about the models of the Objaverse dataset or about your own point clouds!
Please do not hesitate to tell us if you have any feedback! ?
| Dialogue 1 | Dialogue 2 | Dialogue 3 | Dialogue 4 |
|---|---|---|---|
 |
 |
 |
 |
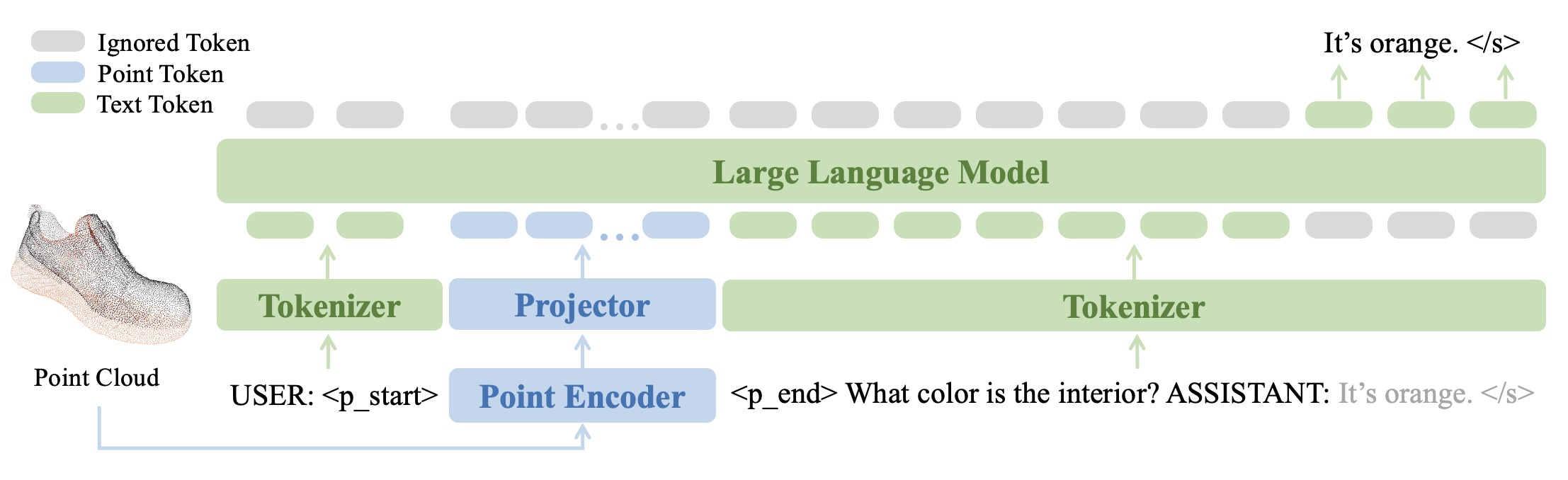
Please refer to our paper for more results.
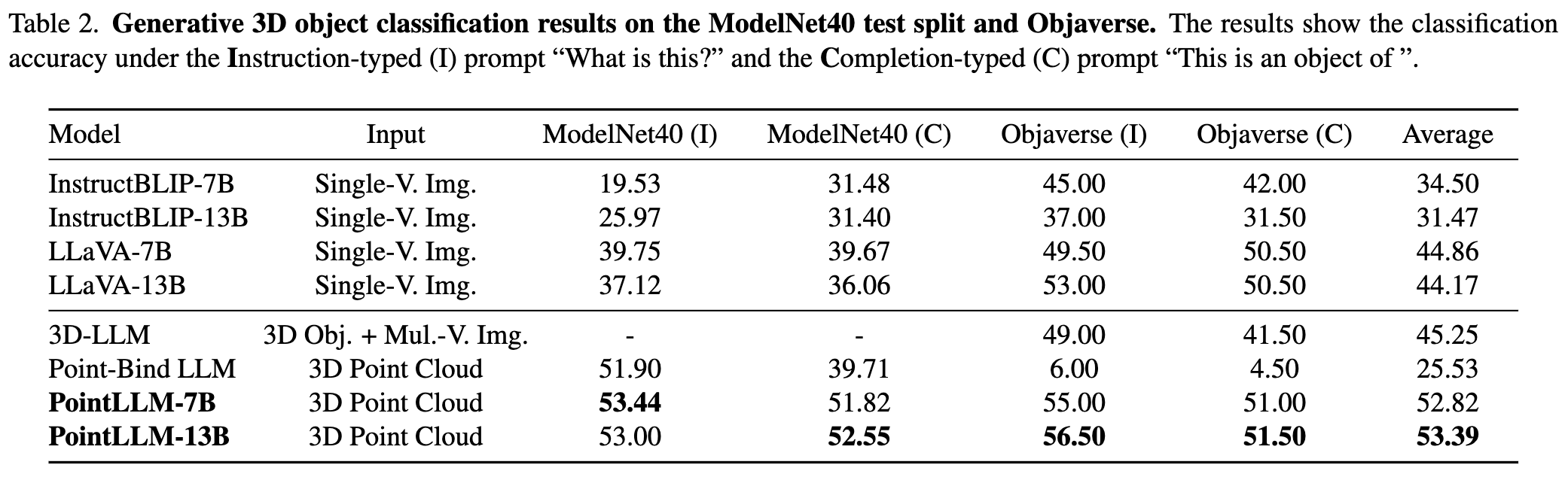
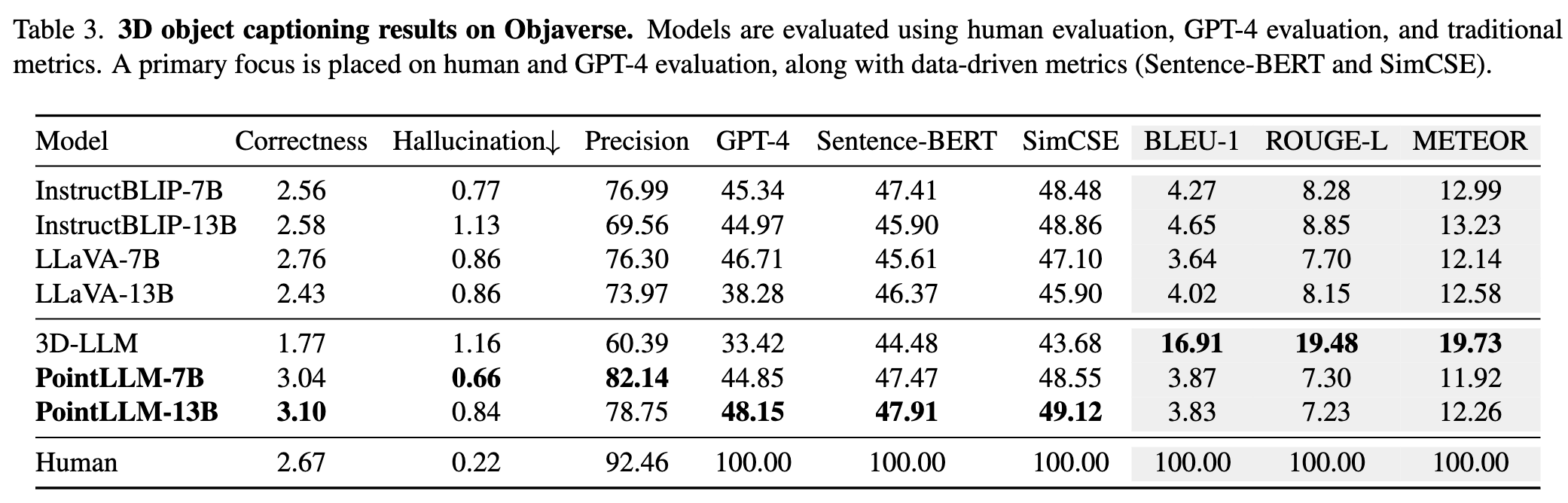
Please refer to our paper for more results.

We test our codes under the following environment:
To start:
git clone [email protected]:OpenRobotLab/PointLLM.git
cd PointLLMconda create -n pointllm python=3.10 -y
conda activate pointllm
pip install --upgrade pip # enable PEP 660 support
pip install -e .
# * for training
pip install ninja
pip install flash-attn8192_npy containing 660K point cloud files named {Objaverse_ID}_8192.npy. Each file is a numpy array with dimensions (8192, 6), where the first three dimensions are xyz and the last three dimensions are rgb in [0, 1] range.cat Objaverse_660K_8192_npy_split_a* > Objaverse_660K_8192_npy.tar.gz
tar -xvf Objaverse_660K_8192_npy.tar.gzPointLLM folder, create a folder data and create a soft link to the uncompressed file in the directory.cd PointLLM
mkdir data
ln -s /path/to/8192_npy data/objaverse_dataPointLLM/data folder, create a directory named anno_data.anno_data directory. The directory should look like this:PointLLM/data/anno_data
├── PointLLM_brief_description_660K_filtered.json
├── PointLLM_brief_description_660K.json
└── PointLLM_complex_instruction_70K.jsonPointLLM_brief_description_660K_filtered.json is filtered from PointLLM_brief_description_660K.json by removing the 3000 objects we reserved as the validation set. If you want to reproduce the results in our paper, you should use the PointLLM_brief_description_660K_filtered.json for training. The PointLLM_complex_instruction_70K.json contains objects from the training set.pointllm/data/data_generation/system_prompt_gpt4_0613.txt.PointLLM_brief_description_val_200_GT.json we use for the benchmarks on Objaverse dataset here, and put it in PointLLM/data/anno_data. We also provide the 3000 object ids we filter during training here and their corresponding referencing GT here, which can be used to evaluate on all the 3000 objects.modelnet40_data in PointLLM/data. Download the test split of ModelNet40 point clouds modelnet40_test_8192pts_fps.dat here and put it in PointLLM/data/modelnet40_data.PointLLM folder, create a directory named checkpoints.checkpoints directory.cd PointLLM
scripts/PointLLM_train_stage1.shscripts/PointLLM_train_stage2.shUsually, you do not have to care about the following contents. They are only for reproducing the results in our v1 paper (PointLLM-v1.1). If you want to compare with our models or use our models for downstream tasks, please use PointLLM-v1.2 (refer to our v2 paper), which has better performance.
PointLLM v1.1 and v1.2 use slightly different pre-trained point encoders and projectors. If you want to reproduce PointLLM v1.1, edit the config.json file in the directory of initial LLM and point encoder weights, for example, vim checkpoints/PointLLM_7B_v1.1_init/config.json.
Change the key "point_backbone_config_name" to specify another point encoder config:
# change from
"point_backbone_config_name": "PointTransformer_8192point_2layer" # v1.2
# to
"point_backbone_config_name": "PointTransformer_base_8192point", # v1.1Edit the checkpoint path of the point encoder in scripts/train_stage1.sh:
# change from
point_backbone_ckpt=$model_name_or_path/point_bert_v1.2.pt # v1.2
# to
point_backbone_ckpt=$model_name_or_path/point_bert_v1.1.pt # v1.1torch.float32 data type for chatting about 3D models of Objaverse. The model checkpoints will be downloaded automatically. You can also manually download the model checkpoints and specify their paths. Here is an example:cd PointLLM
PYTHONPATH=$PWD python pointllm/eval/PointLLM_chat.py --model_name RunsenXu/PointLLM_7B_v1.2 --data_name data/objaverse_data --torch_dtype float32You can also easily modify the codes for using point clouds other than those from Objaverse, as long as the point clouds input to the model have dimensions (N, 6), where the first three dimensions are xyz and the last three dimensions are rgb (in [0, 1] range). You may sample the point clouds to have 8192 points, as our model is trained on such point clouds.
The following table shows GPU requirements for different models and data types. We recommend using torch.bfloat16 if applicable, which is used in the experiments in our paper.
| Model | Data Type | GPU Memory |
|---|---|---|
| PointLLM-7B | torch.float16 | 14GB |
| PointLLM-7B | torch.float32 | 28GB |
| PointLLM-13B | torch.float16 | 26GB |
| PointLLM-13B | torch.float32 | 52GB |
cd PointLLM
PYTHONPATH=$PWD python pointllm/eval/chat_gradio.py --model_name RunsenXu/PointLLM_7B_v1.2 --data_name data/objaverse_datacd PointLLM
export PYTHONPATH=$PWD
# Open Vocabulary Classification on Objaverse
python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type classification --prompt_index 0 # or --prompt_index 1
# Object captioning on Objaverse
python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type captioning --prompt_index 2
# Close-set Zero-shot Classification on ModelNet40
python pointllm/eval/eval_modelnet_cls.py --model_name RunsenXu/PointLLM_7B_v1.2 --prompt_index 0 # or --prompt_index 1{model_name}/evaluation as a dict with the following format:{
"prompt": "",
"results": [
{
"object_id": "",
"ground_truth": "",
"model_output": "",
"label_name": "" # only for classification on modelnet40
}
]
}cd PointLLM
export PYTHONPATH=$PWD
export OPENAI_API_KEY=sk-****
# Open Vocabulary Classification on Objaverse
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-4-0613 --eval_type open-free-form-classification --parallel --num_workers 15
# Object captioning on Objaverse
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-4-0613 --eval_type object-captioning --parallel --num_workers 15
# Close-set Zero-shot Classification on ModelNet40
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-3.5-turbo-0613 --eval_type modelnet-close-set-classification --parallel --num_workers 15Ctrl+C. This will save the temporary results. If an error occurs during the evaluation, the script will also save the current state. You can resume the evaluation from where it left off by running the same command again.{model_name}/evaluation as another dict.
Some of the metrics are explained as follows:"average_score": The GPT-evaluated captioning score we report in our paper.
"accuracy": The classification accuracy we report in our paper, including random choices made by ChatGPT when model outputs are vague or ambiguous and ChatGPT outputs "INVALID".
"clean_accuracy": The classification accuracy after removing those "INVALID" outputs.
"total_predictions": The number of predictions.
"correct_predictions": The number of correct predictions.
"invalid_responses": The number of "INVALID" outputs by ChatGPT.
# Some other statistics for calling OpenAI API
"prompt_tokens": The total number of tokens of the prompts for ChatGPT/GPT-4.
"completion_tokens": The total number of tokens of the completion results from ChatGPT/GPT-4.
"GPT_cost": The API cost of the whole evaluation process, in US Dollars ?.--start_eval flag and specifying the --gpt_type. For example:python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type classification --prompt_index 0 --start_eval --gpt_type gpt-4-0613python pointllm/eval/traditional_evaluator.py --results_path /path/to/model_captioning_outputCommunity contributions are welcome!? If you need any support, please feel free to open an issue or contact us.
If you find our work and this codebase helpful, please consider starring this repo ? and cite:
@inproceedings{xu2024pointllm,
title={PointLLM: Empowering Large Language Models to Understand Point Clouds},
author={Xu, Runsen and Wang, Xiaolong and Wang, Tai and Chen, Yilun and Pang, Jiangmiao and Lin, Dahua},
booktitle={ECCV},
year={2024}
}
This work is under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Together, Let's make LLM for 3D great!


