Stable Diffusion End-to-End Guide - From Noob to Expert
I became interested in using SD to generate images for military applications. Most of the resources are taken from 4chan's NSFW boards, as anons use SD to make hentai. Interestingly, the canonical SD WebUI has built-in functionality with anime/hentai image boards... One of the first use cases of SD right after DALL-E was generating anime girls, so the jump to hentai is not surprising.
Anyhow, the techniques from these weirdos are applicable to a variety of applications, most specifically LoRAs, which are like model fine-tuners. The idea is to work with specific LoRAs (e.g., military vehicles, aircraft, weapons, etc.) to generate synthetic image data for training vision models. Training new, useful LoRAs is also of interest. Later stuff may include inpainting for perturbation.
Disclaimer and Sources
Every link here may contain NSFW content, as most of the cutting-edge work on SD and LoRAs is with porn or hentai. So, please be wary when you are working with these resources. ALSO, Rentry.org pages are the main resources linked to in this guide. If any of the rentry pages do not work, change the .org to .co and the link should work. Otherwise, use the Wayback machine.
-TP
Play With It!
What can you actually do with SD? Huggingface and some others have some apps in-browser for you. Play around with them to see the power! What we will do in this guide is get the full, extensible WebUI to allow us to do anything we want.
- Huggingface Text to Image SD Playground
- Dreamstudio Text to Image SD App
- Dezgo Text to Image SD App
- Huggingface Image to Image SD Playground
- Huggingface Inpainting Playground
Table of Contents
- WebUI Basics
- Set up Local GPU usage
- Linux Setup
- Going Deeper
- Prompting
- NovelAI Model
- LoRA
- Playing with Models
- VAEs
- Put it all Together
- The General SD Process
- Saving Prompts
- txt2img Settings
- Regenerating a Previously-Generated Image
- Troubleshooting Errors
- Getting Comfortable
- Testing
- WebUI Advanced
- Prompt Editing
- Xformers
- Img2Img
- Inpainting
- Extras
- ControlNets
- Making New Stuff (WIP)
- Checkpoint Merger
- Training LoRAs
- Training New Models
- Google Colab Setup (WIP)
- Midjourney
- MJ Parameters
- MJ Advanced Prompts
- DreamStudio (WIP)
- Stable Horde (WIP)
- DreamBooth (WIP)
- Video Diffusion (WIP)
WebUI Basics
It's somewhat daunting to get into this... but 4channers have done a good job making this approachable. Below are the steps I took, in the simplest terms. Your intent is to get the Stable Diffusion WebUI (built with Gradio) running locally so you can start prompting and making images.
Set up Local GPU Usage
We will do Google Colab Pro setup later, so we can run SD on any device anywhere we want; but to start, let's get the WebUI setup on a PC. You need 16GB RAM, a GPU with 2GB VRAM, Windows 7+ and 20+GB disk space.
- Finish the starting setup guide
- I followed this up to step 7, after which it goes into the hentai stuff
- Step 3 takes 15-45 minutes on average Internet speed, as the models are 5+ GB each
- Step 7 can take upwards of half an hour and may seem "stuck" in the CLI
- In step 3 I downloaded SD1.5, not the 2.x versions, as 1.5 produces much better results
- CivitAI has all the SD models; it's like HuggingFace but for SD specifically
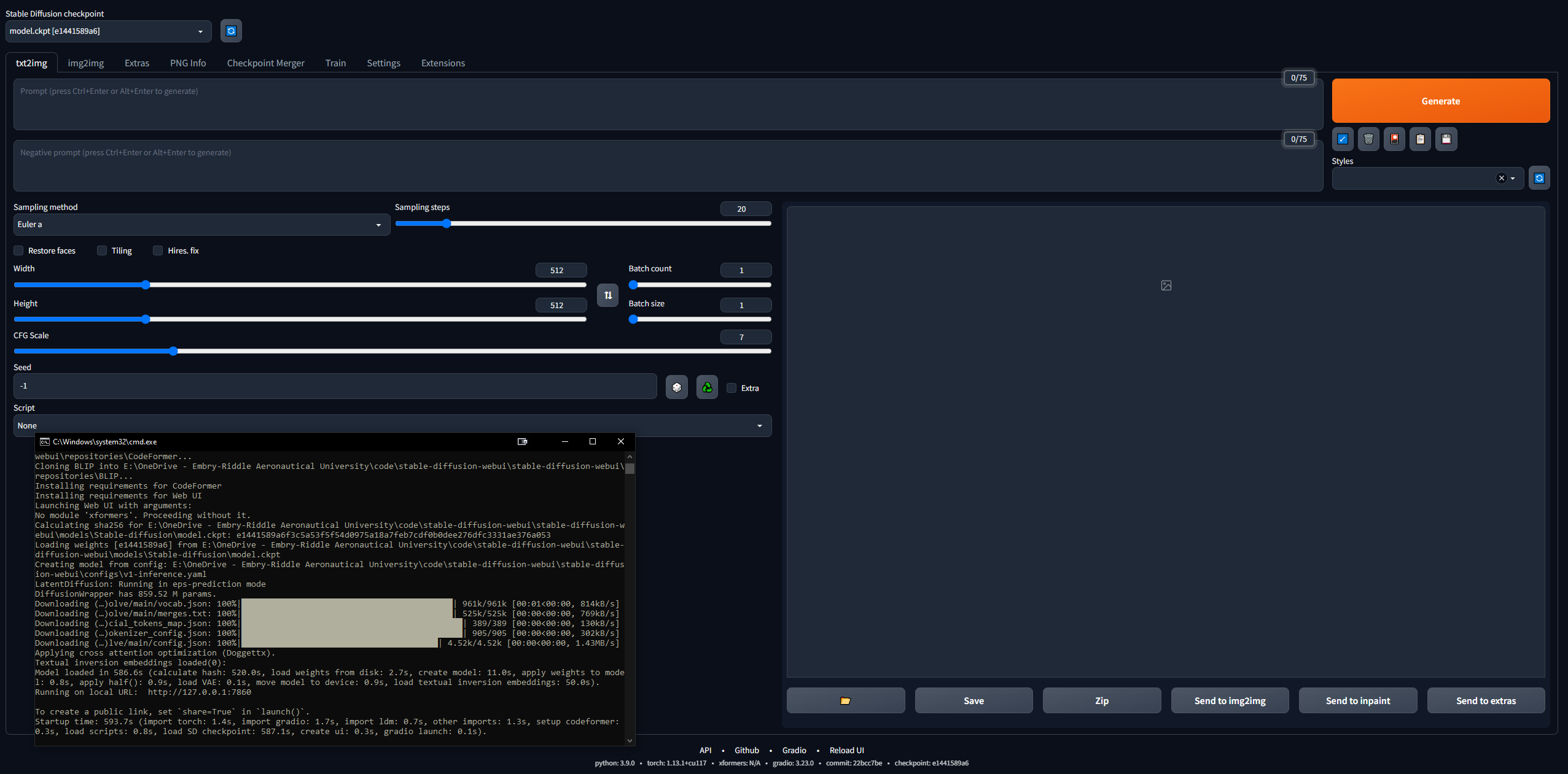
- Verify that the WebUI works
- Copy the URL the CLI outputs once done, e.g.,
127.0.0.1:7860 (do NOT use Ctrl + C because this command can close the CLI)
- Paste into browser and voila; try a prompt and you're off to the races
- Images will be saved automatically when generated to
stable-diffusion-webuioutputstxt2img-images<date>
- Remember, to update, just open a CLI in the stable-diffusion-webui folder and enter the command
git pull
Linux Setup
Ignore this entirely if you have Windows. I did manage to get it running on Linux too, although it's a bit more complicated. I started by following this guide, but it is rather poorly written, so below are the steps I took to get it running in Linux. I was using Linux Mint 20, which is an Ubuntu 20 distribution.
- Start by cloning the webui repo:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
- Get a SD model (e.g., SD 1.5, like in the previous section)
- Put the model ckpt file into
stable-diffusion-webui/models/Stable-diffusion
- Download Python (if you don't already have it):
sudo apt install python3 python3-pip python3-virtualenv wget git
- And the WebUI is very particular, so we need to install Conda, a virtual environment manager, to work inside of:
wget https://repo.anaconda.com/miniconda/Minconda3-latest-Linux-x86_64.sh
chmod +x Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
- Now create the environment:
conda create --name sdwebui python=3.10.6
- Activate the environment:
conda activate sdwebui
- Navigate to your WebUI folder and type
./webui.sh
- It should execute for a bit until you get an error about not being able to access CUDA/your GPU... this is fine, because it's our next step
- Start by wiping any existing Nvidia drivers:
sudo apt update
sudo apt purge *nvidia*
- Now, sort of following some bits from this guide, find out what GPU your Linux machine has (easiest way to do this is to open the Driver Manager app and your GPU will be listed; but there are a dozen ways, just Google it)
- Go to this page and click the "Latest New Feature Branch" under Linux x86_64 (for me, it was 530.xx.xx)
- Click the tab "Supported Products" and Ctrl + F to find your GPU; if it is listed, proceed, otherwise back out and try "Latest Production Branch Version"; note the number, e.g., 530
- In a terminal, type:
sudo add-apt-repository ppa:graphics-drivers/ppa
- Update with
sudo apt-get update
- Launch the Driver Manager app and you should see a list of them; do NOT select the recommended one (e.g., nvidia-driver-530-open), select the exact one from earlier (e.g., nvidia-driver-530), and Apply Changes; OR, install it in the terminal with
sudo apt-get install nvidia-driver-530
- AT THIS POINT, you should get a popup through your CLI about Secure Boot, asking you for an 8-digit password: set it and write it down
- Reboot your PC and before your encryption/user login, you should see a BIOS-like screen (I am writing this from memory) with an option to input a MOK key; click it and enter your password, then submit and boot; some info here
- Log in like normally and type the command
nvidia-smi; if successful, it should print a table; if not, it will say something like "Could not connect to the GPU; please ensure the most up to date driver is installed"
- Now to install CUDA (the last command here should print some info about your new CUDA install); from this guide:
sudo apt update
sudo apt install apt-transport-https ca-certificates gnupg
sudo apt install nvidia-cuda-toolkit
nvcc-version
- Now go back and do steps 7-9; if you get this "ERROR: Cannot activate python venv, aborting...", go to the next step (otherwise, you are off to the races and will copy the IP address from the CLI like normal and can begin playing with SD)
- This Github issue has some troubleshooting for this venv problem... for me, what worked was running
python3 -c 'import venv'
python3 -m venv venv/
And then going to the /stable-diffusion-webui folder and running:
rm -rf venv/
python3 -m venv venv/
After that, it worked for me.
Going Deeper
- Read up on prompting techniques, because there are lots of things to know (e.g., positive prompt vs. negative prompt, sampling steps, sampling method, etc.)
- OpenArt Promptbook Guide
- Definitive SD Prompting Guide
- A succint prompting guide
- 4chan prompting tips (NSFW)
- Collection of prompts and images
- Step-by-Step Anime Girl Prompting Guide
- Read up on SD knowledge in general:
- Seminal Stable Diffusion Publication
- CompVis / Stability AI Github (home of the original SD models)
- Stable Diffusion Compendium (good outside resource)
- Stable Diffusion Links Hub (incredible 4chan resource)
- Stable Diffusion Goldmine
- Simplified SD Goldmine
- Random/Misc. SD Links
- FAQ (NSFW)
- Another FAQ
- Join the Stable Diffusion Discord
- Keep up to date with Stable Diffsion news
- Did you know that as of March 2023, a 1.7B parameter text-to-video diffusion model is available?
- Mess around in the WebUI, play with different models, settings, etc.
Prompting
The order of words in a prompt has an effect: earlier words take precedence. The general structure of a good prompt, from here:
<general positives> <descriptors of subject> <descriptors of background> <post-processing, camera, etc.>
And another good guide says the prompt should follow this structure:
<subject> <medium> <style> <artist> <website> <resolution> <additional details> <color> <lighting>
A seminal paper on prompt engineering txt2img models, here. The definitive resource on LLM prompting, here.
Whatever you prompt, try to follow some sort of structure so your process is replicable. Below are the necessary prompt syntax elements:
- () = x1.05 modifier
- [] = /1.05 modifier
- (word:1.05) == (word)
- (word:1.1025) == ((word))
- (word:.952) == [word]
- (word:.907) == [[word]]
- The AND keyword allows you to prompt two separate prompts at once to merge them; good so things don't get smashed together in latent space
- E.g.,
1girl standing on grass in front of castle AND castle in background
NovelAI Model
The default model is pretty neat but, as is usually the case in history, sex drives most things. NovelAI (NAI) was an anime-focused SD content generation service and its main model was leaked. Most of the SD-generated images of anime men and women you see (NSFW or not) come from this leaked model.
In any case, it's just really good at generating people and most of the models or LoRAs you will play with merging are compatible with it because they are trained on anime images. Also, humans present a really good starting use case for fine-tuning exactly what LoRAs you want to use for professional purposes. You will be troubleshooting a lot and most of the guides out there are for images of women. Later we will get into variable auto-encoders (VAEs), which brings true realism to the model.
- Follow the NovelAI Speedrun Guide
- You'll need to Torrent the leaked model or find it elsewhere
- Once you get the files into the folder for the WebUI,
stable-diffusion-webuimodelsStable-diffusion, and select the model there, you should have to wait a few minutes while the CLI loads the VAE weights
- If you have trouble here, copy the config.yaml file from the folder where the model was and follow the same naming scheme (like in this guide)
- This is important... Recreate the Asuka image exactly, referring to the troubleshooting guide if it does not match
- Find new SD models and LoRAs
- CivitAI
- Huggingface
- SDG Models
- SDG Model Motherload (NSFW)
- SDG LoRA Motherload (NSFW)
- Lots of popular models (also the prompting guide from earlier) (NSFW)
LoRA
Low-Rank Adaptation (LoRA) allows fine-tuning for a given model. More info on LoRAs here. In the WebUI, you can add LoRAs to a model like icing on a cake. Training new LoRAs is also pretty easy. There are other, "ancestral" means of fine-tuning (e.g., textual inversion and hypernetworks), but LoRAs are the state-of-the-art.
- ZTZ99A Tank - military tank LoRA (a specific tank)
- Fighter Jets - fighter jet LoRA
- epi_noiseoffset - LoRA that makes images pop, increases contrast
I will use the tank LoRA throughout the guide. Please note that this is not a very good LoRA, as it is meant for anime-style images, but it is fine to play around with.
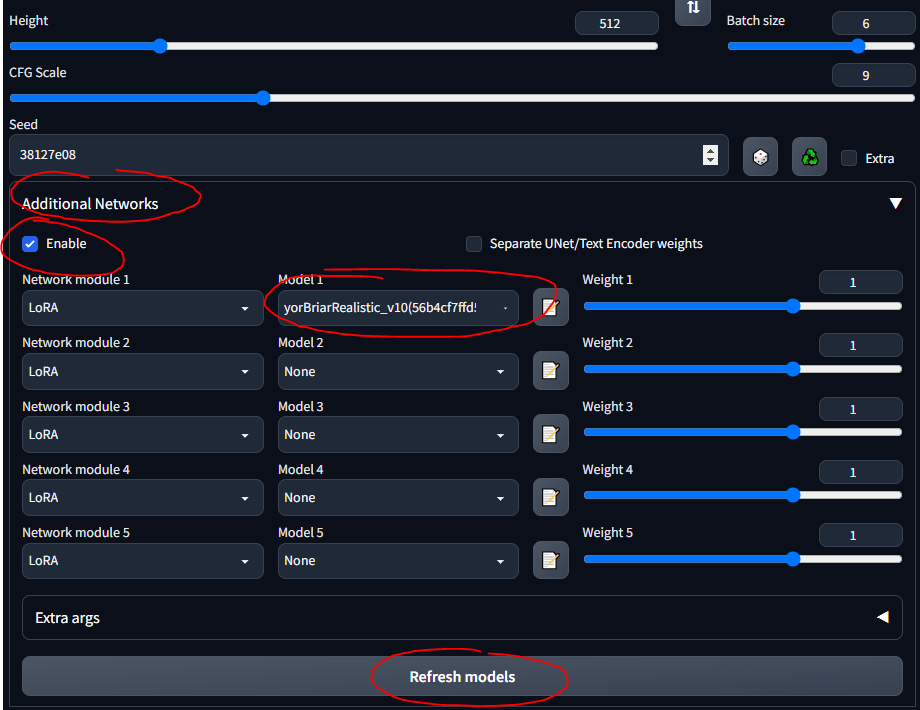
- Follow this quick guide to install the extension
- You should now see an "Additional Networks" section in the UI
- Put your LoRAs into
stable-diffusion-webuiextensionssd-webui-additional-networksmodelslora
- Select and go
- MAKE SURE YOU CHECK 'ENABLE'
- Just know that any LoRA you download probably has info describing how to use it... like "use the keyword tank" or something; make sure wherever you download it from (e.g., CivitAI), you read its description
Playing with Models
Building upon the previous section... different models have different training data and training keywords... so using booru tags on some models doesn't work very well. Below are some of the models I played with and the "instructions" for them.
SDG Model Motherload, used to get most of the models, I'm just summarizing the instructions here for quick reference; most of the models are for literal porn, I focused on the realistic ones. Follow the links to see example prompts, images and detailed notes on using each of them.
- Default SD model (1.5, from the setup step; you can play with SD's 2.x versions but to be frank, they suck)
- NovelAI model (from the first guide)
- Anything v3 - general purpose anime model
- Dreamshaper - realism, all-purpose
- Deliberate - realism, fantasy, paintings, scenery
- Neverending Dream - realism, fantasy, good for people and animals
- Uses the booru tag system
- Epic Diffusion - ultra-realism, intended to replace original SD
- AbyssOrangeMix (AOM) - anime, realism, artistic, paintings, extremely common and good for testing
- Kotosmix - general purpose, realism, anime, scenery, people, DPM++ 2M Karras sampler recommended
CivitAI was used to get all the others. You need to make an account otherwise you will not be able to see NSFW stuff, including weapons and military equipment. On CivitAI, some models (checkpoints) include VAEs; if it states this, download it as well and place it alongside the model.
- ChilloutMix - ultra-realism, portraits, one of the most popular
- Protogen x3.4 - ultra-realism
- Use trigger words: modelshoot style, analog style, mdjrny-v4-style, nousr robot
- Dreamlike Photoreal 2.0 - ultra-realism
- Use trigger word: photorealistic
- SPYBG's Toolkit for Digital Artists - realism, concept art
- Use trigger words: tk-char, tk-env
VAEs
Variable Autoencoders make images look better, crisper, less blown out. Some also fix hands and faces. But it's mostly a saturation and shading thing. Explained here and here (NSFW). The NovelAI / Anything VAE is commonly used. It's basically an add-on to your model, just like a LoRA.
Find VAEs at the VAE List:
- NAI / Anything - for anime models
- Comes with the NAI model by default when you put it into the models folder
- SD 1.5 - for realistic models
- Download a VAE
- Follow this quick section of the guide to set up VAEs in the WebUI
- Make sure to put them in
stable-diffusion-webuimodelsVAE
- Play around with making images with and without your VAE, to see the differences
Put it all Together
Here are some general notes and helpful things I learned along the way that do not necessarily fit the chronological flow of this guide.
The General SD Process
A good way to learn is to browse cool images on CivitAI, AIbooru or other SD sites (4chan, Reddit, etc.), open what you like and copy the generation parameters into the WebUI. Full disclosure: recreating an image exactly is not always possible, as described here. But you can generally get pretty close. To really play around, turn the CFG low so the model can get more creative. Try batches and walk away from the computer to come back to lots to pick through.
The general process for a WebUI workflow is:
find/pick models/LoRAs -> txt2img (repeat, change params, etc.) -> img2img -> inpainting -> extra ->
- txt2img - prompt and get images
- img2img - edit images and generate similar ones
- inpainting - edit parts of images (will discuss later)
- extra - final image edits (will discuss later)
Saving Prompts
Sometimes you want to go back to prompts without pasting in images or writing them from scratch. You can save prompts to re-use them in the WebUI.
- Write a positive and/or negative prompt
- Under the Generate button, click the button on the right to save your "style"
- Enter a name and save
- Select it anytime by clicking the Styles drop-down
txt2img Settings
This section is more or less a digest of this guide's information.
- More sampling steps generally means more accuracy (except for "a" samplers, like Euler a, that change every so often)
- Play with this on and off; generally, when on, it really makes faces look good
- Highres. fix is good for images above 512x512; useful if there is more than one person in an image
- CFG is best at low-middle values, like 5-10
Regenerating a Previously-Generated Image
To work from an SD-generated image that already exists; maybe someone sent it to you or you want to recreate one you made:
- In the WebUI, go to the PNG Info tab
- Drag and drop the image you are interested into the UI
- They are saved in
stable-diffusion-webuioutputstxt2img-images<date>
- See the used parameters on the right
- Works because PNGs can store metadata
- You can send it right to the txt2img page with the corresponding button
- Might have to check back and forth to make sure the model, VAE and other parameters auto-populate correctly
Be aware, some sites remove PNG metadata when images are uploaded (e.g., 4chan), so look for URLs to the full images or use sites that retain SD metadata, like CivitAI or AIbooru.
Troubleshooting Errors
I got a few errors now and again. Mostly out of memory (VRAM) errors that were fixed by lowering values on some parameters. Sometimes the Restore faces and Hires. fix settings can cause this. In the file stable-diffusion-webuiwebui-user.bat, on the line set COMMANDLINE_ARGS=, you can put some flags that fix common errors.
- A NaN error, something to the effect of "a VAE produced a NaN something", add the parameter
--disable-nan-check
- If you ever get black images, add
--no-half
- If you keep running out of VRAM, add
--medvram or for potato computers, --lowvram
- Face restoration Codeformer fix here (if it does break, try resetting your Internet first)
- Slow model loading (when switching to a new one) is probably because .safetensors files load slowly if things aren't configured properly. This thread discusses it.
One really common issue stems from having an incorrect Python version or Torch version. You will get errors like "cannot install Torch" or "Torch cannot find GPU". The simplest fix is:
- Uninstall any Python version you have updated, because the SD WebUI expects 3.10.6 (I have used 3.11.5 and ignored the starting error just fine, but 3.10.6 seems to work best) (you can also use a version manager if you're advanced enough)
- Install Python 3.10.6, making sure to add it to your PATH (both your
Python folder and the Python/Scripts folders)
- Delete the
venv folder in your stable-diffusion-webui folder
- Run
stable-diffusion-webuiwebui-user.bat and let it re-build the venv properly
- Enjoy
All commandline arguments can be found here.
Getting Comfortable
Some extensions can make using the WebUI better. Get the Github link, go to Extensions tab, install from URL; optionally, in the Extensions Tab, click Available, then Load From and you can browse extensions locally, this mirrors the extensions Github wiki.
- Tag Completer - recommends and auto-completes booru tags as you type
- Stable Diffusion Web UI State - preserves the UI state even after restarting
- Test My Prompt - a script that you can run to remove individual words from your prompt to see how it affects image generation
- Model-Keyword - autofills keywords associated with some models and LoRAs, pretty well-maintained and up-to-date as of Apr. 2023
- NSFW Checker - blacks out NSFW images; useful if you are working in an office, as a lot of good models allow NSFW content and you may not want to see that at work
- BE AWARE: this extension can mess up inpainting or even generation by blacking out NSFW images (not temporally, it literally outputs a black image instead), so make sure to turn it off as needed
- Gelbooru Prompt - pulls tags and creates an automatic-prompt from any Gelbooru image using its hash
- booru2prompt - similar to Gelbooru Prompt but a bit more functionality
- Dynamic Prompting - a template language for prompt generation that allows you to run random or combinatorial prompts to generate various images (uses wildcards)
- Model toolkit - popular extension that helps you manage, edit and create models
- Model Converter - useful for converting models, changing precisions etc., when you are training your own
Testing
So now you have some models, LoRAs and prompts... how can you test to see what works best? Below the Additional Networks pane, there is the Script dropdown. In here, click X/Y/Z plot. In the X type, select Checkpoint name; in the X values, click the button to the right to paste all of your models. In the Y type, try VAE, or perhaps seed, or CFG scale. Whatever attribute you pick, paste (or enter) the values you want to graph. For instance, if you have 5 models and 5 VAEs, you will make a grid of 25 images, comparing how each model outputs with each VAE. This is very versatile and can help you decide what to use. Just beware that if your X or Y axes are models of VAEs, it has to load the model or VAE weights for every combination, so it can take a while.
A really good resource on SD comparisons can be found here (NSFW). There are lots of links to follow. You can begin to form an understanding on how the various models, VAEs, LoRAs, parameter values and so on affect image generation.
I adopted a test prompt from here and used the tank LoRA to make this X/Y grid. You can see how the various models and samplers work with each other. From this test, we can evaluate that:
- The models ChilloutMix, Deliberate, Dreamlike Photoreal and Epic Diffusion seem to produce the most "realistic" tank images
- In later independent tests, it was found that the Protogen X34 Photorealism and SpyBGs Toolkit were both pretty good at tanks too
- The most promising samplers here seem to be DPM++ SDE or any of the Karras samplers.

The exact parameters used (not including the model or sampler) for every one of these tank images are given below (again, taken from here):
- Positive prompt: tank, bf2042, Best quality, masterpiece, ultra high res, (photorealistic:1.4), detailed skin, cinematic lighting, cinematic highly detailed, colorful, modern Photograph, a group of soldiers in battlefield, battlefield explosion everywhere, jet fighters and helicopters flying in the sky, two tanks on the ground, In desert area , buildings on fire and one abandoned military armored vehicle in the background
- Negative prompt: naked, (worst quality:2), (low quality:2), (normal quality:2), lowres, bad anatomy, bad hands, normal quality, ((monochrome)), ((grayscale)), collapsed eyeshadow, multiple eyeblows, pink hair, holes on breasts, ng_deepnegative_v1_75t, nsfw, nipples,extra fingers, ((extra arms)), (extra legs), mutated hands, (fused fingers), (too many fingers), (long neck:1.3)
- Steps: 22
- CFG scale: 7.5
- Seed: 1656460887
- Size: 480x480
- Clip skip: 2
- AddNet Enabled: True, AddNet Module 1: LoRA, AddNet Model 1: ztz99ATank_ztz99ATank(82a1a1085b2b), AddNet Weight A 1: 1, AddNet Weight B 1: 1
WebUI Advanced
In this section are the more advanced things you can do once you get a good familiarity with using models, LoRAs, VAEs, prompting, parameters, scripting and extensions in the txt2image tab of the WebUI.
Prompt Editing
Also known as prompt blending. Prompt editing allows you to have the model change its prompt on specified steps. The below image was taken from a 4chan post and describes the technique. For instance, as stated in this guide, prompt editing can be used to blend faces.
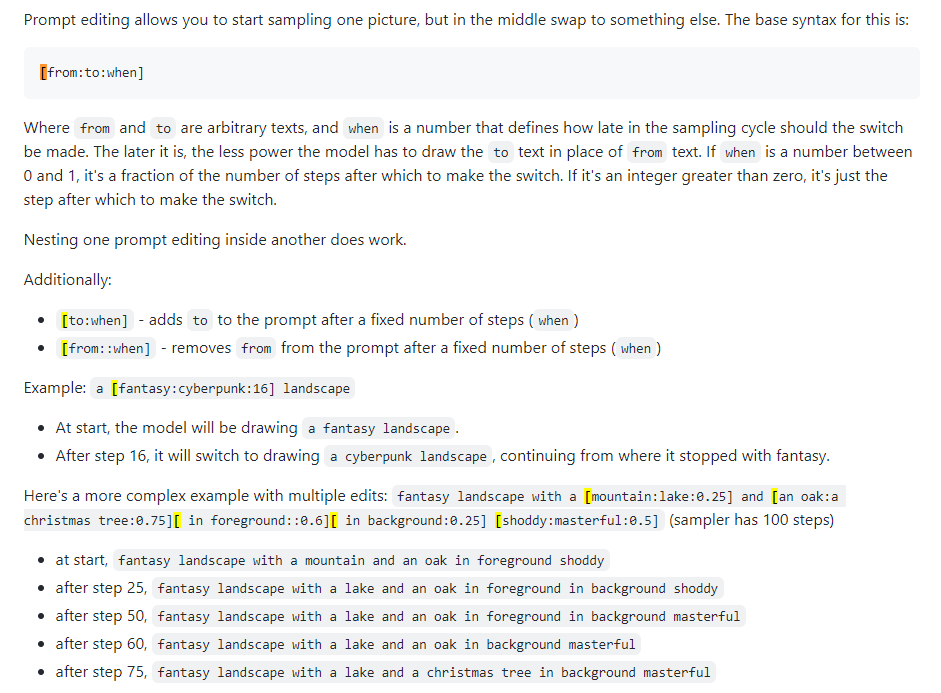
Xformers
Xformers, or cross-attention layers. A way to speed up image generation (measured in seconds/iteration, or s/it) on Nvidia GPUs, lowers VRAM usage but causes non-determinism. Only consider this if you have a powerful GPU; realistically you need a Quadro.
img2img
Not exactly used much, sort of a confusing tab. Can be used to generate images given sketches, like in the Huggingface Image to Image SD Playground. This tab has a sub-tab, inpainting, which is the subject of the next section and a very important capability of the WebUI. While you can use this section to generate altered images given one you already made (output to stable-diffusion-webuioutputsimg2img-images), the functionality is spotty to me... it seems to use an insane amount of memory and I can barely get it to work. Go to the next section below.
Inpainting
This is where the power lies for the content creator or someone interested in image perturbation. Output is in stable-diffusion-webuioutputsimg2img-images.
- Inpainting and outpainting guide
- 4chan inpainting (NSFW)
- Definitive inpainting guide
- Grab an image you like but that isn't perfect, something is off - it needs to be tweaked
- Or generate one and click Send to inpaint (all the settings will auto-populate)
- You are now in the img2img -> inpaint sub-tab
- Draw (with your mouse) on the image the exact spot you want to change
- Set mask mode to "inpaint masked", masked content to "original" and inpaint area to "only masked"
- In the prompt area up above, write the new prompt to tweak that spot in the image; do a negative prompt if you'd like
- Generate an image (ideally, do a batch of 4 or so)
- Whichever one you like, click Send to inpaint and iterate until you have a finished image
Outpainting
Outpainting is a rather complex semantic process. Outpainting lets you take an image and expand it as many times as you would like, essentially growing the borders of it. The process is described here. You expand the image only 64 pixels at a time. There are two UI tools for this (that I could find):
- Alpha Canvas (built into WebUI as an extension/script)
- Hua (web-app for inpainting/outpainting)
Extras
This WebUI tab is specifically for upscaling. If you get an image you really like, you can upscale it here at the end of your workflow. Upscaled images are stored in stable-diffusion-webuioutputsextras-images. Some of the memory issues associated with upscaling with more powerful upscalers during generation in the txt2img tab (e.g., the 4x+ ones) do not happen here because you are not generating new images, you are only upscaling static ones.
ControlNets
The best way to understand what a ControlNet does is like saying "inpainting on steroids". You give it an input image (SD-generated or not) and it can modify the entire thing. Also possible with ControlNets are poses. You can give a reference pose for a person and generate corresponding images given your typical prompt. A good start to understand ControlNets is here.
- Install the ControlNet extension, sd-webui-controlnet in the WebUI
- Make sure to reload the UI, by clicking the Reload UI button in the settings tab
- Verify that the ControlNet button is now in the txt2img (and img2img) tab, below Additional Networks (where you put your LoRAs)
- Activate multi ControlNet models: Settings -> ControlNet -> Mutli ControlNet slider -> 2+
- Reload the UI and in the ControlNet area you should see multiple model tabs
- You can combine ControlNets (e.g., Canny and OpenPose) just like using multiple LoRAs
- Get a ControlNet model
- The Canny models are edge-detection models; images are converted into black-and-white edge images, where the edges tell SD, roughly, what your image will look like
- The OpenPose models take an image of a person and convert it to a pose model to use in later images
- There are a lot of other models that can be investigated there as well
- Let's grab the Canny and OpenPose models
- Put them into
stable-diffusion-webuiextensionssd-webui-controlnetmodels
- Get any image of interest to you, or generate a new one; here, I will use this tank image I generated earlier

- Settings in txt2img: sampling method "DDIM", sampling steps 20, width/height same as your selected image
- Settings in the ControlNet tab: check Enable, Preprocessor "Canny", Model "control_canny-fp16", canvas width/height same as your selected image (all other settings default)
- Modify your prompts and click generate; I tried to convert my tank image to one on Mars

- Positive prompt was: a scene on mars, outerspace, space, universe, ((galaxy space background)), stars, moonbase, futuristic, black background, dark background, stars in sky, (night time) red sand, ((stars in the background)), tank, bf2042, Best quality, masterpiece, ultra high res, (photorealistic:1.4), detailed skin, cinematic lighting, cinematic highly detailed, colorful, modern Photograph, a group of soldiers in battlefield, battlefield explosion everywhere, jet fighters and helicopters flying in the sky, two tanks on the ground, In desert area , buildings on fire and one abandoned military armored vehicle in the background, tree, forest, sky
- Go grab an image with people in it and you can do both the Canny model in Control Model - 0 and the OpenPose model in Control Model - 1 to really have fun with it
- Again, watch this video to really go into depth with Canny and OpenPose
Making New Stuff
This is all well and good, but sometimes you need better models or LoRAs for professional use cases. Because most of the SD content is literally meant for generating women or porn, specific models and LoRAs may need to be trained.
- Browse every topic of interest here
- Training LoRAs
- LoRA train
- Lazy LoRA training guide
- A Good LoRA training guide from CivitAI
- Another LoRA training guide
- More general LoRA info
- Merging models
- Mixing models
Training New Models
See the section on DreamBooth.
Checkpoint Merger
TODO
The checkpoint merger tab in the WebUI lets you combine two models together, like mixing two sauces in a pot, where the output is a new sauce that is a combination of both of them.
Training LoRAs
TODO
Training a LoRA is not necessarily hard, it's just a matter of gathering enough data.
Google Colab Setup
This is an important step if you have to work away from your rig. Google Colab Pro is 10 dollars a month and gives you 89 GB of RAM and access to good GPUs, so you can technically run prompts from your phone and have them work for you on a server in Timbuktu. If you don't mind a bit of extra cost, Google Colab Pro+ is 50 dollars a month and is even better.
- Go to this pre-built SD Colab
- You can clone it to your GDrive or just use it as it sits so it's always the most up-to-date from the Github
- Run the first 4 code blocks (takes a bit)
- Skip the ControlNet code block
- Run 'Start Stable-Diffusion' (takes a bit)
- Put username/password if you want to (probably a good idea as Gradio is public)
- Click the Gradio link ('running on public URL')
- Use the WebUI like normal
- Send the link to your phone and you can generate images on-the-go
- To add new models and LoRAs, you should have new folders in your Google Drive:
gdrive/MyDrive/sd/stable-diffusion-webui, and from this base folder you can use the same folder structure stuff you've been doing in the local WebUI
- Do the LoRA extension installation like earlier and the folder structure will auto-populate just like on desktop
- Now every time you want to use it, you just have to run the 'Start Stable-Diffusion' code block (none of the other stuff), get a gradio link and you're done
Google Colab is always free and you can use it forever, but it can be a little slow. Upgrading to Colab Pro for $10/month gives you some more power. But Colab Pro+ for $50/month is where the fun really is. Pro+ lets you run your code for 24 hours even after you close the tab.
TODO
I do get a weird error that breaks it with my Pro subscription when I set my runtime -> runetime type notebook settings to Premium GPU class and High-RAM. It's because xFormers wasn't built with CUDA support. This could be solved by using TPUs instead or disabling xFormers but I don't have the patience for it right now. Try the Colab's issues.
Midjourney
MJ is really good for artists. It is not AT ALL as extensible or powerful as SD in the WebUI (NSFW is impossible), but you can generate some pretty awesome things. You can use it for free in the MJ Discord (sign up on their site) for a few prompts or pay $8/month for the basic plan, whereafter you can use it in your own private server. All the Discord commands can be found here and here. The prompt structure for MJ is:
/imagine <optional image prompt> <prompt> --parameters
MJ Parameters
These are for MJ V4, mostly the same for MJ 5. All models are described here.
- --ar 1.2-2.1: aspect ratio, default is 1:1
- --chaos 0-100: variation in, default is 0
- --no plants: removes plants
- --q 0.0-2.0: rendering quality time, default is 1
- --seed: the seed
- --stop 10-100: stop job partway to generate a blurrier image
- --style 4a/4b/4c: style of MJ 4'
- --stylize 0-1000: how strongly MJ's aesthetic runs free, default is 100
- --uplight: use a "light" upscaler, image is less detailed
- --upbeta: use a beta upscaler, closer to original image
- --upanime: upscaler for anime images
- --niji: alternative model for anime images
- --hd: use an earlier model that produces larger images, good for abstracts and landscapes
- --test: use the special MJ test model
- --testp: use the special MJ photography-focused test model
- --tile: for MJ 5 only, generates a repeating image
- --v 1/2/3/4/5: which MJ version to use (5 is best)
MJ Advanced Prompts
- You can inject an image (or images) into the beginning of a prompt to influence its style and colors. See this doc. Upload an image to your Discord server and right-click to get the link.
- Remixing lets you make variations of an image, changing models, subjects or medium. See this doc.
- Multi prompts lets MJ consider two or more separate concepts individually. MJ versions 1-4 and niji only. For instance, "hot dog" will make images of the food, "hot:: dog" will make images of a warm canine. You can add weights to prompts too; for instance, "hot::2 dog" will make images of dogs on fire. MJ 1/2/3 accepts integer weights, MJ 4 can accept decimals. See this doc.
- Blending lets you upload 2-5 images to merge them into a new image. The /blend command is described here.
DreamStudio
TODO
DreamStudio (NOT DreamBooth) is the flagship platform from the Stability AI company. Their site is a platform, DreamBooth Studio, from which you can generate images. It sort of rests in between Midjourney and the WebUI in terms of open functionality. DreamBooth Studio seems to be built atop the invoke.ai platform, which you can install and run locally like the WebUI.
Stable Horde
TODO
The Stable Horde is a community effort to make stable diffusion free to everyone. It essentially works like Torrenting or Bitcoin hashing, where everyone contributes some of their GPU power to generate SD content. The Horde app can be accessed here.
DreamBooth
TODO
DreamBooth (NOT DreamStudio) was Google's implementation of a Stable Diffusion model fine-tuning technique. In short: you can use it to train models with your own pictures. You can use it directly from here or here. It's more complex than just downloading models and clicking around in the WebUI, as you are working to actually train and serialize a new model. Some videos summarize how to do it:
- DreamBooth Easy Tutorial
- DreamBooth 10 Minute Training
- WebUI DreamBooth extension
And some good guides:
- Reddit Advanced DreamBooth Advice
- Simple DreamBooth
- DreamBooth Dump (lots of info, scroll through links)
A Google Colab for DreamBooth:
- TheLastBen DreamBooth Training Colab (same author as the SD Colab described in Google Colab Setup)
There is also a model trainer called EveryDream. A full comparison between DreamBooth and EveryDream can be found here.
Video Diffusion
TODO
It is possible as of March-ish 2023 to use stable diffusion to generate videos. Currently (April 2023), functionality is rather simplistic, as videos are generated from similar images, frame by frame, giving videos a sort of "flipbook" look. There are two primary extensions for the WebUI you can use:
- Animator - easier
- Deforum - more functionality
Junkyard
Stuff I don't know much about but need to look into
There is a process you can follow to get good results over and over... this will be refined over time.
- TODO
- Highres fix, here
- upscaling, all over but here mostly
chatgpt integration?
outpainting
dall-e 2
deforum https://deforum.github.io/


