llm data annotation
1.0.0
This framework combines human expertise with the efficiency of Large Language Models (LLMs) like OpenAI's GPT-3.5 to simplify dataset annotation and model improvement. The iterative approach ensures the continuous improvement of data quality, and consequently, the performance of models fine-tuned using this data. This not only saves time but also enables the creation of customized LLMs that leverage both human annotators and LLM-based precision.
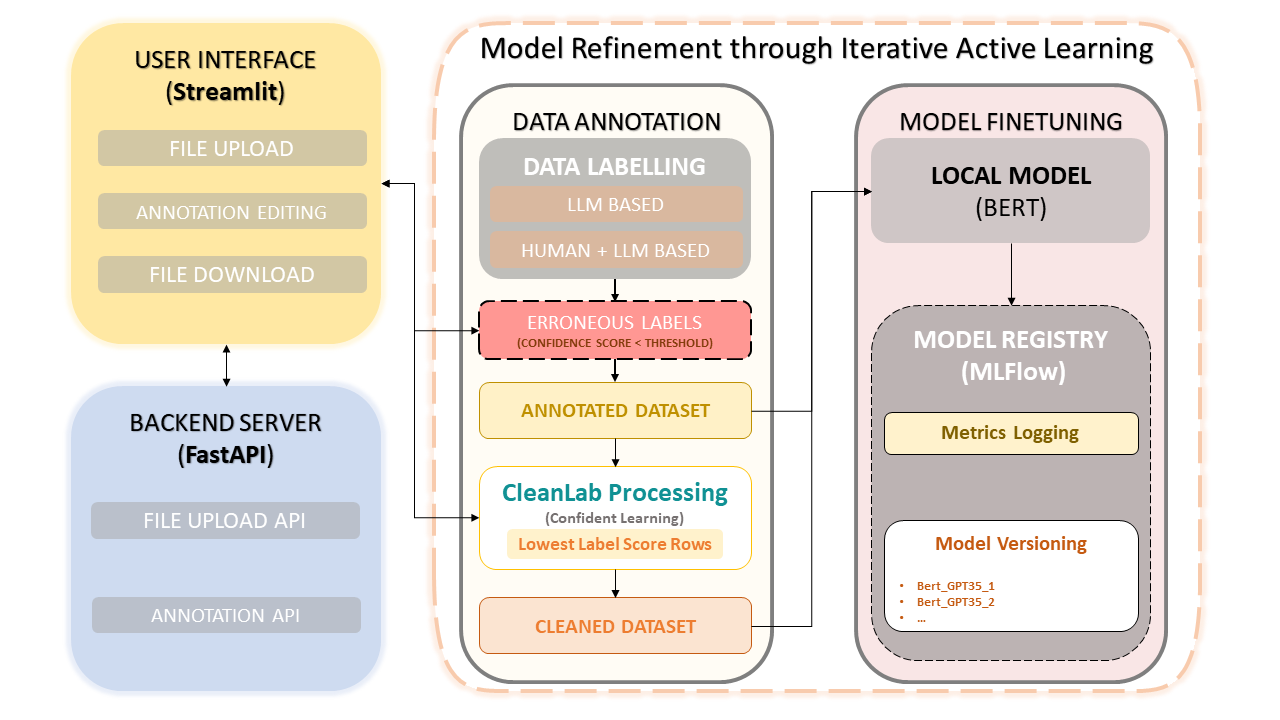
Dataset Uploading and Annotation
Manual Annotation Corrections
CleanLab: Confident Learning Approach
Data Versioning and Saving
Model Training
pip install -r requirements.txtStart the FastAPI backend:
uvicorn app:app --reloadRun the Streamlit app:
streamlit run frontend.pyLaunch MLflow UI: To view models, metrics, and registered models, you can access the MLflow UI with the following command:
mlflow uiAccess the provided links in your web browser:
http://127.0.0.1:5000.Follow the on-screen prompts to upload, annotate, correct, and train on your dataset.
Confident learning has emerged as a groundbreaking technique in supervised learning and weak-supervision. It aims at characterizing label noise, finding label errors, and learning efficiently with noisy labels. By pruning noisy data and ranking examples to train with confidence, this method ensures a clean and reliable dataset, enhancing the overall model performance.
This project is open-sourced under the MIT License.


