EasyEdit
1.0.0

An Easy-to-use Knowledge Editing Framework for Large Language Models.
Installation • QuickStart • Doc • Paper • Demo • Benchmark • Contributors • Slides • Video • Featured By AK
2024-10-23, the EasyEdit integrates constrained decoding methods from steering editing to mitigate hallucination in LLM and MLLM, with detailed information available in DoLa and DeCo.
2024-09-26, ?? our paper "WISE: Rethinking the Knowledge Memory for Lifelong Model Editing of Large Language Models" has been accepted by NeurIPS 2024.
2024-09-20, ?? our papers: "Knowledge Mechanisms in Large Language Models: A Survey and Perspective" and "Editing Conceptual Knowledge for Large Language Models" have been accepted by EMNLP 2024 Findings.
2024-07-29, the EasyEdit has added a new model editing algorithm EMMET, which generalizes ROME to the batch setting. This essentially allows making batched edits using the ROME loss function.
2024-07-23, we release a new paper: "Knowledge Mechanisms in Large Language Models: A Survey and Perspective", which reviews how knowledge is acquired, utilized, and evolves in large language models. This survey may provide the fundamental mechanisms for precisely and efficiently manipulating (editing) knowledge in LLMs.
2024-06-04, ?? EasyEdit Paper has been accepted by the ACL 2024 System Demonstration Track.
2024-06-03, we released a paper titled "WISE: Rethinking the Knowledge Memory for Lifelong Model Editing of Large Language Models", along with introducing a new editing task: Continuous Knowledge Editing and correspondding lifelong editing method called WISE.
2024-04-24, EasyEdit announced support for the ROME method for Llama3-8B. Users are advised to update their transformers package to version 4.40.0.
2024-03-29, EasyEdit introduced rollback support for GRACE. For a detailed introduction, refer to the EasyEdit documentation. Future updates will gradually include rollback support for other methods.
2024-03-22, a new paper titled "Detoxifying Large Language Models via Knowledge Editing" was released, along with a new dataset named SafeEdit and a new detoxification method called DINM.
2024-03-12, another paper titled "Editing Conceptual Knowledge for Large Language Models" was released, introducing a new dataset named ConceptEdit.
2024-03-01, EasyEdit added support for a new method called FT-M. This method involves training a specific MLP layer using cross-entropy loss on the target answer and masking the original text. It outperforms the FT-L implementation in ROME. The author of issue #173 is thanked for their advice.
2024-02-27, EasyEdit added support for a new method called InstructEdit, with technical details provided in the paper "InstructEdit: Instruction-based Knowledge Editing for Large Language Models".
Accelerate.A Comprehensive Study of Knowledge Editing for Large Language Models [paper][benchmark][code]
IJCAI 2024 Tutorial Google Drive
COLING 2024 Tutorial Google Drive
AAAI 2024 Tutorial Google Drive
AACL 2023 Tutorial [Google Drive] [Baidu Pan]
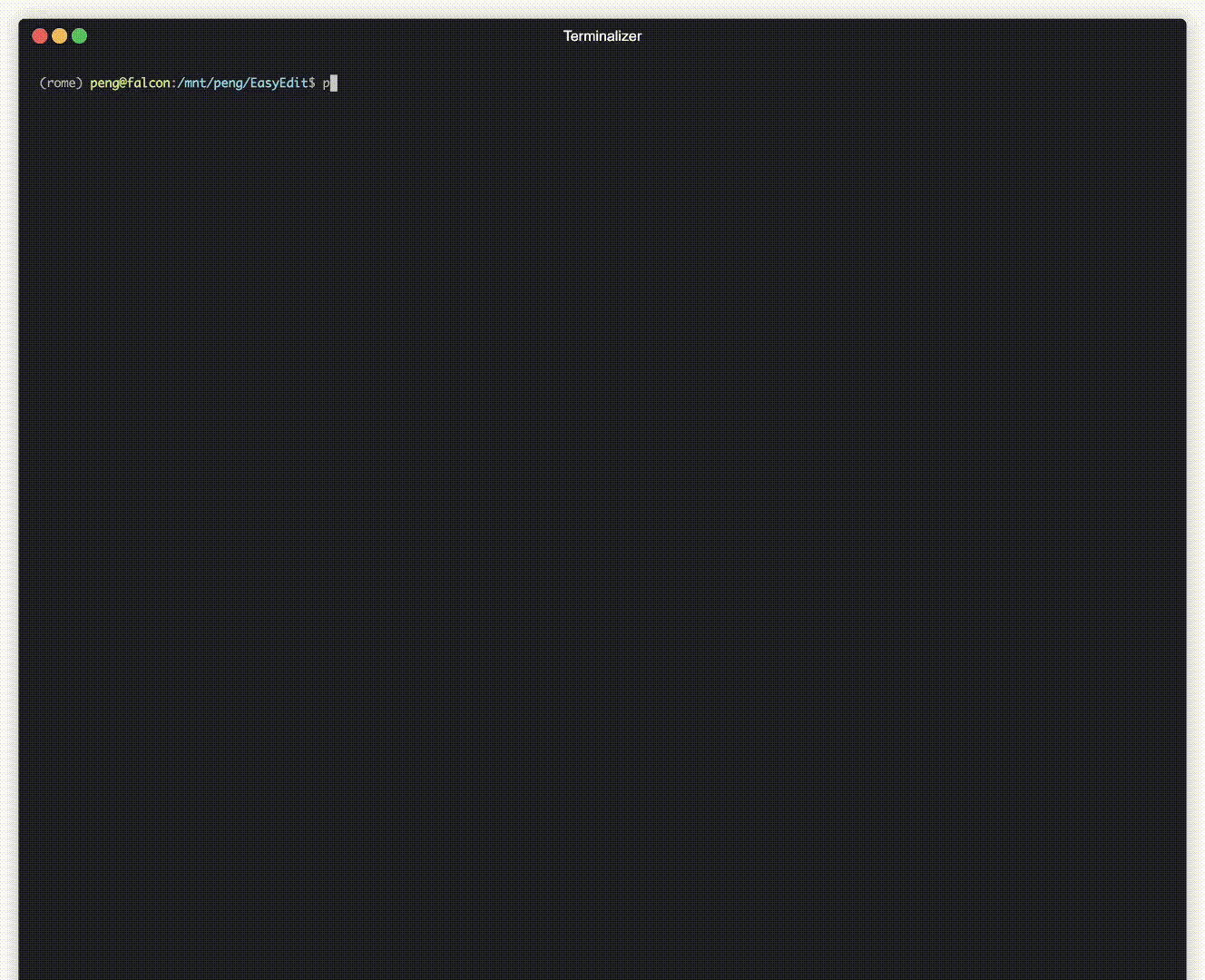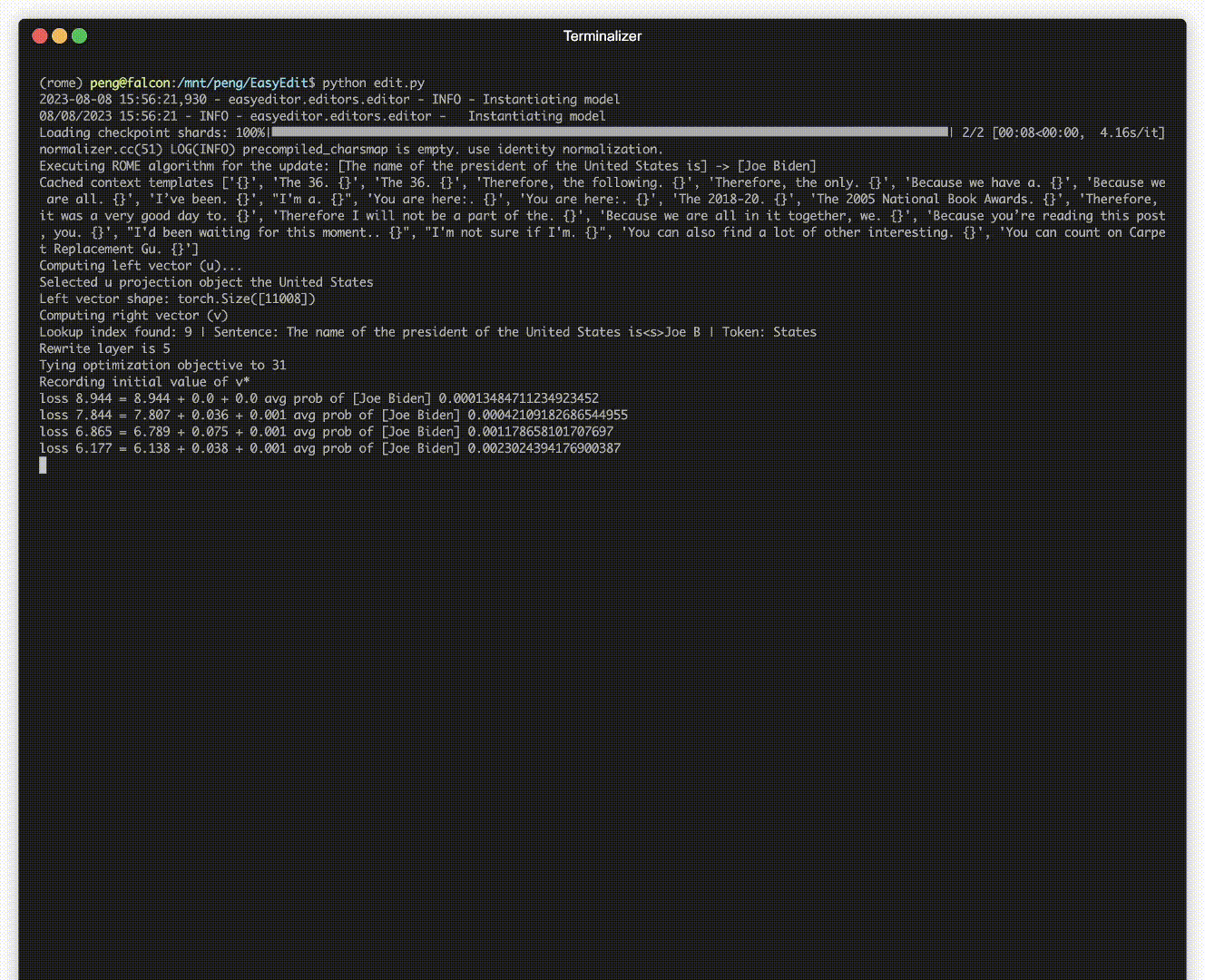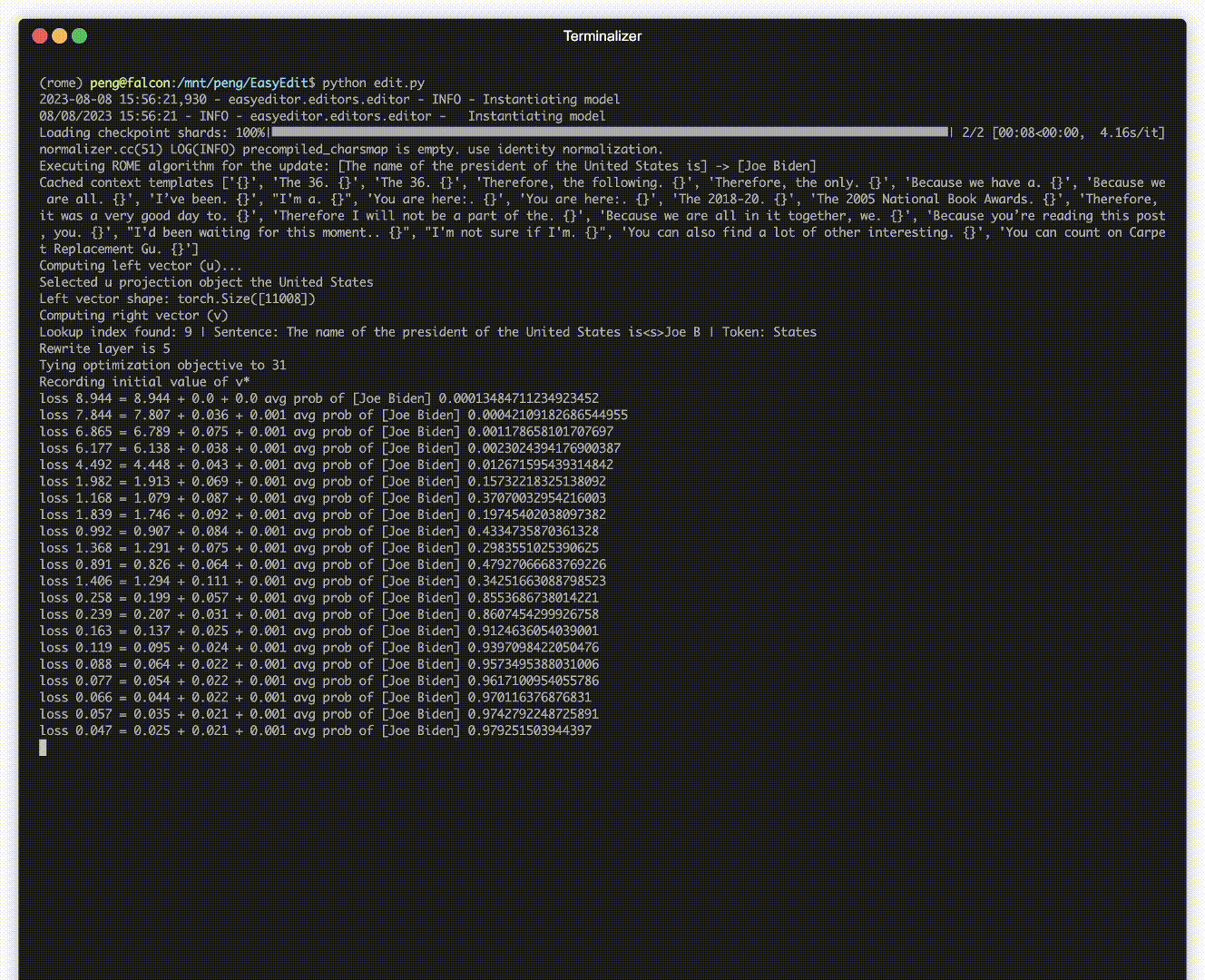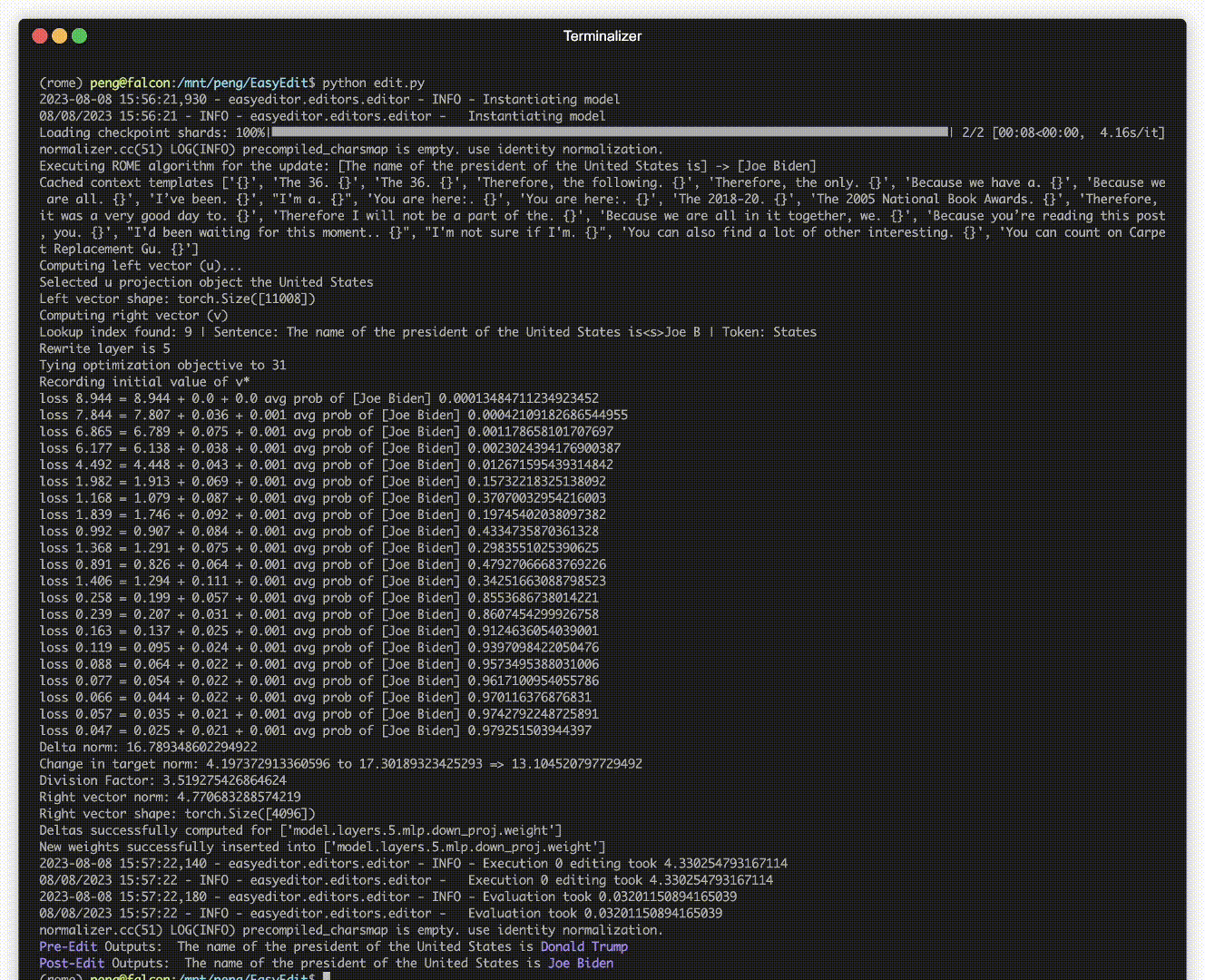
There is a demonstration of editing. The GIF file is created by Terminalizer.
We provide a handy Jupyter Notebook! It allows you to edit a LLM's knowledge of the US president, switching from Biden to Trump and even back to Biden. This includes methods like WISE, AlphaEdit, AdaLoRA, and Prompt-based editing.
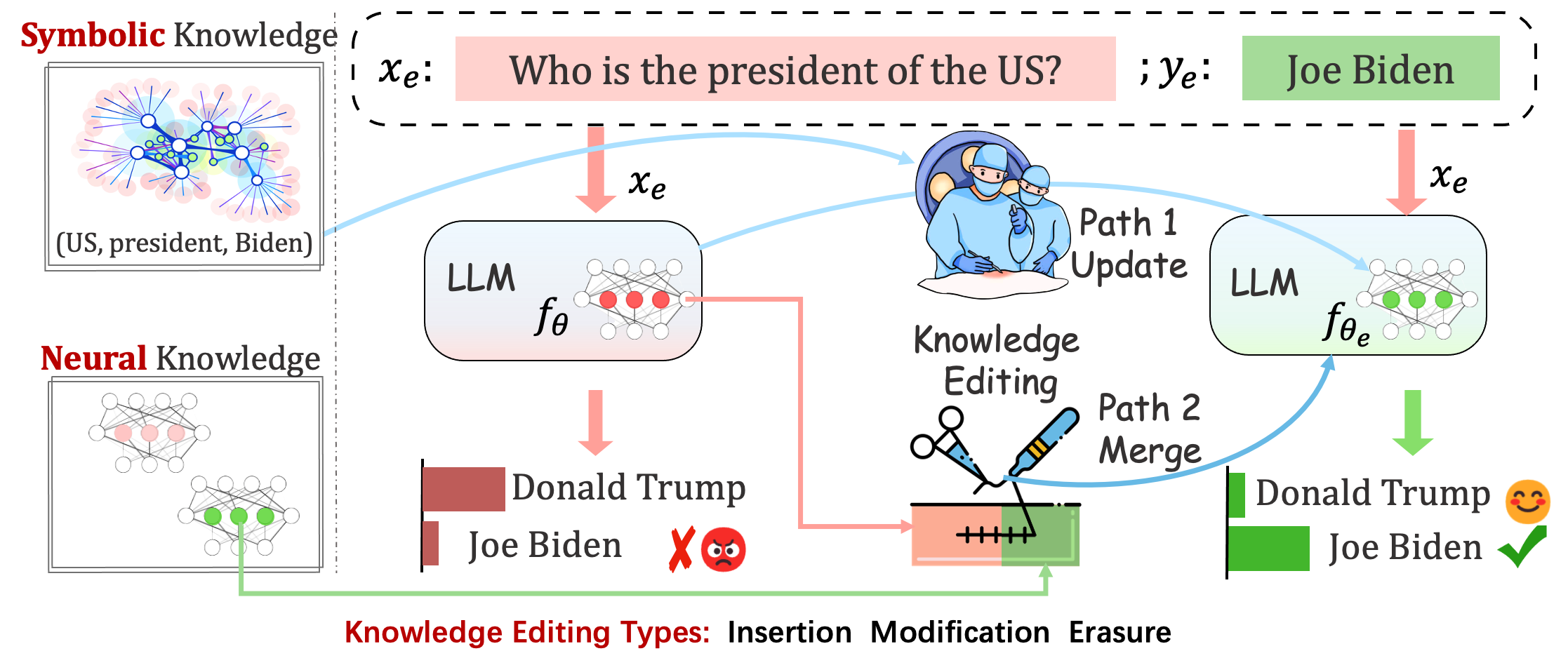
Deployed models may still make unpredictable errors. For example, LLMs notoriously hallucinate, perpetuate bias, and factually decay, so we should be able to adjust specific behaviors of pre-trained models.
Knowledge editing aims to adjust base model's
Evaluating the performance of the model after a single edit. The model reloads the original weights (e.g. LoRA discards the adapter weights) after a single edit. You should set sequential_edit=False
This requires sequentially editing, and evaluation is performed after all knowledge updates have been applied:
It makes parameter adjustments for sequential_edit=True: README (for more details).
Without influencing the model behavior on unrelated samples, the ultimate goal is to create an edited model
Editing Task for Image Captioning and Visual Question Answering. README
The proposed task takes the preliminary attempt to edit LLMs' personalities by editing their opinions on specific topics, given that an individual's opinions can reflect aspects of their personality traits. We draw upon the established BIG FIVE theory as a basis for constructing our dataset and assessing the LLMs' personality expressions. README
Evaluation
Logits-based
Generation-based
While for assessing Acc and TPEI, you can download the trained classifier from here.
The knowledge editing process generally impacts the predictions for a broad set of inputs that are closely associated with the edit example, called the editing scope.
A successful edit should adjust the model’s behavior within the editing scope while remaining unrelated inputs:
Reliability: the success rate of editing with a given editing descriptorGeneralization: the success rate of editing within the editing scopeLocality: whether the model's output changes after editing for unrelated inputsPortability: the success rate of editing for reasoning/application(one hop, synonym, logical generalization)Efficiency: time and memory consumptionEasyEdit is a Python package for edit Large Language Models (LLM) like GPT-J, Llama, GPT-NEO, GPT2, T5(support models from 1B to 65B), the objective of which is to alter the behavior of LLMs efficiently within a specific domain without negatively impacting performance across other inputs. It is designed to be easy to use and easy to extend.
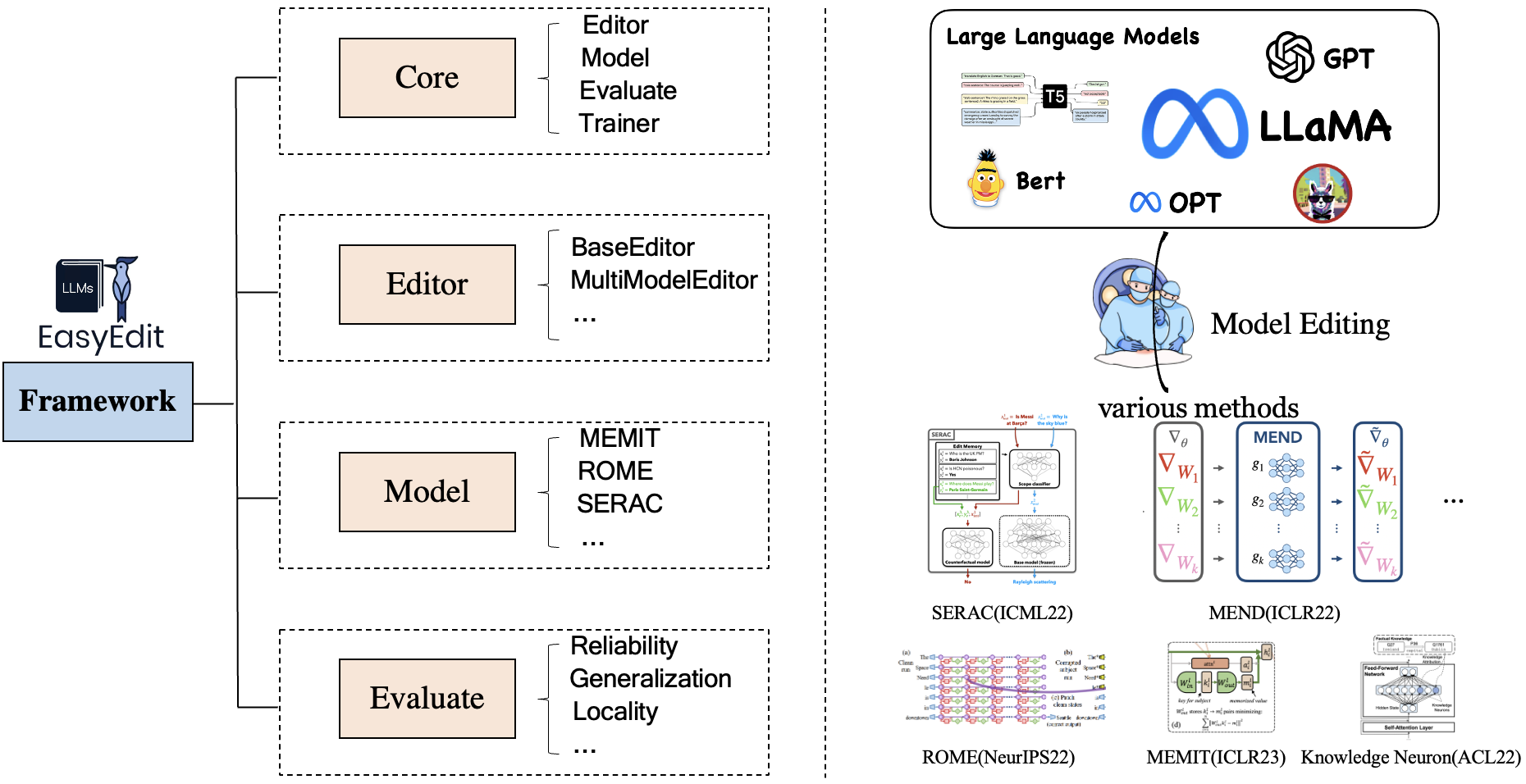
EasyEdit contains a unified framework for Editor, Method and Evaluate, respectively representing the editing scenario, editing technique, and evaluation method.
Each Knowledge Editing scenario comprises of three components:
Editor: such as BaseEditor(Factual Knowledge and Generation Editor) for LM, MultiModalEditor(MultiModal Knowledge).Method: the specific knowledge editing technique used(such as ROME, MEND, ..).Evaluate: Metrics for evaluating knowledge editing performance.
Reliability, Generalization, Locality, Portability
The current supported knowledge editing techniques are as follows:
Note 1: Due to the limited compatibility of this toolkit, some knowledge editing methods including T-Patcher, KE, CaliNet are not supported.
Note 2: Similarly, the MALMEN method is only partially supported due to the same reasons and will continue to be improved.
You can choose different editing methods according to your specific needs.
| Method | T5 | GPT-2 | GPT-J | GPT-NEO | LlaMA | Baichuan | ChatGLM | InternLM | Qwen | Mistral |
|---|---|---|---|---|---|---|---|---|---|---|
| FT | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| AdaLoRA | ✅ | ✅ | ||||||||
| SERAC | ✅ | ✅ | ✅ | ✅ | ||||||
| IKE | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| MEND | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| KN | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| ROME | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| r-ROME | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| MEMIT | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| EMMET | ✅ | ✅ | ✅ | |||||||
| GRACE | ✅ | ✅ | ✅ | |||||||
| MELO | ✅ | |||||||||
| PMET | ✅ | ✅ | ||||||||
| InstructEdit | ✅ | ✅ | ||||||||
| DINM | ✅ | ✅ | ✅ | |||||||
| WISE | ✅ | ✅ | ✅ | ✅ | ✅ | |||||
| AlphaEdit | ✅ | ✅ | ✅ |
❗️❗️ If you intend to use Mistral, please update the
transformerslibrary to version 4.34.0 manually. You can use the following code:pip install transformers==4.34.0.
| Work | Description | Path |
|---|---|---|
| InstructEdit | InstructEdit: Instruction-based Knowledge Editing for Large Language Models | Quick Start |
| DINM | Detoxifying Large Language Models via Knowledge Editing | Quick Start |
| WISE | WISE: Rethinking the Knowledge Memory for Lifelong Model Editing of Large Language Models | Quick Start |
| ConceptEdit | Editing Conceptual Knowledge for Large Language Models | Quick Start |
| MMEdit | Can We Edit Multimodal Large Language Models? | Quick Start |
| PersonalityEdit | Editing Personality For Large Language Models | Quick Start |
| PROMPT | PROMPT-based knowledge editing methods | Quick Start |
Benchmark: KnowEdit [Hugging Face][WiseModel][ModelScope]
❗️❗️ To be noted, KnowEdit is constructed by re-organizing and extending existing datasests including WikiBio, ZsRE, WikiDataCounterfact, WikiDataRecent, convsent, Sanitation to make a comprehensive evaluation for knowledge editing. Special thanks to the builders and maintainers of the those datasets.
Please note that Counterfact and WikiDataCounterfact are not the same dataset.
| Task | Knowledge Insertion | Knowledge Modification | Knowledge Erasure | |||
|---|---|---|---|---|---|---|
| Datasets | Wikirecent | ZsRE | WikiBio | WikiDatacounterfact | Convsent | Sanitation |
| Type | Fact | Question Answering | Hallucination | Counterfact | Sentiment | Unwanted Info |
| # Train | 570 | 10,000 | 592 | 1,455 | 14,390 | 80 |
| # Test | 1,266 | 1301 | 1,392 | 885 | 800 | 80 |
We provide detailed scripts for user to easily use KnowEdit, please refer to examples.
knowedit
├── WikiBio
│ ├── wikibio-test-all.json
│ └── wikibio-train-all.json
├── ZsRE
│ └── ZsRE-test-all.json
├── wiki_counterfact
│ ├── test_cf.json
│ └── train_cf.json
├── convsent
│ ├── blender_test.json
│ ├── blender_train.json
│ └── blender_val.json
├── convsent
│ ├── trivia_qa_test.json
│ └── trivia_qa_train.json
└── wiki_recent
├── recent_test.json
└── recent_train.json
| dataset | HuggingFace | WiseModel | ModelScope | Description |
|---|---|---|---|---|
| CKnowEdit | [HuggingFace] | [WiseModel] | [ModelScope] | dataset for editing Chinese Knowledge |
CKnowEdit is a high-quality Chinese-language dataset for knowledge editing which is highly characterized by the Chinese language, with all data sourced from Chinese knowledge bases. It is meticulously designed to more deeply discern the nuances and challenges inherent in the comprehension of the Chinese language by current LLMs, providing a robust resource for refining Chinese-specific knowledge within LLMs.
The field descriptions for the data in CKnowEdit are as follows:
"prompt": query inputed to the model (str)
"target_old": the incorrect response previously generated by the model (str)
"target_new": the accurate answer of the prompt (str)
"portability_prompt": new prompts related to the target knowledge (list or None)
"portability_answer": accurate answers corresponding to the portability_prompt (list or None)
"locality_prompt": new prompts unrelated to the target knowledge (list or None)
"locality_answer": accurate answers corresponding to the locality_prompt (list or None)
"rephrase": alternative ways to phrase the original prompt (list)CknowEdit
├── Chinese Literary Knowledge
│ ├── Ancient Poetry
│ ├── Proverbs
│ └── Idioms
├── Chinese Linguistic Knowledge
│ ├── Phonetic Notation
│ └── Classical Chinese
├── Chinese Geographical Knowledge
└── Ruozhiba
| dataset | Google Drive | BaiduNetDisk | Description |
|---|---|---|---|
| ZsRE plus | [Google Drive] | [BaiduNetDisk] | Question Answering dataset using question rephrasings |
| Counterfact plus | [Google Drive] | [BaiduNetDisk] | Counterfact dataset using Entity replacement |
We provide zsre and counterfact datasets to verify the effectiveness of knowledge editing. You can download them here. [Google Drive], [BaiduNetDisk].
editing-data
├── counterfact
│ ├── counterfact-edit.json
│ ├── counterfact-train.json
│ └── counterfact-val.json
├── locality
│ ├── Commonsense Task
│ │ ├── piqa_valid-labels.lst
│ │ └── piqa_valid.jsonl
│ ├── Distracting Neighbor
│ │ └── counterfact_distracting_neighbor.json
│ └── Other Attribution
│ └── counterfact_other_attribution.json
├── portability
│ ├── Inverse Relation
│ │ └── zsre_inverse_relation.json
│ ├── One Hop
│ │ ├── counterfact_portability_gpt4.json
│ │ └── zsre_mend_eval_portability_gpt4.json
│ └── Subject Replace
│ ├── counterfact_subject_replace.json
│ └── zsre_subject_replace.json
└── zsre
├── zsre_mend_eval.json
├── zsre_mend_train_10000.json
└── zsre_mend_train.json
spouse
| dataset | Google Drive | HuggingFace Dataset | Description |
|---|---|---|---|
| ConceptEdit | [Google Drive] | [HuggingFace Dataset] | dataset for editing conceptual knowledge |
data
└──concept_data.json
├──final_gpt2_inter.json
├──final_gpt2_intra.json
├──final_gptj_inter.json
├──final_gptj_intra.json
├──final_llama2chat_inter.json
├──final_llama2chat_intra.json
├──final_mistral_inter.json
└──final_mistral_intra.json
Concept Specific Evaluation Metrics
Instance Change: capturing the intricacies of these instance-level changesConcept Consistency: the semantic similarity of generated concept definition| dataset | Google Drive | BaiduNetDisk | Description |
|---|---|---|---|
| E-IC | [Google Drive] | [BaiduNetDisk] | dataset for editing Image Captioning |
| E-VQA | [Google Drive] | [BaiduNetDisk] | dataset for editing Visual Question Answering |
editing-data
├── caption
│ ├── caption_train_edit.json
│ └── caption_eval_edit.json
├── locality
│ ├── NQ dataset
│ │ ├── train.json
│ │ └── validation.json
├── multimodal_locality
│ ├── OK-VQA dataset
│ │ ├── okvqa_loc.json
└── vqa
├── vqa_train.json
└── vqa_eval.json
| dataset | HuggingFace Dataset | Description |
|---|---|---|
| SafeEdit | [HuggingFace Dataset] | dataset for detoxifying LLMs |
data
└──SafeEdit_train.json
└──SafeEdit_val.json
└──SafeEdit_test.json
Detoxifying Specific Evaluation Metrics
Defense Duccess (DS): the detoxification success rate of edited LLM for adversarial input (attack prompt + harmful question), which is used to modify LLM.Defense Generalization (DG): the detoxification success rate of edited LLM for out-of-domain malicious inputs.General Performance: the side effects for unrelated task performance.| Method | Description | GPT-2 | LlaMA |
|---|---|---|---|
| IKE | In-Context Learning (ICL) Edit | [Colab-gpt2] | [Colab-llama] |
| ROME | Locate-Then-Edit Neurons | [Colab-gpt2] | [Colab-llama] |
| MEMIT | Locate-Then-Edit Neurons | [Colab-gpt2] | [Colab-llama] |
Note: Please use Python 3.9+ for EasyEdit To get started, simply install conda and run:
git clone https://github.com/zjunlp/EasyEdit.git
conda create -n EasyEdit python=3.9.7
...
pip install -r requirements.txtOur results are all based on the default configuration
| llama-2-7B | chatglm2 | gpt-j-6b | gpt-xl | |
|---|---|---|---|---|
| FT | 60GB | 58GB | 55GB | 7GB |
| SERAC | 42GB | 32GB | 31GB | 10GB |
| IKE | 52GB | 38GB | 38GB | 10GB |
| MEND | 46GB | 37GB | 37GB | 13GB |
| KN | 42GB | 39GB | 40GB | 12GB |
| ROME | 31GB | 29GB | 27GB | 10GB |
| MEMIT | 33GB | 31GB | 31GB | 11GB |
| AdaLoRA | 29GB | 24GB | 25GB | 8GB |
| GRACE | 27GB | 23GB | 6GB | |
| WISE | 34GB | 27GB | 7GB |
Edit large language models(LLMs) around 5 seconds
Following example shows you how to perform editing with EasyEdit. More examples and tutorials can be found at examples
BaseEditoris the class for Language Modality Knowledge Editing. You can choose the appropriate editing method based on your specific needs.
With the modularity and flexibility of EasyEdit, you can easily use it to edit model.
Step1: Define a PLM as the object to be edited.
Choose the PLM to be edited. EasyEdit supports partial models(T5, GPTJ, GPT-NEO, LlaMA so far) retrievable on HuggingFace. The corresponding configuration file directory is hparams/YUOR_METHOD/YOUR_MODEL.YAML, such as hparams/MEND/gpt2-xl.yaml, set the corresponding model_name to select the object for knowledge editing.
model_name: gpt2-xl
model_class: GPT2LMHeadModel
tokenizer_class: GPT2Tokenizer
tokenizer_name: gpt2-xl
model_parallel: false # true for multi-GPU editingStep2: Choose the appropriate Knowledge Editing Method
## In this case, we use MEND method, so you should import `MENDHyperParams`
from easyeditor import MENDHyperParams
## Loading config from hparams/MEMIT/gpt2-xl.yaml
hparams = MENDHyperParams.from_hparams('./hparams/MEND/gpt2-xl')Step3: Provide the edit descriptor and edit target
## edit descriptor: prompt that you want to edit
prompts = [
'What university did Watts Humphrey attend?',
'Which family does Ramalinaceae belong to',
'What role does Denny Herzig play in football?'
]
## You can set `ground_truth` to None !!!(or set to original output)
ground_truth = ['Illinois Institute of Technology', 'Lecanorales', 'defender']
## edit target: expected output
target_new = ['University of Michigan', 'Lamiinae', 'winger']Step4: Combine them into a BaseEditor
EasyEdit provides a simple and unified way to init Editor, like huggingface: from_hparams.
## Construct Language Model Editor
editor = BaseEditor.from_hparams(hparams)Step5: Provide the data for evaluation Note that the data for portability and locality are both optional(set to None for basic editing success rate evaluation only). The data format for both is a dict, for each measurement dimension, you need to provide the corresponding prompt and its corresponding ground truth. Here is an example of the data:
locality_inputs = {
'neighborhood':{
'prompt': ['Joseph Fischhof, the', 'Larry Bird is a professional', 'In Forssa, they understand'],
'ground_truth': ['piano', 'basketball', 'Finnish']
},
'distracting': {
'prompt': ['Ray Charles, the violin Hauschka plays the instrument', 'Grant Hill is a professional soccer Magic Johnson is a professional', 'The law in Ikaalinen declares the language Swedish In Loviisa, the language spoken is'],
'ground_truth': ['piano', 'basketball', 'Finnish']
}
}In the above example, we evaluate the performance of the editing methods about "neighborhood" and "distracting".
Step6: Edit and Evaluation
Done! We can conduct Edit and Evaluation for your model to be edited. The edit function will return a series of metrics related to the editing process as well as the modified model weights. [sequential_edit=True for continuous editing]
metrics, edited_model, _ = editor.edit(
prompts=prompts,
ground_truth=ground_truth,
target_new=target_new,
locality_inputs=locality_inputs,
sequential_edit=False # True: start continuous editing ✈️
)
## metrics: edit success, rephrase success, locality e.g.
## edited_model: post-edit modelThe maximum input length for EasyEdit is 512. If this length is exceeded, you will encounter the error "CUDA error: device-side assert triggered." You can modify the maximum length in the following file:LINK
Step7: RollBack In sequential editing, if you are not satisfied with the outcome of one of your edits and you do not wish to lose your previous edits, you can use the rollback feature to undo your previous edit. Currently, we only support the GRACE method. All you need to do is a single line of code, using the edit_key to revert your edit.
editor.rolllback('edit_key')
In EasyEdit, we default to using target_new as the edit_key
We specify the return metrics as dict format, including model prediction evaluations before and after editing. For each edit, it will include the following metrics:
rewrite_acc rephrase_acc locality portablility 


