graph gpt
v0.4.0
This repository is the official implementation of “GraphGPT: Graph Learning with Generative Pre-trained Transformers” in PyTorch.
GraphGPT: Graph Learning with Generative Pre-trained Transformers
Qifang Zhao, Weidong Ren, Tianyu Li, Xiaoxiao Xu, Hong Liu
10/13/2024
CHANGELOG.md for details.08/18/2024
CHANGELOG.md for details.07/09/2024
03/19/2024
permute_nodes for graph-level map-style dataset, in order to increase variations of Eulerian paths,
and result in better and robust results.StackedGSTTokenizer so that semantics (i.e., node/edge attrs) tokens can be stacked together with structural
tokens, and the length of sequence would be reduced a lot.01/23/2024
01/03/2024

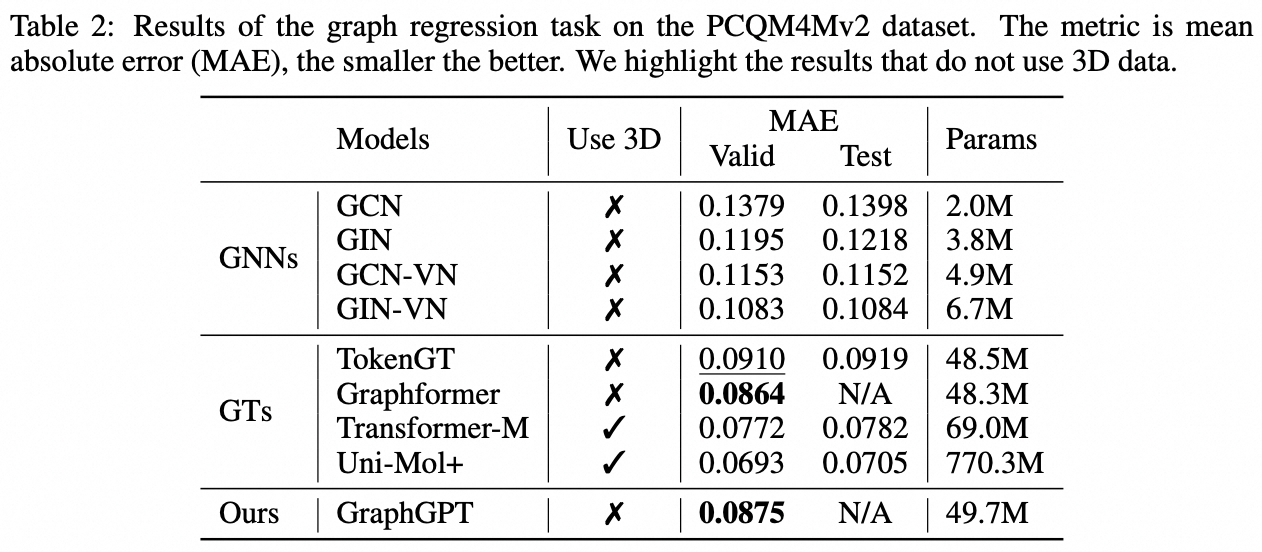
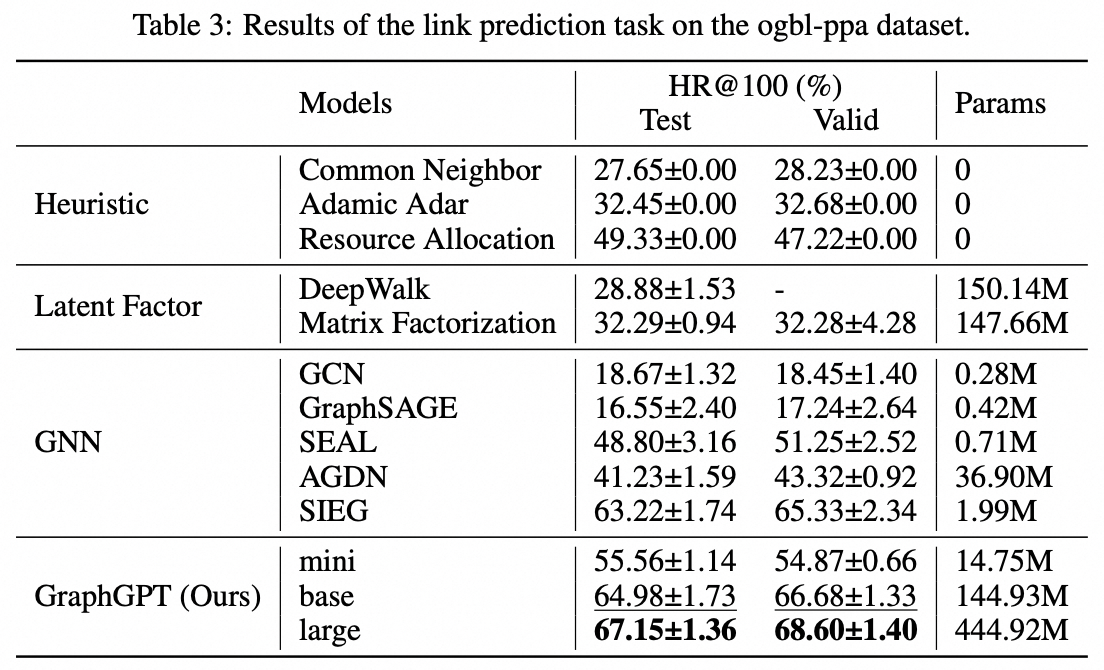
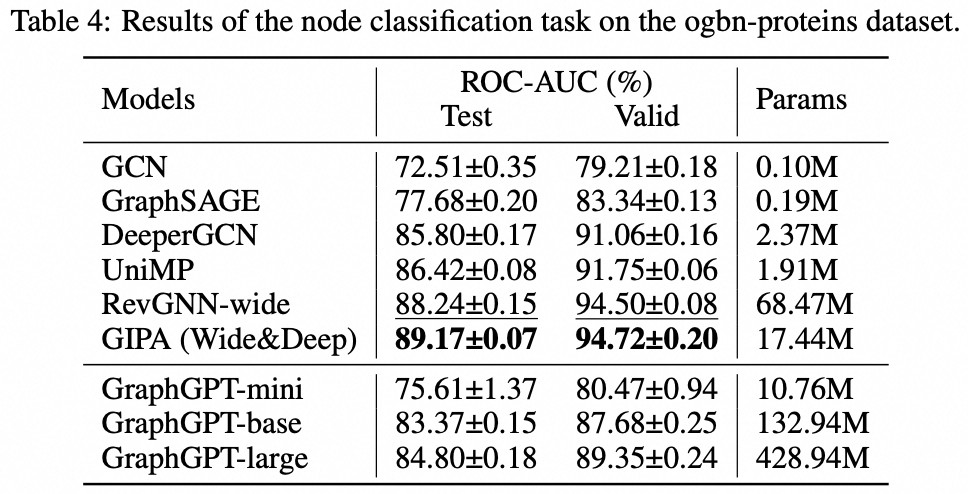
We propose GraphGPT, a novel model for Graph learning by self-supervised Generative Pre-training Graph Eulerian Transformers (GET). We first introduce GET, which consists of a vanilla transformer encoder/decoder backbone and a transformation that turns each graph or sampled subgraph into a sequence of tokens representing the node, edge and attributes reversibly using the Eulerian path. Then we pre-train the GET with either the next-token-prediction (NTP) task or scheduled masked-token-prediction (SMTP) task. Lastly, we fine-tune the model with the supervised tasks. This intuitive, yet effective model achieves superior or close results to the state-of-the-art methods for the graph-, edge- and node-level tasks on the large scale molecular dataset PCQM4Mv2, the protein-protein association dataset ogbl-ppa, citation network dataset ogbl-citation2 and the ogbn-proteins dataset from the Open Graph Benchmark (OGB). Furthermore, the generative pre-training enables us to train GraphGPT up to 2B+ parameters with consistently increasing performance, which is beyond the capability of GNNs and previous graph transformers.
After converting Eulerized graphs to sequences, there are several different ways to attach node and edge attributes to
the sequences. We name these methods as short, long and prolonged.
Given the graph, we Eulerize it first, and then turn it into an equivalent sequence. And then, we re-index the nodes cyclically.
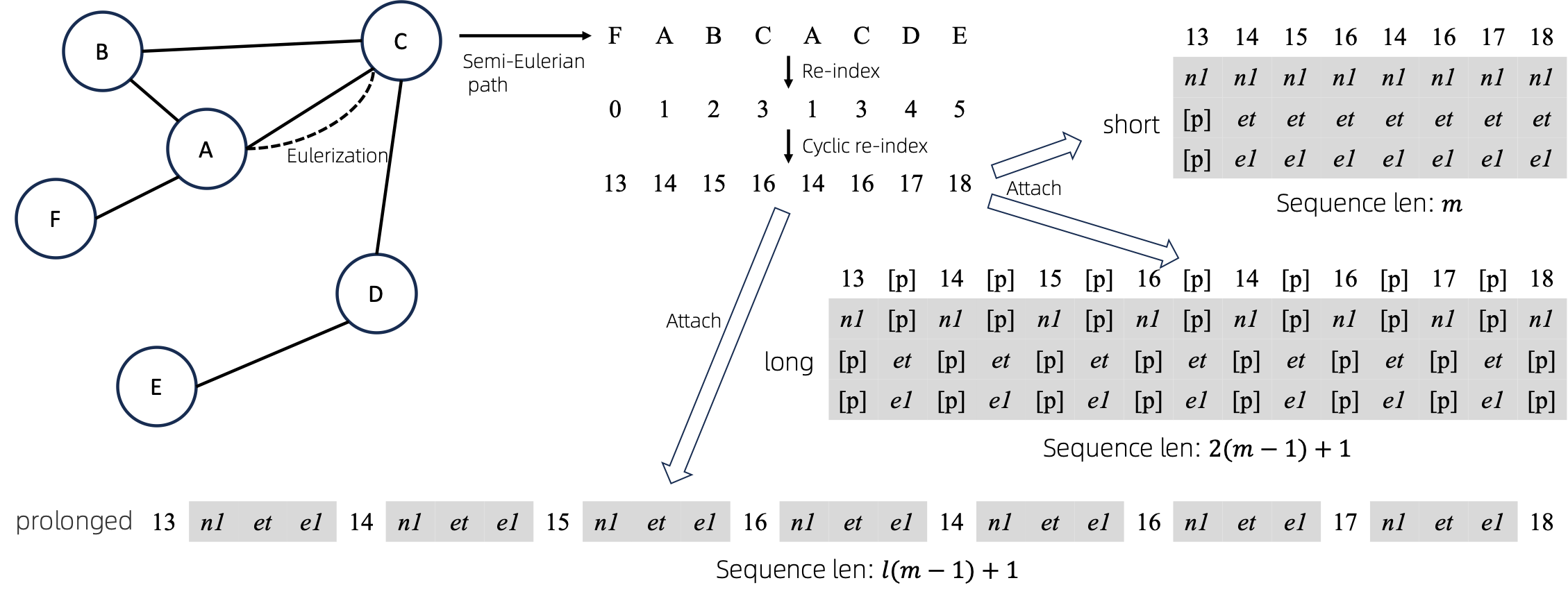
Assume the graph has one node attributes and one edge attributes, and then the short, long and prolong method
are shown above.
In the above figures, n1, n2 and e1 represents the tokens of node and edge attributes, and [p] represents the
padding token.
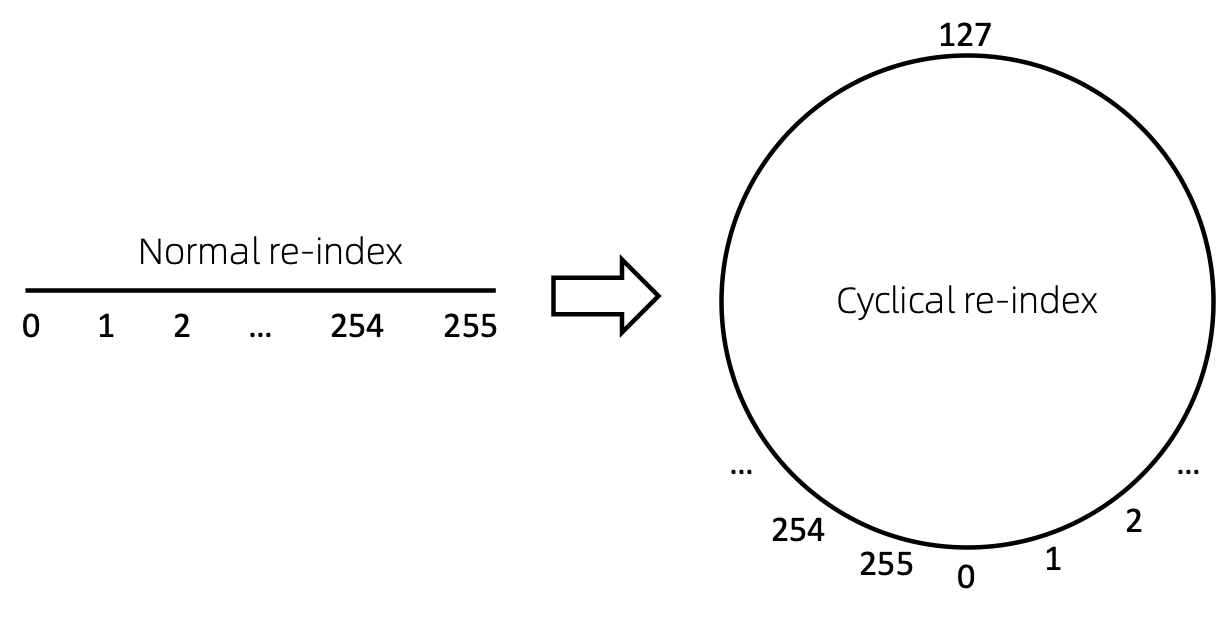
A straightforward way to re-index the sequence of nodes is to start with 0 and add 1 incrementally. By this way, tokens
of small indices will be sufficiently trained, and the large indices won't. To overcome this, we propose
cyclical re-index, which starts with a random number in the given range, say [0, 255], and increment by 1.
After hitting the boundary, e.g., 255, the next node index will be 0.
Outdated. To be updated soon.
git clone https://github.com/alibaba/graph-gpt.gitconda create -n graph_gpt python=3.8 pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.7 -c pytorch -c nvidia
conda activate graph_gpt
cd graph-gpt
pip install -r ./requirements.txt
pip install torch-scatter torch-sparse -f https://data.pyg.org/whl/torch-1.13.1+cpu.html
sudo apt-get install bcThe datasets are downloaded using python package ogb.
When you run scripts in ./examples, the dataset will be automatically downloaded.
However, the dataset PCQM4M-v2 is huge, and downloading and
preprocessing might be problematic. We suggest cd ./src/utils/ and python dataset_utils.py
to download and preprocess dataset separately.
./examples/graph_lvl/pcqm4m_v2_pretrain.sh, e.g., dataset_name, model_name,
batch_size, workerCount and etc, and then run ./examples/graph_lvl/pcqm4m_v2_pretrain.sh to pretrain
the model with the PCQM4M-v2 dataset.
./examples/toy_examples/reddit_pretrain.sh directly../examples/graph_lvl/pcqm4m_v2_supervised.sh, e.g., dataset_name, model_name,
batch_size, workerCount, pretrain_cpt and etc, and then run ./examples/graph_lvl/pcqm4m_v2_supervised.sh
to fine-tune with downstream tasks.
./examples/toy_examples/reddit_supervised.sh directly..pre-commit-config.yaml: create the file with following content for python
repos:
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v4.4.0
hooks:
- id: check-yaml
- id: end-of-file-fixer
- id: trailing-whitespace
- repo: https://github.com/psf/black
rev: 23.7.0
hooks:
- id: blackpre-commit install: install pre-commit into your git hooks.
pre-commit install should always be the first thing you do.pre-commit run --all-files: run all pre-commit hooks on a repositorypre-commit autoupdate: update your hooks to the latest version automaticallygit commit -n: pre-commit checks can be disabled for a particular commit with the commandIf you find this work useful, please kindly cite following papers:
@article{zhao2024graphgpt,
title={GraphGPT: Graph Learning with Generative Pre-trained Transformers},
author={Zhao, Qifang and Ren, Weidong and Li, Tianyu and Xu, Xiaoxiao and Liu, Hong},
journal={arXiv preprint arXiv:2401.00529},
year={2024}
}Qifang Zhao ([email protected])
Sincerely appreciate your suggestions on our work!
Released under the MIT license (see LICENSE):
Ali-GraphGPT-project is an AI project on training large scale transformer decoder with graph datasets,
developed by Alibaba and licensed under the MIT License.


