CDial GPT
1.0.0
This project provides a large-scale Chinese conversation data set and a Chinese conversation pre-training model (Chinese GPT model) on this data set. For more information, please refer to our paper.
The code of this project is modified from TransferTransfo and uses the HuggingFace Pytorch version of the Transformers library, which can be used for pre-training and fine-tuning.
from datasets import load_dataset
dataset = load_dataset ( "lccc" , "base" ) # or "large" The data set LCCC (Large-scale Cleaned Chinese Conversation) we provide mainly consists of two parts: LCCC-base (Baidu Netdisk, Google Drive) and LCCC-large (Baidu Netdisk, Google Drive). We designed a strict Data filtering process to ensure the quality of conversation data in this dataset. This data filtering process includes a series of manual rules and several classifiers based on machine learning algorithms. The noise we filter out includes: dirty words, special characters, facial expressions, grammatically incorrect sentences, context-irrelevant dialogue, etc.
The statistics of this data set are shown in the table below. Among them, we call a dialogue containing only two sentences a "single-turn dialogue", and we call a dialogue containing more than two sentences a "multi-turn dialogue". Use Jieba word segmentation when counting the size of the word list.
| LCCC-base (Baidu Cloud Disk, Google Drive) | one-turn conversation | Multiple rounds of dialogue |
|---|---|---|
| total dialogue turns | 3,354,232 | 3,466,274 |
| Total dialogue sentences | 6,708,464 | 13,365,256 |
| Total characters | 68,559,367 | 163,690,569 |
| Vocabulary size | 372,063 | 666,931 |
| Average number of words in conversational sentences | 6.79 | 8.32 |
| Average number of sentences per conversation round | 2 | 3.86 |
Note that the cleaning process of the LCCC-base dataset is more stringent than that of LCCC-large, so its size is also smaller.
| LCCC-large (Baidu Cloud Disk, Google Drive) | one-turn conversation | Multiple rounds of dialogue |
|---|---|---|
| total dialogue turns | 7,273,804 | 4,733,955 |
| Total dialogue sentences | 14,547,608 | 18,341,167 |
| Total characters | 162,301,556 | 217,776,649 |
| Vocabulary size | 662,514 | 690,027 |
| Number of evaluation words for conversational sentences | 7.45 | 8.14 |
| Average number of sentences per conversation round | 2 | 3.87 |
The original conversation data in the LCCC-base data set comes from Weibo conversations, and the original conversation data in the LCCC-large data set is integrated with other open source conversation data sets based on these Weibo conversations:
| Dataset | total dialogue turns | Conversation example |
|---|---|---|
| Weibo Corpus | 79M | Q: I had hot pot seven or eight times in Chengdu, Chongqing. A: Hahahaha! Then my mouth might rot! |
| PTT Gossiping Corpus | 0.4M | Q: Why do villagers always bully high school students? QQ A: If you think that if you choose a good subject, you will become Bill Gates, then you might as well drop out of school. |
| Subtitle Corpus | 2.74M | Q: People in Beijing opera are not free. A: They put people in cages. |
| Xiaohuangji Corpus | 0.45M | Q: Have you ever been in love? A: Have you ever been in love? Oh, don’t mention it, I’m sad... |
| Tieba Corpus | 2.32M | Q: Front row, all the Lu fans are getting up, right? A: The title says assists, but after watching that ball, it’s really a living irony. |
| Qingyun Corpus | 0.1M | Q: It seems you love money very much. A: Oh, really? Then you're almost there |
| Douban Conversation Corpus | 0.5M | Q: Learn pure English by watching original English movies A: I love Friends and have watched it many times Q: I’m almost exhausted watching the same CD A: Then your English should be pretty good now |
| E-commerical Conversation Corpus | 0.5M | Q: Will this be a good deal? A: Not yet. Q: Will it be available in the future? A: Not sure. Please pay attention to us. |
| Chinese Chat Corpus | 0.5M | Q: My legs are useless today. You guys are celebrating the holiday, so I’ll move bricks. A: It’s hard work. I even went to make a lot of money on Christmas. Come on. Q: After all, I don’t have a boyfriend, so any holiday is the same. |
We also provide a series of Chinese pre-training models (Chinese GPT models). The pre-training process of these models is divided into two steps, first pre-training on a Chinese novel data, and then pre-training on the LCCC data set.
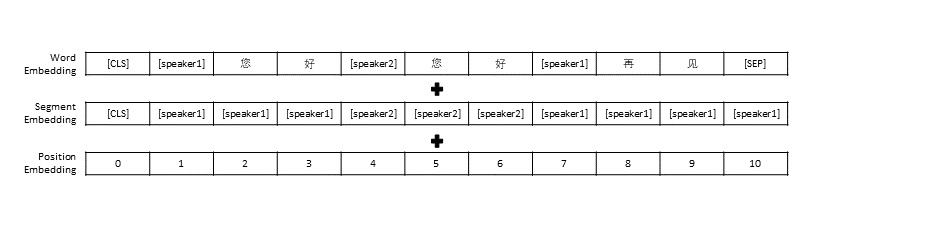
We followed the data preprocessing settings in TransferTransfo, which spliced all the conversation history into one sentence, and then used this sentence as the input of the model to predict the conversation reply. In addition to the vector representation of each word, the input of our model also includes the speaker vector representation and the position vector representation.
| Pre-trained model | Number of parameters | Data used for pre-training | describe |
|---|---|---|---|
| GPT Novel | 95.5M | Chinese novel data | Chinese pre-trained GPT model built based on Chinese novel data (the novel data includes a total of 1.3B words) |
| CDial-GPT LCCC-base | 95.5M | LCCC-base | Based on GPT Novel , use the Chinese pre-trained GPT model trained by LCCC-base |
| CDial-GPT2 LCCC-base | 95.5M | LCCC-base | Based on GPT Novel , use the Chinese pre-trained GPT2 model trained with LCCC-base |
| CDial-GPT LCCC-large | 95.5M | LCCC-large | Based on GPT Novel , use the Chinese pre-trained GPT model trained by LCCC-large |
Install directly from source:
git clone https://github.com/thu-coai/CDial-GPT.git
cd CDial-GPT
pip install -r requirements.txt
Step 1: Prepare the data set required for pre-training model and fine-tuning (such as STC dataset or toy data "data/toy_data.json" in the project directory. Please note that if the data contains English, it must be separated by letters, such as: hello)
# 下载 STC 数据集 中的训练集和验证集 并将其解压至 "data_path" 目录 (如果微调所使用的数据集为 STC)
git lfs install
git clone https://huggingface.co/thu-coai/CDial-GPT_LCCC-large # 您可自行下载模型或者OpenAIGPTLMHeadModel.from_pretrained("thu-coai/CDial-GPT_LCCC-large")
ps: You can use the following links to download the training set and verification set of STC (Baidu Cloud Disk, Google Drive)
Step 2: Train the model
python train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # 使用单个GPU进行训练
or
python -m torch.distributed.launch --nproc_per_node=8 train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # 以分布式的方式在8块GPU上训练
The train_path parameter is also provided in our training script, which allows users to read plain text files in slices. If you are using a system with limited memory, consider using this parameter to read in training data. If you use train_path you need to leave data_path empty.
Step 3: Generate text
# YOUR_MODEL_PATH: 你要使用的模型的路径,每次微调后的模型目录保存在./runs/中
python infer.py --model_checkpoint YOUR_MODEL_PATH --datapath data/STC_test.json --out_path STC_result.txt # 在测试数据上生成回复
python interact.py --model_checkpoint YOUR_MODEL_PATH # 在命令行中与模型进行交互
ps: You can use the following link to download the STC test set (Baidu Cloud Disk, Google Drive)
Training script parameters
| parameter | type | default value | describe |
|---|---|---|---|
| model_checkpoint | str | "" | Path or URL of model files (Directory of pre-training model and config/vocab files) |
| pretrained | bool | False | If False, then train the model from scratch |
| data_path | str | "" | Path of the dataset |
| dataset_cache | str | default="dataset_cache" | Path or url of the dataset cache |
| train_path | str | "" | Path of the training set for distributed dataset |
| valid_path | str | "" | Path of the validation set for distributed dataset |
| log_file | str | "" | Output logs to a file under this path |
| num_workers | int | 1 | Number of subprocesses for data loading |
| n_epochs | int | 70 | Number of training epochs |
| train_batch_size | int | 8 | Batch size for training |
| valid_batch_size | int | 8 | Batch size for validation |
| max_history | int | 15 | Number of previous exchanges to keep in history |
| scheduler | str | "noam" | Method of optimizer |
| n_emd | int | 768 | Number of n_emd in config file (for noam) |
| eval_before_start | bool | False | If true, start evaluation before training |
| warmup_steps | int | 5000 | Warm up steps |
| valid_steps | int | 0 | Perform validation every X steps, if is not 0 |
| gradient_accumulation_steps | int | 64 | Accumulate gradients on several steps |
| max_norm | float | 1.0 | Clipping gradient norm |
| device | str | "cuda" if torch.cuda.is_available() else "cpu" | Device (cuda or cpu) |
| fp16 | str | "" | Set to O0, O1, O2 or O3 for fp16 training (see apex documentation) |
| local_rank | int | -1 | Local rank for distributed training (-1: not distributed) |
We evaluated the dialogue pre-training model fine-tuned using the STC data set (training set/validation set (Baidu Netdisk, Google Drive), test set (Baidu Netdisk, Google Drive)). All responses were sampled using Nucleus Sampling (p=0.9, temperature=0.7).
| Model | Model size | PPL | BLEU-2 | BLEU-4 | Dist-1 | Dist-2 | Greedy Matching | Embedding Average |
|---|---|---|---|---|---|---|---|---|
| Attn-Seq2seq | 73M | 34.20 | 3.93 | 0.90 | 8.5 | 11.91 | 65.84 | 83.38 |
| Transformer | 113M | 22.10 | 6.72 | 3.14 | 8.8 | 13.97 | 66.06 | 83.55 |
| GPT2-chitchat | 88M | - | 2.28 | 0.54 | 10.3 | 16.25 | 61.54 | 78.94 |
| GPT Novel | 95.5M | 21.27 | 5.96 | 2.71 | 8.0 | 11.72 | 66.12 | 83.34 |
| GPT LCCC-base | 95.5M | 18.38 | 6.48 | 3.08 | 8.3 | 12.68 | 66.21 | 83.54 |
| GPT2 LCCC-base | 95.5M | 22.76 | 5.69 | 2.50 | 7.7 | 10.87 | 66.24 | 83.46 |
| GPT LCCC-large | 95.5M | 18.23 | 6.63 | 3.20 | 8.3 | 12.71 | 66.25 | 83.63 |
We sampled 200 responses for each model and invited three annotators on the outsourcing platform to manually evaluate these responses. The evaluation dimensions were conversational fluency, contextual relevance, and response diversity. The scoring range for each dimension is 2/1/0. Please refer to our paper for more details.
| Model | +2 | +1 | +0 | Kappa |
|---|---|---|---|---|
| Attn-Seq2Seq | 27.1% | 21.4% | 51.4% | 0.4544 |
| Transformer | 42.4% | 23.6% | 34.0% | 0.4429 |
| GPT2-chitchat | 24.3% | 19,1% | 56.6% | 0.3941 |
| GPT LCCC-base | 46.7% | 21.8% | 31.5% | 0.3954 |
| GPT LCCC-large | 48.6% | 24.5% | 27.0% | 0.4203 |
We randomly sampled 1,000 conversation replies and counted the bad replies among these replies:
| Contains repeated statements | Contains curse words | Other bad replies |
|---|---|---|
| twenty three | 9 | 2 |
We fine-tuned the parameters of the GPT LCCC-large model on the STC dataset, and used this fine-tuned model to generate the following conversation example:
| Post | Response |
|---|---|
| This is actually Beijing, not Harbin. | The weather in Harbin seems to be better than that in Beijing. It rains lightly here and there are strong winds during the day. |
| The operator’s campus advertising competition was so fun! Hahaha. | I thought it was Jack Ma's advertisement. |
| Delsa S posa candy color series wedding dress, pink, blue, red and purple, playful and fresh, do you like it? | The last one is so beautiful, so beautiful! |
We also used the above fine-tuned model to obtain the following interaction results:
| Roel | Response |
|---|---|
| User | Don't love me to no avail |
| Bot | Fruitless love is so painful. |
| User | But it’s okay if you’ve loved it |
| Bot | Sometimes, love is a game. |
| User | I always lose |
| Bot | I love you as much as I love you. |
| User | Can you pull it? |
| Bot | You can pull it. |
| User | Don't imitate me |
| Bot | What I'm saying is that you can't do it. |
| User | You force me to do it, right? |
| Bot | No, I am forcing you to speak, right? |
Yida Wang, Pei Ke, Yinhe Zheng, Kaili Huang, Yong Jiang, Xiaoyan Zhu, Minlie Huang
Zuoxian Ye, Yao Wang, Yifan Pan
The LCCC data set and pre-trained dialogue model provided by this project are for scientific research purposes only. The conversations in the LCCC data set are collected from different sources. Although we have designed a strict data cleaning process, we do not guarantee that all inappropriate content has been filtered. All content and opinions contained in this data are independent of the authors of this project. The model and code provided in this project are only a component of the complete dialogue system. The decoding scripts we provide are for scientific research purposes only. All dialogue content generated using the models and scripts in this project has nothing to do with the author of this project.
If you find our project helpful, please cite our paper:
@inproceedings{wang2020chinese,
title={A Large-Scale Chinese Short-Text Conversation Dataset},
author={Wang, Yida and Ke, Pei and Zheng, Yinhe and Huang, Kaili and Jiang, Yong and Zhu, Xiaoyan and Huang, Minlie},
booktitle={NLPCC},
year={2020},
url={https://arxiv.org/abs/2008.03946}
}
This project provides a large-scale cleaned Chinese conversation dataset and a Chinese GPT model pre-trained on this dataset. Please refer to our paper for more details.
Our code used for the pre-training is adapted from the TransferTransfo model based on the Transformers library. The codes used for both pre-training and fine-tuning are provided in this repository.
We present a Large-scale Cleaned Chinese Conversation corpus (LCCC) containing: LCCC-base (Baidu Netdisk, Google Drive) and LCCC-large (Baidu Netdisk, Google Drive). A rigorous data cleaning pipeline is designed to ensure the quality of the corpus. This pipeline involves a set of rules and several classifier-based filters. Noises such as offensive or sensitive words, special symbols, emojis, grammatically incorrect sentences, and incoherent conversations are filtered.
The statistic of our corpus is presented below. Dialogues with only two utterances are regarded as "Single-turn", and dialogues with more than three utterances are regarded as "Multi-turn". The vocabulary size is calculated in word-level, and Jieba is used to tokenize each utterance to words.
| LCCC-base (Baidu Netdisk, Google Drive) | Single-turn | Multi-turn |
|---|---|---|
| Sessions | 3,354,382 | 3,466,607 |
| Utterances | 6,708,554 | 13,365,268 |
| Characters | 68,559,727 | 163,690,614 |
| Vocabulary | 372,063 | 666,931 |
| Avg. words per utterance | 6.79 | 8.32 |
| Avg. utterances per session | 2 | 3.86 |
Note that LCCC-base is cleaned using more strict rules compared to LCCC-large.
| LCCC-large (Baidu Netdisk, Google Drive) | Single-turn | Multi-turn |
|---|---|---|
| Sessions | 7,273,804 | 4,733,955 |
| Utterances | 14,547,608 | 18,341,167 |
| Characters | 162,301,556 | 217,776,649 |
| Vocabulary | 662,514 | 690,027 |
| Avg. words per utterance | 7.45 | 8.14 |
| Avg. utterances per session | 2 | 3.87 |
The raw dialogues for LCCC-base originate from a Weibo Corpus that we crawled from Weibo, and the raw dialogues for LCCC-large is built by combining several conversation datasets in addition to the Weibo Corpus:
| Dataset | Sessions | Sample |
|---|---|---|
| Weibo Corpus | 79M | Q: I had hot pot seven or eight times in Chengdu, Chongqing. A: Hahahaha! Then my mouth might rot! |
| PTT Gossiping Corpus | 0.4M | Q: Why do villagers always bully high school students? QQ A: If you think that if you choose a good subject, you will become Bill Gates, then you might as well drop out of school. |
| Subtitle Corpus | 2.74M | Q: People in Beijing opera are not free. A: They put people in cages. |
| Xiaohuangji Corpus | 0.45M | Q: Have you ever been in love? A: Have you ever been in love? Oh, don’t mention it, I’m sad... |
| Tieba Corpus | 2.32M | Q: Front row, all the Lu fans are getting up, right? A: The title says assists, but after watching that ball, it’s really a living irony. |
| Qingyun Corpus | 0.1M | Q: It seems you love money very much. A: Oh, really? Then you're almost there |
| Douban Conversation Corpus | 0.5M | Q: Learn pure English by watching original English movies A: I love Friends and have watched it many times Q: I’m almost exhausted watching the same CD A: Then your English should be pretty good now |
| E-commerical Conversation Corpus | 0.5M | Q: Will this be a good deal? A: Not yet. Q: Will it be available in the future? A: Not sure. Please pay attention to us. |
| Chinese Chat Corpus | 0.5M | Q: My legs are useless today. You guys are celebrating the holiday, so I’ll move bricks. A: It’s hard work. I even went to make a lot of money on Christmas. Come on. Q: After all, I don’t have a boyfriend, so any holiday is the same. |
We also present a series of Chinese GPT model that are first pre-trained on a Chinese novel dataset and then post-trained on our LCCC dataset.
Similar to TransferTransfo, we concatenate all dialogue histories into one context sentence, and use this sentence to predict the response. The input of our model consists of word embedding, speaker embedding, and positional embedding of each word.
| Models | Parameter Size | Pre-training Dataset | Description |
|---|---|---|---|
| GPT Novel | 95.5M | Chinese Novel | A GPT model pre-trained on Chinese Novel dataset (1.3B words, note that we do not provide the detail of this model) |
| CDial-GPT LCCC-base | 95.5M | LCCC-base | A GPT model post-trained on LCCC-base dataset from GPT Novel |
| CDial-GPT2 LCCC-base | 95.5M | LCCC-base | A GPT2 model post-trained on LCCC-base dataset from GPT Novel |
| CDial-GPT LCCC-large | 95.5M | LCCC-large | A GPT model post-trained on LCCC-large dataset from GPT Novel |
Install from the source codes:
git clone https://github.com/thu-coai/CDial-GPT.git
cd CDial-GPT
pip install -r requirements.txt
Step 1: Prepare the data for fine-tuning (Eg, STC dataset or "data/toy_data.json" in our respository) and the pre-trianed model:
# Download the STC dataset and unzip into "data_path" dir (fine-tuning on STC)
git lfs install
git clone https://huggingface.co/thu-coai/CDial-GPT_LCCC-large # or OpenAIGPTLMHeadModel.from_pretrained("thu-coai/CDial-GPT_LCCC-large")
ps: You can download the train and valid split of STC from the following links: (Baidu Netdisk, Google Drive)
Step 2: Train the model
python train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # Single GPU training
or
python -m torch.distributed.launch --nproc_per_node=8 train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # Training on 8 GPUs
Note: We have also provided train_path argument in the training script to read dataset in plain text, which will be sliced and handled distributionally. You can consider to use this argument if the dataset is too large for your system's memory. (also, remember to leave the data_path argument empty if you are using train_path ).
Step 3: Inference mode
# YOUR_MODEL_PATH: the model path used for generation
python infer.py --model_checkpoint YOUR_MODEL_PATH --datapath data/STC_test.json --out_path STC_result.txt # Do Inference on a corpus
python interact.py --model_checkpoint YOUR_MODEL_PATH # Interact on the terminal
ps: You can download the test split of STC from the following links: (Baidu Netdisk, Google Drive)
Training Arguments
| Arguments | Type | Default value | Description |
|---|---|---|---|
| model_checkpoint | str | "" | Path or URL of model files (Directory of pre-training model and config/vocab files) |
| pretrained | bool | False | If False, then train the model from scratch |
| data_path | str | "" | Path of the dataset |
| dataset_cache | str | default="dataset_cache" | Path or url of the dataset cache |
| train_path | str | "" | Path of the training set for distributed dataset |
| valid_path | str | "" | Path of the validation set for distributed dataset |
| log_file | str | "" | Output logs to a file under this path |
| num_workers | int | 1 | Number of subprocesses for data loading |
| n_epochs | int | 70 | Number of training epochs |
| train_batch_size | int | 8 | Batch size for training |
| valid_batch_size | int | 8 | Batch size for validation |
| max_history | int | 15 | Number of previous exchanges to keep in history |
| scheduler | str | "noam" | Method of optimizer |
| n_emd | int | 768 | Number of n_emd in config file (for noam) |
| eval_before_start | bool | False | If true, start evaluation before training |
| warmup_steps | int | 5000 | Warm up steps |
| valid_steps | int | 0 | Perform validation every X steps, if is not 0 |
| gradient_accumulation_steps | int | 64 | Accumulate gradients on several steps |
| max_norm | float | 1.0 | Clipping gradient norm |
| device | str | "cuda" if torch.cuda.is_available() else "cpu" | Device (cuda or cpu) |
| fp16 | str | "" | Set to O0, O1, O2 or O3 for fp16 training (see apex documentation) |
| local_rank | int | -1 | Local rank for distributed training (-1: not distributed) |
Evaluation is performed on results generated by models fine-tuned on
STC dataset (Train/Valid split (Baidu Netdisk, Google Drive), Test split (Baidu Netdisk, Google Drive)). All responses are generated using the Nucleus Sampling scheme with a threshold 0.9 and temperature 0.7.
| Models | Model Size | PPL | BLEU-2 | BLEU-4 | Dist-1 | Dist-2 | Greedy Matching | Embedding Average |
|---|---|---|---|---|---|---|---|---|
| Attn-Seq2seq | 73M | 34.20 | 3.93 | 0.90 | 8.5 | 11.91 | 65.84 | 83.38 |
| Transformer | 113M | 22.10 | 6.72 | 3.14 | 8.8 | 13.97 | 66.06 | 83.55 |
| GPT2-chitchat | 88M | - | 2.28 | 0.54 | 10.3 | 16.25 | 61.54 | 78.94 |
| GPT Novel | 95.5M | 21.27 | 5.96 | 2.71 | 8.0 | 11.72 | 66.12 | 83.34 |
| GPT LCCC-base | 95.5M | 18.38 | 6.48 | 3.08 | 8.3 | 12.68 | 66.21 | 83.54 |
| GPT2 LCCC-base | 95.5M | 22.76 | 5.69 | 2.50 | 7.7 | 10.87 | 66.24 | 83.46 |
| GPT LCCC-large | 95.5M | 18.23 | 6.63 | 3.20 | 8.3 | 12.71 | 66.25 | 83.63 |
We also employed 3 crowd-sourced annotators to evaluate 200 samples of each model about fluency, relevance, and diversity based on a 2/1/0 score schema. Refer to our paper for more details.
| Models | +2 | +1 | +0 | Kappa |
|---|---|---|---|---|
| Attn-Seq2Seq | 27.1% | 21.4% | 51.4% | 0.4544 |
| Transformer | 42.4% | 23.6% | 34.0% | 0.4429 |
| GPT2-chitchat | 24.3% | 19,1% | 56.6% | 0.3941 |
| GPT LCCC-base | 46.7% | 21.8% | 31.5% | 0.3954 |
| GPT LCCC-large | 48.6% | 24.5% | 27.0% | 0.4203 |
We randomly select 1000 generated samples, and make a statistic of toxic generation:
| Repetition | Dirty word | Other Bad Cases |
|---|---|---|
| twenty three | 9 | 2 |
Single-turn generated examples from STC dataset (fine-tuned on STC):
| Post | Response |
|---|---|
| This is actually Beijing, not Harbin. | The weather in Harbin seems to be better than that in Beijing. It rains lightly here and there are strong winds during the day. |
| The operator’s campus advertising competition was so fun! Hahaha. | I thought it was Jack Ma's advertisement. |
| Delsa S posa candy color series wedding dress, pink, blue, red and purple, playful and fresh, do you like it? | The last one is so beautiful, so beautiful! |
Multi-turn generated examples using the interactive script:
| Roel | Response |
|---|---|
| User | Don't love me to no avail |
| Bot | Fruitless love is so painful. |
| User | But it’s okay if you’ve loved it |
| Bot | Sometimes, love is a game. |
| User | I always lose |
| Bot | I love you as much as I love you. |
| User | Can you pull it? |
| Bot | You can pull it. |
| User | Don't imitate me |
| Bot | What I'm saying is that you can't do it. |
| User | You force me to do it, right? |
| Bot | No, I am forcing you to speak, right? |
Yida Wang, Pei Ke, Yinhe Zheng, Kaili Huang, Yong Jiang, Xiaoyan Zhu, Minlie Huang
Zuoxian Ye, Yao Wang, Yifan Pan
The LCCC dataset and the pre-trained models aim to facilitate the research for conversation generation. The LCCC dataset provided in this repository originates from various sources. Although a rigorous cleaning process has been carried out, there is no guarantee that all the inappropriate contents have been completely filtered out. All the contents contained in this dataset does not represent the authors' opinion. This repository contains only part of the modeling machinery needed to actually produce a dialogue model. The decoding script provided in this repository is only for the research purpose . We are not responsible for any contents generated using our model.
Please kindly cite our paper if you use the datasets or models in your research:
@inproceedings{wang2020chinese,
title={A Large-Scale Chinese Short-Text Conversation Dataset},
author={Wang, Yida and Ke, Pei and Zheng, Yinhe and Huang, Kaili and Jiang, Yong and Zhu, Xiaoyan and Huang, Minlie},
booktitle={NLPCC},
year={2020},
url={https://arxiv.org/abs/2008.03946}
}


