YAYI2
1.0.0

[README] [?HF Repo] [?Web version]
Chinese | English
[2024.03.28] All models and data are uploaded to the Magic Community.
[2023.12.22] We released the technical report YAYI 2: Multilingual Open-Source Large Language Models.
YAYI 2 is a new generation of open source large language model developed by Zhongke Wenge, including Base and Chat versions, with a parameter size of 30B. YAYI2-30B is a large language model based on Transformer, which uses high-quality, multi-language corpus of more than 2 trillion Tokens for pre-training. For general and domain-specific application scenarios, we use millions of instructions for fine-tuning, and use human feedback reinforcement learning methods to better align the model with human values.
The open source model this time is the YAYI2-30B Base model. We hope to promote the development of the Chinese pre-trained large model open source community through the open source of Yayi large models, and actively contribute to this. Through open source, we work with every partner to build the Yayi large model ecosystem.
For more technical details, please read our technical report YAYI 2: Multilingual Open-Source Large Language Models.
| Data set name | size | ? HF model identification | Download address | Magic model logo | Download address |
|---|---|---|---|---|---|
| YAYI2 Pretrain Data | 500G | wenge-research/yayi2_pretrain_data | Data set download | wenge-research/yayi2_pretrain_data | Data set download |
| Model name | context length | ? HF model identification | Download address | Magic model logo | Download address |
|---|---|---|---|---|---|
| YAYI2-30B | 4096 | wenge-research/yayi2-30b | Model download | wenge-research/yayi2-30b | Model download |
| YAYI2-30B-Chat | 4096 | wenge-research/yayi2-30b-chat | Coming soon... |
We conducted evaluations on multiple benchmark data sets, including C-Eval, MMLU, CMMLU, AGIEval, GAOKAO-Bench, GSM8K, MATH, BBH, HumanEval and MBPP. We examined the model's performance in language understanding, subject knowledge, mathematical reasoning, logical reasoning, and code generation. The YAYI 2 model demonstrates significant performance improvements over open source models of similar size.
| subject knowledge | math | logical reasoning | code | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Model | C-Eval(val) | MMLU | AGIEval | CMMLU | GAOKAO-Bench | GSM8K | MATH | BBH | HumanEval | MBPP |
| 5-shot | 5-shot | 3/0-shot | 5-shot | 0-shot | 8/4-shot | 4-shot | 3-shot | 0-shot | 3-shot | |
| MPT-30B | - | 46.9 | 33.8 | - | - | 15.2 | 3.1 | 38.0 | 25.0 | 32.8 |
| Falcon-40B | - | 55.4 | 37.0 | - | - | 19.6 | 5.5 | 37.1 | 0.6 | 29.8 |
| LLaMA2-34B | - | 62.6 | 43.4 | - | - | 42.2 | 6.2 | 44.1 | 22.6 | 33.0 |
| Baichuan2-13B | 59.0 | 59.5 | 37.4 | 61.3 | 45.6 | 52.6 | 10.1 | 49.0 | 17.1 | 30.8 |
| Qwen-14B | 71.7 | 67.9 | 51.9 | 70.2 | 62.5 | 61.6 | 25.2 | 53.7 | 32.3 | 39.8 |
| InternLM-20B | 58.8 | 62.1 | 44.6 | 59.0 | 45.5 | 52.6 | 7.9 | 52.5 | 25.6 | 35.6 |
| Aquila2-34B | 98.5 | 76.0 | 43.8 | 78.5 | 37.8 | 50.0 | 17.8 | 42.5 | 0.0 | 41.0 |
| Yi-34B | 81.8 | 76.3 | 56.5 | 82.6 | 68.3 | 67.6 | 15.9 | 66.4 | 26.2 | 38.2 |
| YAYI2-30B | 80.9 | 80.5 | 62.0 | 84.0 | 64.4 | 71.2 | 14.8 | 54.5 | 53.1 | 45.8 |
We conducted our evaluation using the source code provided by the OpenCompass Github repository. For comparison models, we list their evaluation results on the OpenCompass list, as of December 15, 2023. For other models that have not participated in the evaluation on the OpenCompass platform, including MPT, Falcon and LLaMa 2, we adopted the results reported by LLaMA 2.
We provide simple examples to illustrate how to quickly use YAYI2-30B for inference. This example can be run on a single A100/A800.
git clone https://github.com/wenge-research/YAYI2.git
cd YAYI2conda create --name yayi_inference_env python=3.8
conda activate yayi_inference_envPlease note that this project requires Python 3.8 or higher.
pip install transformers==4.33.1
pip install torch==2.0.1
pip install sentencepiece==0.1.99
pip install accelerate==0.25.0
>> > from transformers import AutoModelForCausalLM , AutoTokenizer
>> > tokenizer = AutoTokenizer . from_pretrained ( "wenge-research/yayi2-30b" , trust_remote_code = True )
>> > model = AutoModelForCausalLM . from_pretrained ( "wenge-research/yayi2-30b" , device_map = "auto" , trust_remote_code = True )
>> > inputs = tokenizer ( 'The winter in Beijing is' , return_tensors = 'pt' )
>> > inputs = inputs . to ( 'cuda' )
>> > pred = model . generate (
** inputs ,
max_new_tokens = 256 ,
eos_token_id = tokenizer . eos_token_id ,
do_sample = True ,
repetition_penalty = 1.2 ,
temperature = 0.4 ,
top_k = 100 ,
top_p = 0.8
)
>> > print ( tokenizer . decode ( pred . cpu ()[ 0 ], skip_special_tokens = True ))When you visit for the first time, the model needs to be downloaded and loaded, which may take some time.
This project supports instruction fine-tuning based on the distributed training framework deepspeed. Configure the environment and execute the corresponding script to start full-parameter fine-tuning or LoRA fine-tuning.
conda create --name yayi_train_env python=3.10
conda activate yayi_train_envpip install -r requirements.txtpip install --upgrade acceleratepip install flash-attn==2.0.3 --no-build-isolation
pip install triton==2.0.0.dev20221202 --no-deps Data format: refer to data/yayi_train_example.json , which is a standard JSON file. Each piece of data consists of "system" and "conversations" , where "system" is the global role setting information and can be an empty string. "conversations" is Multiple rounds of dialogue between human and yayi characters.
Operation instructions: Run the following command to start full-parameter fine-tuning of the Yayi model. This command supports multi-machine and multi-card training. It is recommended to use 16*A100 (80G) or above hardware configuration.
deepspeed --hostfile config/hostfile
--module training.trainer_yayi2
--report_to " tensorboard "
--data_path " ./data/yayi_train_example.json "
--model_name_or_path " your_model_path "
--output_dir " ./output "
--model_max_length 2048
--num_train_epochs 1
--per_device_train_batch_size 1
--gradient_accumulation_steps 1
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 500
--save_total_limit 10
--learning_rate 5e-6
--warmup_steps 2000
--lr_scheduler_type cosine
--logging_steps 1
--gradient_checkpointing True
--deepspeed " ./config/deepspeed.json "
--bf16 True Or start via command line:
bash scripts/start.sh Please note that if you need to use the ChatML template for instruction fine-tuning, you can change --module training.trainer_yayi2 in the command to --module training.trainer_chatml ; if you need to customize the Chat template, you can modify the system in the Chat template of trainer_chatml.py Special token definitions for the three roles of , user, and assistant. The following is an example of a ChatML template. If this template or a custom template is used during training, it also needs to be consistent during inference.
<|im_start|>system
You are a helpful and harmless assistant named YAYI.<|im_end|>
<|im_start|>user
Hello!<|im_end|>
<|im_start|>assistant
Hello! How can I assist you today?<|im_end|>
<|im_start|>user
1+1=<|im_end|>
<|im_start|>assistant
1+1 equals 2.<|im_end|>
bash scripts/start_lora.sh In the pre-training stage, we not only used Internet data to train the model's language ability, but also added general selected data and domain data to enhance the model's professional skills. The data distribution is as follows: 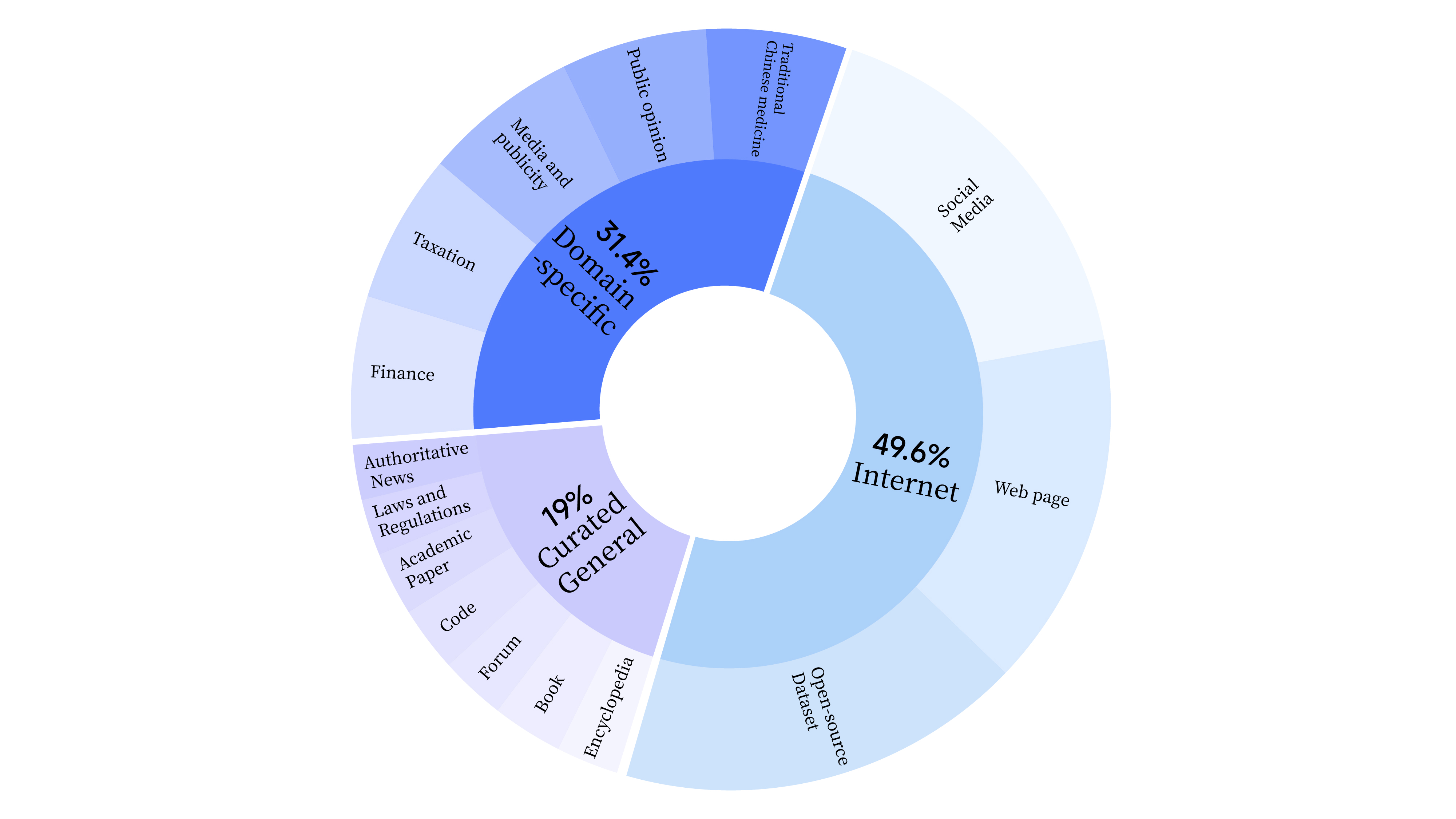
We have built a set of data processing pipelines to improve data quality in all aspects, including four modules: standardization, heuristic cleaning, multi-level deduplication, and toxicity filtering. We collected a total of 240TB of raw data, and only 10.6TB of high-quality data remained after preprocessing. The overall process is as follows: 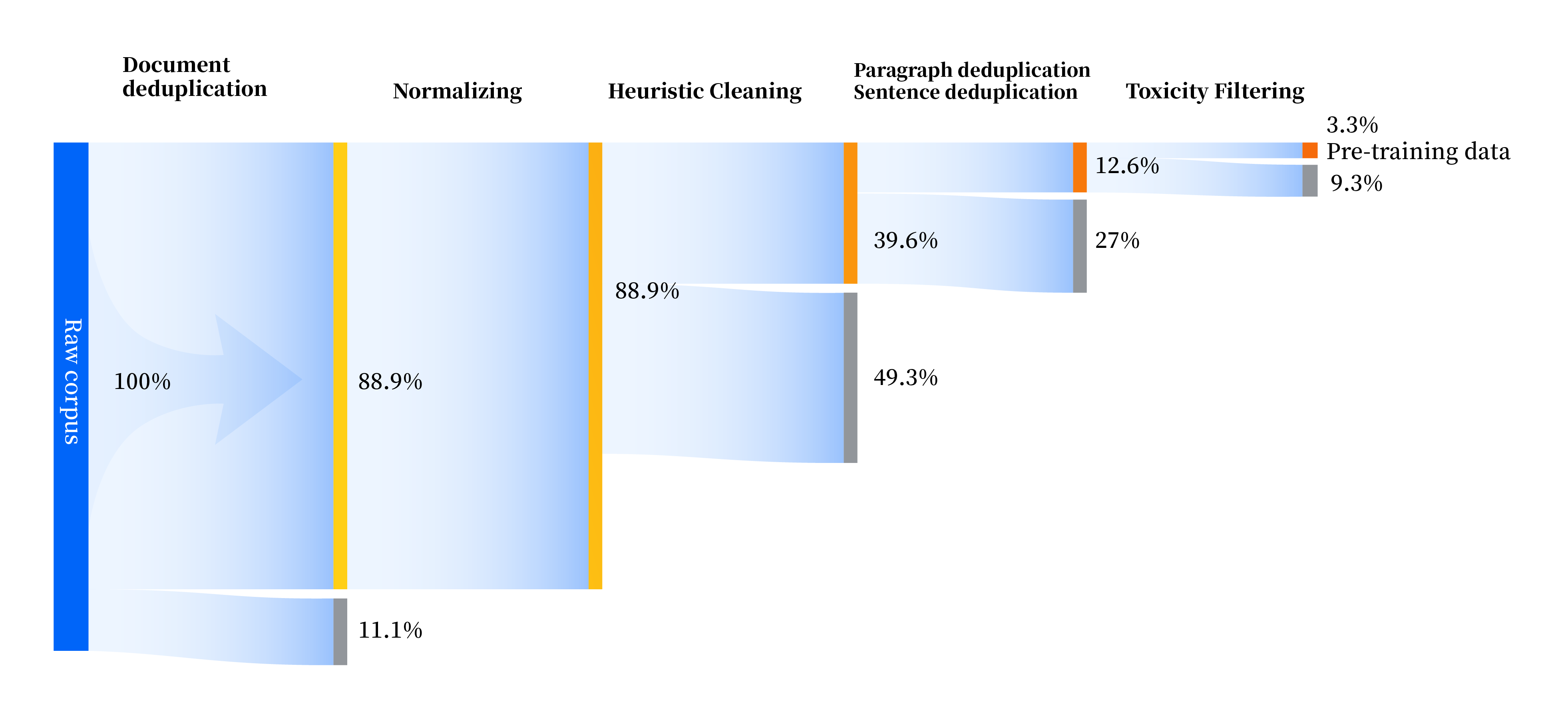

The loss curve of the YAYI 2 model is shown in the figure below: 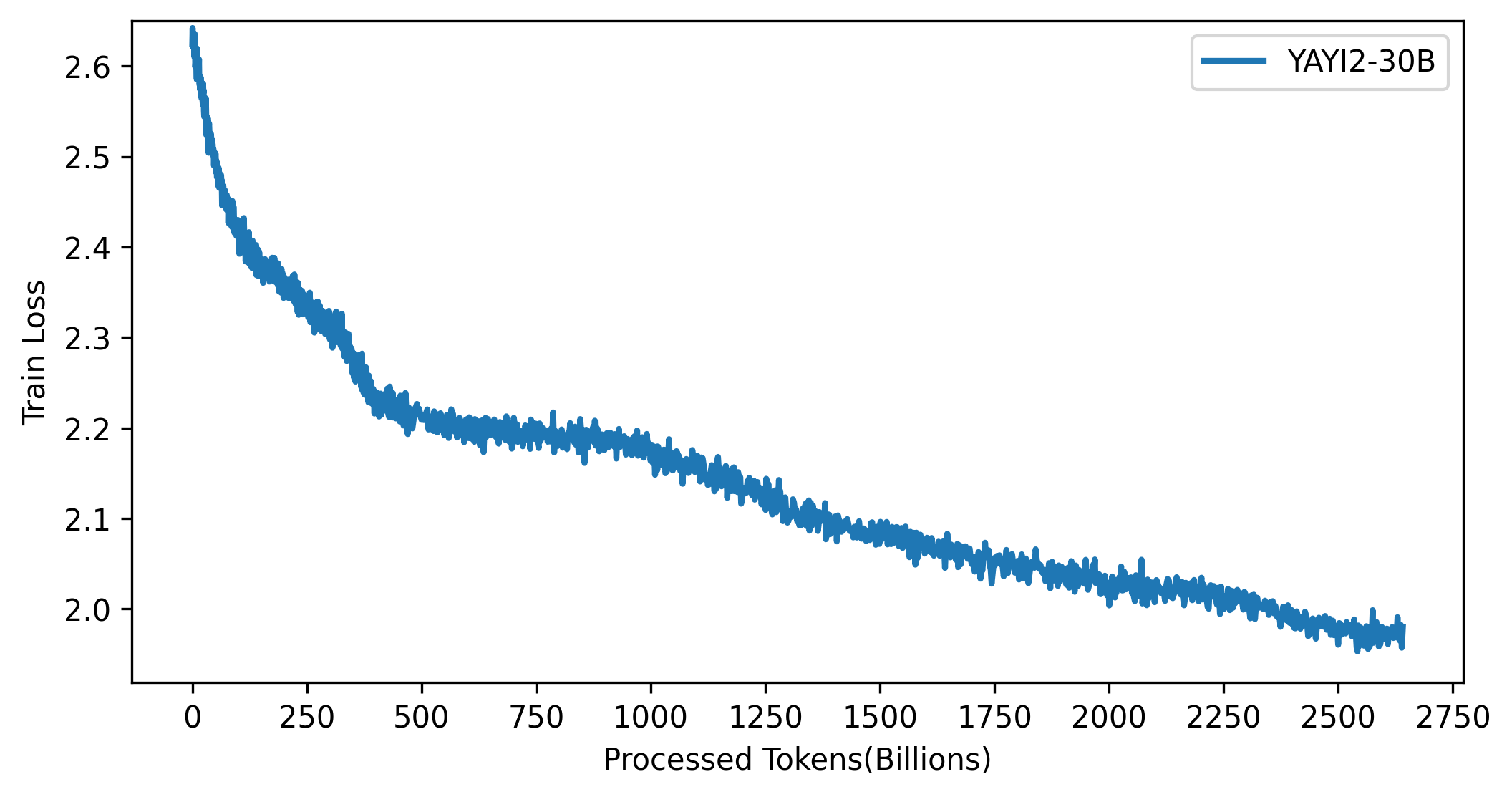
The code in this project is open source in accordance with the Apache-2.0 protocol. The community's use of the YAYI 2 model and data needs to comply with the "Yayi YAYI 2 Model Community License Agreement." If you need to use YAYI 2 series models or their derivatives for commercial purposes, please complete the "YAYI 2 Model Commercial Registration Information" and send it to [email protected]. We will reply within 3 working days after receiving the email. The review will be conducted on a daily basis. After passing the review, you will receive a commercial license. Please strictly abide by the relevant content of the "YAYI 2 Model Commercial License Agreement" during use. Thank you for your cooperation!
If you use our model in your work, please cite our paper:
@article{YAYI 2,
author = {Yin Luo, Qingchao Kong, Nan Xu, et.al.},
title = {YAYI 2: Multilingual Open Source Large Language Models},
journal = {arXiv preprint arXiv:2312.14862},
url = {https://arxiv.org/abs/2312.14862},
year = {2023}
}


