Transformer Architectures From Scratch
1.0.0
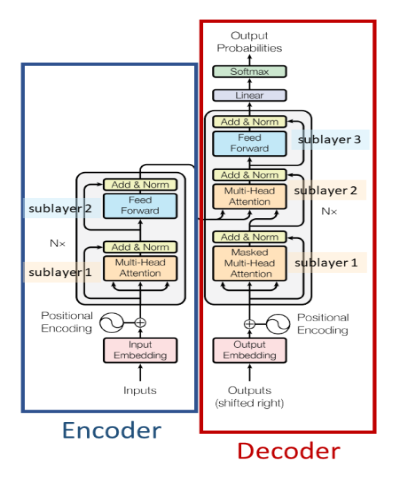
A Self attention based Encoder-Decoder Architecture. It is mostly used for
Paper - https://arxiv.org/abs/1706.03762
A Self-attention based Encoder Architecture. It is mostly used for
Paper - https://arxiv.org/abs/1810.04805
A Self-attention based Decoder based Autoregressive model. It is mostly used for
Paper - https://paperswithcode.com/method/gpt
A Self-attention based Decoder based Autoregressive model with a slight change in architecture and trained on larger corpus of text than GPT-1. It is mostly used for
Paper - https://d4mucfpksywv.cloudfront.net/better-language-models/language-models.pdf
A State of the art Self-attention based Encoder Architecture for Computer Vision application. It is mostly used for
Paper - https://arxiv.org/abs/2006.03677
A Self-attention based Encoder-Decoder Architecture with a linear time complexity other than transformer which has quadratic time complexity. It is mostly used
Paper - https://arxiv.org/abs/2009.14794


