Kosmos X
0.0.1

pip3 install --upgrade kosmosximport torch
from kosmosx.model import Kosmos
# Create a sample text token tensor
text_tokens = torch.randint(0, 32002, (1, 50), dtype=torch.long)
# Create a sample image tensor
images = torch.randn(1, 3, 224, 224)
# Instantiate the model
model = Kosmos()
text_tokens = text_tokens.long()
# Pass the sample tensors to the model's forward function
output = model.forward(
text_tokens=text_tokens,
images=images
)
# Print the output from the model
print(f"Output: {output}")Establish your configuration with: accelerate config then: accelerate launch train.py
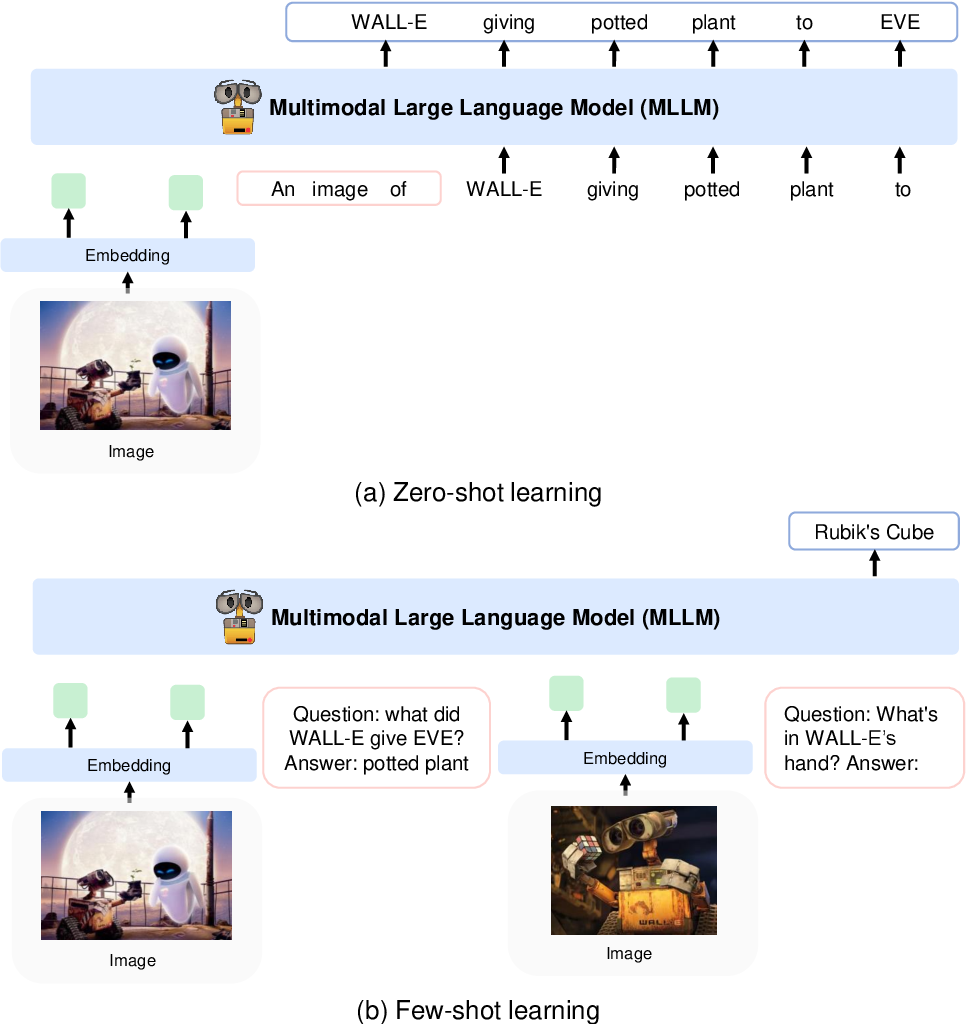
KOSMOS-1 uses a decoder-only Transformer architecture based on Magneto (Foundation Transformers), i.e. an architecture that employs a so called sub-LN approach where layer normilization is added both before the attention module (pre-ln) and afterwards (post-ln) combining the advantages that either approaches have for language modelling and image understanding respectively. The model is also initialized according to a specific metric also described in the paper, allowing for more stable training at higher learning rates.
They encode images to image features using a CLIP VIT-L/14 model and use a perceiver resampler introduced in Flamingo to pool the image features from 256 -> 64 tokens. The image features are combined with the token embeddings by adding them to the input sequence surrounded by special tokens <image> and </image>. An example is <s> <image> image_features </image> text </s>. This allows image(s) to be interwoven with text in the same sequence.
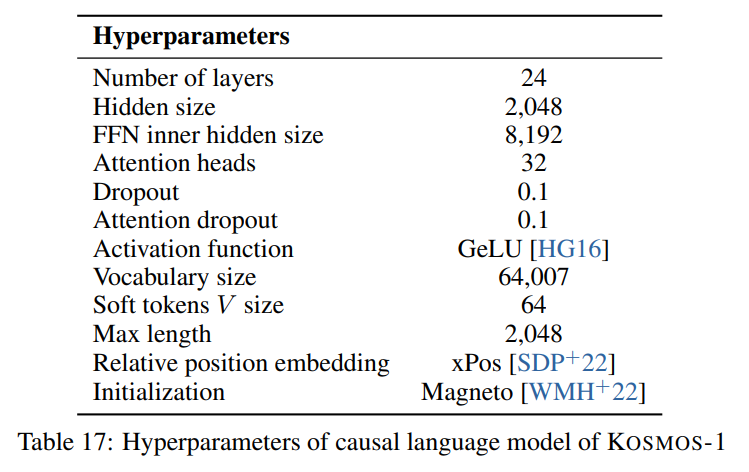
We follow the hyperparameters described in the paper visible in the following image:
We use the torchscale implementation of the decoder-only Transformer architecture from Foundation Transformers:
from torchscale.architecture.config import DecoderConfig
from torchscale.architecture.decoder import Decoder
config = DecoderConfig(
decoder_layers=24,
decoder_embed_dim=2048,
decoder_ffn_embed_dim=8192,
decoder_attention_heads=32,
dropout=0.1,
activation_fn="gelu",
attention_dropout=0.1,
vocab_size=32002,
subln=True, # sub-LN approach
xpos_rel_pos=True, # rotary positional embeddings
max_rel_pos=2048
)
decoder = Decoder(
config,
embed_tokens=embed,
embed_positions=embed_positions,
output_projection=output_projection
)For the image model (CLIP VIT-L/14) we use a pretrained OpenClip model:
from transformers import CLIPModel
clip_model = CLIPModel.from_pretrained("laion/CLIP-ViT-L-14-laion2B-s32B-b82K").vision_model
# projects image to [batch_size, 256, 1024]
features = clip_model(pixel_values=images)["last_hidden_state"]We follow the default hyperparams for the perceiver resampler as no hyperparams are given in the paper:
from flamingo_pytorch import PerceiverResampler
perceiver = PerceiverResampler(
dim = 1024,
depth = 2,
dim_head = 64,
heads = 8,
num_latents = 64,
num_media_embeds = 256
)
# projects image features to [batch_size, 64, 1024]
self.perceive(images).squeeze(1)Because the model expects a hidden dimension of 2048, we use a nn.Linear layer to project the image features to the correct dimension and initialize it according to Magneto's initialization scheme:
image_proj = torch.nn.Linear(1024, 2048, bias=False)
torch.nn.init.normal_(
image_proj.weight, mean=0, std=2048**-0.5
)
scaled_image_features = image_proj(image_features)The paper describes a SentencePiece with a vocabulary of 64007 tokens. For simplicity (as we don't have the training corpus available), we use the next best open-source alternative which is the pretrained T5-large tokenizer from HuggingFace. This tokenizer has a vocabulary of 32002 tokens.
from transformers import T5Tokenizer
tokenizer = T5Tokenizer.from_pretrained(
"t5-large",
additional_special_tokens=["<image>", "</image>"],
extra_ids=0,
model_max_length=1984 # 2048 - 64 (image features)
)We then embed the tokens with a nn.Embedding layer. We actually use a bnb.nn.Embedding from
bitandbytes which allows us to use 8-bit AdamW later.
import bitsandbytes as bnb
embed = bnb.nn.Embedding(
32002, # Num embeddings
2048, # Embedding dim
padding_idx
)For positional embeddings, we use:
from torchscale.component.embedding import PositionalEmbedding
embed_positions= PositionalEmbedding(
2048, # Num embeddings
2048, # Embedding dim
padding_idx
)Also, we add an output projection layer to project the hidden dimension to the vocabulary size and initialize it according to Magneto's initialization scheme:
output_projection = torch.nn.Linear(
2048, 32002, bias=False
)
torch.nn.init.normal_(
output_projection.weight, mean=0, std=2048**-0.5
)I had to make some slight changes to the decoder to allow it to accept already embedded features in the forward pass. This was necessary to allow the more complex input sequence described above. The changes are visible in the following diff in line 391 of torchscale/architecture/decoder.py:
+if kwargs.get("passed_x", None) is None:
+ x, _ = self.forward_embedding(
+ prev_output_tokens, token_embeddings, incremental_state
+ )
+else:
+ x = kwargs["passed_x"]
-x, _ = self.forward_embedding(
- prev_output_tokens, token_embeddings, incremental_state
-)Here is a markdown table with metadata for the datasets mentioned in the paper:
| Dataset | Description | Size | Link |
|---|---|---|---|
| The Pile | Diverse English text corpus | 800 GB | Huggingface |
| Common Crawl | Web crawl data | - | Common Crawl |
| LAION-400M | Image-text pairs from Common Crawl | 400M pairs | Huggingface |
| LAION-2B | Image-text pairs from Common Crawl | 2B pairs | ArXiv |
| COYO | Image-text pairs from Common Crawl | 700M pairs | Github |
| Conceptual Captions | Image-alt text pairs | 15M pairs | ArXiv |
| Interleaved CC Data | Text and images from Common Crawl | 71M docs | Custom dataset |
| StoryCloze | Commonsense reasoning | 16k examples | ACL Anthology |
| HellaSwag | Commonsense NLI | 70k examples | ArXiv |
| Winograd Schema | Word ambiguity | 273 examples | PKRR 2012 |
| Winogrande | Word ambiguity | 1.7k examples | AAAI 2020 |
| PIQA | Physical commonsense QA | 16k examples | AAAI 2020 |
| BoolQ | QA | 15k examples | ACL 2019 |
| CB | Natural language inference | 250 examples | Sinn und Bedeutung 2019 |
| COPA | Causal reasoning | 1k examples | AAAI Spring Symposium 2011 |
| RelativeSize | Commonsense reasoning | 486 pairs | ArXiv 2016 |
| MemoryColor | Commonsense reasoning | 720 examples | ArXiv 2021 |
| ColorTerms | Commonsense reasoning | 320 examples | ACL 2012 |
| IQ Test | Nonverbal reasoning | 50 examples | Custom dataset |
| COCO Captions | Image captioning | 413k images | PAMI 2015 |
| Flickr30k | Image captioning | 31k images | TACL 2014 |
| VQAv2 | Visual QA | 1M QA pairs | CVPR 2017 |
| VizWiz | Visual QA | 31k QA pairs | CVPR 2018 |
| WebSRC | Web QA | 1.4k examples | EMNLP 2021 |
| ImageNet | Image classification | 1.28M images | CVPR 2009 |
| CUB | Image classification | 200 bird species | TOG 2011 |
APACHE


