Copulas
v0.12.0 - 2024-11-12
This repository is part of The Synthetic Data Vault Project, a project from DataCebo.

Copulas is a Python library for modeling multivariate distributions and sampling from them using copula functions. Given a table of numerical data, use Copulas to learn the distribution and generate new synthetic data following the same statistical properties.
Key Features:
Model multivariate data. Choose from a variety of univariate distributions and copulas – including Archimedian Copulas, Gaussian Copulas and Vine Copulas.
Compare real and synthetic data visually after building your model. Visualizations are available as 1D histograms, 2D scatterplots and 3D scatterplots.
Access & manipulate learned parameters. With complete access to the internals of the model, set or tune parameters to your choosing.
Install the Copulas library using pip or conda.
pip install copulasconda install -c conda-forge copulasGet started using a demo dataset. This dataset contains 3 numerical columns.
from copulas.datasets import sample_trivariate_xyz
real_data = sample_trivariate_xyz()
real_data.head()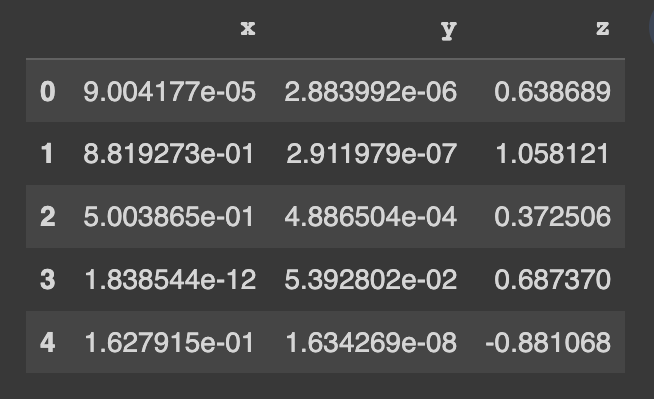
Model the data using a copula and use it to create synthetic data. The Copulas library offers many options including Gaussian Copula, Vine Copulas and Archimedian Copulas.
from copulas.multivariate import GaussianMultivariate
copula = GaussianMultivariate()
copula.fit(real_data)
synthetic_data = copula.sample(len(real_data))Visualize the real and synthetic data side-by-side. Let's do this in 3D so see our full dataset.
from copulas.visualization import compare_3d
compare_3d(real_data, synthetic_data)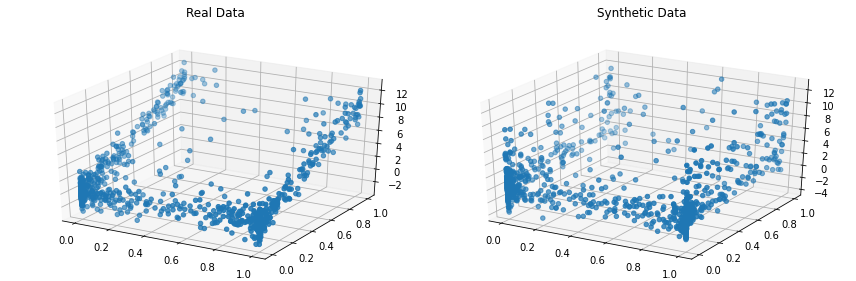
Click below to run the code yourself on a Colab Notebook and discover new features.
Learn more about Copulas library from our documentation site.
Questions or issues? Join our Slack channel to discuss more about Copulas and synthetic data. If you find a bug or have a feature request, you can also open an issue on our GitHub.
Interested in contributing to Copulas? Read our Contribution Guide to get started.
The Copulas open source project first started at the Data to AI Lab at MIT in 2018. Thank you to our team of contributors who have built and maintained the library over the years!
View Contributors

The Synthetic Data Vault Project was first created at MIT's Data to AI Lab in 2016. After 4 years of research and traction with enterprise, we created DataCebo in 2020 with the goal of growing the project. Today, DataCebo is the proud developer of SDV, the largest ecosystem for synthetic data generation & evaluation. It is home to multiple libraries that support synthetic data, including:
Get started using the SDV package -- a fully integrated solution and your one-stop shop for synthetic data. Or, use the standalone libraries for specific needs.


