airllm
1.0.0

Quickstart | Configurations | MacOS | Example notebooks | FAQ
AirLLM optimizes inference memory usage, allowing 70B large language models to run inference on a single 4GB GPU card without quantization, distillation and pruning. And you can run 405B Llama3.1 on 8GB vram now.
[2024/08/20] v2.11.0: Support Qwen2.5
[2024/08/18] v2.10.1 Support CPU inference. Support non sharded models. Thanks @NavodPeiris for the great work!
[2024/07/30] Support Llama3.1 405B (example notebook). Support 8bit/4bit quantization.
[2024/04/20] AirLLM supports Llama3 natively already. Run Llama3 70B on 4GB single GPU.
[2023/12/25] v2.8.2: Support MacOS running 70B large language models.
[2023/12/20] v2.7: Support AirLLMMixtral.
[2023/12/20] v2.6: Added AutoModel, automatically detect model type, no need to provide model class to initialize model.
[2023/12/18] v2.5: added prefetching to overlap the model loading and compute. 10% speed improvement.
[2023/12/03] added support of ChatGLM, QWen, Baichuan, Mistral, InternLM!
[2023/12/02] added support for safetensors. Now support all top 10 models in open llm leaderboard.
[2023/12/01] airllm 2.0. Support compressions: 3x run time speed up!
[2023/11/20] airllm Initial version!
First, install the airllm pip package.
pip install airllmThen, initialize AirLLMLlama2, pass in the huggingface repo ID of the model being used, or the local path, and inference can be performed similar to a regular transformer model.
(You can also specify the path to save the splitted layered model through layer_shards_saving_path when init AirLLMLlama2.
from airllm import AutoModel
MAX_LENGTH = 128
# could use hugging face model repo id:
model = AutoModel.from_pretrained("garage-bAInd/Platypus2-70B-instruct")
# or use model's local path...
#model = AutoModel.from_pretrained("/home/ubuntu/.cache/huggingface/hub/models--garage-bAInd--Platypus2-70B-instruct/snapshots/b585e74bcaae02e52665d9ac6d23f4d0dbc81a0f")
input_text = [
'What is the capital of United States?',
#'I like',
]
input_tokens = model.tokenizer(input_text,
return_tensors="pt",
return_attention_mask=False,
truncation=True,
max_length=MAX_LENGTH,
padding=False)
generation_output = model.generate(
input_tokens['input_ids'].cuda(),
max_new_tokens=20,
use_cache=True,
return_dict_in_generate=True)
output = model.tokenizer.decode(generation_output.sequences[0])
print(output)Note: During inference, the original model will first be decomposed and saved layer-wise. Please ensure there is sufficient disk space in the huggingface cache directory.
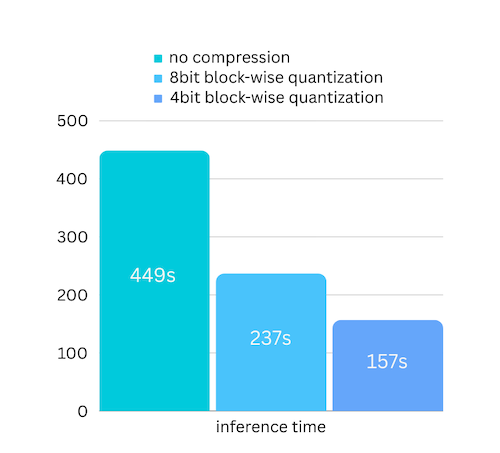
We just added model compression based on block-wise quantization-based model compression. Which can further speed up the inference speed for up to 3x , with almost ignorable accuracy loss! (see more performance evaluation and why we use block-wise quantization in this paper)
pip install -U bitsandbytes
pip install -U airllm
model = AutoModel.from_pretrained("garage-bAInd/Platypus2-70B-instruct",
compression='4bit' # specify '8bit' for 8-bit block-wise quantization
)Quantization normally needs to quantize both weights and activations to really speed things up. Which makes it harder to maintain accuracy and avoid the impact of outliers in all kinds of inputs.
While in our case the bottleneck is mainly at the disk loading, we only need to make the model loading size smaller. So, we get to only quantize the weights' part, which is easier to ensure the accuracy.
When initialize the model, we support the following configurations:
Just install airllm and run the code the same as on linux. See more in Quick Start.
Example [python notebook] (https://github.com/lyogavin/airllm/blob/main/air_llm/examples/run_on_macos.ipynb)
Example colabs here:
from airllm import AutoModel
MAX_LENGTH = 128
model = AutoModel.from_pretrained("THUDM/chatglm3-6b-base")
input_text = ['What is the capital of China?',]
input_tokens = model.tokenizer(input_text,
return_tensors="pt",
return_attention_mask=False,
truncation=True,
max_length=MAX_LENGTH,
padding=True)
generation_output = model.generate(
input_tokens['input_ids'].cuda(),
max_new_tokens=5,
use_cache= True,
return_dict_in_generate=True)
model.tokenizer.decode(generation_output.sequences[0])from airllm import AutoModel
MAX_LENGTH = 128
model = AutoModel.from_pretrained("Qwen/Qwen-7B")
input_text = ['What is the capital of China?',]
input_tokens = model.tokenizer(input_text,
return_tensors="pt",
return_attention_mask=False,
truncation=True,
max_length=MAX_LENGTH)
generation_output = model.generate(
input_tokens['input_ids'].cuda(),
max_new_tokens=5,
use_cache=True,
return_dict_in_generate=True)
model.tokenizer.decode(generation_output.sequences[0])from airllm import AutoModel
MAX_LENGTH = 128
model = AutoModel.from_pretrained("baichuan-inc/Baichuan2-7B-Base")
#model = AutoModel.from_pretrained("internlm/internlm-20b")
#model = AutoModel.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
input_text = ['What is the capital of China?',]
input_tokens = model.tokenizer(input_text,
return_tensors="pt",
return_attention_mask=False,
truncation=True,
max_length=MAX_LENGTH)
generation_output = model.generate(
input_tokens['input_ids'].cuda(),
max_new_tokens=5,
use_cache=True,
return_dict_in_generate=True)
model.tokenizer.decode(generation_output.sequences[0])A lot of the code are based on SimJeg's great work in the Kaggle exam competition. Big shoutout to SimJeg:
GitHub account @SimJeg, the code on Kaggle, the associated discussion.
safetensors_rust.SafetensorError: Error while deserializing header: MetadataIncompleteBuffer
If you run into this error, most possible cause is you run out of disk space. The process of splitting model is very disk-consuming. See this. You may need to extend your disk space, clear huggingface .cache and rerun.
Most likely you are loading QWen or ChatGLM model with Llama2 class. Try the following:
For QWen model:
from airllm import AutoModel #<----- instead of AirLLMLlama2
AutoModel.from_pretrained(...)For ChatGLM model:
from airllm import AutoModel #<----- instead of AirLLMLlama2
AutoModel.from_pretrained(...)Some models are gated models, needs huggingface api token. You can provide hf_token:
model = AutoModel.from_pretrained("meta-llama/Llama-2-7b-hf", #hf_token='HF_API_TOKEN')Some model's tokenizer doesn't have padding token, so you can set a padding token or simply turn the padding config off:
input_tokens = model.tokenizer(input_text,
return_tensors="pt",
return_attention_mask=False,
truncation=True,
max_length=MAX_LENGTH,
padding=False #<----------- turn off padding
)If you find AirLLM useful in your research and wish to cite it, please use the following BibTex entry:
@software{airllm2023,
author = {Gavin Li},
title = {AirLLM: scaling large language models on low-end commodity computers},
url = {https://github.com/lyogavin/airllm/},
version = {0.0},
year = {2023},
}
Welcomed contributions, ideas and discussions!
If you find it useful, please or buy me a coffee!


