WilmerAI
1.0.0
This is a personal project that is under heavy development. It could, and likely does, contain bugs, incomplete code, or other unintended issues. As such, the software is provided as-is, without warranty of any kind.
WilmerAI reflects the work of a single developer and the efforts of his personal time and resources; any views, methodologies, etc. found within are his own and should not reflect upon his employer.
WilmerAI is a sophisticated middleware system designed to take incoming prompts and perform various tasks on them before sending them to LLM APIs. This work includes utilizing a Large Language Model (LLM) to categorize the prompt and route it to the appropriate workflow or processing a large context (200,000+ tokens) to generate a smaller, more manageable prompt suitable for most local models.
WilmerAI stands for "What If Language Models Expertly Routed All Inference?"
Assistants Powered by Multiple LLMs in Tandem: Incoming prompts can be routed to "categories", with each category powered by a workflow. Each workflow can have as many nodes as you want, each node powered by a different LLM. For example- if you ask your assistant "Can you write me a Snake game in python?", that might be categorized as CODING and goes to your coding workflow. The first node of that workflow might ask Codestral-22b (or ChatGPT 4o if you want) to answer the question. The second node might ask Deepseek V2 or Claude Sonnet to code review it. The next node might ask Codestral to give a final once over and then respond to you. Whether your workflow is just a single model responding because it's your best coder, or whether its many nodes of different LLMs working together to generate a response- the choice is yours.
Support For The Offline Wikipedia API: WilmerAI has a node that can make calls to the OfflineWikipediaTextApi. This means that you can have a category, for example "FACTUAL", that looks at your incoming message, generates a query from it, queries the wikipedia API for a related article, and uses that article as RAG context injection to respond.
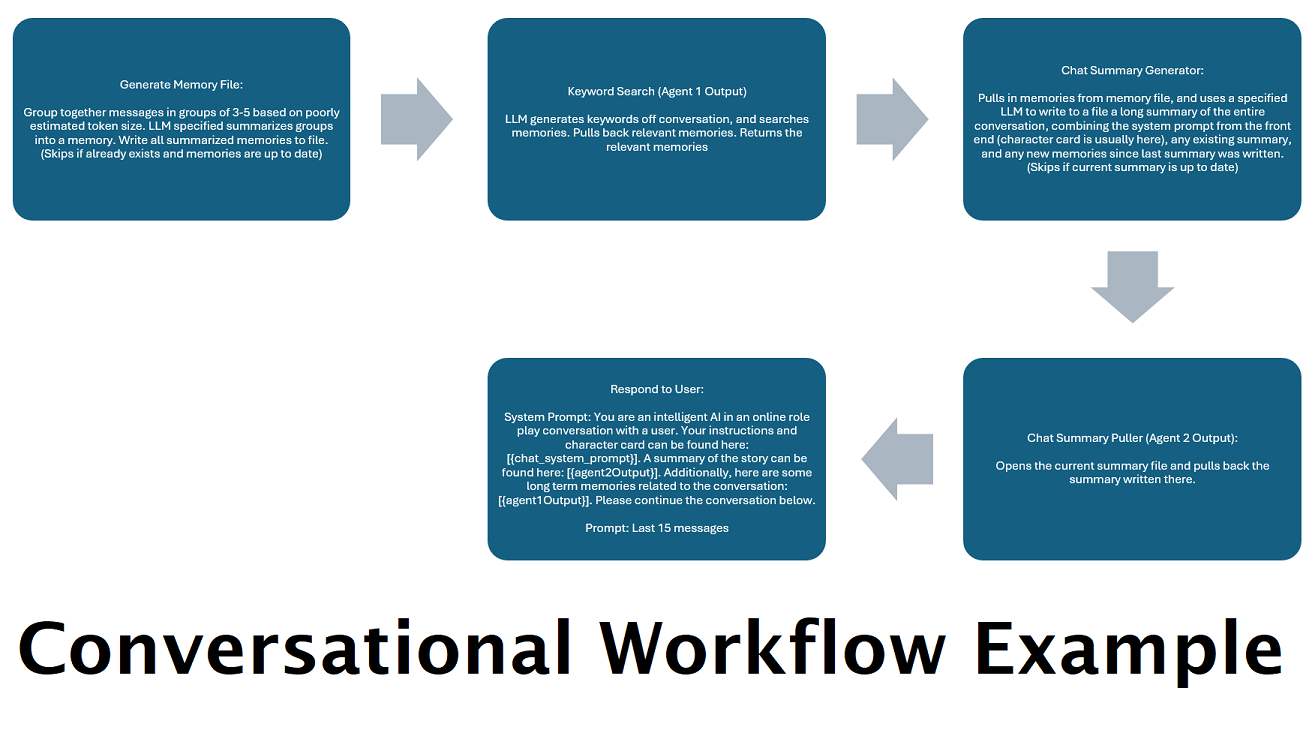
Continually Generated Chat Summaries to Simulate a "Memory": The Chat Summary node will generate "memories", by chunking your messages and then summarizing them and saving them to a file. It will then take those summarized chunks and generate an ongoing, constantly updating, summary of the entire conversation, that can be pulled and used within the prompt to the LLM. The results allow you to take 200k+ context conversations and keep relative track of what has been said even when limiting the prompts to the LLM to 5k context or less.
Use Multiple Computers To Parallel Process Memories and Responses: If you have 2 computers that can run LLMs,
you can designate one to be the "responder" and one to be responsible for generating memories/summaries. This kind
of workflow lets you keep talking to your LLM while the memories/summary are being updated, while still using the
existing memories. This means not needing to ever wait for the summary to update, even if you task a large and
powerful
model to handle that task so that you have higher quality memories. (See example user convo-role-dual-model)
Multi-LLM Group Chats In SillyTavern: It is possible to use Wilmer to have a group chat in ST where every
character is a different LLM, if you do desire (author personally does this.) There are example characters available
in DocsSillyTavern, split into two groups. These example characters/groups are subsets of larger groups that the
author uses.
Middleware Functionality: WilmerAI sits between the interface you use to communicate with an LLM (such as SillyTavern, OpenWebUI, or even a Python program's terminal) and the backend API serving the LLMs. It can handle multiple backend LLMs simultaneously.
Using Multiple LLMs at Once: Example setup: SillyTavern -> WilmerAI -> several instances of KoboldCpp. For example, Wilmer could be connected to Command-R 35b, Codestral 22b, Gemma-2-27b, and use all of those in its responses back to the user. As long as your LLM of choice is exposed via a v1/Completion or chat/Completion endpoint, or KoboldCpp's Generate endpoint, you can use it.
Customizable Presets: Presets are saved in a json file that you can readily customize. Almost every about presets can be managed via the json, including the parameter names. This means that you don't have to wait for a Wilmer update to make use of something new. For example, DRY came out recently on KoboldCpp. If that wasn't in the preset json for Wilmer, you should be able to simply add it and start using it.
API Endpoints: It provides OpenAI API compatible chat/Completions and v1/Completions endpoints to connect to
via your front end, and can connect to either type on the back end. This allows for complex configurations, such
as connecting to Wilmer as a v1/Completion API, and then having Wilmer connected to chat/Completion, v1/Completion
KoboldCpp Generate endpoints all at the same time.
Prompt Templates: Supports prompt templates for v1/Completions API endpoints. WilmerAI also has its own prompt
template for connections from a front end via v1/Completions. The template can be found in the "Docs" folder and is
ready for upload to SillyTavern.
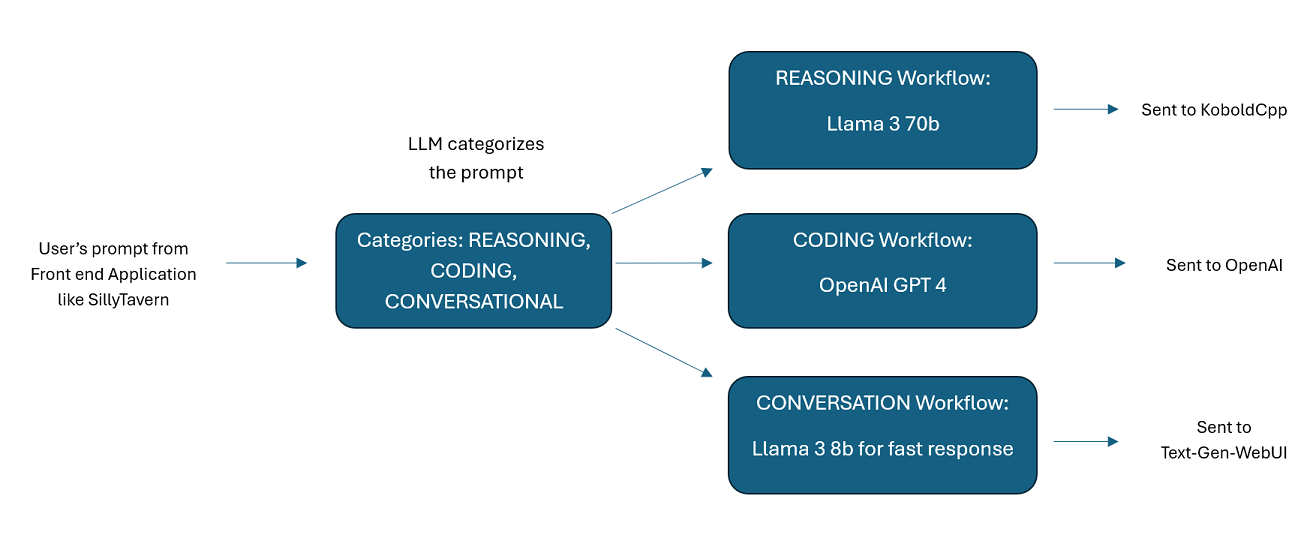
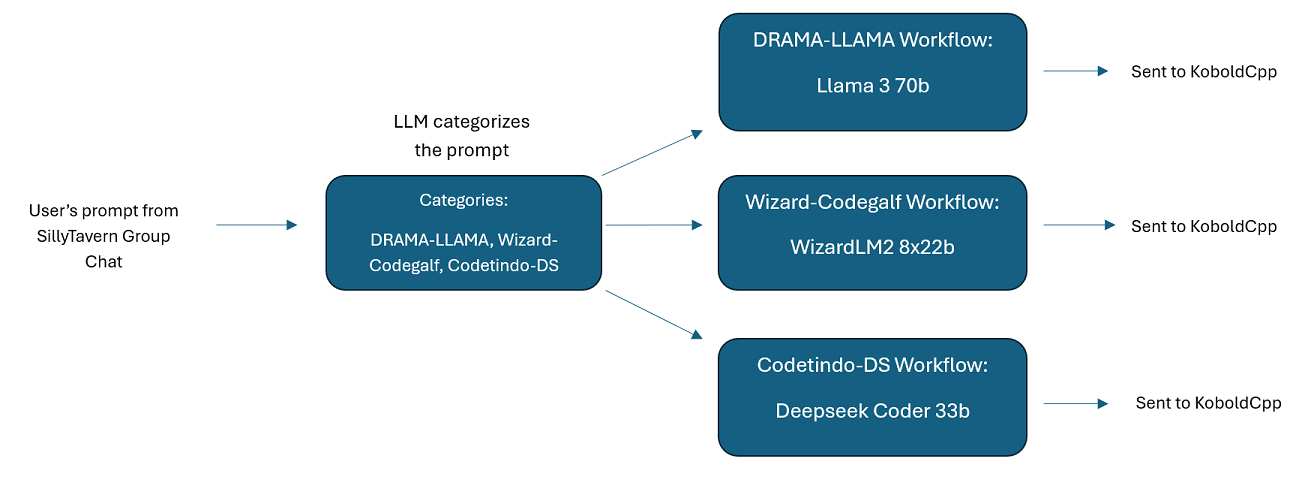
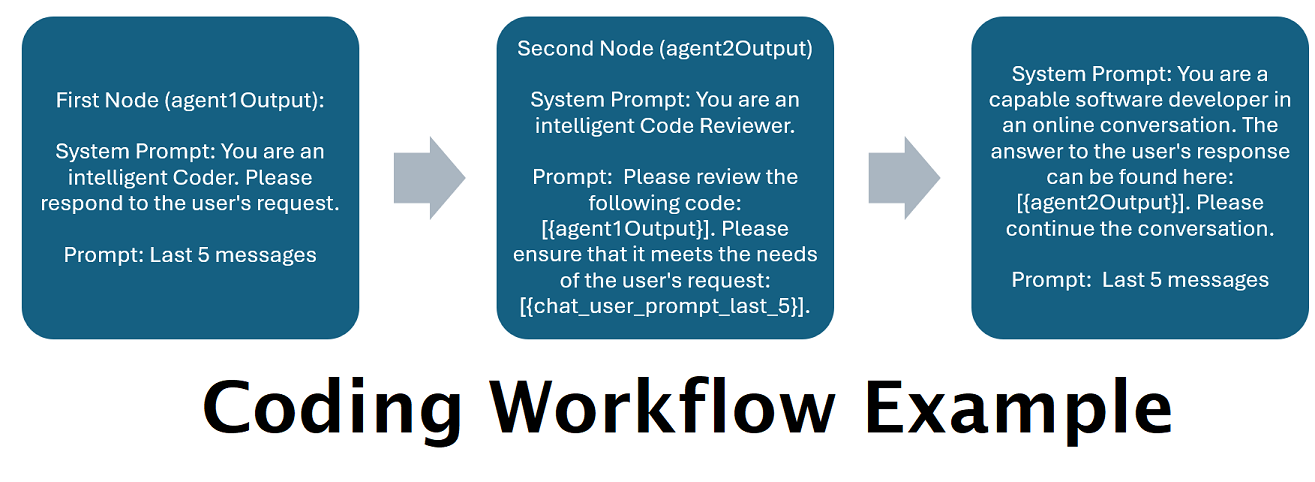

Please keep in mind that workflows, by their very nature, could make many calls to an API endpoint based on how you set them up. WilmerAI does not track token usage, does not report accurate token usage via its API, nor offer any viable way to monitor token usage. So if token usage tracking is important to you for cost reasons, please be sure to keep track of how many tokens you are using via any dashboard provided to you by your LLM APIs, especially early on as you get used to this software.
Your LLM directly affects the quality of WilmerAI. This is an LLM driven project, where the flows and outputs are almost entirely dependent on the connected LLMs and their responses. If you connect Wilmer to a model that produces lower quality outputs, or if your presets or prompt template have flaws, then Wilmer's overall quality will be much lower quality as well. It's not much different than agentic workflows in that way.
While the author is doing his best to make something useful and high quality, this is an ambitious solo project and is bound to have its problems (especially since the author is not natively a Python developer, and relied heavily on AI to help him get this far). He is slowly figuring it out, though.
Wilmer exposes both an OpenAI v1/Completions and chat/Completions endpoint, making it compatible with most front ends. While I have primarily used this with SillyTavern, it might also work with Open-WebUI.
To connect as a Text Completion in SillyTavern, follow these steps (the below screenshot is from SillyTavern):
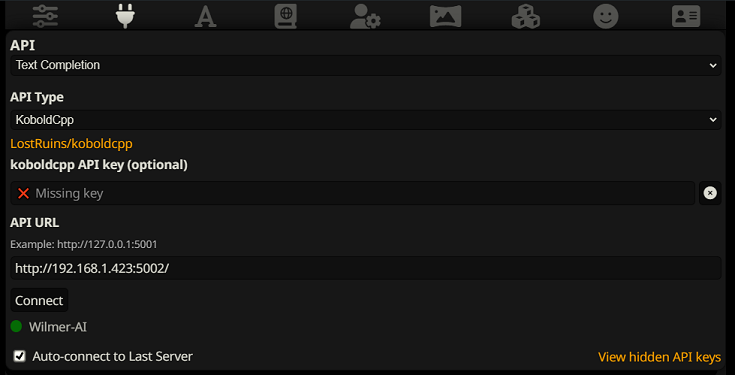
When using text completions, you need to use a WilmerAI-specific Prompt Template format. An importable ST file can be
found within Docs/SillyTavern/InstructTemplate. The context template is also included if you'd like to use that as
well.
The instruction template looks like this:
[Beg_Sys]You are an intelligent AI Assistant.[Beg_User]SomeOddCodeGuy: Hey there![Beg_Assistant]Wilmer: Hello![Beg_User]SomeOddCodeGuy: This is a test[Beg_Assistant]Wilmer: Nice.
From SillyTavern:
"input_sequence": "[Beg_User]",
"output_sequence": "[Beg_Assistant]",
"first_output_sequence": "[Beg_Assistant]",
"last_output_sequence": "",
"system_sequence_prefix": "[Beg_Sys]",
"system_sequence_suffix": "",
There are no expected newlines or characters between tags.
Please ensure that Context Template is "Enabled" (checkbox above the dropdown)
To connect as Chat Completions in SillyTavern, follow these steps (the below screenshot is from SillyTavern):
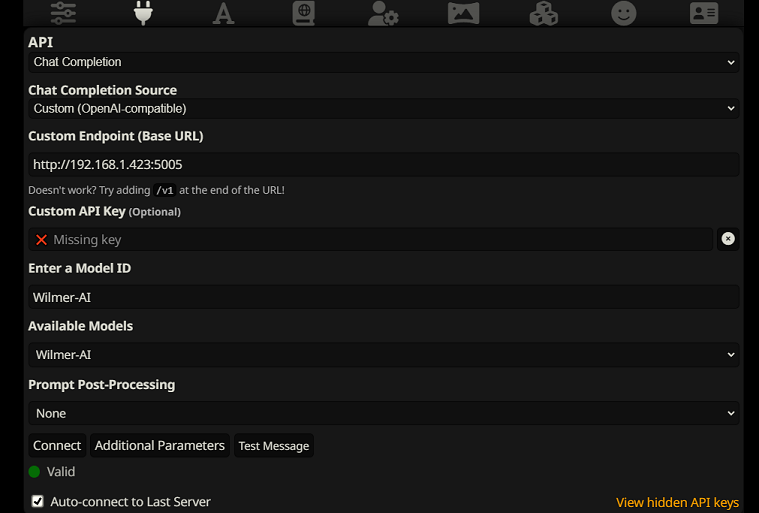
chatCompleteAddUserAssistant to true. (I
don't recommend setting both to true at the same time. Do either character names from SillyTavern, OR user/assistant
from Wilmer. The AI might get confused otherwise.)For either connection type, I recommend going to the "A" icon in SillyTavern and selecting "Include Names" and "Force Groups and Personas" under instruct mode, and then going to the far left icon (where the samplers are) and checking "stream" on the top left, and then on the top right checking "unlock" under context and dragging it to 200,000+. Let Wilmer worry about the context.
Wilmer currently has no user interface; everything is controlled via JSON configuration files located in the "Public" folder. This folder contains all essential configurations. When updating or downloading a new copy of WilmerAI, you should simply copy your "Public" folder to the new installation to retain your settings.
This section will walk you through setting up Wilmer. I have broken the sections into steps; I might recommend copying each step, 1 by 1, into an LLM and asking it to help you set the section up. That may make this go much easier.
IMPORTANT NOTES
It is important to note three things about Wilmer setup.
A) Preset files are 100% customizable. What is in that file goes to the llm API. This is because cloud APIs do not handle some of the various presets that local LLM APIs handle. As such, if you use OpenAI API or other cloud services, the calls will probably fail if you use one of the regular local AI presets. Please see the preset "OpenAI-API" for an example of what openAI accepts.
B) I have recently replaced all prompts in Wilmer to go from using the second person to third person. This has had pretty decent results for me, and I'm hoping it will for you as well.
C) By default, all the user files are set to turn on streaming responses. You either need to enable this in your front end that is calling Wilmer so that both match, or you need to go into Users/username.json and set Stream to "false". If you have a mismatch, where the front end does/does not expect streaming and your wilmer expects the opposite, nothing will likely show on the front end.
Installing Wilmer is straightforward. Ensure you have Python installed; the author has been using the program with Python 3.10 and 3.12, and both work well.
Option 1: Using Provided Scripts
For convenience, Wilmer includes a BAT file for Windows and a .sh file for macOS. These scripts will create a virtual
environment, install the required packages from requirements.txt, and then run Wilmer. You can use these scripts to
start Wilmer each time.
.bat file..sh file.IMPORTANT: Never run a BAT or SH file without inspecting it first, as this can be risky. If you are unsure about the safety of such a file, open it in Notepad/TextEdit, copy the contents and then ask your LLM to review it for any potential issues.
Option 2: Manual Installation
Alternatively, you can manually install the dependencies and run Wilmer with the following steps:
Install the required packages:
pip install -r requirements.txtStart the program:
python server.pyThe provided scripts are designed to streamline the process by setting up a virtual environment. However, you can safely ignore them if you prefer manual installation.
NOTE: When running either the bat file, the sh file or the python file, all three now accept the following OPTIONAL arguments:
So, for example, consider the following possible runs:
bash run_macos.sh (will use user specified in _current-user.json, configs in "Public", logs in "logs")bash run_macos.sh --User "single-model-assistant" (will default to public for configs and "log" for logs)bash run_macos.sh --ConfigDirectory "/users/socg/Public/configs" --User "single-model-assistant" (will just
use default for "logs"bash run_macos.sh --ConfigDirectory "/users/socg/Public/configs" --User "single-model-assistant" --LoggingDirectory "/users/socg/wilmerlogs"This these optional arguments allow users to spin up multiple instances of WilmerAI, each instance using a different user profile, logging to a different place, and specifying configs at a different location, if desired.
Within the Public/Configs you will find a series of folders containing json files. The two that you are
most interested in are the Endpoints folder and the Users folder.
NOTE: The Factual workflow nodes of the assistant-single-model, assistant-multi-model
and group-chat-example users will attempt to utilize the
OfflineWikipediaTextApi
project to pull full wikipedia articles to RAG against. If you don't have this API, the workflow
should not have any issues, but I personally use this API to help improve the factual responses I get.
You can specify the IP address to your API in the user json of your choice.
First, choose which template user you'd like to use:
assistant-single-model: This template is for a single small model being used on all nodes. This also has routes for many different category types and uses appropriate presets for each node. If you're wondering why there are routes for different categories when there is only 1 model: it's so that you can give each category their own presets, and also so that you can make custom workflows for them. Maybe you want the coder to do multiple iterations to check itself, or the reasoning to think through things in multiple steps.
assistant-multi-model: This template is for using many models in tandem. Looking at the endpoints for this user, you can see that every category has its own endpoint. There is absolutely nothing stopping you from re-using the same API for multiple categories. For example, you might use Llama 3.1 70b for coding, math, and reasoning, and Command-R 35b 08-2024 for categorization, conversation, and factual. Don't feel like you NEED 10 different models. This is simply to allow you to bring that many if you want. This user uses appropriate presets for each node in the workflows.
convo-roleplay-single-model: This user uses a single model with a custom workflow that is good for conversations, and should be good for roleplay (awaiting feedback to tweak if needed). This bypasses all routing.
convo-roleplay-dual-model: This user uses two models with a custom workflow that is good for conversations, and should be good for roleplay (awaiting feedback to tweak if needed). This bypasses all routing. NOTE: This workflow works best if you have 2 computers that can run LLMs. With the current setup for this user, when you send a message to Wilmer, the responder model (computer 1) will respond to you. Then the workflow will apply a "workflow lock" at that point. The memory/chat summary model (computer 2) will then begin updating the memories and summary of the conversation so far, which is passed to the responder to help it remember stuff. If you were to send another prompt while the memories are being written, the responder (computer 1) will grab whatever summary exists and go ahead and respond to you. The workflow lock will stop you from re-entering the new memories section. What this means is that you can continue talking to your responder model while new memories are being written. This is a HUGE performance boost. I've tried it out, and for me the response times were amazing. Without this, I get responses in 30 seconds 3-5 times, and then suddenly have a 2 minute wait to generate memories. With this, every message is 30 seconds, every time, on Llama 3.1 70b on my Mac Studio.
group-chat-example: This user is an example of my own personal group chats. The characters and the groups
included are actual characters and actual groups that I use. You can find the example characters in
the Docs/SillyTavern
folder. These are SillyTavern compatible characters that you can import directly into that program or any program
that supports .png character import types. The dev team
characters have only 1 node per workflow: they simply respond to you. The advisory group characters have 2 nodes
per workflow: first node generates a response, and the second node enforces the character's "persona" (the endpoint
in charge of this is the businessgroup-speaker endpoint). The group
chat personas help a lot to vary up the responses you get, even if you use only 1 model. However, I aim to use
different models for every character (but re-using models between groups; so, for example, I have a Llama 3.1 70b
model character in each group).
Once you have selected the user that you want to use, there are a couple of steps to perform:
Update the endpoints for your user under Public/Configs/Endpoints. The example characters are sorted into folders
for each. The user's endpoint folder is specified at the bottom of their user.json file. You will want to fill in
every endpoint
appropriately for the LLMs you are using. You can find some example endpoints under the _example-endpoints folder.
You will need to set your current user. You can do this when running the bat/sh/py file by using the --User argument, or you can do this in Public/Configs/Users/_current-user.json. Simply put the name of the user as the current user and save.
You will want to open your user json file and peek at the options. Here you can set whether you want streaming or not, can set the IP address to your offline wiki API (if you're using it), specify where you want your memories/summary files to go during DiscussionId flows, and also specify where you want the sqllite db to go if you use Workflow Locks.
That's it! Run Wilmer, connect to it, and you should be good to go.
First, we'll set up the endpoints and models. Within the Public/Configs folder you should see the following sub-folders. Let's walk through what you need.
These configuration files represent the LLM API endpoints you are connected to. For example, the following JSON
file, SmallModelEndpoint.json, defines an endpoint:
{
"modelNameForDisplayOnly": "Small model for all tasks",
"endpoint": "http://127.0.0.1:5000",
"apiTypeConfigFileName": "KoboldCpp",
"maxContextTokenSize": 8192,
"modelNameToSendToAPI": "",
"promptTemplate": "chatml",
"addGenerationPrompt": true
}These configuration files represent the different API types that you might be hitting when using Wilmer.
{
"nameForDisplayOnly": "KoboldCpp Example",
"type": "koboldCppGenerate",
"presetType": "KoboldCpp",
"truncateLengthPropertyName": "max_context_length",
"maxNewTokensPropertyName": "max_length",
"streamPropertyName": "stream"
}These files specify the prompt template for a model. Consider the following example, llama3.json:
{
"promptTemplateAssistantPrefix": "<|start_header_id|>assistant<|end_header_id|>nn",
"promptTemplateAssistantSuffix": "<|eot_id|>",
"promptTemplateEndToken": "",
"promptTemplateSystemPrefix": "<|start_header_id|>system<|end_header_id|>nn",
"promptTemplateSystemSuffix": "<|eot_id|>",
"promptTemplateUserPrefix": "<|start_header_id|>user<|end_header_id|>nn",
"promptTemplateUserSuffix": "<|eot_id|>"
}These templates are applied to all v1/Completion endpoint calls. If you prefer not to use a template, there is a file
called _chatonly.json that breaks up messages with newlines only.
Creating and activating a user involves four major steps. Follow the instructions below to set up a new user.
First, within the Users folder, create a JSON file for the new user. The easiest way to do this is to copy an existing
user JSON file, paste it as a duplicate, and then rename it. Here is an example of a user JSON file:
{
"port": 5006,
"stream": true,
"customWorkflowOverride": false,
"customWorkflow": "CodingWorkflow-LargeModel-Centric",
"routingConfig": "assistantSingleModelCategoriesConfig",
"categorizationWorkflow": "CustomCategorizationWorkflow",
"defaultParallelProcessWorkflow": "SlowButQualityRagParallelProcessor",
"fileMemoryToolWorkflow": "MemoryFileToolWorkflow",
"chatSummaryToolWorkflow": "GetChatSummaryToolWorkflow",
"conversationMemoryToolWorkflow": "CustomConversationMemoryToolWorkflow",
"recentMemoryToolWorkflow": "RecentMemoryToolWorkflow",
"discussionIdMemoryFileWorkflowSettings": "_DiscussionId-MemoryFile-Workflow-Settings",
"discussionDirectory": "D:\Temp",
"sqlLiteDirectory": "D:\Temp",
"chatPromptTemplateName": "_chatonly",
"verboseLogging": true,
"chatCompleteAddUserAssistant": true,
"chatCompletionAddMissingAssistantGenerator": true,
"useOfflineWikiApi": true,
"offlineWikiApiHost": "127.0.0.1",
"offlineWikiApiPort": 5728,
"endpointConfigsSubDirectory": "assistant-single-model",
"useFileLogging": false
}0.0.0.0, making it visible on your network if run on another computer. Running multiple instances of Wilmer on
different ports is supported.true, the router is disabled, and all prompts go only to the specified workflow,
making it a single workflow instance of Wilmer.customWorkflowOverride is true.Routing folder, without the .json extension.DiscussionId.chatCompleteAddUserAssistant is true.DataFinder character.Next, update the _current-user.json file to specify what user you want to use. Match the name of the new user JSON
file,
without the .json extension.
NOTE: You can ignore this if you want to use the --User argument when running Wilmer instead.
Create a routing JSON file in the Routing folder. This file can be named anything you want. Update the routingConfig
property in your user JSON file with this name, minus the .json extension. Here is an example of a routing config
file:
{
"CODING": {
"description": "Any request which requires a code snippet as a response",
"workflow": "CodingWorkflow"
},
"FACTUAL": {
"description": "Requests that require factual information or data",
"workflow": "ConversationalWorkflow"
},
"CONVERSATIONAL": {
"description": "Casual conversation or non-specific inquiries",
"workflow": "FactualWorkflow"
}
}.json extension, triggered if the category is chosen.In the Workflow folder, create a new folder that matches the username from the Users folder. The quickest way to do
this is to copy an existing user's folder, duplicate it, and rename it.
If you choose to make no other changes, you will need to go through the workflows and update the endpoints to point to the endpoint you want. If you are using an example workflow added with Wilmer, then you should already be fine here.
Within the "Public" folder you should have:
Workflows in this project are modified and controlled in the Public/Workflows folder, within your user's specific
workflows folder. For example, if your user is named socg and you have a socg.json file in the Users folder, then
within workflows you should have a Workflows/socg folder.
Here is an example of what a workflow JSON might look like:
[
{
"title": "Coding Agent",
"agentName": "Coder Agent One",
"systemPrompt": "You are an exceptionally powerful and intelligent technical AI that is currently in a role play with a user in an online chat.nThe instructions for the roleplay can be found below:n[n{chat_system_prompt}n]nPlease continue the conversation below. Please be a good team player. This means working together towards a common goal, and does not always include being overly polite or agreeable. Disagreement when the other user is wrong can help foster growth in everyone, so please always speak your mind and critically review your peers. Failure to correct someone who is wrong could result in the team's work being a failure.",
"prompt": "",
"lastMessagesToSendInsteadOfPrompt": 6,
"endpointName": "SocgMacStudioPort5002",
"preset": "Coding",
"maxResponseSizeInTokens": 500,
"addUserTurnTemplate": false
},
{
"title": "Reviewing Agent",
"agentName": "Code Review Agent Two",
"systemPrompt": "You are an exceptionally powerful and intelligent technical AI that is currently in a role play with a user in an online chat.",
"prompt": "You are in an online conversation with a user. The last five messages can be found here:n[n{chat_user_prompt_last_five}n]nYou have already considered this request quietly to yourself within your own inner thoughts, and come up with a possible answer. The answer can be found here:n[n{agent1Output}n]nPlease critically review the response, reconsidering your initial choices, and ensure that it is accurate, complete, and fulfills all requirements of the user's request.nnOnce you have finished reconsidering your answer, please respond to the user with the correct and complete answer.nnIMPORTANT: Do not mention your inner thoughts or make any mention of reviewing a solution. The user cannot see the answer above, and any mention of it would confuse the user. Respond to the user with a complete answer as if it were the first time you were answering it.",
"endpointName": "SocgMacStudioPort5002",
"preset": "Coding",
"maxResponseSizeInTokens": 1000,
"addUserTurnTemplate": true
}
]The above workflow is made up of conversation nodes. Both nodes do one simple thing: send a message to the LLM specified at the endpoint.
title. It's helpful to name these ending in "One", "Two", etc., to keep track of the agent
output. The first node's output is saved to {agent1Output}, the second to {agent2Output}, and so on.Endpoints
folder, without the .json extension.Presets folder, without the .json extension.false (see first example node above). If you send a prompt, set this as true (see
second example node above).NOTE: The addDiscussionIdTimestampsForLLM feature was an experiment, and truthfully I am not happy with how the experiment went. Even the largest LLMs misread the timestamps, got confused by them, etc. I have other plans for this feature which should be far more useful, but I left it in and won't be removing it, even though I don't necessarily recommend using it. -Socg
You can use several variables within these prompts. These will be appropriately replaced at runtime:
{chat_user_prompt_last_one}: The last message in the conversation, without prompt template tags wrapping the
message.
{templated_user_prompt_last_one}: The last message in the conversation, wrapped in the appropriate user/assistant
prompt template tags.
{chat_system_prompt}: The system prompt sent from the front end. Often contains character card and other important
info.
{templated_system_prompt}: The system prompt from the front end, wrapped in the appropriate system prompt template
tag.
{agent#Output}: # is replaced with the number you want. Every node generates an agent output. The first node is
always 1, and each subsequent node increments by 1. For example, {agent1Output} for the first node, {agent2Output}
for the second, etc.
{category_colon_descriptions}: Pulls the categories and descriptions from your Routing JSON file.
{categoriesSeparatedByOr}: Pulls the category names, separated by "OR".
[TextChunk]: A special variable unique to the parallel processor, likely not used often.NOTE: For a deeper understanding of how memories work, please see the Understanding Memories section
This node will pull N number of memories (or most recent messages if no DiscussionId is present) and add a custom delimiter between them. So if you have a memory file with 3 memories, and choose a delimiter of "n---------n" then you might get the following:
This is the first memory
---------
This is the second memory
---------
This is the third memory
Combining this node with the chat summary can allow the LLM to receive not only the summarized breakdown of the entire conversation as a whole, but also a list of all the memories that summary was built off of, which may contain more detailed and granular information about it. Sending both of those together, alongside the last 15-20 messages, can create the impression of a continual and persistent memory of the entire chat up to the most recent messages. Special care to craft good prompts for the generation of the memories can help to ensure the details you care about are captured, while less pertinent details are ignored.
This node will NOT generate new memories; this is so that workflow locks can be respected if you are using them on a multi-computer setup. Currently the best way to generate memories is the FullChatSummary node.


