Ainur
1.0.0
Ainur is an innovative deep learning model for conditional multimodal music generation. It is designed to generate high-quality stereo music samples at 48 kHz conditioned on a variety of inputs, such as lyrics, text descriptors, and other audio. Ainur's hierarchical diffusion architecture, combined with CLASP embeddings, allows it to produce coherent and expressive music compositions across a wide range of genres and styles.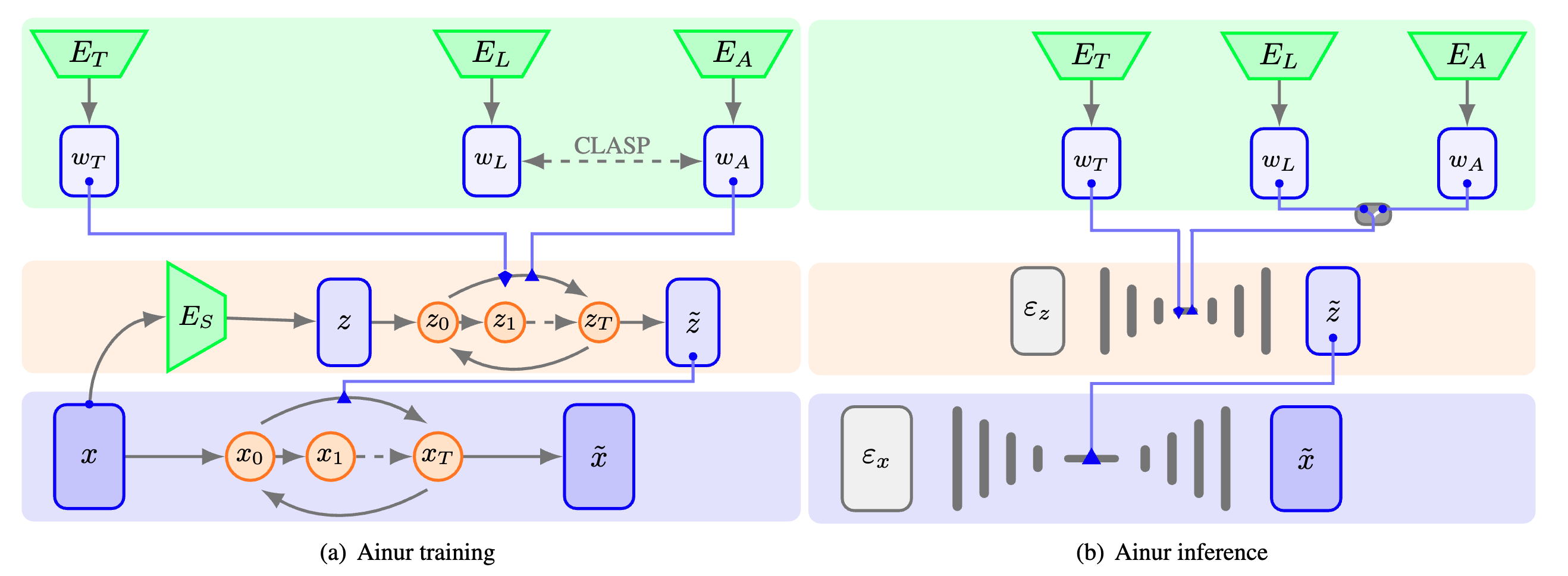

Conditional Generation: Ainur enables the generation of music conditioned on lyrics, text descriptors, or other audio, offering a flexible and creative approach to music composition.
High-Quality Output: The model is capable of producing 22-second stereo music samples at 48 kHz, ensuring high fidelity and realism.
Multimodal Learning: Ainur employs CLASP embeddings, which are multimodal representations of lyrics and audio, to facilitate the alignment of textual lyrics with corresponding audio fragments.
Objective Evaluation: We provide comprehensive evaluation metrics, including Frechet Audio Distance (FAD) and CLASP Cycle Consistency (C3), to assess the quality and coherence of generated music.
To run Ainur, ensure you have the following dependencies installed:
Python 3.8+
PyTorch 1.13.1
PyTorch Lightning 2.0.0
You can install the required Python packages by running:
pip install -r requirements.txt
Clone this repository:
git clone https://github.com/ainur-music/ainur.gitcd ainur
Install the dependencies (as mentioned above).
Run Ainur with your desired input. Check out the example notebooks in the examples folder for guidance on using Ainur for music generation. (coming soon)
Ainur guides the generation of music and improves the quality of the vocals through textual information and synced lyrics. Here's an examples of inputs for training and generating music with Ainur:
«Red Hot Chili Peppers, Alternative Rock, 7 of 19»
«[00:45.18] I got your hey oh, now listen what I say oh [...]»
We compare the performance of Ainur with other state-of-the-art model for text-to-music generation. We based the evaluation on objective metrics like FAD and using different embedding model for reference: VGGish, YAMNet and Trill.
| Model | Rate [kHz] | Length [s] | Parameters [M] | Inference Steps | Inference Time [s] ↓ | FAD VGGish ↓ | FAD YAMNet ↓ | FAD Trill ↓ |
|---|---|---|---|---|---|---|---|---|
| Ainur | 48@2 | 22 | 910 | 50 | 14.5 | 8.38 | 20.70 | 0.66 |
| Ainur (no CLASP) | 48@2 | 22 | 910 | 50 | 14.7 | 8.40 | 20.86 | 0.64 |
| AudioLDM | 16@1 | 22 | 181 | 200 | 2.20 | 15.5 | 784.2 | 0.52 |
| AudioLDM 2 | 16@1 | 22 | 1100 | 100 | 20.8 | 8.67 | 23.92 | 0.52 |
| MusicGen | 16@1 | 22 | 300 | 1500 | 81.3 | 14.4 | 53.04 | 0.66 |
| Jukebox | 16@1 | 1 | 1000 | - | 538 | 20.4 | 178.1 | 1.59 |
| MusicLM | 16@1 | 5 | 1890 | 125 | 153 | 15.0 | 61.58 | 0.47 |
| Riffusion | 44.1@1 | 5 | 890 | 50 | 6.90 | 5.24 | 15.96 | 0.67 |
Explore and listen to music generated by Ainur here.
You can download pre-trained Ainur and CLASP checkpoints from drive:
Ainur best checkpoint (model with lowest loss during training)
Ainur last checkpoint (model with the highest number of training steps)
CLASP checkpoint
This project is licensed under the MIT License - see the LICENSE file for details.
© 2023 Giuseppe Concialdi


