langchain opensearch rag
1.0.0
Create an Amazon OpenSearch Serverless collection (type Vector search and choose Easy create option) - documentation.
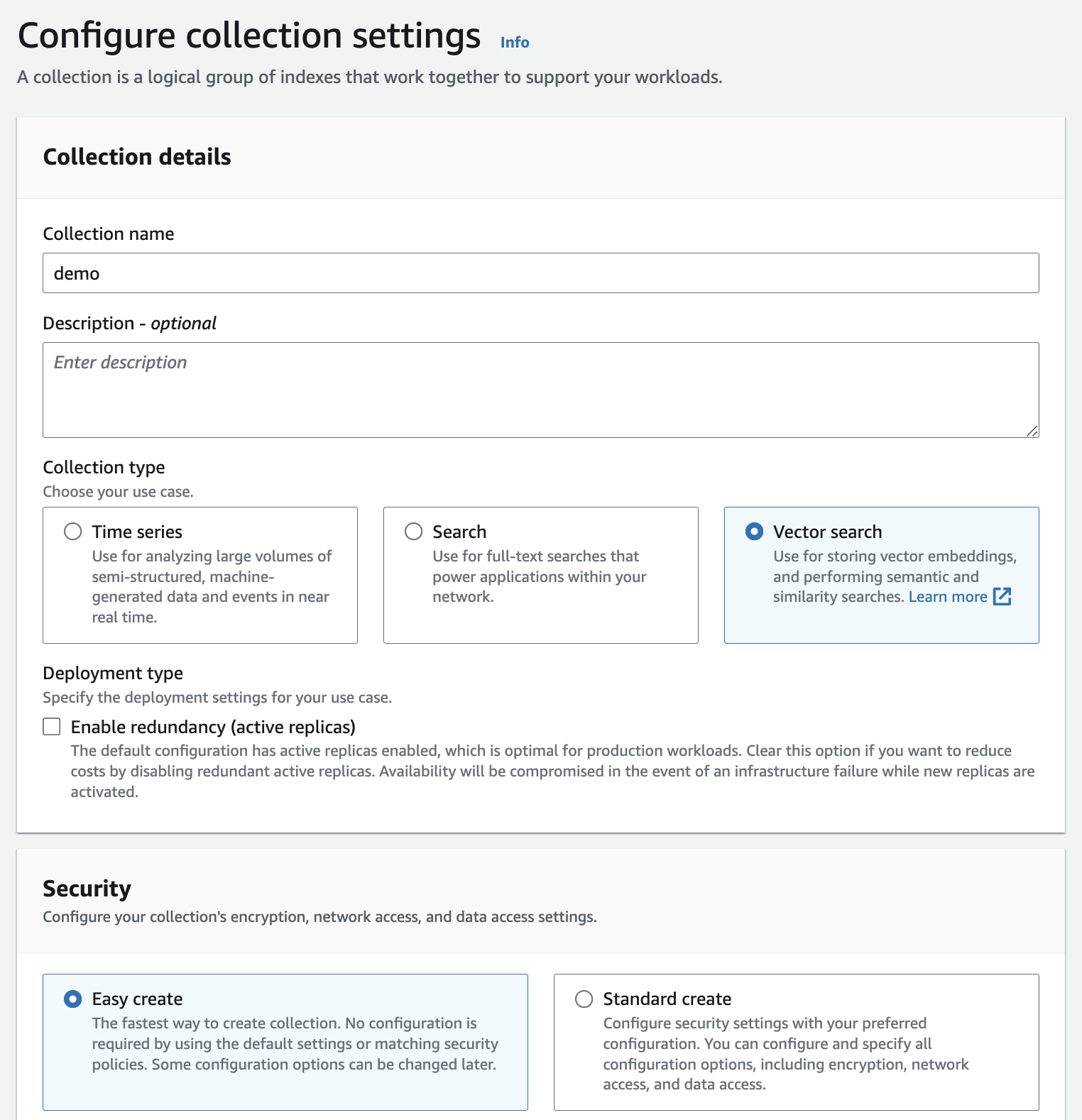
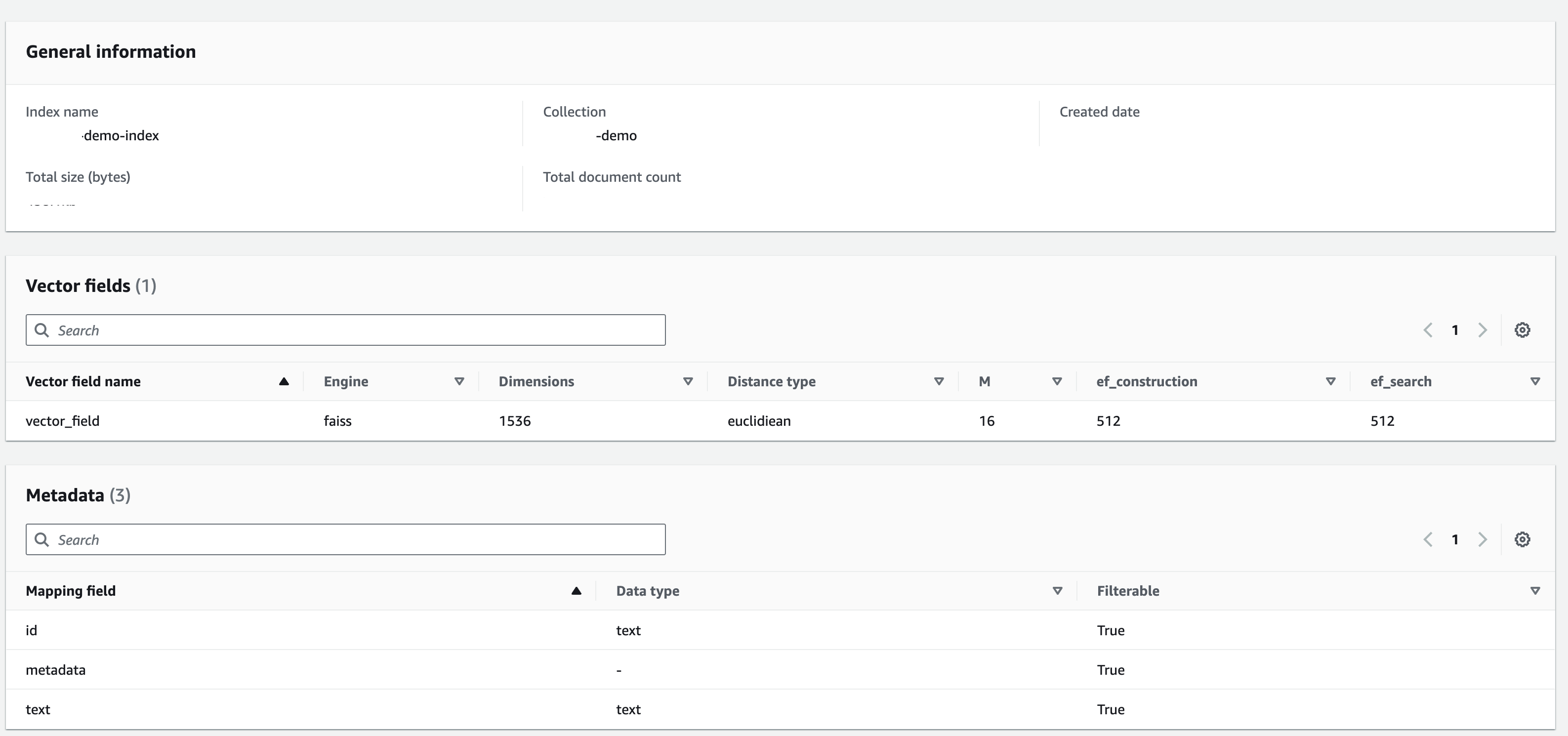
Create an index with below configuration:
Download the Amazon 2022 Letter to Shareholders and place it in the same directory.
Create a .env file and provide the following info about your Amazon OpenSearch setup:
opensearch_index_name='<enter name>'
opensearch_url='<enter URL>'
engine='faiss'
vector_field='vector_field'
text_field='text'
metadata_field='metadata'Make sure you have configured Amazon Bedrock for access from your local machine. Also, you need access to amazon.titan-embed-text-v1 embedding model and anthropic.claude-v2 model in Amazon Bedrock - follow these instructions for details.
Load PDF data:
python3 -m venv myenv
source myenv/bin/activate
pip3 install -r requirements.txt
python3 load.pyVerify data in OpenSearch collection
streamlit run app_semantic_search.py --server.port 8080You can ask questions, such as:
What is Amazon's doing in the field of generative AI?
What were the key challenges Amazon faced in 2022?
What were some of the important investments and initiatives mentioned in the letter?
In a different terminal:
source myenv/bin/activate
streamlit run app_rag.py --server.port 8081You can ask questions, such as:
What is Amazon's doing in the field of generative AI?
What were the key challenges Amazon faced in 2022?
What were some of the important investments and initiatives mentioned in the letter?


