EasyDetect
1.0.0

An Easy-to-Use Multimodal Hallucination Detection Framework for MLLMs
Acknowledgement • Benchmark • Demo • Overview • ModelZoo • Installation • Quickstart • Citation
Acknowledgement
Overview
Unified Multimodal Hallucination
Dataset: MHalluBench Statistic
Framework: UniHD Illustration
ModelZoo
Installation
⏩Quickstart
Citation
2024-05-17 The paper Unified Hallucination Detection for Multimodal Large Language Models is accepted by ACL 2024 main conference.
2024-04-21 We replace all the base models in the demo with our own trained models, significantly reducing the inference time.
2024-04-21 We release our open-source hallucination detection model HalDet-LLAVA, which can be downloaded in huggingface, modelscope and wisemodel.
2024-02-10 We release the EasyDetect demo.
2024-02-05 We release the paper:"Unified Hallucination Detection for Multimodal Large Language Models" with a new benchmark MHaluBench! We are looking forward to any comments or discussions on this topic :)
2023-10-20 The EasyDetect project has been launched and is under development.
Part implementation of this project were assisted and inspired by the related hallucination toolkits including FactTool, Woodpecker, and others. This repository also benefits from the public project from mPLUG-Owl, MiniGPT-4, LLaVA, GroundingDINO, and MAERec . We follow the same license for open-sourcing and thank them for their contributions to the community.
EasyDetect is a systematic package which is proposed as an easy-to-use hallucination detection framework for Multimodal Large Language Models(MLLMs) like GPT-4V, Gemini, LlaVA in your research experiments.
A prerequisite for unified detection is the coherent categorization of the principal categories of hallucinations within MLLMs. Our paper superficially examines the following Hallucination Taxonomy from a unified perspective:


Figure 1: Unified multimodal hallucination detection aims to identify and detect modality-conflicting hallucinations at various levels such as object, attribute, and scene-text, as well as fact-conflicting hallucinations in both image-to-text and text-to-image generation.
Modality-Conflicting Hallucination. MLLMs sometimes generate outputs that conflict with inputs from other modalities, leading to issues such as incorrect objects, attributes, or scene text. An example in above Figure (a) includes an MLLM inaccurately describing an athlete's uniform , showcasing an attribute-level conflict due to MLLMs' limited ability to achieve fine-grained text-image alignment.
Fact-Conflicting Hallucination. Outputs from MLLMs may contradict established factual knowledge. Image-to-text models can generate narratives that stray from the actual content by incorporating irrelevant facts, while text-to-image models may produce visuals that fail to reflect the factual knowledge contained in text prompts. These discrepancies underline the struggle of MLLMs to maintain factual consistency, representing a significant challenge in the domain.
Unified detection of multimodal hallucination necessitates the check of each image-text pair a={v, x}, wherein v denotes either the visual input provided to an MLLM, or the visual output synthesized by it. Correspondingly, x signifies the MLLM's generated textual response based on v or the textual user query for synthesizing v. Within this task, each x may contain multiple claims, denoted asa to determine whether it is "hallucinatory" or "non-hallucinatory", providing a rationale for their judgments based on the provided definition of hallucination. Text hallucination detection from LLMs denotes a sub-case in this setting, where v is null.
To advance this research trajectory, we introduce the meta-evaluation benchmark MHaluBench, which encompasses the content from image-to-text and text-to-image generation, aiming to rigorously assess the advancements in multimodal halluci- nation detectors. Further statistical details about MHaluBench are provided in below Figures.
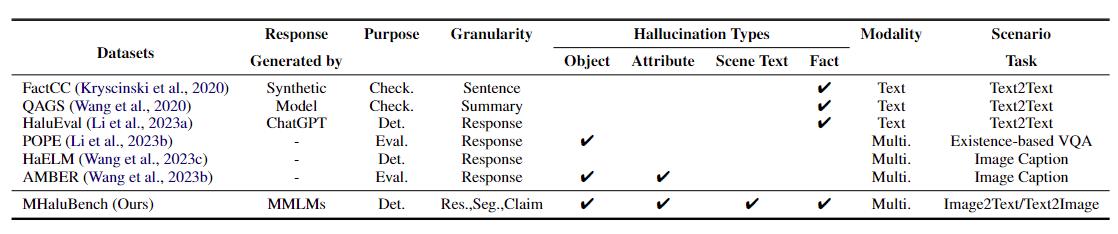
Table 1: A comparison of benchmarks with respect to existing fact-checking or hallucination evaluation. "Check." indicates verifying factual consistency, "Eval." denotes evaluating hallucinations generated by different LLMs, and its response is based on different LLMs under test, while "Det." embodies the evaluation of a detector’s capability in identifying hallucinations.
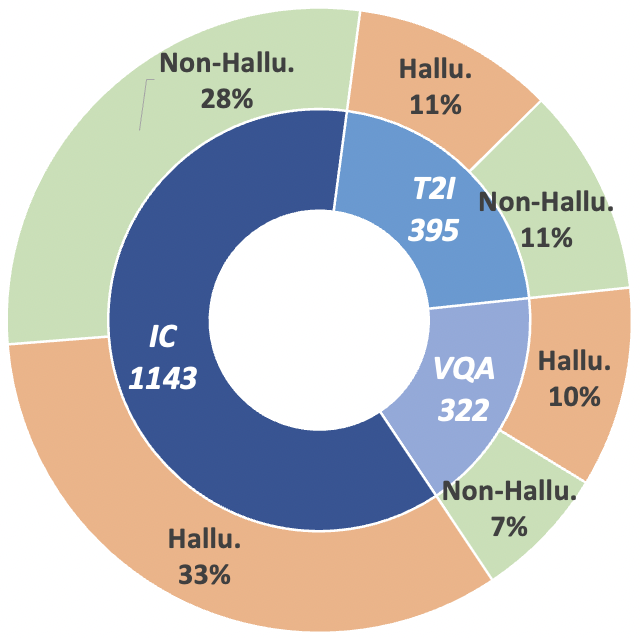
Figure 2: Claim-Level data statistics of MHaluBench. "IC" signifies Image Captioning and "T2I" indicates Text-to-Image synthesis, respectively.
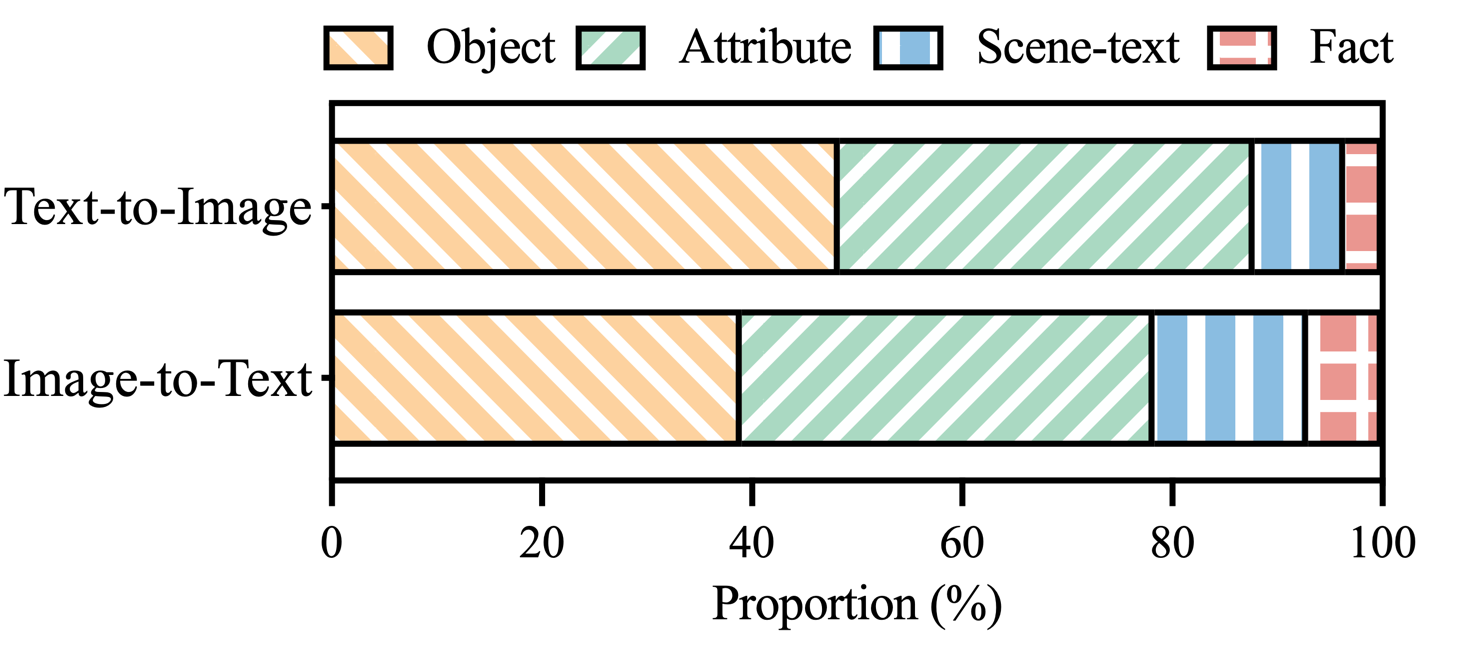
Figure 3: Distribution of hallucination categories within hallucination-labeled claims of MHaluBench.
Addressing the key challenges in hallucination detection, we introduce a unified framework in Figure 4 that systematically tackles multimodal hallucination identification for both image-to-text and text-to-image tasks. Our framework capitalizes on the domain-specific strengths of various tools to efficiently gather multi-modal evidence for confirming hallucinations.
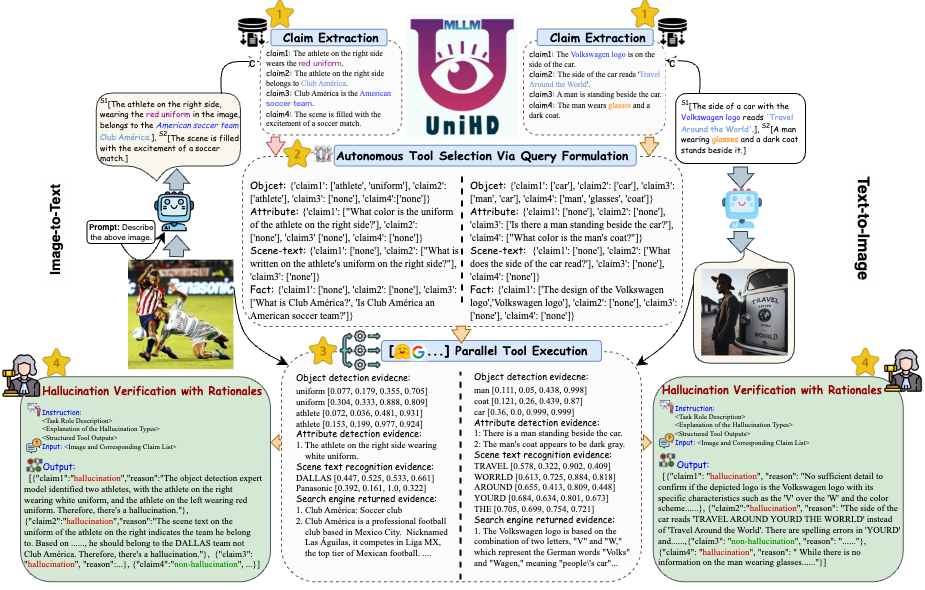
Figure 4: The specific illustration of UniHD for unified multimodal hallucination detection.
You can download two versions of HalDet-LLaVA, 7b and 13b, on three platforms: HuggingFace, ModelScope, and WiseModel.
| HuggingFace | ModelScope | WiseModel |
|---|---|---|
| HalDet-llava-7b | HalDet-llava-7b | HalDet-llava-7b |
| HalDet-llava-13b | HalDet-llava-13b | HalDet-llava-13b |
The claim level results on validation dataset
Self-Check(GPT-4V) means use GPT-4V with 0 or 2 cases
UniHD(GPT-4V/GPT-4o) means use GPT-4V/GPT-4o with 2-shot and tool information
HalDet (LLAVA) means use LLAVA-v1.5 trained on our train datasets
| task type | model | Acc | Prec avg | Recall avg | Mac.F1 |
| image-to-text | Self-Check 0shot (GPV-4V) | 75.09 | 74.94 | 75.19 | 74.97 |
| Self-Check 2shot (GPV-4V) | 79.25 | 79.02 | 79.16 | 79.08 | |
| HalDet (LLAVA-7b) | 75.02 | 75.05 | 74.18 | 74.38 | |
| HalDet (LLAVA-13b) | 78.16 | 78.18 | 77.48 | 77.69 | |
| UniHD(GPT-4V) | 81.91 | 81.81 | 81.52 | 81.63 | |
| UniHD(GPT-4o) | 86.08 | 85.89 | 86.07 | 85.96 | |
| text-to-image | Self-Check 0shot (GPV-4V) | 76.20 | 79.31 | 75.99 | 75.45 |
| Self-Check 2shot (GPV-4V) | 80.76 | 81.16 | 80.69 | 80.67 | |
| HalDet (LLAVA-7b) | 67.35 | 69.31 | 67.50 | 66.62 | |
| HalDet (LLAVA-13b) | 74.74 | 76.68 | 74.88 | 74.34 | |
| UniHD(GPT-4V) | 85.82 | 85.83 | 85.83 | 85.82 | |
| UniHD(GPT-4o) | 89.29 | 89.28 | 89.28 | 89.28 |
To view more detailed information about HalDet-LLaVA and the train dataset, please refer to the readme.
Installation for local development:
git clone https://github.com/zjunlp/EasyDetect.git cd EasyDetect pip install -r requirements.txt
Installation for tools(GroundingDINO and MAERec):
# install GroundingDINO git clone https://github.com/IDEA-Research/GroundingDINO.git cp -r GroundingDINO pipeline/GroundingDINO cd pipeline/GroundingDINO/ pip install -e . cd .. # install MAERec git clone https://github.com/Mountchicken/Union14M.git cp -r Union14M/mmocr-dev-1.x pipeline/mmocr cd pipeline/mmocr/ pip install -U openmim mim install mmengine mim install mmcv mim install mmdet pip install timm pip install -r requirements/albu.txt pip install -r requirements.txt pip install -v -e . cd .. mkdir weights cd weights wget -q https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth wget https://download.openmmlab.com/mmocr/textdet/dbnetpp/dbnetpp_resnet50-oclip_fpnc_1200e_icdar2015/dbnetpp_resnet50-oclip_fpnc_1200e_icdar2015_20221101_124139-4ecb39ac.pth -O dbnetpp.pth wget https://github.com/Mountchicken/Union14M/releases/download/Checkpoint/maerec_b_union14m.pth -O maerec_b.pth cd ..
We provide example code for users to quickly get started with EasyDetect.
Users can easily configure the parameters of EasyDetect in a yaml file or just quickly use the default parameters in the configuration file we provide. The path of the configuration file is EasyDetect/pipeline/config/config.yaml
openai: api_key: Input your openai api key base_url: Input base_url, default is None temperature: 0.2 max_tokens: 1024tool: detect:groundingdino_config: the path of GroundingDINO_SwinT_OGC.pymodel_path: the path of groundingdino_swint_ogc.pthdevice: cuda:0BOX_TRESHOLD: 0.35TEXT_TRESHOLD: 0.25AREA_THRESHOLD: 0.001 ocr:dbnetpp_config: the path of dbnetpp_resnet50-oclip_fpnc_1200e_icdar2015.pydbnetpp_path: the path of dbnetpp.pthmaerec_config: the path of maerec_b_union14m.pymaerec_path: the path of maerec_b.pthdevice: cuda:0content: word.numbercachefiles_path: the path of cache_files to save temp imagesBOX_TRESHOLD: 0.2TEXT_TRESHOLD: 0.25 google_serper:serper_api_key: Input your serper api keysnippet_cnt: 10prompts: claim_generate: pipeline/prompts/claim_generate.yaml query_generate: pipeline/prompts/query_generate.yaml verify: pipeline/prompts/verify.yaml
Example Code
from pipeline.run_pipeline import *pipeline = Pipeline()text = "The cafe in the image is named "Hauptbahnhof""image_path = "./examples/058214af21a03013.jpg"type = "image-to-text"response, claim_list = pipeline.run(text=text, image_path=image_path, type=type)print(response)print(claim_list)
Please cite our repository if you use EasyDetect in your work.
@article{chen23factchd, author = {Xiang Chen and Duanzheng Song and Honghao Gui and Chengxi Wang and Ningyu Zhang and Jiang Yong and Fei Huang and Chengfei Lv and Dan Zhang and Huajun Chen}, title = {FactCHD: Benchmarking Fact-Conflicting Hallucination Detection}, journal = {CoRR}, volume = {abs/2310.12086}, year = {2023}, url = {https://doi.org/10.48550/arXiv.2310.12086}, doi = {10.48550/ARXIV.2310.12086}, eprinttype = {arXiv}, eprint = {2310.12086}, biburl = {https://dblp.org/rec/journals/corr/abs-2310-12086.bib}, bibsource = {dblp computer science bibliography, https://dblp.org}}@inproceedings{chen-etal-2024-unified-hallucination,title = "Unified Hallucination Detection for Multimodal Large Language Models",author = "Chen, Xiang and Wang, Chenxi and Xue, Yida and Zhang, Ningyu and Yang, Xiaoyan and Li, Qiang and Shen, Yue and Liang, Lei and Gu, Jinjie and Chen, Huajun",editor = "Ku, Lun-Wei and Martins, Andre and Srikumar, Vivek",booktitle = "Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",month = aug,year = "2024",address = "Bangkok, Thailand",publisher = "Association for Computational Linguistics",url = "https://aclanthology.org/2024.acl-long.178",pages = "3235--3252",
}We will offer long-term maintenance to fix bugs, solve issues and meet new requests. So if you have any problems, please put issues to us.


