QuillGPT
1.0.0

QuillGPT is an implementation of the GPT decoder block based on the architecture from Attention is All You Need paper by Vaswani et. al. implemented in PyTorch. Additionally, this repository contains two pre-trained models—Shakespearean GPT and Harpoon GPT—along with their trained weights. For ease of experimentation and deployment, a Streamlit Playground is provided for interactive exploration of these models and FastAPI microservice implemented with Docker containerization for scalable deployment. You'll also find Python scripts for training new GPT models and performing inference on them, along with notebooks showcasing trained models. To facilitate text encoding and decoding, a simple tokenizer is implemented. Explore QuillGPT to utilize these tools and enhance your natural language processing projects!
There are two pre-trained models and weights included in this repository.
| Feature | Shakespearean GPT | Harpoon GPT |
|---|---|---|
| Parameters | 10.7 M | 226 M |
| Weights | Weights | Weights |
| Model Config | Config | Config |
| Training Data | Text from Shakespearean plays (input.txt) | Random text from books (corpus.txt) |
| Embedding Type | Character embeddings | Character embeddings |
| Training Notebook | Notebook | Notebook |
| Hardware | NVIDIA T4 | NVIDIA A100 |
| Training & Validation Loss | 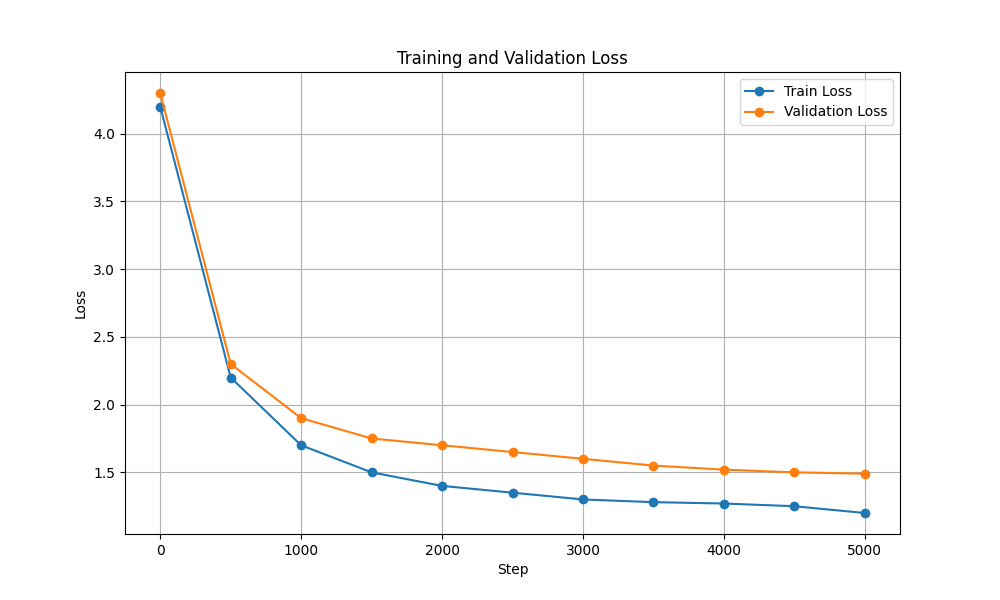 |
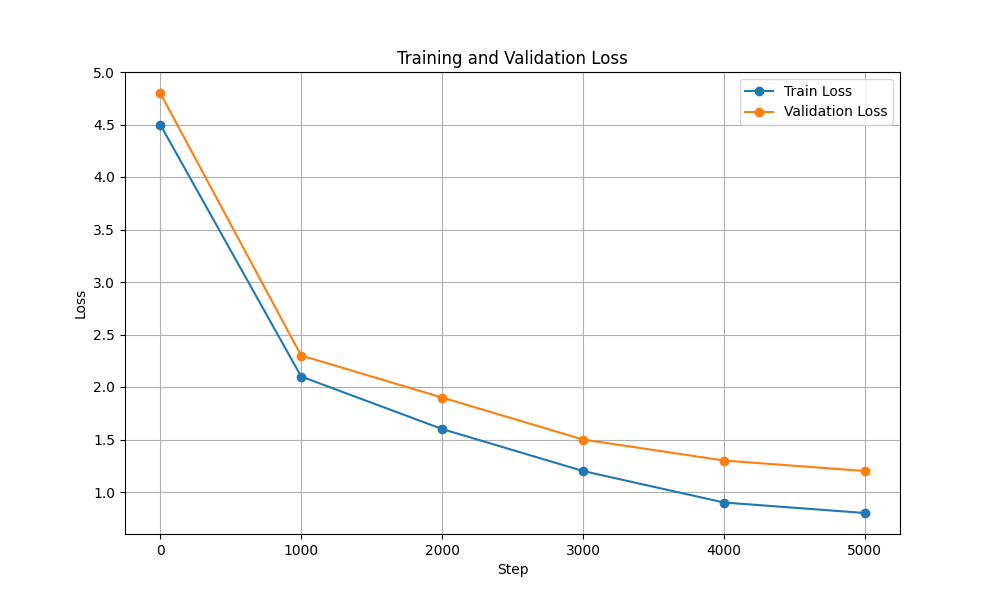 |
To run the training and inference scripts, follow these steps:
git clone https://github.com/NotShrirang/GPT-From-Scratch.git
cd GPT-From-Scratchpip install -r requirements.txtMake sure you download the weights for Harpoon GPT from here before proceeding!
It is hosted on Streamlit Cloud Service. You can visit it through the link here.
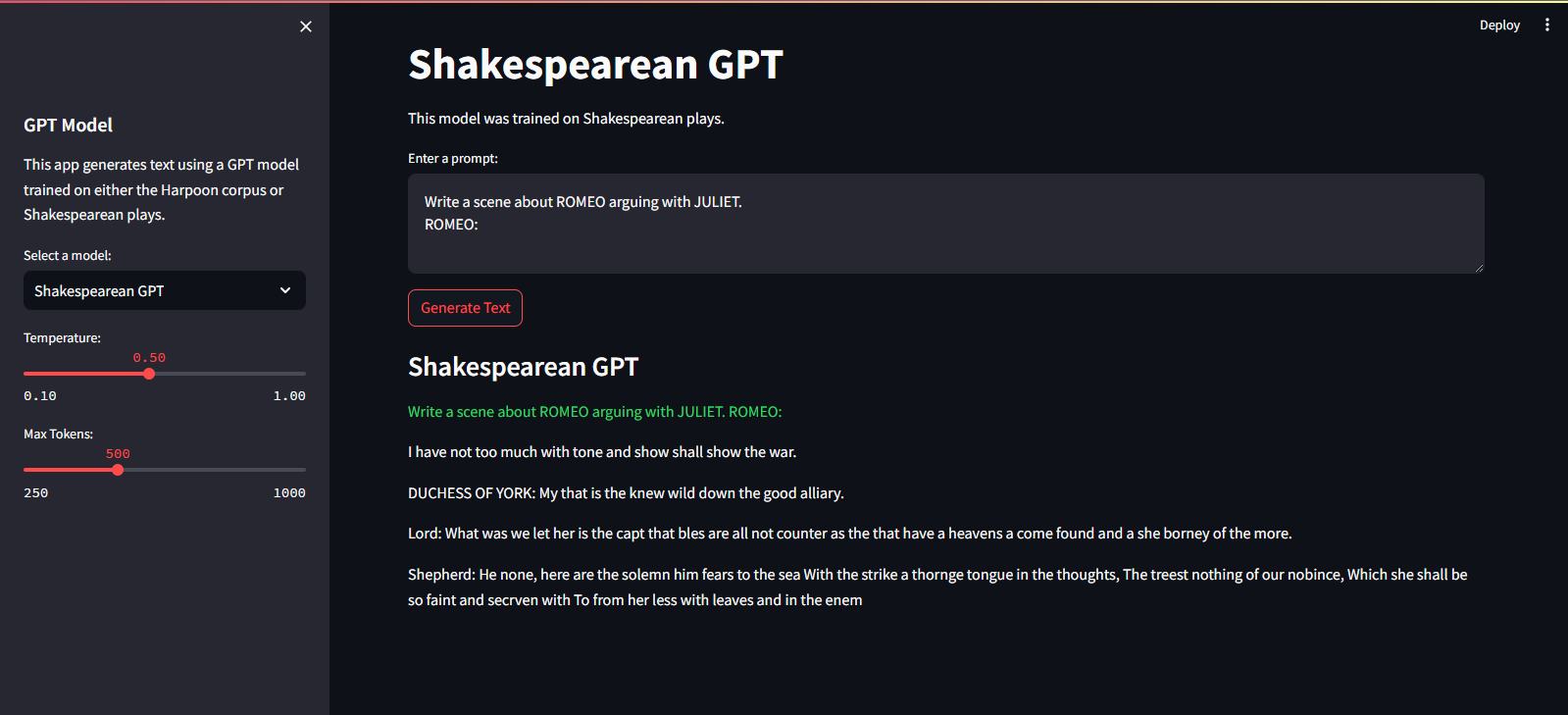
streamlit run app.pypython main.py./run.sh start-dev./run.sh stop-devTo train the GPT model, follow these steps:
Prepare data. Put the whole text data into single .txt file and save it.
Write the configurations for transformer and save the file.
For example:
json { "data_path": "data/corpus.txt", "vocab_size": 135, "batch_size": 32, "block_size": 256, "max_iters": 3000, "eval_interval": 300, "learning_rate": 3e-5, "eval_iters": 50, "n_embd": 1024, "n_head": 12, "n_layer": 18, "dropout": 0.3, }
Train model using script scripts/train_gpt.py
python scripts/train_gpt.py
--config_path config/config.json
--data_path data/corpus.txt
--output_dir trained_models(You can change the config_path, data_path and output_dir as per your requirements.)
output_dir specified in the command.After training, you can use the trained GPT model for text generation. Here's an example of using the trained model for inference:
python scripts/inference_gpt.py
--config_path config/shakespearean_config.json
--weights_path weights/GPT_model_char.pt
--max_length 500
--prompt "Once upon a time"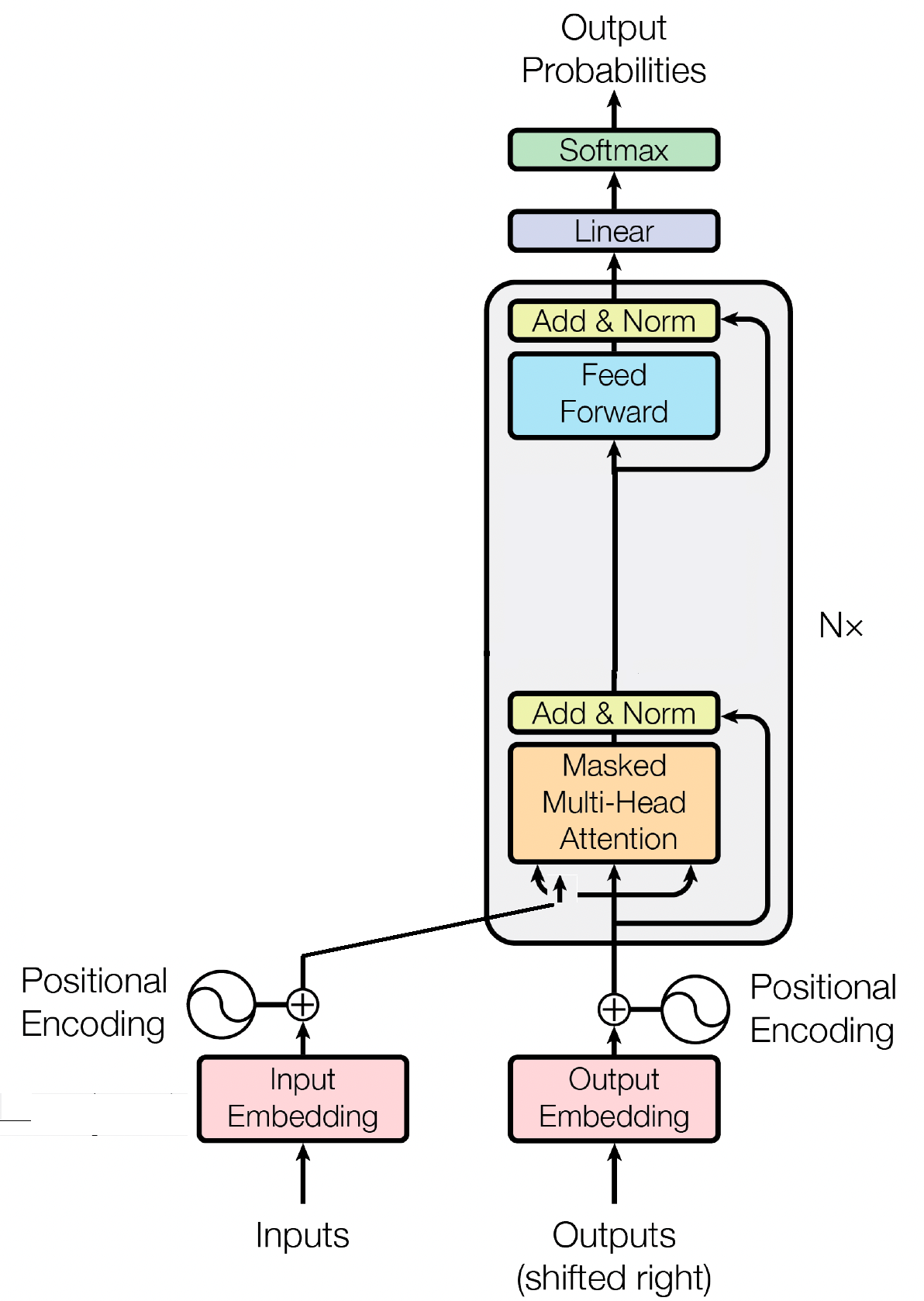
The decoder block is a crucial component of the GPT (Generative Pre-trained Transformer) model, it is where GPT actually generates the text. It leverages the self-attention mechanism to process input sequences and generate coherent outputs. Each decoder block consists of multiple layers, including self-attention layers, feed-forward neural networks, and layer normalization. The self-attention layers allow the model to weigh the importance of different words in a sequence, capturing context and dependencies regardless of their positions. This enables the GPT model to generate contextually relevant text.
Input embeddings play a crucial role in transformer-based models like GPT by transforming input tokens into meaningful numerical representations. These embeddings serve as the initial input for the model, capturing semantic information about the words in the sequence. The process involves mapping each token in the input sequence to a high-dimensional vector space, where similar tokens are positioned closer together. This enables the model to understand the relationships between different words and effectively learn from the input data. The input embeddings are then fed into the subsequent layers of the model for further processing.
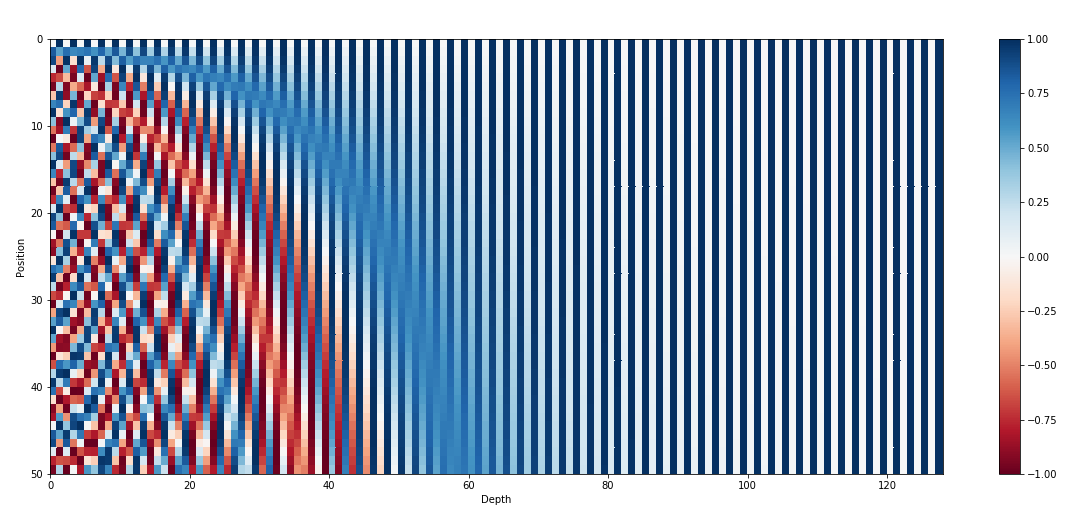
In addition to input embeddings, positional embeddings are another vital component of transformer architectures such as GPT. Since transformers lack inherent information about the order of tokens in a sequence, positional embeddings are introduced to provide the model with positional information. These embeddings encode the position of each token within the sequence, allowing the model to distinguish between tokens based on their positions. By incorporating positional embeddings, transformers like GPT can effectively capture the sequential nature of data and generate coherent outputs that maintain the correct order of words in the generated text.

Self-attention, a fundamental mechanism in transformer-based models like GPT, operates by assigning importance scores to different words in a sequence. This process involves three key steps: calculating attention scores, applying softmax to obtain attention weights, and finally combining these weights with the input embeddings to generate contextually informed representations. At its core, self-attention allows the model to focus more on relevant words while de-emphasizing less important ones, facilitating effective learning of contextual dependencies within the input data. This mechanism is pivotal in capturing long-range dependencies and contextual nuances, enabling transformer models to generate long sequences of text.
MIT © Shrirang Mahajan
Feel free to submit pull requests, create issues, or spread the word!
Support me by simply starring this repository!


