While exploring cryptography I found a Khan Academy's video that peaked my interest in the flaws of the infamous Caesar's cipher.
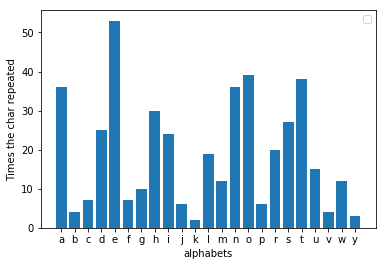
Whenever you write long letter or an email in English, you unintentionally leave a fingerprint behind; if you scan a message you've written and count the frequency of each letter, you'll find a fairly consistent pattern. 'e' will most likely be the most recurring letter in the entire message. I took a random fable from the internet to test this out and the result I attained was what was to be expected from it. 'e' was indeed the most popular letter. This fact holds true for any message that is long enough.
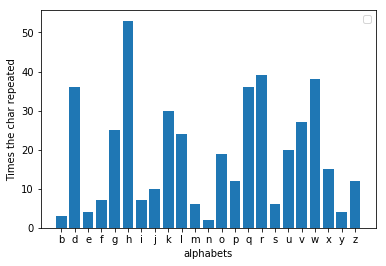
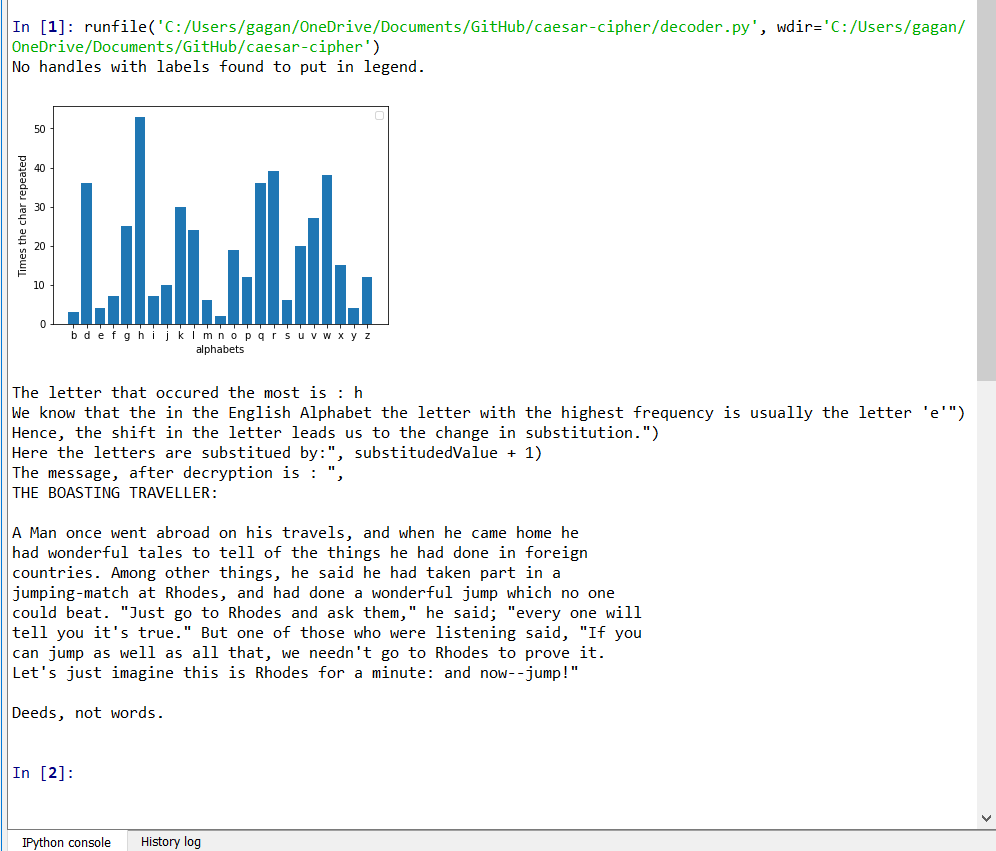
The flaw that Al-kindi found was that, when you analyze the frequency of the encrypted message, a different letter now recurs the most. If you check how far the letter is shifted from three, you could find the value the message is substituted by. For example, if 'h' is the most popular letter in the encrypted message, then the shift was likely three. Now by reversing the shift, we could get the original message easily. In the decoder.py when you feed it an encrypted file, it decrypts the message and prints it. I encrypted the same fable by shifting the alphabets by three letters and it turns out that 'h' is indeed the most popular letter here.
To reproduce the results of my cipher and to explore it with other messages, in addition to python you must have matplotlib installed.
pip install matplotlibRemember: The decoder works on the principle of linguistics and statistics, so longer the message, more accurate the result.
Gagan Devagiri © MIT


