This guide will help you assemble and test a developer preview version of the RHEL AI product.
Welcome to the Red Hat Enterprise Linux AI Developer Preview! This guide is meant to introduce you to RHEL AI Developer Preview capabilities. As with other Developer Previews, expect changes to these workflows, additional automation and simplification, as well as a broadening of capabilities, hardware and software support versions, performance improvements (and other optimizations) prior to GA.
RHEL AI is an open-source product that includes:
Note
RHEL AI is targeted at server platforms and workstations with discrete GPUs. For laptops, please use upstream InstructLab.
Here is a list of servers validated by Red Hat engineers to work with the RHEL AI Developer Preview. We anticipate that recent systems certified to run RHEL 9, with recent datacenter GPUs such as those listed below, will work with this Developer Preview.
| GPU Vendor / Specs | RHEL AI Dev Preview |
|---|---|
| Dell (4) NVIDIA H100 | Yes |
IBM GX3 Instances |
Yes |
| Lenovo (8) AMD MI300x | Yes |
| AWS p4 and p5 instances (NVIDIA) | Ongoing |
| Intel | Ongoing |
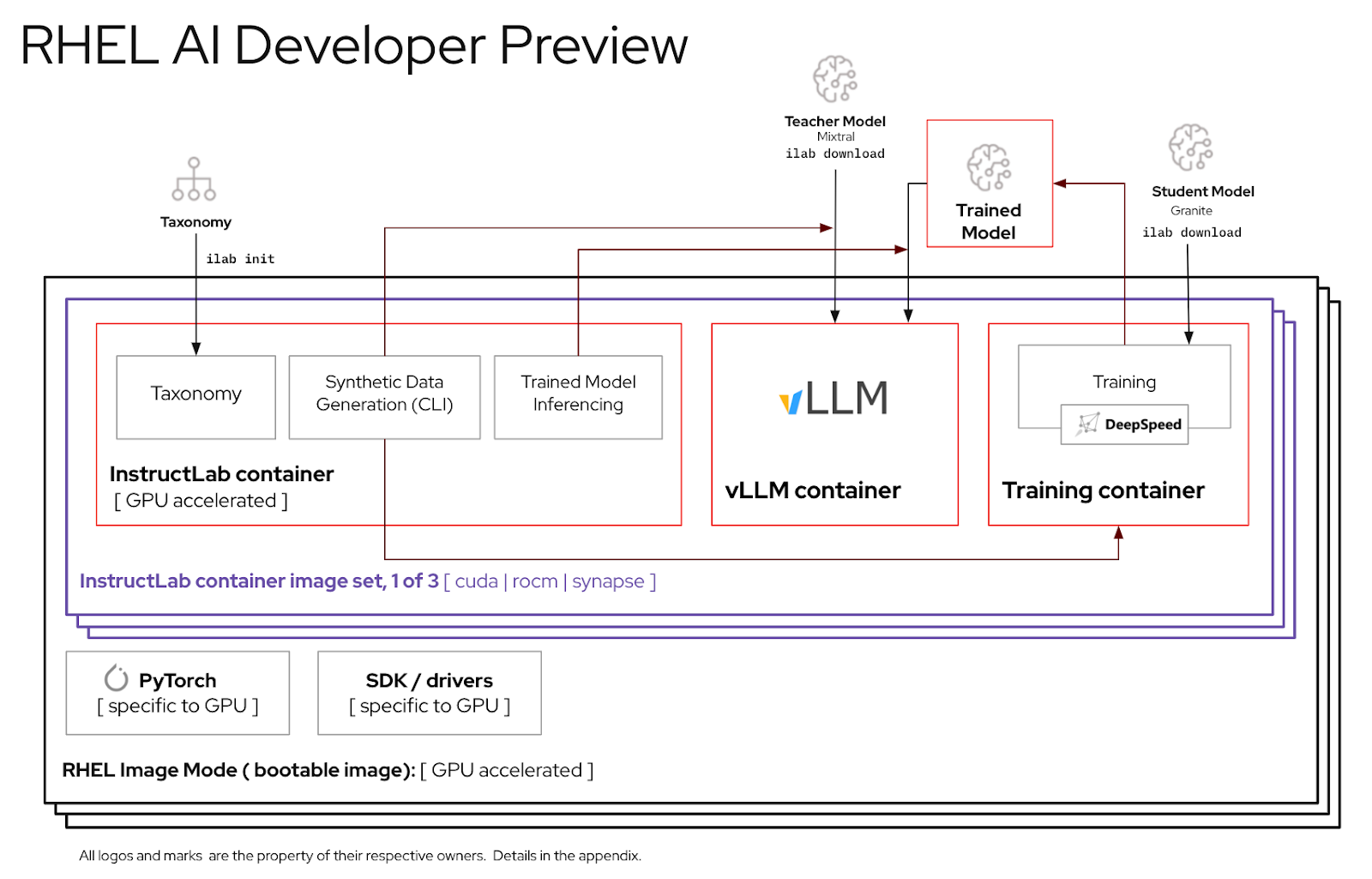
For the best experience using the RHEL AI developer preview period, we have included a pruned taxonomy tree inside the InstructLab container. This will allow for validating training to complete in a reasonable time frame on a single server.
Formula:
A single GPU can train ~250 samples per minute.
If you have 8 GPUs and 10,000 samples, expect it to take
By the end of this exercise, you’ll have:
bootc is a transactional, in-place
operating system that provisions and updates using OCI/Docker container images.
bootc is the key component in a broader mission of bootable containers.
The original Docker container model of using "layers" to model applications has been extremely successful. This project aims to apply the same technique for bootable host systems - using standard OCI/Docker containers as a transport and delivery format for base operating system updates.
The container image includes a Linux kernel (in e.g. /usr/lib/modules), which is
used to boot. At runtime on a target system, the base userspace is not itself
running in a container by default. For example, assuming systemd is in use,
systemd acts as pid1 as usual - there's no "outer" process.
In the following example, the bootc container is labeled Node Base Image:
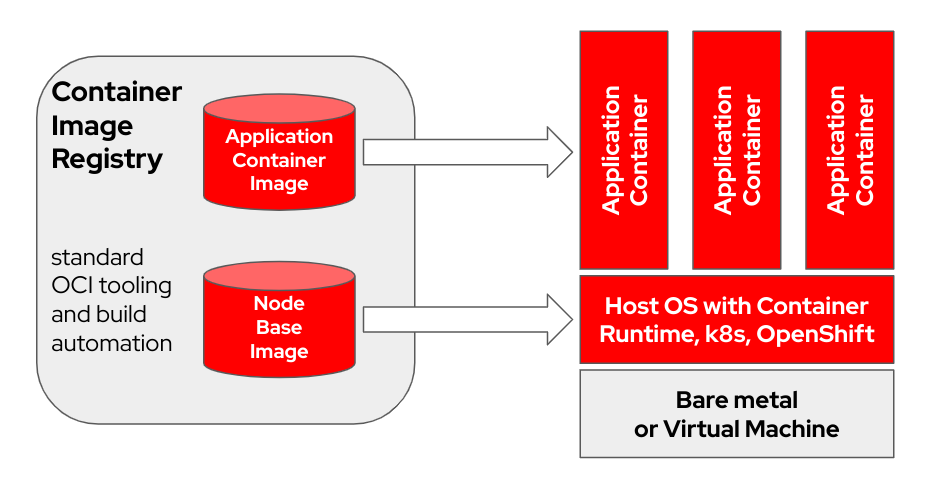
Depending on your build host hardware and internet connection speed, building and uploading container images could take up to 2 hours.
m5.xlarge using GP3 storage)quay.io or another image registry.Register the host (How to register and subscribe a RHEL system to the Red Hat Customer Portal using Red Hat Subscription-Manager?)
sudo subscription-manager register --username <username> --password <password>Install required packages
sudo dnf install git make podman buildah lorax -yClone the RHEL AI Developer Preview git repo
git clone https://github.com/RedHatOfficial/rhelai-dev-previewAuthenticate to the Red Hat registry (Red Hat Container Registry
Authentication) using your
redhat.com account.
podman login registry.redhat.io --username <username> --password <password>
podman login --get-login registry.redhat.io
Your_login_hereEnsure you have an SSH key on the build host. This is used during the driver
toolkit image build. (Using ssh-keygen and sharing for key-based authentication
in Linux | Enable Sysadmin)
RHEL AI includes a set of Makefiles to facilitate creating the container images. Depending on your build host hardware and internet connection speed, this could take up to an hour.
Build the InstructLab NVIDIA container image.
make instruct-nvidiaBuild the vllm container image.
make vllmBuild the deepspeed container image.
make deepspeedLast, build the RHEL AI NVIDIA bootc container image. This is the RHEL
Image-mode “bootable” container. We embed the 3 images above into this
container.
make nvidia FROM=registry.redhat.io/rhel9/rhel-bootc:9.4 REGISTRY=<your-registry> REGISTRY_ORG=<your-org-name>The resulting image is tagged ${REGISTRY}/${REGISTRY_ORG}/nvidia-bootc:latest.
For more variables and examples, see the
training/README.
Push the resulting image to your registry. You will refer to this URL inside a kickstart file in an upcoming step.
podman push ${REGISTRY}/${REGISTRY_ORG}/nvidia-bootc:latest
e.g. podman push quay.io/<your-user-name>/nvidia-bootc.latestAt this point you have a RHEL AI bootable container image ready to be installed on a physical or virtual host.
Anaconda is the Red Hat Enterprise Linux installer, and it is embedded in all RHEL downloadable ISO images. The main method of automating RHEL installation is via scripts called Kickstart. For more information about Anaconda and Kickstart, read these documents.
A recent kickstart command called
ostreecontainer
was introduced with RHEL 9.4. We use ostreecontainer to provision the bootable
nvidia-bootc container you just pushed to your registry over the network.
Here is an example of a kickstart file. Copy it to a file called
rhelai-dev-preview-bootc.ks, and customize it for your environment:
# text
## customize this for your target system
# network --bootproto=dhcp --device=link --activate
## Basic partitioning
## customize this for your target system
# clearpart --all --initlabel --disklabel=gpt
# reqpart --add-boot
# part / --grow --fstype xfs
# ostreecontainer --url quay.io/<your-user-name>/nvidia-bootc:latest
# firewall --disabled
# services --enabled=sshd
## optionally add a user
# user --name=cloud-user --groups=wheel --plaintext --password
# sshkey --username cloud-user "ssh-ed25519 AAAAC3Nza....."
## if desired, inject an SSH key for root
# rootpw --iscrypted locked
# sshkey --username root "ssh-ed25519 AAAAC3Nza..."
# reboot
Download the RHEL
9.4
“Boot ISO”, and use mkksiso command to embed the kickstart into the RHEL
boot ISO.
mkksiso rhelai-dev-preview-bootc.ks rhel-9.4-x86_64-boot.iso rhelai-dev-preview-bootc-ks.isoAt this point you should have:
nvidia-bootc:latest: a bootable container image with support for NVIDIA GPUsrhelai-dev-preview-bootc.ks: a kickstart file customized to provision RHEL from your container registry to your target system.rhelai-dev-preview-bootc-ks.iso: a bootable RHEL 9.4 ISO with the kickstart embedded.Boot your target system using the rhelai-dev-preview-bootc-ks.iso file.
anaconda will pull the nvidia-bootc:latest image from your registry and
provision RHEL according to your kickstart file.
Alternative: the kickstart file can be served via HTTP. On the installation via kernel command line and an external HTTP server – add inst.ks=http(s)://kickstart/url/rhelai-dev-preview-bootc.ks
Before using the RHEL AI environment, you must download two models, each tailored to a key function in the high-fidelity tuning process. Granite is used as the student model and is responsible for facilitating the training of a new fine-tuned mode. Mixtral is used as the teacher model and is responsible for aiding the generation phase of the LAB process, where skills and knowledge are used in concert to produce a rich training dataset.
Settings.Access Tokens. Click the New token button and provide a name. The
new token only requires the use of Read permissions since it's only being
used to fetch models. On this screen, you will be able to generate the token
content and save and copy the text to authenticate.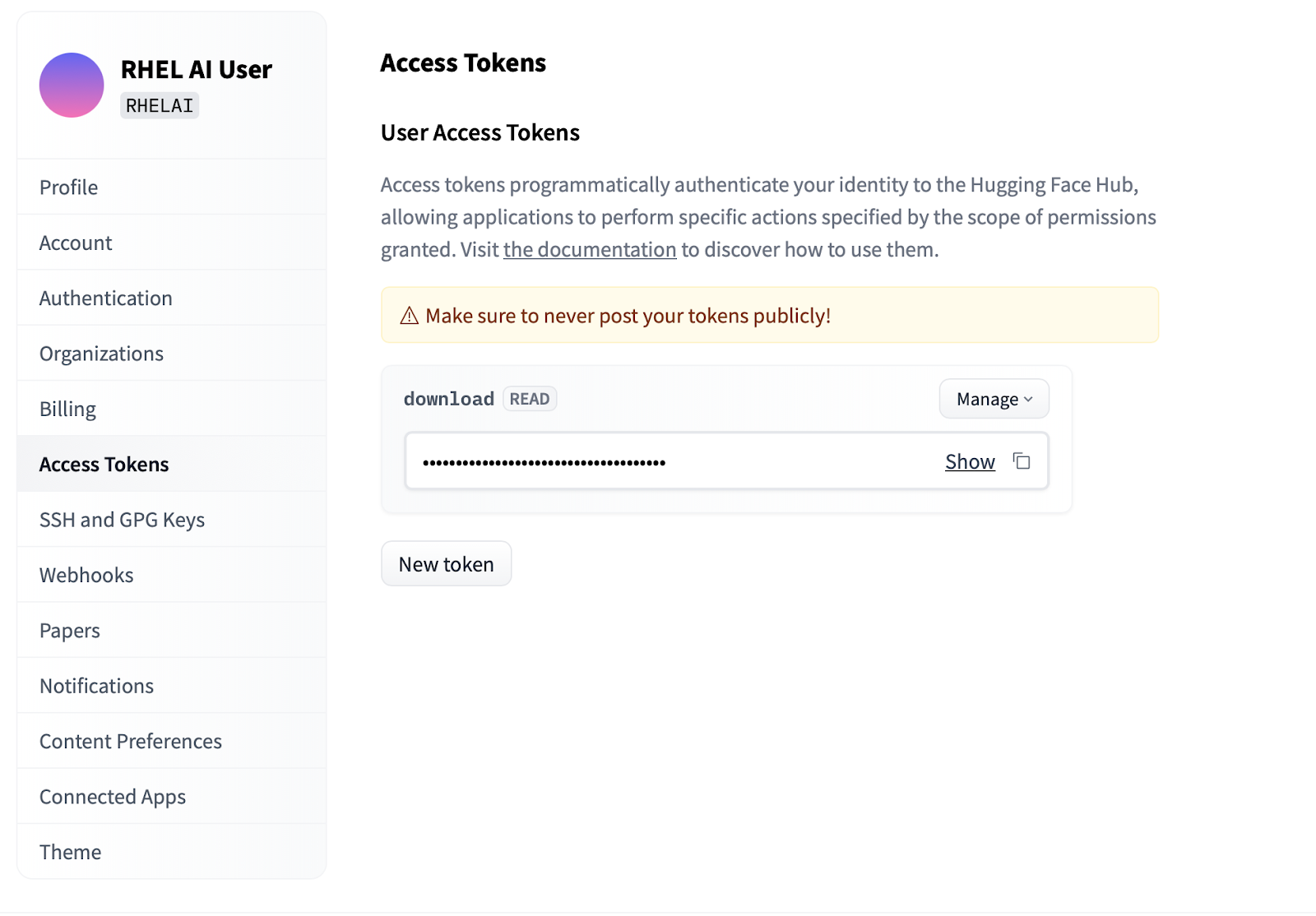
The ilab command line interface that is part of the InstructLab project focuses
on running lightweight quantized models on personal computing devices like
laptops. In contrast, RHEL AI enables the use of high-fidelity training using
full-precision models. For familiarity, the command and parameters mirror that
of InstructLab’s ilab command; however, the backing implementation is very
different.
In RHEL AI, the
ilabcommand is a wrapper that acts as a front-end to a container architecture pre-bundled on the RHEL AI system.
ilab Command Line InterfaceThe first step is to create a new working directory for your project. Everything will be relative to this working directory. It will contain your models, logs, and training data.
mkdir my-project
cd my-projectThe very first ilab command you will run sets up the base environment, including
downloading the taxonomy repo if you choose. This will be needed for later
steps, so it is recommended to do so.
ilab initDefine an environment variable using the HF token you created in the above section under Access Tokens.
export HF_TOKEN=<paste token value here>Next, download the IBM Granite base model. Important: Do not download the “lab” versions of the model. The granite base model is most effective when performing high-fidelity training.
ilab download --repository ibm/granite-7b-baseFollow the same process to download the Mixtral model.
ilab download --repository mistralai/Mixtral-8x7B-Instruct-v0.1Now that you have initialized your project and downloaded your first models, observe the directory structure of your project
my-project/
├─ models/
├─ generated/
├─ taxonomy/
├─ training/
├─ training_output/
├─ cache/
| Folder | Purpose |
|---|---|
| models | Holds all language models, including the saved output of ones you generate with RHEL AI |
| generated | Generated data output from the generation phase, built on modifications to the taxonomy repository |
| taxonomy | Skill or Knowledge data used by the LAB method to generate synthetic data for training |
| training | Converted seed data to facilitate the training process |
| training_output | All transient output of the training process, including logs and in-flight sample checkpoints |
| cache | An internal cache used by the model data |
The next step is to contribute new knowledge or skills into the taxonomy repo. See the InstructLab documentation for more information and examples of how to do this. We also have a set of lab exercises here.
With the additional taxonomy data added, it’s now possible to generate new synthetic data to eventually train a new model. Although, before generation can begin, a teacher model first needs to be started to assist the generator in constructing new data. In a separate terminal session, run the “serve” command and wait for the VLLM startup to complete. Note this process can take several minutes to complete
ilab serve
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)Now that VLLM is serving the teacher mode, the generation process can be started
using the ilab generate command. This process will take some time to complete
and will continually output the total number of instructions generated as it is
updated. This defaults to 5000 instructions, but you can adjust this with the
--num-instructions option.
ilab generateQ> How do cytokines influence the outcome of certain diseases involving tonsils?
A> The outcome of infectious, autoimmune, or malignant diseases affecting tonsils may be influenced by the overall balance of production profiles of pro-inflammatory and anti-inflammatory cytokines. Determining cytokine profiles in tonsil studies is essential for understanding the causes and underlying mechanisms of these disorders.
35%|████████████████████████████████████████▉
In addition to the current data printed to the screen during generation, a full output is recorded in the generated folder. Before training it is recommended to review this output to verify it meets expectations. If it is not satisfactory, try modifying or creating new examples in the taxonomy and rerunning.
less generated/generated_Mixtral*.jsonOnce the generated data is satisfactory, the training process can begin. Although first close the VLLM instance in the terminal session that was started for generation.
CTRL+C
INFO: Application shutdown complete.
INFO: Finished server process [1]
You may receive a Python KeyboardInterrupt exception and stack trace. This can be safely ignored.
With VLLM stopped and the new data generated, the training process can be
launched using the ilab train command. By default, the training process
saves a model checkpoint after every 4999 samples. You can adjust this using the
--num-samples parameter. Additionally, training defaults to running for 10
epochs, which can also be adjusted with the --num-epochs parameter. Generally,
more epochs are better, but after a certain point, more epochs will result in
overfitting. It is typically recommended to stay within 10 or fewer epochs and to
look at different sample points to find the best result.
ilab train --num-epochs 9RunningAvgSamplesPerSec=149.4829861942806, CurrSamplesPerSec=161.99957513920629, MemAllocated=22.45GB, MaxMemAllocated=29.08GB
throughput: 161.84935045724643 samples/s, lr: 1.3454545454545455e-05, loss: 0.840185821056366 cuda_mem_allocated: 22.45188570022583 GB cuda_malloc_retries: 0 num_loss_counted_tokens: 8061.0 batch_size: 96.0 total loss: 0.8581467866897583
Epoch 1: 100%|█████████████████████████████████████████████████████████| 84/84 [01:09<00:00, 1.20it/s]
total length: 2527 num samples 15 - rank: 6 max len: 187 min len: 149
Once the training process has completed, the new model entries will be stored in the models directory with locations printed to the terminal
Generated model in /root/workspace/models/tuned-0504-0051:
.
./samples_4992
./samples_9984
./samples_14976
./samples_19968
./samples_24960
./samples_29952
./samples_34944
./samples_39936
./samples_44928
./samples_49920
The same ilab serve command can be used to serve the new model by passing the
–model option with the name and sample
ilab serve --model tuned-0504-0051/samples_49920After VLLM has started with the new model, a chat session can be launched by
creating a new terminal session and passing the same --model parameter to chat
(Note that if this does not match, you will receive a 404 error message). Ask
it a question related to your taxonomy contributions.
ilab chat --model tuned-0504-0051/samples_49920╭─────────────────────────────── system ────────────────────────────────╮
│ Welcome to InstructLab Chat w/ │
│ /INSTRUCTLAB/MODELS/TUNED-0504-0051/SAMPLES_49920 (type /h for help) │
╰───────────────────────────────────────────────────────────────────────╯
>>> What are tonsils?
╭────────── /instructlab/models/tuned-0504-0051/samples_49920 ──────────╮
│ │
│ Tonsils are a type of mucosal lymphatic tissue found in the │
│ aerodigestive tracts of various mammals, including humans. In the │
│ human body, the tonsils play a crucial role in protecting the body │
│ from infections, particularly those caused by bacteria and viruses. │
╰─────────────────────────────────────────────── elapsed 0.469 seconds ─╯To exit the session, type
exit
That’s it! The purpose of a Developer Preview is to get something out to our users for early feedback. We realize there may be bugs. And we appreciate your time and effort if you’ve made it this far. Chances are you hit some issues or needed to troubleshoot. We encourage you to file bug reports, feature requests, and ask us questions. See the contact information below for how to do that. Thank you!
$ sudo subscription-manager config --rhsm.manage_repos=1
nvidia-smi to make sure the drivers work and can see the GPUsnvtop (available in EPEL) to see whether the GPUs are being used (some code paths have CPU fallback, which we don’t want here)make prune out of the training subdirectory. This will clean up old build artifacts.--no-cache parameter to the build processmake nvidia-bootc CONTAINER_TOOL_EXTRA_ARGS="--no-cache"TMPDIR environment variable:make <platform> TMPDIR=/path/to/tmp

