bigwig loader
v0.1.4
Fast batched dataloading of BigWig files containing epigentic track data and corresponding sequences powered by GPU for deep learning applications.
Bigwig-loader mainly depends on the rapidsai kvikio library and cupy, both of which are best installed using conda/mamba. Bigwig-loader can now also be installed using conda/mamba. To create a new environment with bigwig-loader installed:
mamba create -n my-env -c rapidsai -c conda-forge -c bioconda -c dataloading bigwig-loaderOr add this to you environment.yml file:
name: my-env
channels:
- rapidsai
- conda-forge
- bioconda
- dataloading
dependencies:
- bigwig-loaderand update:
mamba env update -f environment.ymlBigwig-loader can also be installed using pip in an environment which has the rapidsai kvikio library and cupy installed already:
pip install bigwig-loaderWe wrapped the BigWigDataset in a PyTorch iterable dataset that you can directly use:
# examples/pytorch_example.py
import pandas as pd
import torch
from torch.utils.data import DataLoader
from bigwig_loader import config
from bigwig_loader.pytorch import PytorchBigWigDataset
from bigwig_loader.download_example_data import download_example_data
# Download example data to play with
download_example_data()
example_bigwigs_directory = config.bigwig_dir
reference_genome_file = config.reference_genome
train_regions = pd.DataFrame({"chrom": ["chr1", "chr2"], "start": [0, 0], "end": [1000000, 1000000]})
dataset = PytorchBigWigDataset(
regions_of_interest=train_regions,
collection=example_bigwigs_directory,
reference_genome_path=reference_genome_file,
sequence_length=1000,
center_bin_to_predict=500,
window_size=1,
batch_size=32,
super_batch_size=1024,
batches_per_epoch=20,
maximum_unknown_bases_fraction=0.1,
sequence_encoder="onehot",
n_threads=4,
return_batch_objects=True,
)
# Don't use num_workers > 0 in DataLoader. The heavy
# lifting/parallelism is done on cuda streams on the GPU.
dataloader = DataLoader(dataset, num_workers=0, batch_size=None)
class MyTerribleModel(torch.nn.Module):
def __init__(self):
super().__init__()
self.linear = torch.nn.Linear(4, 2)
def forward(self, batch):
return self.linear(batch).transpose(1, 2)
model = MyTerribleModel()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
def poisson_loss(pred, target):
return (pred - target * torch.log(pred.clamp(min=1e-8))).mean()
for batch in dataloader:
# batch.sequences.shape = n_batch (32), sequence_length (1000), onehot encoding (4)
pred = model(batch.sequences)
# batch.values.shape = n_batch (32), n_tracks (2) center_bin_to_predict (500)
loss = poisson_loss(pred[:, :, 250:750], batch.values)
print(loss)
optimizer.zero_grad()
loss.backward()
optimizer.step()A framework agnostic Dataset object can be imported from bigwig_loader.dataset. This dataset object
returns cupy tensors. Cupy tensors adhere to the cuda array interface and can be zero-copy transformed
to JAX or tensorflow tensors.
from bigwig_loader.dataset import BigWigDataset
dataset = BigWigDataset(
regions_of_interest=train_regions,
collection=example_bigwigs_directory,
reference_genome_path=reference_genome_file,
sequence_length=1000,
center_bin_to_predict=500,
window_size=1,
batch_size=32,
super_batch_size=1024,
batches_per_epoch=20,
maximum_unknown_bases_fraction=0.1,
sequence_encoder="onehot",
)See the examples directory for more examples.
This library is meant for loading batches of data with the same dimensionality, which allows for some assumptions that can speed up the loading process. As can be seen from the plot below, when loading a small amount of data, pyBigWig is very fast, but does not exploit the batched nature of data loading for machine learning.
In the benchmark below we also created PyTorch dataloaders (with set_start_method('spawn')) using pyBigWig to compare to the realistic scenario where multiple CPUs would be used per GPU. We see that the throughput of the CPU dataloader does not go up linearly with the number of CPUs, and therefore it becomes hard to get the needed throughput to keep the GPU, training the neural network,saturated during the learning steps.
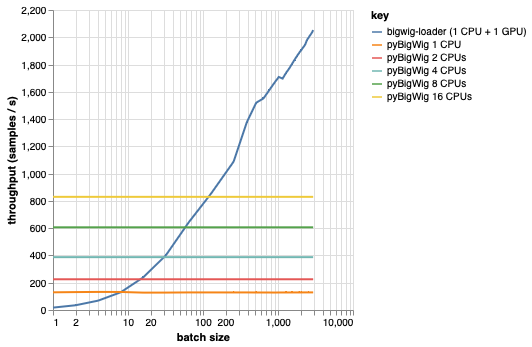
This is the problem bigwig-loader solves. This is an example of how to use bigwig-loader:
git clone [email protected]:pfizer-opensource/bigwig-loadercd bigwig-loaderconda env create -f environment.yml
In this environment you should be able to run pytest -v and see the tests
succeed. NOTE: you need a GPU to use bigwig-loader!
This section guides you through the steps needed to add new functionality. If anything is unclear, please open an issue.
git clone [email protected]:pfizer-opensource/bigwig-loadercd bigwig-loaderconda env create -f environment.yml
pip install -e '.[dev]'pre-commit install to install the pre-commit hooksTests are in the tests directory. One of the most important tests is test_against_pybigwig which makes sure that if there is a mistake in pyBigWIg, it is also in bigwig-loader.
pytest -vv .When github runners with GPU's will become available we would also like to run these tests in the CI. But for now, you can run them locally.
If you use this library, consider citing:
Retel, Joren Sebastian, Andreas Poehlmann, Josh Chiou, Andreas Steffen, and Djork-Arné Clevert. “A Fast Machine Learning Dataloader for Epigenetic Tracks from BigWig Files.” Bioinformatics 40, no. 1 (January 1, 2024): btad767. https://doi.org/10.1093/bioinformatics/btad767.
@article{
retel_fast_2024,
title = {A fast machine learning dataloader for epigenetic tracks from {BigWig} files},
volume = {40},
issn = {1367-4811},
url = {https://doi.org/10.1093/bioinformatics/btad767},
doi = {10.1093/bioinformatics/btad767},
abstract = {We created bigwig-loader, a data-loader for epigenetic profiles from BigWig files that decompresses and processes information for multiple intervals from multiple BigWig files in parallel. This is an access pattern needed to create training batches for typical machine learning models on epigenetics data. Using a new codec, the decompression can be done on a graphical processing unit (GPU) making it fast enough to create the training batches during training, mitigating the need for saving preprocessed training examples to disk.The bigwig-loader installation instructions and source code can be accessed at https://github.com/pfizer-opensource/bigwig-loader},
number = {1},
urldate = {2024-02-02},
journal = {Bioinformatics},
author = {Retel, Joren Sebastian and Poehlmann, Andreas and Chiou, Josh and Steffen, Andreas and Clevert, Djork-Arné},
month = jan,
year = {2024},
pages = {btad767},
}

