nmt
1.0.0
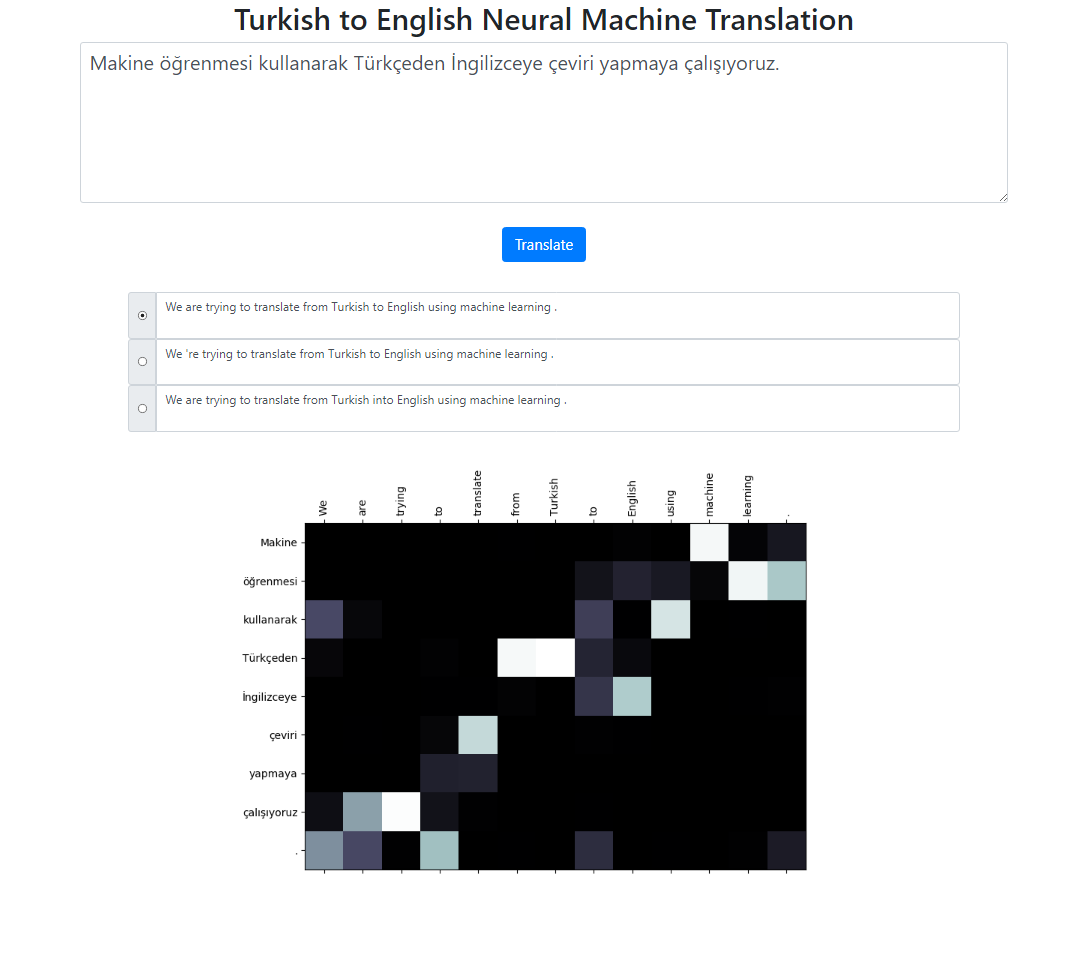
This repository implements a Turkish to English Neural Machine Translation system using Seq2Seq + Global Attention model. There is also a Flask application that you can run locally. You can enter the text, translate and, inspect the results as well as the attention visualization. We run beam search with beam size 3 in the background and return the most probable sequences sorted by their relative score.
The dataset for this project is taken from here. I have used the Tatoeba corpus. I have deleted some of the duplicates found in the data. I also pretokenized the dataset. Finalized version can be found in data folder.
For tokenizing the Turkish sentences, I've used the nltk's RegexpTokenizer.
puncts_except_apostrophe = '!"#$%&()*+,-./:;<=>?@[]^_`{|}~'TOKENIZE_PATTERN = fr"[{puncts_except_apostrophe}]|w+|['w]+"regex_tokenizer = RegexpTokenizer(pattern=TOKENIZE_PATTERN)text = "Titanic 15 Nisan pazartesi saat 02:20'de battı."tokenized_text = regex_tokenizer.tokenize(text)print(" ".join(tokenized_text))# Output: Titanic 15 Nisan pazartesi saat 02 : 20 'de battı .# This splitting property on "02 : 20" is different from the English tokenizer.# We could handle those situations. But I wanted to keep it simple and see if # the attention distribution on those words aligns with the English tokens.# There are similar cases mostly on dates as well like in this example: 02/09/2019For tokenizing the English sentences, I've used the spacy's English model.
en_nlp = spacy.load('en_core_web_sm')text = "The Titanic sank at 02:20 on Monday, April 15th."tokenized_text = en_nlp.tokenizer(text)print(" ".join([tok.text for tok in tokenized_text]))# Output: The Titanic sank at 02:20 on Monday , April 15th .Turkish and English sentences are expected to be in two different files.
file: train.tr tr_sent_1 tr_sent_2 tr_sent_3 ... file: train.en en_sent_1 en_sent_2 en_sent_3 ...
Please run python train.py -h for the full list of arguments.
Sample usage: python train.py --train_data train.tr train.en --valid_data valid.tr valid.en --n_epochs 30 --batch_size 32 --embedding_dim 256 --hidden_size 256 --num_layers 2 --bidirectional --dropout_p 0.3 --device cuda
To compute the corpus level blue score.
usage: test.py [-h] --model_file MODEL_FILE --valid_data VALID_DATA [VALID_DATA ...] Neural Machine Translation Testing optional arguments: -h, --help show this help message and exit --model_file MODEL_FILE Model File --valid_data VALID_DATA [VALID_DATA ...] Validation_data Sample Usage: python test.py --model_file model.bin --validation_data valid.tr valid.en
For running the application locally, run:
python app.py
Make sure that your model paths in the config.py file is properly defined.
Model file
Vocab file
Using subword units (for both Turkish and English)
Different attention mechanisms (learning different parameters for the attention)
Skeleton code for this project is taken from the Stanford's NLP Course: CS224n


