This repository contains PyTorch code for Motif, training AI agents on NetHack with reward functions derived from an LLM's preferences.
Motif: Intrinsic Motivation from Artificial Intelligence Feedback
by Martin Klissarov* & Pierluca D'Oro*, Shagun Sodhani, Roberta Raileanu, Pierre-Luc Bacon, Pascal Vincent, Amy Zhang and Mikael Henaff
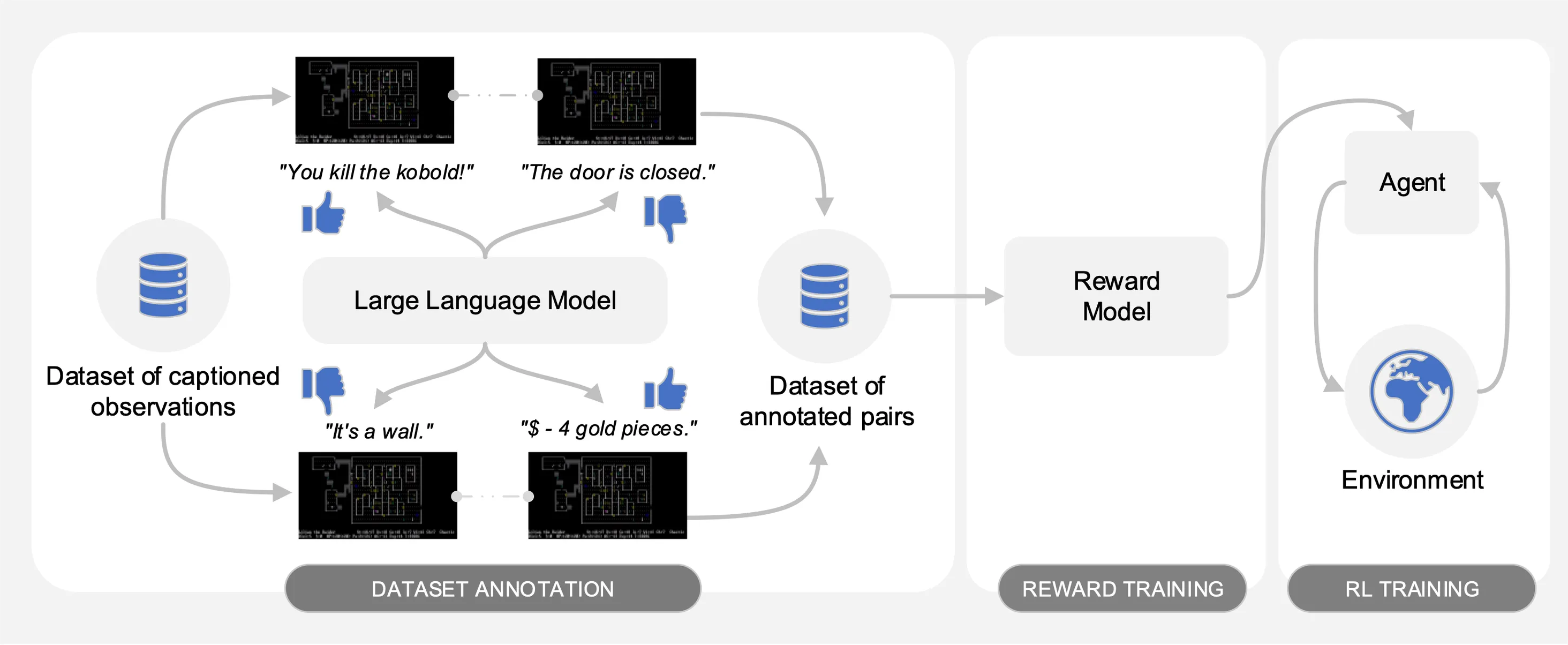
Motif elicits the preferences of a Large Language Model (LLM) on pairs of captioned observations from a dataset of interactions collected on NetHack. Automatically, it distills the LLM's common sense into a reward function that is used to train agents with reinforcement learning.
To facilitate comparisons, we provide training curves in the pickle file motif_results.pkl, containing a dictionary with tasks as keys. For each task, we provide a list of timesteps and average returns for Motif and baselines, for multiple seeds.
As illustrated in the following figure, Motif features three phases:
We detail each of the phases by providing the necessary datasets, commands and raw results to reproduce the experiments in the paper.
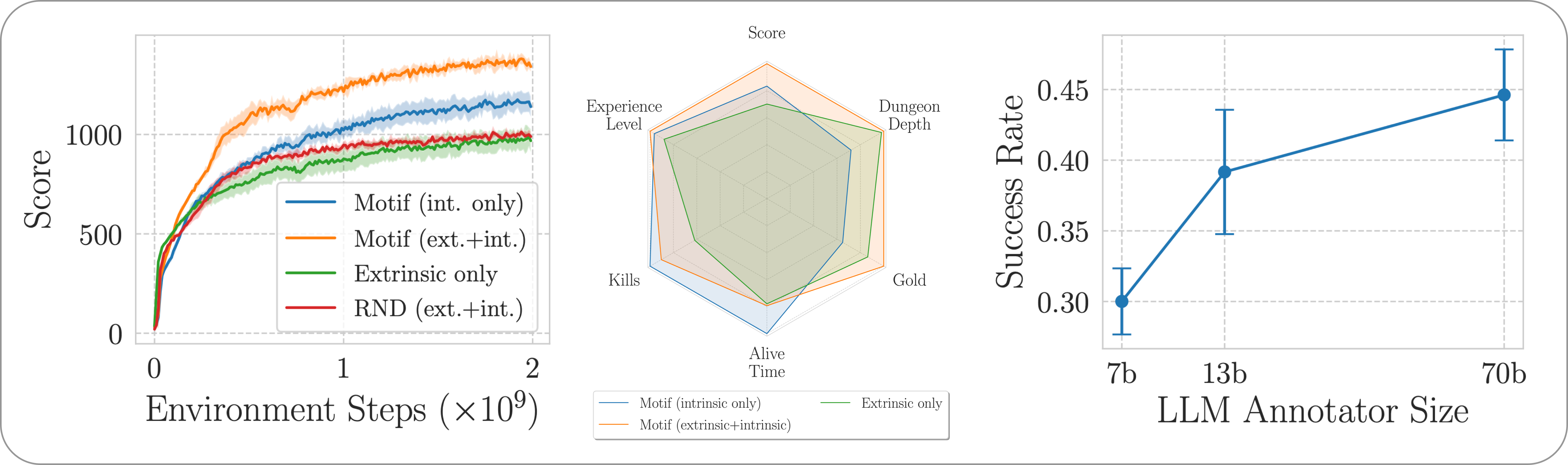
We evaluate Motif's performance on the challenging, open-ended and procedurally generated NetHack game through the NetHack Learning Environment. We investigate how Motif mostly generates intuitive human-aligned behaviors, which can be steered easily through prompt modifications, as well as its scaling properties.

To install the required dependencies for the whole pipeline, simply run pip install -r requirements.txt.
For the first phase, we use a dataset of pairs of observations with captions (i.e., messages from the game) collected by agents
trained with reinforcement learning to maximize the game score.
We provide the dataset in this repository.
We store the different parts into the motif_dataset_zipped directory, that can be unzipped using the following command.
cat motif_dataset_zipped/motif_dataset_part_* > motif_dataset.zip; unzip motif_dataset.zip; rm motif_dataset.zip
The dataset we provide features a set of preferences given by Llama 2 models, contained in the preference/ directory, using the different prompts described in the paper.
The names of the .npy files containing the annotations follow the template llama{size}b_msg_{instruction}_{version}, where size is an LLM size from the set {7,13,70}, instruction is an instruction introduced to the prompt given to the LLM from the set {defaultgoal, zeroknowledge, combat, gold, stairs}, version is the version of the prompt template to be used from the set {default, reworded}.
Here we provide a summary of the available annotations:
| Annotation | Use case from the paper |
|---|---|
llama70b_msg_defaultgoal_default |
Main experiments |
llama70b_msg_combat_default |
Steering towards The Monster Slayer behavior |
llama70b_msg_gold_default |
Steering towards The Gold Collector behavior |
llama70b_msg_stairs_default |
Steering towards The Descender behavior |
llama7b_msg_defaultgoal_default |
Scaling experiment |
llama13b_msg_defaultgoal_default |
Scaling experiment |
llama70b_msg_zeroknowledge_default |
Zero-knowledge prompt experiment |
llama70b_msg_defaultgoal_reworded |
Prompt rewording experiment |
To create the annotations, we use vLLM and the chat version of Llama 2. if you want to generate your own annotations with Llama 2 or reproduce our annotation process, make sure to be able to download the model by following the official instructions (it can take a few days to have access to the model weights).
The annotation script assumes the dataset will be annotated in different chunks using the n-annotation-chunks argument. This allows for a process that can be parallelized depending on the availability of resources, and is robust to restarts/preemption. To run with a single chunk (i.e., to process the entire dataset), and annotate with the default prompt template and task specification, run the following command.
python -m scripts.annotate_pairs_dataset --directory motif_dataset
--prompt-version default --goal-key defaultgoal
--n-annotation-chunks 1 --chunk-number 0
--llm-size 70 --num-gpus 8
Note that the default behavior resumes the annotation process by appending the annotations to the file specifying the configuration, unless otherwise indicated with the --ignore-existing flag. The name of the '.npy' file that is created for the annotations can also be manually selected by using the --custom-annotator-string flag. It is possible to annotate using --llm-size 7 and --llm-size 13 using a single GPU with 32GB of memory.
You can annotate using --llm-size 70 with an 8-GPUs node. We provide here rough estimates of annotation times with NVIDIA V100s 32G GPUs, for a dataset of 100k pairs, which should be able to roughly reproduce most of our results (which are obtained with 500k pairs).
| Model | Resources to annotate |
|---|---|
| Llama 2 7b | ~32 GPU hours |
| Llama 2 13b | ~40 GPU hours |
| Llama 2 70b | ~72 GPU hours |
In the second phase, we distill the LLM's preferences into a reward function through cross-entropy. To launch the reward training with default hyperparameters, use the following command.
python -m scripts.train_reward --batch_size 1024 --num_workers 40
--reward_lr 1e-5 --num_epochs 10 --seed 777
--dataset_dir motif_dataset --annotator llama70b_msg_defaultgoal_default
--experiment standard_reward --train_dir train_dir/reward_saving_dir
The reward function will be trained through the annotations of the annotator that are located in --dataset_dir. The resulting function will then be saved in train_dir under the sub-folder --experiment.
Finally, we train an agent with the resulting reward functions through reinforcement learning. To train an agent on the NetHackScore-v1 task, with the default hyperparameters employed for experiments combining intrinsic and extrinsic rewards, you can use the following command.
python -m scripts.main --algo APPO --env nle_fixed_eat_action --num_workers 24
--num_envs_per_worker 20 --batch_size 4096 --reward_scale 0.1 --obs_scale 255.0
--train_for_env_steps 2_000_000_000 --save_every_steps 10_000_000
--keep_checkpoints 5 --stats_avg 1000 --seed 777 --reward_dir train_dir/reward_saving_dir/standard_reward/
--experiment standard_motif --train_dir train_dir/rl_saving_dir
--extrinsic_reward 0.1 --llm_reward 0.1 --reward_encoder nle_torchbeast_encoder
--root_env NetHackScore-v1 --beta_count_exponent 3 --eps_threshold_quantile 0.5
To change the task, simply modify the --root_env argument. The following table explicitly states the values required in order to match experiments presented to in the paper. The NetHackScore-v1 task is learned with the extrinsic_reward value to be 0.1, while all other tasks take a value of 10.0, in order to incentivize the agent to reach the goal.
| Environment | root_env |
|---|---|
| score | NetHackScore-v1 |
| staircase | NetHackStaircase-v1 |
| staircase (level 3) | NetHackStaircaseLvl3-v1 |
| staircase (level 4) | NetHackStaircaseLvl4-v1 |
| oracle | NetHackOracle-v1 |
| oracle-sober | NetHackOracleSober-v1 |
Additionally, if you want to train agents just using the intrinsic reward coming from the LLM but no reward from the environment, simply set --extrinsic_reward 0.0. In the intrinsic reward-only experiments, we terminate the episode only if the agent dies, rather than when the agent reaches the goal. These modified environments are enumerated in the following table.
| Environment | root_env |
|---|---|
| staircase (level 3) - intrinsic only | NetHackStaircaseLvl3Continual-v1 |
| staircase (level 4) - intrinsic only | NetHackStaircaseLvl4Continual-v1 |
We additionally provide a script for visualizing your trained RL agents. This can provide important insights into its behaviour, but also will generated the top messages for each episode, which can help understanding what it is trying to optimize for. You simply need to run the following command.
python -m scripts.visualize --train_dir train_dir/rl_saving_dir --experiment standard_motif
If you build on our work or find it useful, please cite it using the following bibtex.
@article{klissarovdoro2023motif,
title={Motif: Intrinsic Motivation From Artificial Intelligence Feedback},
author={Klissarov, Martin and D’Oro, Pierluca and Sodhani, Shagun and Raileanu, Roberta and Bacon, Pierre-Luc and Vincent, Pascal and Zhang, Amy and Henaff, Mikael},
year={2023},
month={9},
journal={arXiv preprint arXiv:2310.00166}
}
The majority of Motif is licensed under CC-BY-NC, however portions of the project are available under separate license terms: sample-factory is licensed under the MIT license.


