reference_database_creator
bug fix --in-silico-pcr --untrimmed
CRABS (Creating Reference databases for Amplicon-Based Sequencing) is a versatile software program that generates curated reference databases for metagenomic analysis. CRABS workflow consists of seven modules: (i) download data from online repositories; (ii) import downloaded data into CRABS format; (iii) extract amplicon regions through in silico PCR analysis; (iv) retrieve amplicons without primer-binding regions through alignments with in silico extracted barcodes; (v) curate and subset the local database via multiple filtering parameters; (vi) export the local database in various formats according to the taxonomic classifier requirements; and (vi) post-processing functions, i.e., visualisations, to explore and provide a summary overview of the local reference database. These seven modules are split into eighteen functions and are described below. Additionally, example code is provided for each of the eighteen functions. Finally, a tutorial to build a local shark reference database for the MiFish-E primer set is provided at the end of this README document to provide an example script for reference.
We are excited to announce that CRABS has seen a major update and code redesign based on user feedback, which we hope will improve the user experience of building your very own local reference database!
Please find below a list of features and improvements added to CRABS v 1.0.0:
CRABS v 1.0.0 can now be downloaded manually by cloning this GitHub repository (see 4.1 Manual installation for detailed info). We will update the Docker container and conda package as soon as possible to facilitate easy installation of the newest version.
When using CRABS in your research projects, please cite the following paper:
[Jeunen, G.-J., Dowle, E., Edgecombe, J., von Ammon, U., Gemmell, N. J., & Cross, H. (2022). crabs—A software program to generate curated reference databases for metabarcoding sequencing data. Molecular Ecology Resources, 00, 1– 14.](https://doi.org/10.1111/1755-0998.13741)
CRABS is a command-line only toolkit running on typical Unix/Linux environments and is exclusively written in python3. However, CRABS makes use of the subprocess module in python to run several commands in bash syntax to circumvent python-specific idiosyncrasies and increase execution speed. We provide three ways to install CRABS. For the most up-to-date version of CRABS, we recommend the manual installation by cloning this GitHub repository and installing 10 dependencies separately (installation instructions for all dependencies provided in 4.1 Manual installation). CRABS can also be installed via Docker and conda. Both methods allow for easy installation by automatically co-installing all dependencies. We aim to keep the Docker container and conda package up-to-date, though a certain delay to update to the newest version can occur, especially for the conda package. Below are details for all three approaches.
For the manual installation, first clone the CRABS repository. This step requires GitHub to be available to the command line (installation instructions for GitHub).
git clone https://github.com/gjeunen/reference_database_creator.git
Depending on your settings, CRABS might need to be made executable on your system. This can be achieved using the code below.
chmod +x reference_database_creator/crabs
Once CRABS is installed, we need to ensure all dependencies are installed and globally accessible. The latest version of CRABS (version v 1.0.0) runs on Python 3.11.7 (or any compatible version to 3.11.7) and relies on five Python modules that might not come standard with Python, as well as five external software programs. All dependencies are listed below, together with a link to the installation instructions. The version numbers provided for each module and software program are the ones CRABS was developed on. Though compatible versions of each could be used as well.
Python modules:
External software programs:
Once CRABS and all the dependencies are installed, CRABS can be made accessible throughout the OS using the code below.
export PATH="/path/to/crabs/folder:$PATH"
Substitute /path/to/crabs/folder with the actual path to the GitHub repository folder on the OS, i.e, the folder created during the git clone command above. Adding the export code to the .bash_profile or .bashrc file will make CRABS globally accessible at any time.
Docker is an open-source project that allows for deployment of software applications inside 'containers' that are isolated from your computer and run through a virtual host operating system called Docker Engine. The main advantage of running docker over virtual machines is that they use much less resources. This isolation means that you can run a Docker container on most operating systems, including Mac, Windows, and Linux. You may need to set up a free account to use Docker Desktop. This link has a nice introduction to the basics of using Docker. Here is a link to get you started and oriented to the Docker multiverse.
There are only two steps to get the Crabs running on your computer. First, install Docker Desktop on your computer, which is free for most users. Here are the instructions for Mac; here are the instructions for Windows computers, and here are the instructions for Linux (most major Linux platforms are supported). Once you have Docker Desktop installed and running (the Desktop application must be running for you to use any docker commands on the command line), you just have to 'pull' our Crabs image, and you are ready to go:
docker pull quay.io/swordfish/crabs:0.1.7
While the installation of a docker application is easy, using those applications can be a little tricky at first. To help you get started we have provided some example commands using the docker version of crabs. These examples can be found in the docker_intro folder on this repo. From these examples you should be able to run through setting up an entire reference database and be ready to go. We will continue to expand on these examples and test this in many different situations. Please ask questions and provide feedback in the Issues tab.
To install the conda package, you must first install conda. See this link for details. If conda is already installed, it is good practice to update the conda tool with conda update conda before installing CRABS.
Once conda is installed, follow the steps below to install CRABS and all dependencies. Make sure to enter the commands in the order they appear below.
conda create -n CRABS
conda activate CRABS
conda config --add channels bioconda
conda config --add channels conda-forge
conda install -c bioconda crabs
Once you have entered the install command, conda will process the request (this might take a minute or so), and then display all the packages and programs that will be installed, and ask to confirm this. Type y to start the installation. After this finishes, CRABS should be ready to go.
We have tested this installation on Mac and Linux systems. We have not yet tested on Windows Subsystem for Linux (WSL).
Use the code below to check if CRABS is successfully installed and pull up the help information.
crabs -hThe help information splits the eighteen functions into different groups, with each group listing the function at the top and the required and optional parameters underneath.

CRABS contains seven modules, which incorporate eighteen functions:
Module 1: download data from online repositories
--download-taxonomy: download NCBI taxonomy information;--download-bold: download sequence data from the Barcode of Life Database (BOLD);--download-embl: download sequence data from the European Nucleotide Archive (ENA; EMBL);--download-mitofish: download sequence data from the MitoFish database;--download-ncbi: download sequence data from the National Center for Biotechnology Information (NCBI).Module 2: import downloaded data into CRABS format
--import: import downloaded sequences or custom barcodes into CRABS format;--merge: merge different CRABS-formatted files into a single file.Module 3: extract amplicon regions through in silico PCR analysis
--in-silico-pcr: extract amplicons from downloaded data by locating and removing primer-binding regions.Module 4: retrieve amplicons without primer-binding regions
--pairwise-global-alignment: retrieve amplicons without primer-binding regions by aligning downloaded sequences to in silico extracted barcodes.Module 5: curate and subset the local database via multiple filtering parameters
--dereplicate: discard duplicate sequences;--filter: discard sequences via multiple filtering parameters;--subset: subset the local database to retain or exclude specified taxonomic groups.Module 6: export the local database
--export: export the CRABS-formatted database to various formats according to the requirements of the taxonomic classifier to be used.Module 7: post-processing functions to explore and provide a summary overview of the local reference database
--diversity-figure: creates a horizontal bar chart displaying the number of species and sequences group per specified level included in the reference database;--amplicon-length-figure: creates a line chart depicting amplicon length distributions separated by taxonomic group;--phylogenetic-tree: creates a phylogenetic tree with barcodes from the reference database for a target list of species;--amplification-efficiency-figure: creates a bar graph displaying mismatches in the primer-binding regions;--completeness-table: creates a spreadsheet containing barcode availability for taxonomic groups.Initial sequencing data can be downloaded by CRABS from four online repositories, including (i) BOLD, (ii) EMBL, (iii) MitoFish, and NCBI. From version v 1.0.0 onwards, the downloading of data from each repository is split up into its own function. Additionally, CRABS does not automatically format the data after downloading to increase flexibility and enable debugging when the download of data fails.
Besides downloading sequence data, CRABS is also capable of downloading the NCBI taxonomy information, which CRABS uses for creating the taxonomic lineage for each sequence.
--download-taxonomy
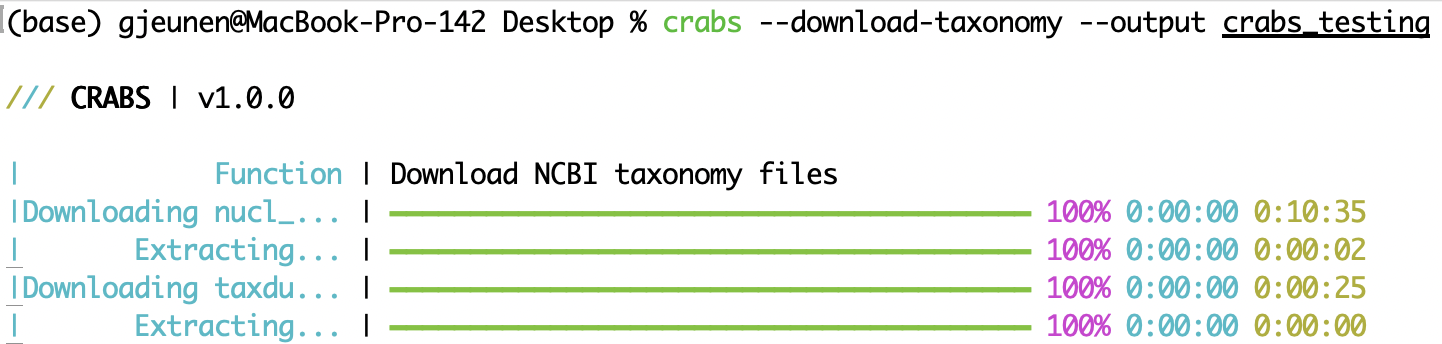
To assign a taxonomic lineage to each downloaded sequence in the reference database (see 5.2 Module 2), the taxonomic information needs to be downloaded. CRABS utilizes NCBI's taxonomy and downloads three specific files to your computer: (i) a file linking accession numbers to taxonomic IDs (nucl_gb.accession2taxid), (ii) a file containing information about the phylogenetic name associated with each taxonomic ID (names.dmp), and (iii) a file containing information how taxonomic IDs are linked (nodes.dmp). The output directory for the downloaded files can be specified using the --output parameter. To exclude either file nucl_gb.accession2taxid or files names.dmp and nodes.dmp, the --exclude acc2tax or --exclude taxdump parameter can be provided, respectively. The first code below does not download any file, as both acc2tax and taxdump are provided for the --exclude parameter. The second line of code downloads all three files to the subdirectory --output crabs_testing. The screenshot underneath displays what is printed to the console when executing this line of code.
crabs --download-taxonomy --exclude 'acc2taxid,taxdump'
crabs --download-taxonomy --output crabs_testing
--download-bold
BOLD sequences are downloaded through the BOLD website. The output file, which is structured as a two-line fasta document, can be specified using the --output parameter. Users can specify which taxonomic group to download using the --taxon parameter. We recommend writing a simple for loop (example provided below) when users want to download multiple taxonomic groups, thereby limiting the amount of data to be downloaded from BOLD per instance. However, if only a limited number of taxonomic groups are of interest, taxonomic group names can also be separated by | (example provided below). We also recommend users to check if the taxonomic group name to be downloaded is listed within the BOLD archive or if alternative names need to be used. For example, specifying --taxon Chondrichthyes will not download all cartilaginous fish sequences from BOLD, since this class name is not listed on BOLD. Users should rather use --taxon Elasmobranchii in this instance. Users can also specify to limit the download to a specific genetic marker by providing the --marker parameter. When multiple genetic markers are of interest, marker names should be separated by |. The four main DNA barcoding markers on BOLD are COI-5P, ITS, matK, and rbcL. Input for the --marker parameter is case sensitive.
Recommended approach: A simple for loop to download data from BOLD for multiple taxonomic groups (recommended approach). The code below first downloads data for Elasmobranchii, followed by sequences assigned to Mammalia. Downloaded data will be written to the subdirectory --output crabs_testing and placed in two separate files, indicating which data belongs to which taxonomic group, i.e., crabs_testing/bold_Elasmobranchii.fasta and crabs_testing/bold_Mammalia.fasta.
for taxon in Elasmobranchii Mammalia; do crabs --download-bold --taxon ${taxon} --output crabs_testing/bold_${taxon}.fasta; done

Alternative option: Besides the recommended for loop, multiple taxon names can be provided at once by separating the names using |.
crabs --download-bold --taxon 'Elasmobranchii|Mammalia' --output crabs_testing/bold_elasmobranchii_mammalia.fasta
--download-embl
Sequences from EMBL are downloaded through the ENA FTP site. EMBL files will first be downloaded in a '.fasta.gz' format and be automatically unzipped once the download is complete. This database does not provide as much flexibility with regards to selective downloading compared to BOLD or NCBI. Rather, EMBL data is structured into 15 tax divisions, which can be downloaded separately. The tax division to download can be specified using the --taxon parameter. Since each tax division is split into several files, a * is provided after the name to download all files. Users can also download a specific file by writing the file name in full. A list of all 15 tax division options is provided below. The output directory and file name can be specified using the --output parameter.
List of tax divisions:
crabs --download-embl --taxon 'mam*' --output crabs_testing/embl_mam.fasta
--download-mitofish
CRABS can also download the MitoFish database. This database is a single two-line fasta file. The output directory and file name can be specified using the --output parameter.
crabs --download-mitofish --output crabs_testing/mitofish.fasta

--download-ncbi
Sequences from the NCBI database are downloaded through the Entrez Programming Utilities. NCBI allows the downloading of data from various databases, which users can specify with the --database parameter. For most users, the --database nucleotide database will be most appropriate for building a local reference database.
To specify the data to be downloaded from NCBI, users provide a search through the --query parameter. Crafting good NCBI searches can be difficult. A good way to build a search query is to use the NCBI webpage search window. From this link, first do an initial search and press enter. This will bring you to the results page where you can further refine your search. In the screenshot below, we've further refined the search by limiting sequence length between 100 - 25,000 bp and only incorporating mitochondrial sequences. Users can copy-paste the text in the "Search details" box on the website and provide it in quotes to the --query parameter. Another benefit of using the NCBI webpage search window is that the webpage will display how many sequences match your search query, which should match the number of sequences reported by CRABS. This webpage provides a further short tutorial on using the search function on the NCBI webpage that our team has written for extra information.
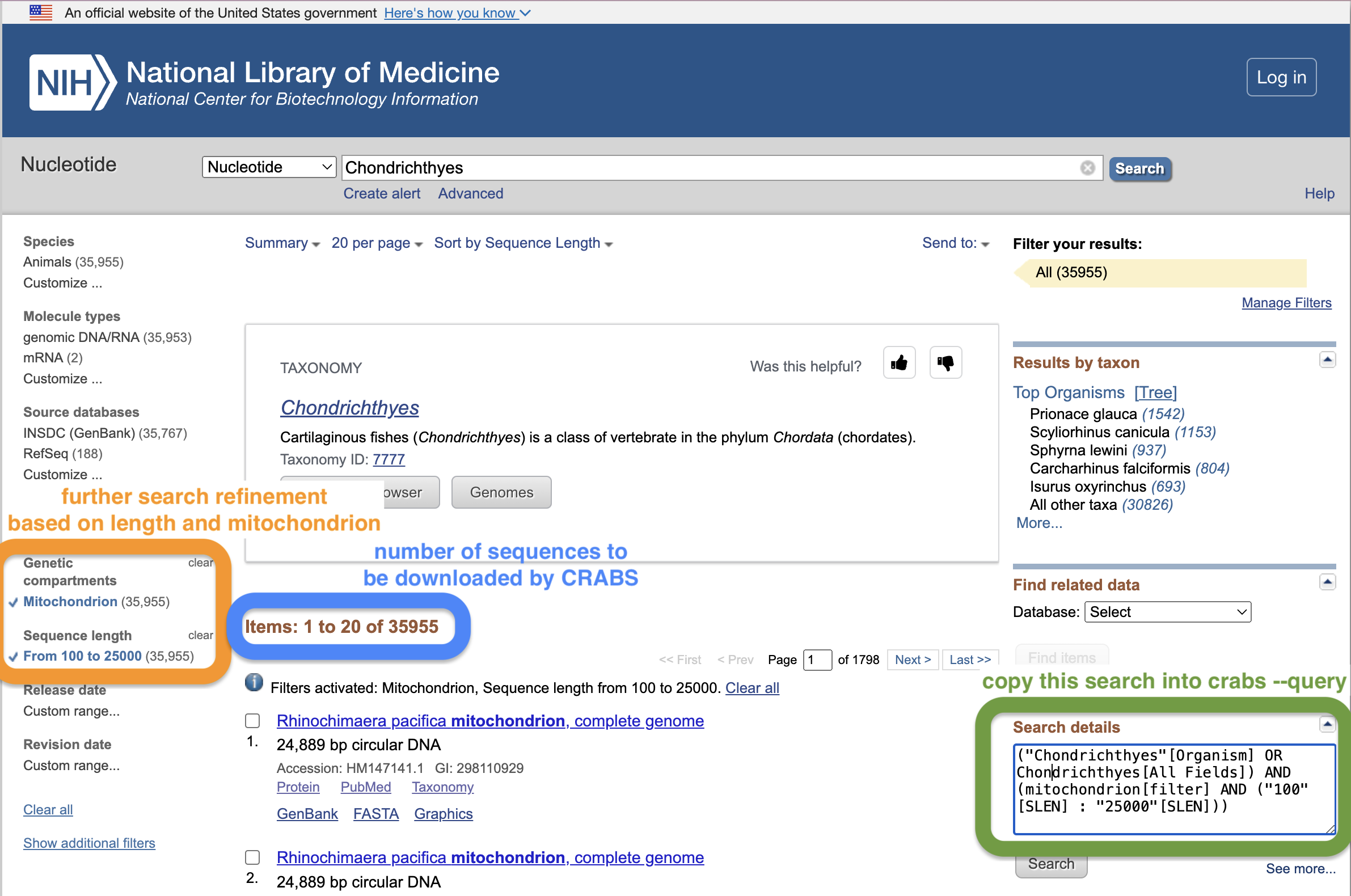
Besides the search query (--query), users can further restrict the search term by downloading sequence data for a list of species using the --species parameter. The --species parameter either takes an input string of species names separated by + or an input .txt file with a single species name per line in the document. The --batchsize parameter provides users the option to download sequences in batches of N from the NCBI website. This parameter defaults to 5,000. It is not recommended to increase this value above 5,000, as the NCBI servers will most likely disconnect the download if too many sequences are downloaded at once. The --email parameter allows users to specify their email address, which is required to access the NCBI servers. Finally, the output directory and filename can be specified using the --output parameter.
crabs --download-ncbi --query '("Chondrichthyes"[Organism] OR Chondrichthyes[All Fields]) AND (mitochondrion[filter] AND ("100"[SLEN] : "25000"[SLEN]))' --output crabs_testing/ncbi_chondrichthyes.fasta --email [email protected] --database nucleotide

--import
Once the data from online repositories are downloaded, files will need to be imported into CRABS using the --import function. CRABS format constitutes a single tab-delimited line per sequence containing all information, including (i) sequence ID, (ii) taxonomic name parsed from the initial download, (iii) NCBI taxon ID number, (iv) taxonomic lineage according to NCBI taxonomy, and (v) the sequence. CRABS will try to obtain the NCBI accession number for each sequence as a sequence ID. If the sequence does not contain an accession number, i.e., it is not deposited on NCBI, CRABS will generate unique sequence IDs using the following format: crabs_*[num]*_taxonomic_name. The format of the input document is specified using the --import-format parameter and specifies the name of the repository from which the data was downloaded, i.e., BOLD, EMBL, MITOFISH, or NCBI. The taxonomic lineage CRABS creates is based on the NCBI taxonomy and CRABS requires the three files downloaded using the --download-taxonomy function, i.e., --names, --nodes, and --acc2tax. From version v 1.0.0, CRABS is capable of resolving synonym and unaccepted names to incorporate a larger number of sequences and diversity in the local reference database. The taxonomic ranks to be included in the taxonomic lineage can be specified using the --ranks parameters. While any taxonomic rank can be included, we recommend using the following input to include all necessary information for most taxonomic classifiers --ranks 'superkingdom;phylum;class;order;family;genus;species'. The output file can be specified using the --output parameter and is a simple .txt file. In the Terminal Window, CRABS prints the results of the number of sequences imported, as well as any sequences for which no taxonomic lineage could be generated.
crabs --import --import-format bold --input crabs_testing/bold_Elasmobranchii.fasta --names crabs_testing/names.dmp --nodes crabs_testing/nodes.dmp --acc2tax crabs_testing/nucl_gb.accession2taxid --output crabs_testing/crabs_bold.txt --ranks 'superkingdom;phylum;class;order;family;genus;species'

--merge
When sequence data from multiple online repositories are downloaded, files can be merged into a single file after importing (see 5.2.1 --import) using the --merge function. Input files to merge can be entered using the --input parameter, with files separated by ;. It is possible that a sequence was downloaded multiple times when deposited on various online repositories. Using the --uniq parameter retains only a single version of each accession number. The output file can be specified using the --output parameter. In the Terminal Window, CRABS prints the results of the number of sequences merged, as well as the number of sequences retained when using the --uniq parameter.
crabs --merge --input 'crabs_testing/crabs_bold.txt;crabs_testing/crabs_mitofish.txt;crabs_testing/crabs_ncbi.txt' --uniq --output crabs_testing/merged.txt

CRABS extracts the amplicon region of the primer set by conducting an in silico PCR (function: --in-silico-pcr). CRABS uses cutadapt v 4.4 for the in silico PCR to increase speed of execution of traditional python code. Input and output file names can be specified using the '--input' and '--output' parameters, respectively. Both the forward and reverse primer should be provided in 5'-3' direction using the '--forward' and '--reverse' parameters, respectively. CRABS will reverse complement the reverse primer. From version v 1.0.0, CRABS is capable of retaining barcodes in both direction using a single in silico PCR analysis. Hence, no reverse complementation step and rerunning of the in silico PCR is conducted, thereby significantly increasing execution speed. To retain sequences for which no primer-binding regions could be found, an output file can be specified for the --untrimmed parameter. The maximum allowed number of mismatches found in the primer-binding regions can be specified using the --mismatch parameter, with a default setting of 4. Finally, the in silico PCR analysis can be multithreaded in CRABS. By default the maximum number of threads are being used, but users can specify the number of threads to use with the --threads parameter.
crabs --in-silico-pcr --input crabs_testing/merged.txt --output crabs_testing/insilico.txt --forward GACCCTATGGAGCTTTAGAC --reverse CGCTGTTATCCCTADRGTAACT

It is common practice to remove primer-binding regions from reference sequences when deposited in an online database. Therefore, when the reference sequence was generated using the same forward and/or reverse primer as searched for in the --in-silico-pcr function, the --in-silico-pcr function will have failed to recover the amplicon region of the reference sequence. To account for this possibility, CRABS has the option to run a Pairwise Global Alignment, implemented using VSEARCH v 2.16.0, to extract amplicon regions for which the reference sequence does not contain the full forward and reverse primer-binding regions. To accomplish this, the --pairwise-global-alignment function takes in the originally downloaded database file using the --input parameter. The database to be searched against is the output file from the --in-silico-pcr and can be specified using the --amplicons parameter. The output file can be specified using the --output parameter. The primer sequences, only used to calculate basepair length, can be set with the --forward and --reverse parameters. As the --pairwise-global-alignment function can take a long time to run for large databases, sequence length can be restricted to speed up the process using the --size-select parameter. Minimum percentage identity and query coverage can be specified using the --percent-identity and --coverage parameters, respectively. --percent-identity should be provided as a percentage value between 0 and 1 (e.g., 95% = 0.95), while --coverage should be provided as a percentage value between 0 and 100 (e.g., 95% = 95). By default, the --pairwise-global-alignment function is restricted to retain sequences where primer sequences are not fully present in the reference sequence (alignment starting or ending within the length of the forward or reverse primer). When the --all-start-positions parameter is provided, positive hits will be included when the alignment is found outside the range of the primer-binding regions (missed by --in-silico-pcr function due to too many mismatches in the primer-binding region). We do not recommend using the --all-start-positions, as it is very unlikely a barcode will be amplified using the specified primer set of the --in-silico-pcr function when more than 4 mismatches are present in the primer-binding regions.
crabs --pairwise-global-alignment --input crabs_testing/merged.txt --amplicons crabs_testing/insilico.txt --output crabs_testing/aligned.txt --forward GACCCTATGGAGCTTTAGAC --reverse CGCTGTTATCCCTADRGTAACT --size-select 10000 --percent-identity 0.95 --coverage 0.95

--pairwise-global-alignment
The --pairwise-global-alignment function can take a substantial amount of time to execute when CRABS is processing large sequence files, even though multithreading is supported. Since the update to CRABS v 1.0.0, an identical file structure is in place from --import to --export, thereby enabling functions to be executed in any order. While we still recommend to follow the order of the CRABS workflow, the --pairwise-global-alignment function can be significantly sped up when executing the --dereplicate and --filter functions prior to the --in-silico-pcr function. By executing these curation steps prior to --in-silico-pcr, the number of sequences needed to be processed by CRABS for the --pairwise-global-alignment function will be signficantly reduced.
NOTE 1: when executing the --filter function prior to --in-silico-pcr, please make sure to omit any parameters that are directly impacting the sequence, as --filter will base this on the entire sequence and not the extracted amplicon. Hence, omit the following parameters: --minimum-length, --maximum-length, --maximum-n.
NOTE 2: when executing the --dereplicate and --filter functions prior to --in-silico-pcr, it would be advisable to run both functions again after --pairwise-global-alignment, as the database could be further curated now that the amplicons are extracted.
Once all potential barcodes for the primer set have been extracted by the --in-silico-pcr and --pairwise-global-alignment functions, the local reference database can undergo further curation and subsetting within CRABS using various functions, including --dereplicate, --filter, and --subset.
--dereplicate
The first curation method is to dereplicate the local reference database using the --dereplicate function. It is possible that for certain taxa multiple identical barcodes are contained within the local reference database at this point. This can occur when different research groups have deposited identical sequences or if the intra-specific variation between sequences for a taxon is not contained within the extracted barcode. It is best to remove these identical reference barcodes to speed up taxonomy assignment, as well as improve taxonomy assignment results (especially for taxonomic classifiers providing a limited number of results, i.e., BLAST).
The input and output files can be specified using the --input and --output parameters, respectively. CRABS offers three dereplication methods, which can be specified using the --dereplication-method parameter, including:
crabs --dereplicate --input crabs_testing/aligned.txt --output crabs_testing/dereplicated.txt --dereplication-method 'unique_species'

--filter
The second curation method is to filter the local reference database using various parameters using the --filter function. The input and output files can be specified using the --input and --output parameters, respectively. From version v 1.0.0. CRABS incorporates the filtering based on six parameters, including:
--minimum-length: minimum sequence length for an amplicon to be retained in the database;--maximum-length: maximum sequence length for an amplicon to be retained in the database;--maximum-n: discard amplicons with N or more ambiguous bases (N);--environmental: discard environmental sequences from the database;--no-species-id: discard sequences for which no species name is available;--rank-na: discard sequences with N or more unspecified taxonomic levels.crabs --filter --input crabs_testing/dereplicated.txt --output crabs_testing/filtered.txt --minimum-length 100 --maximum-length 300 --maximum-n 1 --environmental --no-species-id --rank-na 2

--subset
The third and final curation method incorporated in CRABS is to subset the local reference database to include (parameter: --include) or exclude (parameter: --exclude) specific taxa using the --subset function. This function allows for the removal of reference barcodes from taxonomic groups not of interest to the research question. These taxonomic groups could have been incorporated into the local reference database due to potential unspecific amplification of the primer set. Another use-case for --subset is to remove known erroneous sequences.
For taxonomic classifiers based on machine learning (IDTAXA) or k-mer distance (SINTAX), it can be beneficial to subset the reference database by only including taxa known to occur in the region where samples were taken and exclude closely-related species known not to occur in the region to increase the obtained taxonomic resolution of these classifiers and obtain improved taxonomy assignment results.
The input and output files can be specified using the --input and --output parameters, respectively. The --include and --exclude parameters can take in either a list of taxa separated by ; or a .txt file containing a single taxon name per line.
crabs --subset --input crabs_testing/filtered.txt --output crabs_testing/subset.txt --include 'Chondrichthyes'

Once the reference database is finalised, it can be exported into various formats to accomodate specifications required by most software tools assigning taxonomy to metagenomic data. The input and output files can be specified using the --input and --output parameters, respectively. From version v 1.0.0, CRABS incorporate the formatting of the reference database for six different classifiers (parameter: --export-format), including:
--export-format 'sintax': The SINTAX classifier is incorporated into USEARCH and VSEARCH;--export-format 'rdp': The RDP classifier is a standalone program widely used in microbiome studies;--export-format 'qiime-fasta' and --export-format 'qiime-text': Can be used to assign a taxonomic ID in QIIME and QIIME2;--export-format 'dada2-species' and --export-format 'dada2-taxonomy': Can be used to assign a taxonomic ID in DADA2;--export-format 'idt-fasta' and --export-format 'idt-text': The IDTAXA classifier is a machine learning algorithm incorporated in the DECIPHER R package;--export-format 'blast-notax': Creates a local BLAST reference database for blastn and megablast where the output does not provide a taxonomic ID, but lists the accession number;--export-format 'blast-tax': Creates a local BLAST reference database for blastn and megablast where the output provides both the taxonomic ID and accession number.crabs --export --input crabs_testing/subset.txt --output crabs_testing/BLAST_TAX_CHONDRICHTHYES --export-format 'blast-tax'

While exporting the local reference database to a single format (except for the classifiers where the reference database is split over multiple files, i.e., QIIME, DADA2, IDTAXA) will suffice for most users, a simple for loop can be written to export the local reference database to multiple formats if users would like to compare results between different taxonomic classifiers. An example is provided below to export the local reference database in SINTAX, RDP, and IDTAXA formats.
for format in sintax.fasta rdp.fasta idt-fasta.fasta idt-text.txt; do crabs --export --input crabs_testing/subset.txt --output crabs_testing/chondrichthyes_${format} --export-format ${format%%.*}; done

Once the reference database is finalised, CRABS can run five post-processing functions to explore and provide a summary overview of the local reference database, including (i) --diversity-figure, (ii) --amplicon-length-figure, (iii) --phylogenetic-tree, (iv) --amplification-efficiency-figure, and (v) --completeness-table.
--diversity-figure
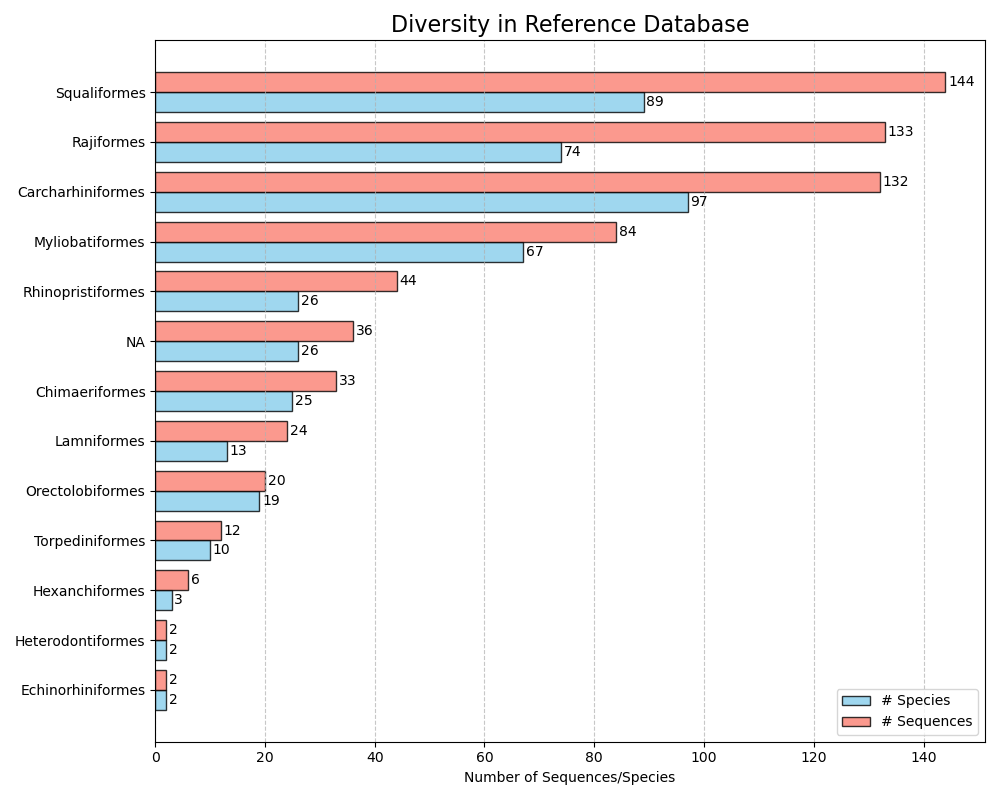
The --diversity-figure function produces a horizontal bar plot with number of species (in blue) and number of sequences (in orange) per for each taxonomic group in the reference database. The user can specify the taxonomic rank to split up the reference database with the --tax-level parameter. The tax level is the number of the rank in which it appeared during the --import function. For example, if --ranks 'superkingdom;phylum;class;order;family;genus;species' was used during --import splitting based on superkingdom would require --tax-level 1, phylum = --tax-level 2, class = --tax-level 3, etc. The input file in CRABS format can be specified using the --input parameter. The figure, in .png format, will be written to the output file, which can be specified using the --output parameter.
crabs --diversity-figure --input crabs_testing/subset.txt --output crabs_testing/diversity-figure.png --tax-level 4
--amplicon-length-figure
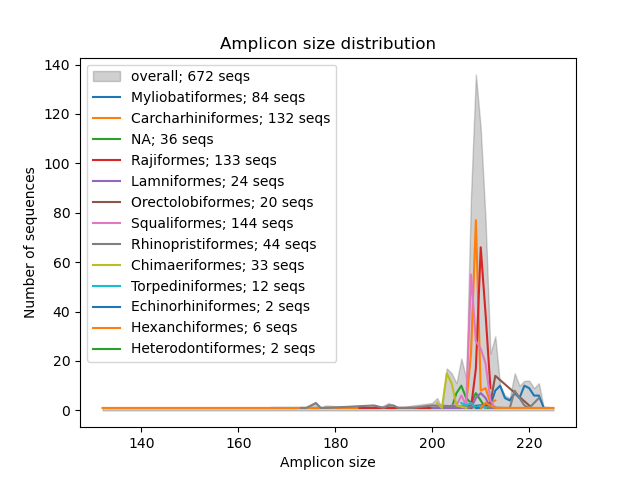
The --amplicon-length-figure function produces a line graph displaying the range of the amplicon length. The overall range in amplicon length across all sequences in the reference database is displayed in a shaded grey color, while the results split per taxonomic group (parameter: --tax-level) are overlayed by coloured lines. Additionally, the legend displays the number of sequences assigned to each of the taxonomic groups and the total number of sequences in the reference database. The input file in CRABS format can be specified using the --input parameter. The figure, in .png format, will be written to the output file, which can be specified using the --output parameter.
crabs --amplicon-length-figure --input crabs_testing/subset.txt --output crabs_testing/amplicon-length-figure.png --tax-level 4
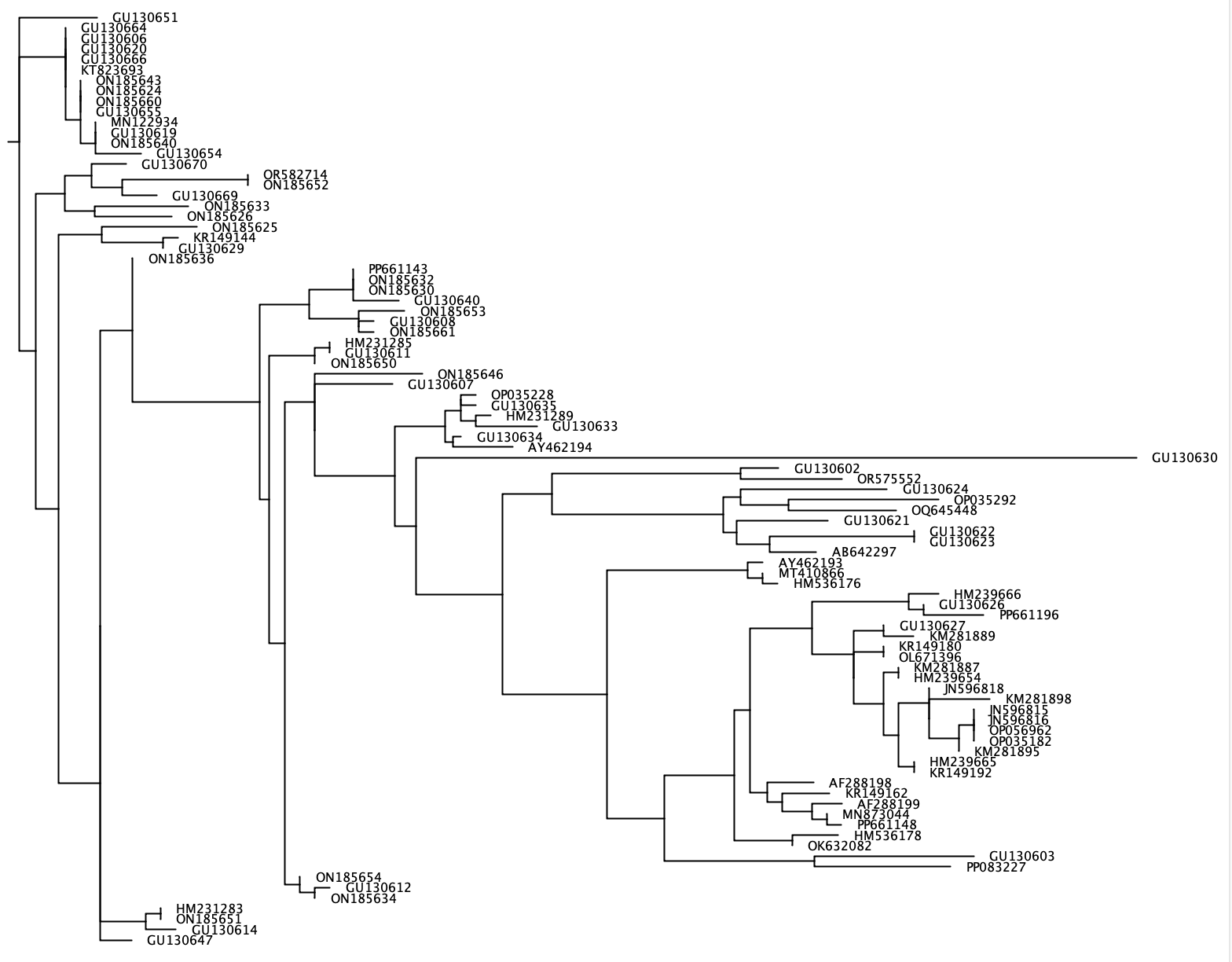
--phylogenetic-tree
The --phylogenetic-tree function will generate a phylogenetic tree for a list of species of interest. This list of species of interest can be imported using the --species parameter and consists of either an input string separated by + or a .txt file with a single species name on each line. For each species of interest, sequences will be extracted from the reference database that share a user-defined taxonomic rank (parameter: --tax-level) with the species of interest. CRABS will generate an alignment of all extracted sequences using clustalw2 v 2.1 and generate a neighbour-joining phylogenetic tree using FastTree. This phylogenetic tree in newick format will be written to the output file using the --output parameter and can be visualised in software programs such as FigTree or Geneious. Since a separate phylogenetic tree will be generated for each species of interest, --output takes in a generic file name, while the exact output file will contain this generic name followed by '_species_name.tree'.
crabs --phylogenetic-tree --input crabs_testing/subset.txt --output crabs_testing/phylo --tax-level 4 --species 'Carcharodon carcharias+Squalus acanthias'
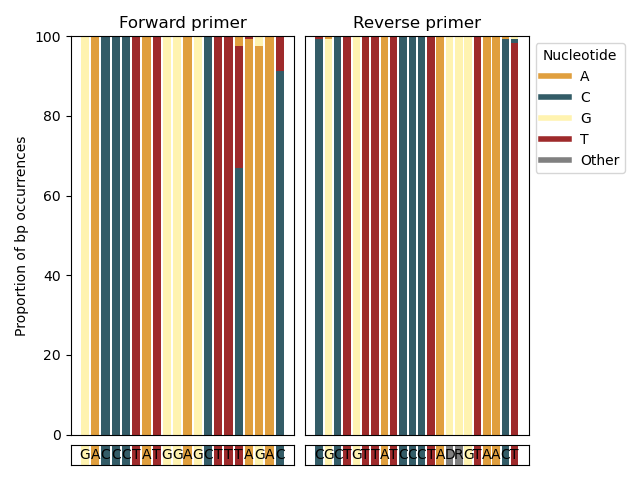
--amplification-efficiency-figure
The --amplification-efficiency-figure function will produce a bar graph, displaying the proportion of base pair occurrence in the primer-binding regions for a user-specified taxonomic group, thereby visualizing places in the forward and reverse primer-binding regions where mismatches might be occurring in the taxonomic group of interest, potentially influencing amplification efficiency. The --amplification-efficiency-figure function takes a final CRABS-formatted reference database as input using the --amplicons parameter. To find the information on the primer-binding regions for each sequence in the input file, the initially downloaded sequences after import need to be provided using the --input parameter. The forward and reverse primer sequences (in 5' - 3' direction) are provided using the --forward and --reverse parameters. The name of the taxonomic group of interest can be provided using the --tax-group parameter and can be set at any taxonomic level that is incorporated in the input file. Finally, the figure in .png format will be written to the output file specified by the --output parameter.
crabs --amplification-efficiency-figure --input crabs_testing/merged.txt --amplicons crabs_testing/subset.txt --forward GACCCTATGGAGCTTTAGAC --reverse CGCTGTTATCCCTADRGTAACT --output crabs_testing/amplification-efficiency.png --tax-group Carcharhiniformes
--completeness-table
The --completeness-table function will output a tab-delimited table (parameter: --output) with information about a list of species of interest. This list of species of interest can be imported using the --species parameter and consists of either an input string separated by + or a .txt file with a single species name on each line. A taxonomic lineage will be generated for each species of interest using the 'names.dmp' and 'nodes.dmp' files downloaded using the --download-taxonomy function using the --names and --nodes parameters, respectively. The output table will have 10 columns providing the following information:
crabs --completeness-table --input crabs_testing/subset.txt --output crabs_testing/completeness.txt --names crabs_testing/names.dmp --nodes crabs_testing/nodes.dmp --species 'Carcharodon carcharias+Squalus acanthias'

crabs --version v 1.0.6: bug fix --> improved parsing of BOLD headers during --import.crabs --version v 1.0.5: bug fix --> added a length restriction to seq ID when building BLAST databases, as needed for the BLAST+ software.crabs --version v 1.0.4: added info --> provided correct information on value input for --pairwise-global-alignment --coverage --percent-identity.crabs --version v 1.0.3: bug fix --> checking NCBI server response 3 times before aborting analysis.crabs --version v 1.0.2: bug fix --> capable of reporting when 0 sequences are returned after analysis.crabs --version v 1.0.1: bug fix --> successful building NCBI query using the --species parameter.

