instructor php
1.0.0
Structured data extraction in PHP, powered by LLMs. Designed for simplicity, transparency, and control.
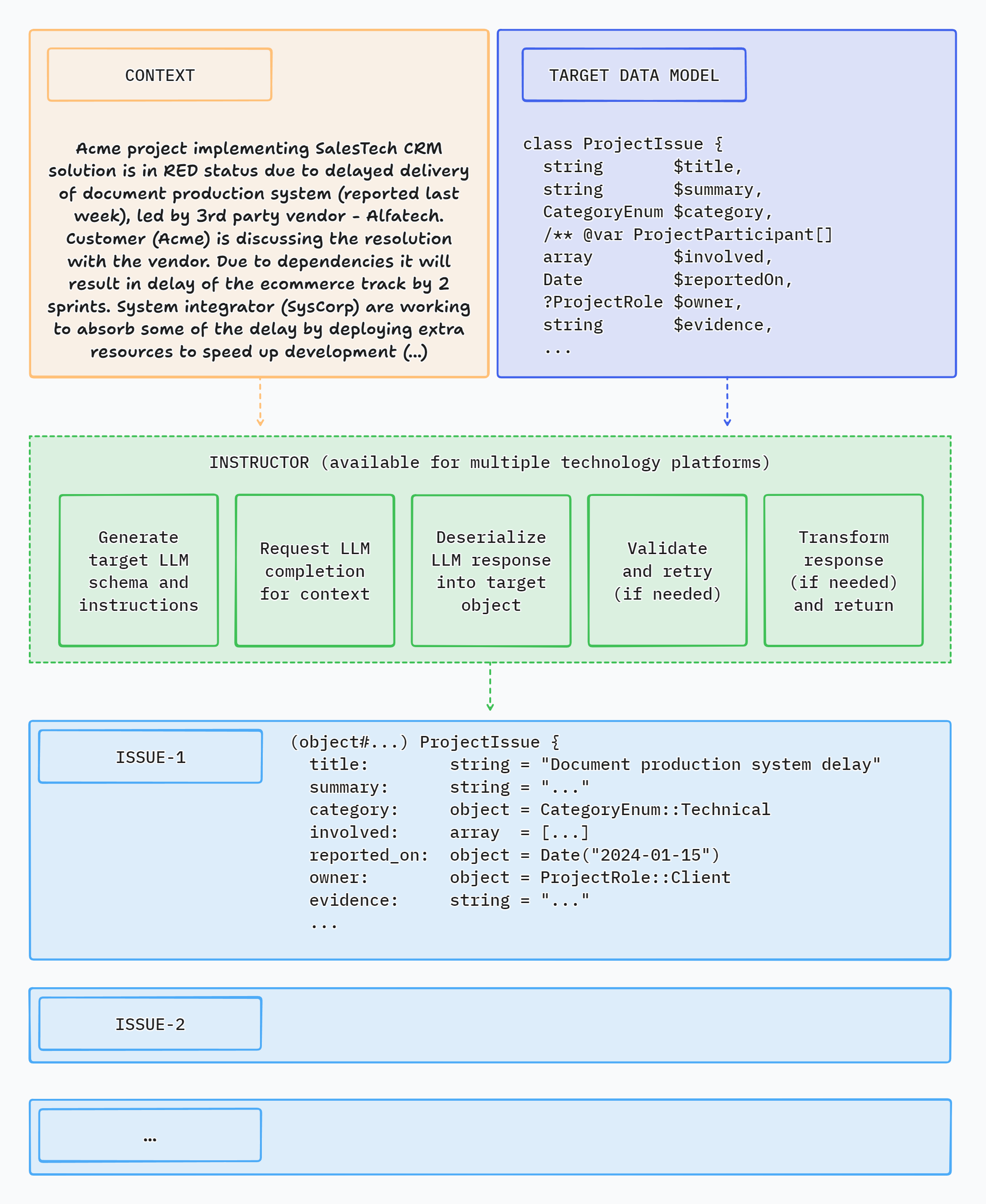
Instructor is a library that allows you to extract structured, validated data from multiple types of inputs: text, images or OpenAI style chat sequence arrays. It is powered by Large Language Models (LLMs).
Instructor simplifies LLM integration in PHP projects. It handles the complexity of extracting structured data from LLM outputs, so you can focus on building your application logic and iterate faster.
Instructor for PHP is inspired by the Instructor library for Python created by Jason Liu.
Here's a simple CLI demo app using Instructor to extract structured data from text:

Structure classCheck out implementations in other languages below:
If you want to port Instructor to another language, please reach out to us on Twitter we'd love to help you get started!
Instructor introduces three key enhancements compared to direct API usage.
You just specify a PHP class to extract data into via the 'magic' of LLM chat completion. And that's it.
Instructor reduces brittleness of the code extracting the information from textual data by leveraging structured LLM responses.
Instructor helps you write simpler, easier to understand code - you no longer have to define lengthy function call definitions or write code for assigning returned JSON into target data objects.
Response model generated by LLM can be automatically validated, following set of rules. Currently, Instructor supports only Symfony validation.
You can also provide a context object to use enhanced validator capabilities.
You can set the number of retry attempts for requests.
Instructor will repeat requests in case of validation or deserialization error up to the specified number of times, trying to get a valid response from LLM.
Installing Instructor is simple. Run following command in your terminal, and you're on your way to a smoother data handling experience!
composer require cognesy/instructor-phpThis is a simple example demonstrating how Instructor retrieves structured information from provided text (or chat message sequence).
Response model class is a plain PHP class with typehints specifying the types of fields of the object.
use CognesyInstructorInstructor;
// Step 0: Create .env file in your project root:
// OPENAI_API_KEY=your_api_key
// Step 1: Define target data structure(s)
class Person {
public string $name;
public int $age;
}
// Step 2: Provide content to process
$text = "His name is Jason and he is 28 years old.";
// Step 3: Use Instructor to run LLM inference
$person = (new Instructor)->respond(
messages: $text,
responseModel: Person::class,
);
// Step 4: Work with structured response data
assert($person instanceof Person); // true
assert($person->name === 'Jason'); // true
assert($person->age === 28); // true
echo $person->name; // Jason
echo $person->age; // 28
var_dump($person);
// Person {
// name: "Jason",
// age: 28
// } NOTE: Instructor supports classes / objects as response models. In case you want to extract simple types or enums, you need to wrap them in Scalar adapter - see section below: Extracting Scalar Values.
Instructor allows you to define multiple API connections in llm.php file.
This is useful when you want to use different LLMs or API providers in your application.
Default configuration is located in /config/llm.php in the root directory
of Instructor codebase. It contains a set of predefined connections to all LLM APIs
supported out-of-the-box by Instructor.
Config file defines connections to LLM APIs and their parameters. It also specifies the default connection to be used when calling Instructor without specifying the client connection.
// This is fragment of /config/llm.php file
'defaultConnection' => 'openai',
//...
'connections' => [
'anthropic' => [ ... ],
'azure' => [ ... ],
'cohere1' => [ ... ],
'cohere2' => [ ... ],
'fireworks' => [ ... ],
'gemini' => [ ... ],
'grok' => [ ... ],
'groq' => [ ... ],
'mistral' => [ ... ],
'ollama' => [
'providerType' => LLMProviderType::Ollama->value,
'apiUrl' => 'http://localhost:11434/v1',
'apiKey' => Env::get('OLLAMA_API_KEY', ''),
'endpoint' => '/chat/completions',
'defaultModel' => 'qwen2.5:0.5b',
'defaultMaxTokens' => 1024,
'httpClient' => 'guzzle-ollama', // use custom HTTP client configuration
],
'openai' => [ ... ],
'openrouter' => [ ... ],
'together' => [ ... ],
// ...To customize the available connections you can either modify existing entries or add your own.
Connecting to LLM API via predefined connection is as simple as calling withClient
method with the connection name.
<?php
// ...
$user = (new Instructor)
->withConnection('ollama')
->respond(
messages: "His name is Jason and he is 28 years old.",
responseModel: Person::class,
);
// ...You can change the location of the configuration files for Instructor to use via
INSTRUCTOR_CONFIG_PATH environment variable. You can use copies of the default
configuration files as a starting point.
Instructor offers a way to use structured data as an input. This is useful when you want to use object data as input and get another object with a result of LLM inference.
The input field of Instructor's respond() and request() methods
can be an object, but also an array or just a string.
<?php
use CognesyInstructorInstructor;
class Email {
public function __construct(
public string $address = '',
public string $subject = '',
public string $body = '',
) {}
}
$email = new Email(
address: 'joe@gmail',
subject: 'Status update',
body: 'Your account has been updated.'
);
$translation = (new Instructor)->respond(
input: $email,
responseModel: Email::class,
prompt: 'Translate the text fields of email to Spanish. Keep other fields unchanged.',
);
assert($translation instanceof Email); // true
dump($translation);
// Email {
// address: "joe@gmail",
// subject: "Actualización de estado",
// body: "Su cuenta ha sido actualizada."
// }
?>Instructor validates results of LLM response against validation rules specified in your data model.
For further details on available validation rules, check Symfony Validation constraints.
use SymfonyComponentValidatorConstraints as Assert;
class Person {
public string $name;
#[AssertPositiveOrZero]
public int $age;
}
$text = "His name is Jason, he is -28 years old.";
$person = (new Instructor)->respond(
messages: [['role' => 'user', 'content' => $text]],
responseModel: Person::class,
);
// if the resulting object does not validate, Instructor throws an exceptionIn case maxRetries parameter is provided and LLM response does not meet validation criteria, Instructor will make subsequent inference attempts until results meet the requirements or maxRetries is reached.
Instructor uses validation errors to inform LLM on the problems identified in the response, so that LLM can try self-correcting in the next attempt.
use SymfonyComponentValidatorConstraints as Assert;
class Person {
#[AssertLength(min: 3)]
public string $name;
#[AssertPositiveOrZero]
public int $age;
}
$text = "His name is JX, aka Jason, he is -28 years old.";
$person = (new Instructor)->respond(
messages: [['role' => 'user', 'content' => $text]],
responseModel: Person::class,
maxRetries: 3,
);
// if all LLM's attempts to self-correct the results fail, Instructor throws an exceptionYou can call request() method to set the parameters of the request and then call get() to get the response.
use CognesyInstructorInstructor;
$instructor = (new Instructor)->request(
messages: "His name is Jason, he is 28 years old.",
responseModel: Person::class,
);
$person = $instructor->get();Instructor supports streaming of partial results, allowing you to start processing the data as soon as it is available.
<?php
use CognesyInstructorInstructor;
$stream = (new Instructor)->request(
messages: "His name is Jason, he is 28 years old.",
responseModel: Person::class,
options: ['stream' => true]
)->stream();
foreach ($stream as $partialPerson) {
// process partial person data
echo $partialPerson->name;
echo $partialPerson->age;
}
// after streaming is done you can get the final, fully processed person object...
$person = $stream->getLastUpdate()
// ...to, for example, save it to the database
$db->save($person);
?>You can define onPartialUpdate() callback to receive partial results that can be used to start updating UI before LLM completes the inference.
NOTE: Partial updates are not validated. The response is only validated after it is fully received.
use CognesyInstructorInstructor;
function updateUI($person) {
// Here you get partially completed Person object update UI with the partial result
}
$person = (new Instructor)->request(
messages: "His name is Jason, he is 28 years old.",
responseModel: Person::class,
options: ['stream' => true]
)->onPartialUpdate(
fn($partial) => updateUI($partial)
)->get();
// Here you get completed and validated Person object
$this->db->save($person); // ...for example: save to DBYou can provide a string instead of an array of messages. This is useful when you want to extract data from a single block of text and want to keep your code simple.
// Usually, you work with sequences of messages:
$value = (new Instructor)->respond(
messages: [['role' => 'user', 'content' => "His name is Jason, he is 28 years old."]],
responseModel: Person::class,
);
// ...but if you want to keep it simple, you can just pass a string:
$value = (new Instructor)->respond(
messages: "His name is Jason, he is 28 years old.",
responseModel: Person::class,
);Sometimes we just want to get quick results without defining a class for the response model, especially if we're trying to get a straight, simple answer in a form of string, integer, boolean or float. Instructor provides a simplified API for such cases.
use CognesyInstructorExtrasScalarScalar;
use CognesyInstructorInstructor;
$value = (new Instructor)->respond(
messages: "His name is Jason, he is 28 years old.",
responseModel: Scalar::integer('age'),
);
var_dump($value);
// int(28)In this example, we're extracting a single integer value from the text. You can also use Scalar::string(), Scalar::boolean() and Scalar::float() to extract other types of values.
Additionally, you can use Scalar adapter to extract one of the provided options by using Scalar::enum().
use CognesyInstructorExtrasScalarScalar;
use CognesyInstructorInstructor;
enum ActivityType : string {
case Work = 'work';
case Entertainment = 'entertainment';
case Sport = 'sport';
case Other = 'other';
}
$value = (new Instructor)->respond(
messages: "His name is Jason, he currently plays Doom Eternal.",
responseModel: Scalar::enum(ActivityType::class, 'activityType'),
);
var_dump($value);
// enum(ActivityType:Entertainment)Sequence is a wrapper class that can be used to represent a list of objects to be extracted by Instructor from provided context.
It is usually more convenient not create a dedicated class with a single array property just to handle a list of objects of a given class.
Additional, unique feature of sequences is that they can be streamed per each completed item in a sequence, rather than on any property update.
class Person
{
public string $name;
public int $age;
}
$text = <<<TEXT
Jason is 25 years old. Jane is 18 yo. John is 30 years old
and Anna is 2 years younger than him.
TEXT;
$list = (new Instructor)->respond(
messages: [['role' => 'user', 'content' => $text]],
responseModel: Sequence::of(Person::class),
options: ['stream' => true]
);See more about sequences in the Sequences section.
Use PHP type hints to specify the type of extracted data.
Use nullable types to indicate that given field is optional.
class Person {
public string $name;
public ?int $age;
public Address $address;
}You can also use PHP DocBlock style comments to specify the type of extracted data. This is useful when you want to specify property types for LLM, but can't or don't want to enforce type at the code level.
class Person {
/** @var string */
public $name;
/** @var int */
public $age;
/** @var Address $address person's address */
public $address;
}See PHPDoc documentation for more details on DocBlock website.
PHP currently does not support generics or typehints to specify array element types.
Use PHP DocBlock style comments to specify the type of array elements.
class Person {
// ...
}
class Event {
// ...
/** @var Person[] list of extracted event participants */
public array $participants;
// ...
}Instructor can retrieve complex data structures from text. Your response model can contain nested objects, arrays, and enums.
use CognesyInstructorInstructor;
// define a data structures to extract data into
class Person {
public string $name;
public int $age;
public string $profession;
/** @var Skill[] */
public array $skills;
}
class Skill {
public string $name;
public SkillType $type;
}
enum SkillType {
case Technical = 'technical';
case Other = 'other';
}
$text = "Alex is 25 years old software engineer, who knows PHP, Python and can play the guitar.";
$person = (new Instructor)->respond(
messages: [['role' => 'user', 'content' => $text]],
responseModel: Person::class,
); // client is passed explicitly, can specify e.g. different base URL
// data is extracted into an object of given class
assert($person instanceof Person); // true
// you can access object's extracted property values
echo $person->name; // Alex
echo $person->age; // 25
echo $person->profession; // software engineer
echo $person->skills[0]->name; // PHP
echo $person->skills[0]->type; // SkillType::Technical
// ...
var_dump($person);
// Person {
// name: "Alex",
// age: 25,
// profession: "software engineer",
// skills: [
// Skill {
// name: "PHP",
// type: SkillType::Technical,
// },
// Skill {
// name: "Python",
// type: SkillType::Technical,
// },
// Skill {
// name: "guitar",
// type: SkillType::Other
// },
// ]
// }If you want to define the shape of data during runtime, you can use Structure class.
Structures allow you to define and modify arbitrary shape of data to be extracted by LLM. Classes may not be the best fit for this purpose, as declaring or changing them during execution is not possible.
With structures, you can define custom data shapes dynamically, for example based on the user input or context of the processing, to specify the information you need LLM to infer from the provided text or chat messages.
Example below demonstrates how to define a structure and use it as a response model:
<?php
use CognesyInstructorExtrasStructureField;
use CognesyInstructorExtrasStructureStructure;
enum Role : string {
case Manager = 'manager';
case Line = 'line';
}
$structure = Structure::define('person', [
Field::string('name'),
Field::int('age'),
Field::enum('role', Role::class),
]);
$person = (new Instructor)->respond(
messages: 'Jason is 25 years old and is a manager.',
responseModel: $structure,
);
// you can access structure data via field API...
assert($person->field('name') === 'Jason');
// ...or as structure object properties
assert($person->age === 25);
?>For more information see Structures section.
You can specify model and other options that will be passed to OpenAI / LLM endpoint.
use CognesyInstructorFeaturesLLMDataLLMConfig;
use CognesyInstructorFeaturesLLMDriversOpenAIDriver;
use CognesyInstructorInstructor;
// OpenAI auth params
$yourApiKey = Env::get('OPENAI_API_KEY'); // use your own API key
// Create instance of OpenAI driver initialized with custom parameters
$driver = new OpenAIDriver(new LLMConfig(
apiUrl: 'https://api.openai.com/v1', // you can change base URI
apiKey: $yourApiKey,
endpoint: '/chat/completions',
metadata: ['organization' => ''],
model: 'gpt-4o-mini',
maxTokens: 128,
));
/// Get Instructor with the default client component overridden with your own
$instructor = (new Instructor)->withDriver($driver);
$user = $instructor->respond(
messages: "Jason (@jxnlco) is 25 years old and is the admin of this project. He likes playing football and reading books.",
responseModel: User::class,
model: 'gpt-3.5-turbo',
options: ['stream' => true ]
);Instructor offers out of the box support for following API providers:
For usage examples, check Hub section or examples directory in the code repository.
You can use PHP DocBlocks (/** */) to provide additional instructions for LLM at class or field level, for example to clarify what you expect or how LLM should process your data.
Instructor extracts PHP DocBlocks comments from class and property defined and includes them in specification of response model sent to LLM.
Using PHP DocBlocks instructions is not required, but sometimes you may want to clarify your intentions to improve LLM's inference results.
/**
* Represents a skill of a person and context in which it was mentioned.
*/
class Skill {
public string $name;
/** @var SkillType $type type of the skill, derived from the description and context */
public SkillType $type;
/** Directly quoted, full sentence mentioning person's skill */
public string $context;
}You can use ValidationMixin trait to add ability of easy, custom data object validation.
use CognesyInstructorFeaturesValidationTraitsValidationMixin;
class User {
use ValidationMixin;
public int $age;
public int $name;
public function validate() : array {
if ($this->age < 18) {
return ["User has to be adult to sign the contract."];
}
return [];
}
}Instructor uses Symfony validation component to validate extracted data. You can use #[Assert/Callback] annotation to build fully customized validation logic.
use CognesyInstructorInstructor;
use SymfonyComponentValidatorConstraints as Assert;
use Symfony

