snips nlu
0.20.2
Snips NLU (Natural Language Understanding) is a Python library that allows to extract structured information from sentences written in natural language.
Behind every chatbot and voice assistant lies a common piece of technology: Natural Language Understanding (NLU). Anytime a user interacts with an AI using natural language, their words need to be translated into a machine-readable description of what they meant.
The NLU engine first detects what the intention of the user is (a.k.a. intent), then extracts the parameters (called slots) of the query. The developer can then use this to determine the appropriate action or response.
Let’s take an example to illustrate this, and consider the following sentence:
"What will be the weather in paris at 9pm?"
Properly trained, the Snips NLU engine will be able to extract structured data such as:
{
"intent": {
"intentName": "searchWeatherForecast",
"probability": 0.95
},
"slots": [
{
"value": "paris",
"entity": "locality",
"slotName": "forecast_locality"
},
{
"value": {
"kind": "InstantTime",
"value": "2018-02-08 20:00:00 +00:00"
},
"entity": "snips/datetime",
"slotName": "forecast_start_datetime"
}
]
}In this case, the identified intent is searchWeatherForecast and two slots were extracted, a locality and a datetime. As you can see, Snips NLU does an extra step on top of extracting entities: it resolves them. The extracted datetime value has indeed been converted into a handy ISO format.
Check out our blog post to get more details about why we built Snips NLU and how it works under the hood. We also published a paper on arxiv, presenting the machine learning architecture of the Snips Voice Platform.
pip install snips-nluWe currently have pre-built binaries (wheels) for snips-nlu and its
dependencies for MacOS (10.11 and later), Linux x86_64 and Windows.
For any other architecture/os snips-nlu can be installed from the source
distribution. To do so, Rust
and setuptools_rust must be
installed before running the pip install snips-nlu command.
Snips NLU relies on external language resources that must be downloaded before the library can be used. You can fetch resources for a specific language by running the following command:
python -m snips_nlu download enOr simply:
snips-nlu download enThe list of supported languages is available at this address.
The easiest way to test the abilities of this library is through the command line interface.
First, start by training the NLU with one of the sample datasets:
snips-nlu train path/to/dataset.json path/to/output_trained_engineWhere path/to/dataset.json is the path to the dataset which will be used during training, and path/to/output_trained_engine is the location where the trained engine should be persisted once the training is done.
After that, you can start parsing sentences interactively by running:
snips-nlu parse path/to/trained_engineWhere path/to/trained_engine corresponds to the location where you have stored the trained engine during the previous step.
Here is a sample code that you can run on your machine after having installed snips-nlu, fetched the english resources and downloaded one of the sample datasets:
>>> from __future__ import unicode_literals, print_function
>>> import io
>>> import json
>>> from snips_nlu import SnipsNLUEngine
>>> from snips_nlu.default_configs import CONFIG_EN
>>> with io.open("sample_datasets/lights_dataset.json") as f:
... sample_dataset = json.load(f)
>>> nlu_engine = SnipsNLUEngine(config=CONFIG_EN)
>>> nlu_engine = nlu_engine.fit(sample_dataset)
>>> text = "Please turn the light on in the kitchen"
>>> parsing = nlu_engine.parse(text)
>>> parsing["intent"]["intentName"]
'turnLightOn'What it does is training an NLU engine on a sample weather dataset and parsing a weather query.
Here is a list of some datasets that can be used to train a Snips NLU engine:
In January 2018, we reproduced an academic benchmark which was published during the summer 2017. In this article, authors assessed the performance of API.ai (now Dialogflow, Google), Luis.ai (Microsoft), IBM Watson, and Rasa NLU. For fairness, we used an updated version of Rasa NLU and compared it to the latest version of Snips NLU (both in dark blue).
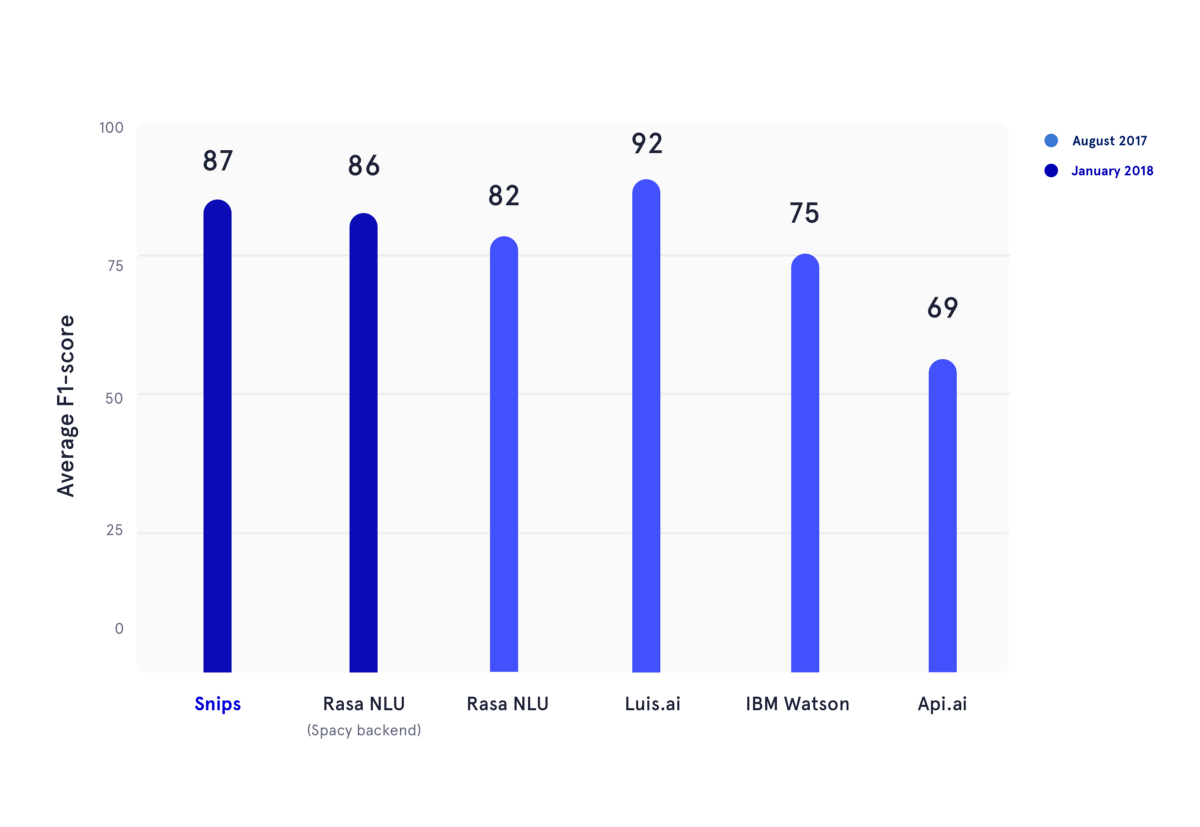
In the figure above, F1 scores of both intent classification and slot filling were computed for several NLU providers, and averaged across the three datasets used in the academic benchmark mentionned before. All the underlying results can be found here.
To find out how to use Snips NLU please refer to the package documentation, it will provide you with a step-by-step guide on how to setup and use this library.
Please cite the following paper when using Snips NLU:
@article{coucke2018snips,
title = {Snips Voice Platform: an embedded Spoken Language Understanding system for private-by-design voice interfaces},
author = {Coucke, Alice and Saade, Alaa and Ball, Adrien and Bluche, Th{'e}odore and Caulier, Alexandre and Leroy, David and Doumouro, Cl{'e}ment and Gisselbrecht, Thibault and Caltagirone, Francesco and Lavril, Thibaut and others},
journal = {arXiv preprint arXiv:1805.10190},
pages = {12--16},
year = {2018}
}Please join the forum to ask your questions and get feedback from the community.
Please see the Contribution Guidelines.
This library is provided by Snips as Open Source software. See LICENSE for more information.
The snips/city, snips/country and snips/region builtin entities rely on software from Geonames, which is made available under a Creative Commons Attribution 4.0 license international. For the license and warranties for Geonames please refer to: https://creativecommons.org/licenses/by/4.0/legalcode.


