RLAIF V
1.0.0

Aligning MLLMs through Open-Source AI Feedback for Super GPT-4V Trustworthiness
中文 | English
[2024.11.26] We support LoRA training now!
[2024.05.28] Our paper is accesible at arXiv now!
[2024.05.20] Our RLAIF-V-Dataset is used for training MiniCPM-Llama3-V 2.5, which represents the first end-side GPT-4V level MLLM!
[2024.05.20] We open-source the code, weights (7B, 12B) and data of RLAIF-V!
We introduce RLAIF-V, a novel framework that aligns MLLMs in a fully open-source paradigm for super GPT-4V trustworthiness. RLAIF-V maximally exploits the open-source feedback from two key perspectives, including high-quality feedback data and online feedback learning algorithm. Notable features of RLAIF-V include:
Super GPT-4V Trustworthiness via Open-source Feedback. By learning from open-source AI feedback, RLAIF-V 12B achieves super GPT-4V trustworthiness in both generative and discriminative tasks.
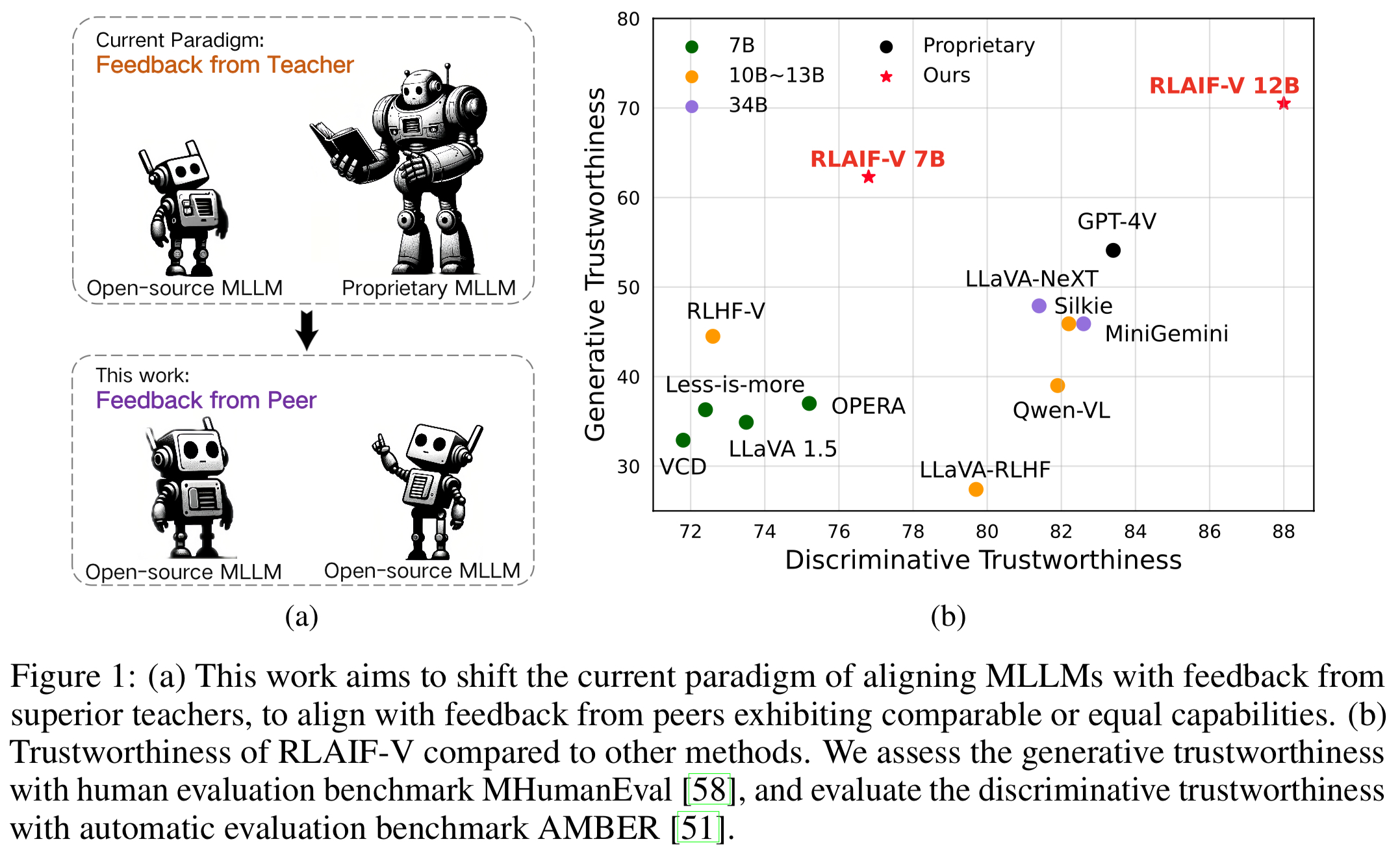
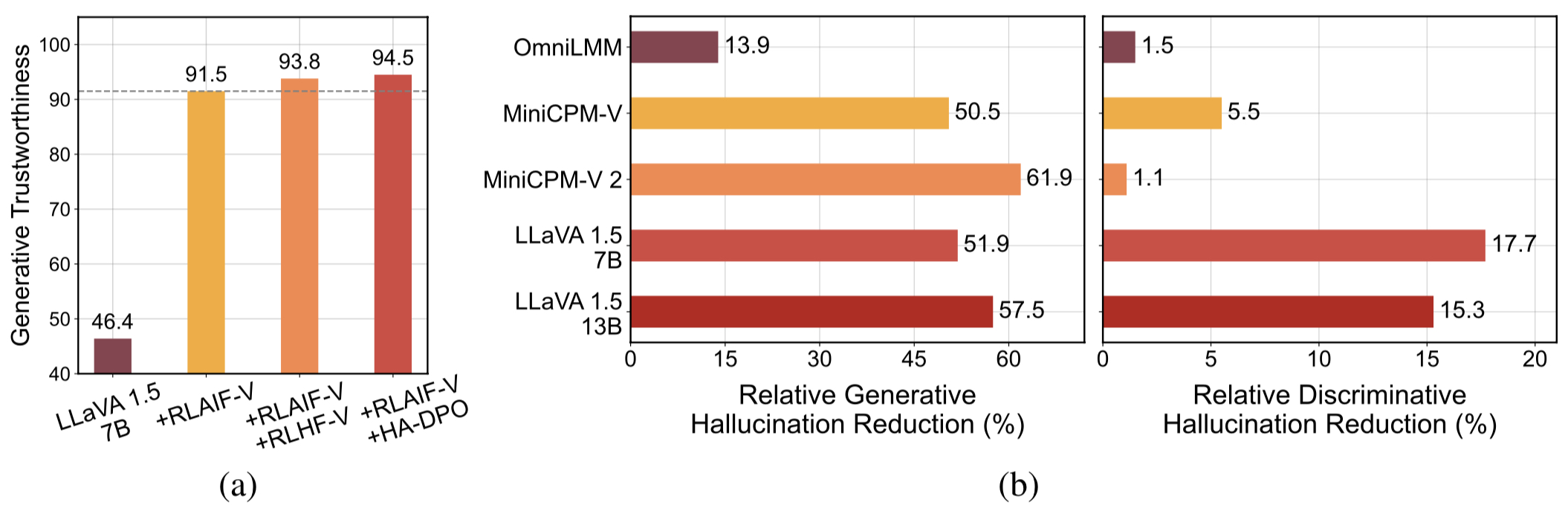
High-quality Generalizable Feedback Data. The feedback data usesed by RLAIF-V effectively reduce the hallucination of different MLLMs.
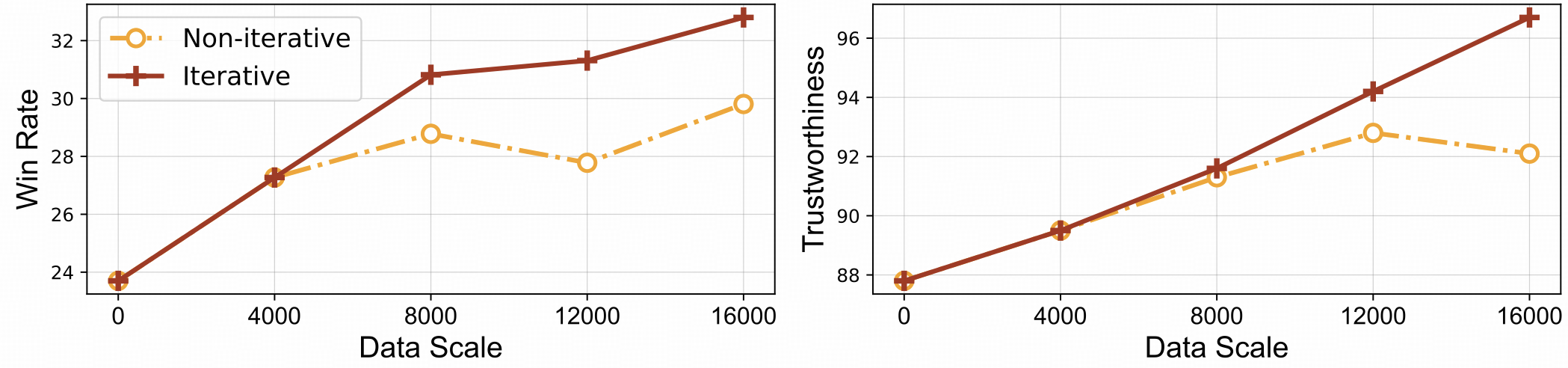
⚡️ Efficient Feedback Learning with Iterative Alignment. RLAIF-V exihibts both better learning efficiency and higher performance compared with the non-iterative approach.
Dataset
Install
Model Weights
Inference
Data Generation
Train
Evaluation
Object HalBench
MMHal Bench
RefoMB
Citation
We present the RLAIF-V Dataset, which is an AI generated preference dataset covering diverse range of tasks and domains. This open-source multimodal preference datasets contains 83,132 high-quality comparison pairs. The dataset contains the generated preference pairs in each training iteration of different models, including LLaVA 1.5 7B, OmniLMM 12B and MiniCPM-V.
Clone this repository and navigate to RLAIF-V folder
git clone https://github.com/RLHF-V/RLAIF-V.gitcd RLAIF-V
Install package
conda create -n rlaifv python=3.10 -y conda activate rlaifv pip install -e .
Install required spaCy model
wget https://github.com/explosion/spacy-models/releases/download/en_core_web_trf-3.7.3/en_core_web_trf-3.7.3.tar.gz pip install en_core_web_trf-3.7.3.tar.gz
| Model | Description | Download |
|---|---|---|
| RLAIF-V 7B | The most trustworthy variant on LLaVA 1.5 | ? |
| RLAIF-V 12B | Based on OmniLMM-12B, achieving super GPT-4V trustworthiness. | ? |
We provide a simple example to show how to use RLAIF-V.
from chat import RLAIFVChat, img2base64chat_model = RLAIFVChat('openBMB/RLAIF-V-7B') # or 'openBMB/RLAIF-V-12B'image_path="./examples/test.jpeg"msgs = "Describe in detail the people in the picture."inputs = {"image": image_path, "question": msgs}answer = chat_model.chat(inputs)print(answer)You can also run this example by executing the following script:
python chat.py

Question:
Why did the car in the picture stop?
Expected outputs:
In the picture, a car stopped on the road due to the presence of a sheep on the roadway. The car likely stopped to allow the sheep to safely move out of the way or avoid any potential accidents with the animal. This situation highlights the importance of being cautious and attentive while driving, especially in areas where animals may roam near roads.
Environment Setup
We provide the OmniLMM 12B model and the MiniCPM-Llama3-V 2.5 model for feedback generation. If you wish to use the MiniCPM-Llama3-V 2.5 for giving feedback, please configure its inference environment according to the instructions in the MiniCPM-V GitHub repository.
Please download our fine-tuned Llama3 8B models: split model and question transformation model, and store them in the ./models/llama3_split folder and the ./models/llama3_changeq folder respectively.
OmniLMM 12B Model Feedback
The following script demonstrates using the LLaVA-v1.5-7b model to generate candidate answers and the OmniLMM 12B model to provide feedback.
mkdir ./results bash ./script/data_gen/run_data_pipeline_llava15_omni.sh
MiniCPM-Llama3-V 2.5 Model Feedback
The following script demonstrates using the LLaVA-v1.5-7b model to generate candidate answers and the MiniCPM-Llama3-V 2.5 model to provide feedback. First, replace minicpmv_python in ./script/data_gen/run_data_pipeline_llava15_minicpmv.sh with the Python path of the MiniCPM-V environment you created.
mkdir ./results bash ./script/data_gen/run_data_pipeline_llava15_minicpmv.sh
Prepare data (Optional)
If you can access huggingface dataset, you can skip this step, we will automatically download the RLAIF-V Dataset.
If you already downloaded the dataset, you can replace 'openbmb/RLAIF-V-Dataset' to your dataset path here at Line 38.
Training
Here, we provide a training script to train the model in 1 iteration. The max_step parameter should be adjusted according to the amount of your data.
Fully Fine-tuning
Run the following command to start fully fine-tuning.
bash ./script/train/llava15_train.sh
LoRA
Run the following command to start lora training.
pip install peft bash ./script/train/llava15_train_lora.sh
Iterative alignment
To reproduce the iterative training process in the paper, you need to do the following steps for 4 times:
S1. Data generation.
Follow the instructions in data generation to generate preference pairs for the base model. Convert the generated jsonl file to huggingface parquet.
S2. Change training config.
In dataset code, replace 'openbmb/RLAIF-V-Dataset' here to your data path.
In training script, replace --data_dir with a new directory, replace --model_name_or_path with the base model path, set --max_step to the number of steps for 4 epoch, set --save_steps to the number of steps for 1/4 epoch.
S3. Do DPO training.
Run the training script to train the base model.
S4. Choose base model for next iteration.
Evaluate each checkpoint on Object HalBench and MMHal Bench, choose the best-performed checkpoint as the base model in the next iteration.
Prepare COCO2014 annotations
The evaluation of Object HalBench relies on the caption and segmentation annotations from the COCO2014 dataset. Please first download the COCO2014 dataset from the COCO dataset's official website.
mkdir coco2014cd coco2014 wget http://images.cocodataset.org/annotations/annotations_trainval2014.zip unzip annotations_trainval2014.zip
Inference, evaluation, and summarization
Please replace {YOUR_OPENAI_API_KEY} with a valid OpenAI api-key.
Note: The evaluation is based on gpt-3.5-turbo-0613.
# cd RLAIF-Vbash ./script/eval/eval_rlaifv_objhal.sh ./RLAIF-V_weight ./results/RLAIF-V ./coco2014/annotations {YOUR_OPENAI_API_KEY}Prepare MMHal Data
Please download the MMHal evaluation data here, and save the file in eval/data.
Run the following script to generate for MMHal Bench:
Note: The evaluation is based on gpt-4-1106-preview.
# cd RLAIF-Vbash ./script/eval/eval_rlaifv_mmhal.sh ./RLAIF-V_weight ./results/RLAIF-V {YOUR_OPENAI_API_KEY}Preparation
To use GPT-4 evaluation, please first run pip install openai==0.28 to install openai package. Next, change the openai.base and openai.api_key in eval/gpt4.py into your own setting.
Evaluation data for dev set can be found at eval/data/RefoMB_dev.jsonl. You need to download each image from the image_url key in each line.
Evaluation for overall score
Save your model answer in answer key of the input data file eval/data/RefoMB_dev.jsonl, for example:
{
"image_url": "https://thunlp.oss-cn-qingdao.aliyuncs.com/multimodal_openmme_test_20240319__20.jpg",
"question": "What is the background of the image?",
"type": "Coarse Perception",
"split": "dev",
"answer": "The background of the image features trees, suggesting that the scene takes place outdoors.",
"gt_description": "......"
}Run the following script to evaluate your model result:
save_dir="YOUR SAVING DIR" model_ans_path="YOUR MODEL ANSWER PATH" model_name="YOUR MODEL NAME" bash ./script/eval/run_refobm_overall.sh $save_dir $model_ans_path $model_name
Evaluation for hallucination score
After evaluating the overall score, an evaluation result file will be created with name A-GPT-4V_B-${model_name}.json. Using this evaluation result file to calculate the hallucination score as follows:
eval_result="EVAL RESULT FILE PATH, e.g. 'A-GPT-4V_B-${model_name}'"
# Do not include ".json" in your file path!
bash ./script/eval/run_refomb_hall.sh $eval_resultNote: For better stability, we recommend you to evaluate more than 3 times and use the average score as the final model score.
Usage and License Notices: The data, code, and checkpoint are intended and licensed for research use only. They are also restricted to uses that follow the license agreement of LLaMA, Vicuna, and Chat GPT. The dataset is CC BY NC 4.0 (allowing only non-commercial use) and models trained using the dataset should not be used outside of research purposes.
RLHF-V: The codebase we built upon.
LLaVA: The instruction model and labeler model of RLAIF-V-7B.
MiniCPM-V: The instruction model and labeler model of RLAIF-V-12B.
If you find our model/code/data/paper helpful, please consider cite our papers and star us ️!
@article{yu2023rlhf, title={Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback}, author={Yu, Tianyu and Yao, Yuan and Zhang, Haoye and He, Taiwen and Han, Yifeng and Cui, Ganqu and Hu, Jinyi and Liu, Zhiyuan and Zheng, Hai-Tao and Sun, Maosong and others}, journal={arXiv preprint arXiv:2312.00849}, year={2023}}@article{yu2024rlaifv, title={RLAIF-V: Aligning MLLMs through Open-Source AI Feedback for Super GPT-4V Trustworthiness}, author={Yu, Tianyu and Zhang, Haoye and Yao, Yuan and Dang, Yunkai and Chen, Da and Lu, Xiaoman and Cui, Ganqu and He, Taiwen and Liu, Zhiyuan and Chua, Tat-Seng and Sun, Maosong}, journal={arXiv preprint arXiv:2405.17220}, year={2024},
} 

