ChatLM mini Chinese
1.0.0
Chinese | English
Today's large language models tend to have larger parameters, and consumer-grade computers are slower to perform simple inferences, let alone train a model from scratch. The goal of this project is to train a generative language model from scratch, including data cleaning, tokenizer training, model pre-training, SFT instruction fine-tuning, RLHF optimization, etc.
ChatLM-mini-Chinese is a small Chinese dialogue model with only 0.2B model parameters (about 210M including shared weights). It can be pre-trained on a machine with a minimum of 4GB of video memory ( batch_size=1 , fp16 or bf16 ), and float16 loading and inference require at least Requires 512MB of video memory.
Huggingface NLP framework, including transformers , accelerate , trl , peft , etc.trainer supports pre-training and SFT fine-tuning on a single machine with a single card or with multiple cards on a single machine. It supports stopping at any position during training and continuing training at any position.Text-to-Text pre-training and non- mask prediction pre-training.sentencepiece and huggingface tokenizers ;batch_size=1, max_len=320 , pre-training is supported on a machine with at least 16GB memory + 4GB video memory;trainer supports prompt command fine-tuning and supports any breakpoint to continue training;sequence to sequence fine-tuning of Huggingface trainer ;peft lora for preference optimization;Lora adapter can be merged into the original model.If you need to do retrieval enhanced generation (RAG) based on small models, you can refer to my other project Phi2-mini-Chinese. For the code, see rag_with_langchain.ipynb
? Latest updates
All data sets come from single-round conversation data sets published on the Internet. After data cleaning and formatting, they are saved as parquet files. For the data processing process, see utils/raw_data_process.py . Main data sets include:
Belle_open_source_1M , train_2M_CN , and train_3.5M_CN that have short answers, do not contain complex table structures, and translation tasks (no English vocabulary list), a total of 3.7 million rows, and 3.38 million rows remain after cleaning.N words of the encyclopedia are the answers. Encyclopedia data of 202309 is used, and 1.19 million entry prompts and answers remain after cleaning. Wiki download: zhwiki, convert the downloaded bz2 file to wiki.txt reference: WikiExtractor. The total number of data sets is 10.23 million: Text-to-Text pre-training set: 9.3 million, evaluation set: 25,000 (because the decoding is slow, the evaluation set is not set too large). Test set: 900,000. SFT fine-tuning and DPO optimization data sets are shown below.
T5 model (Text-to-Text Transfer Transformer), for details, see the paper: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.
The model source code comes from huggingface, see: T5ForConditionalGeneration.
See model_config.json for model configuration. The official T5-base : encoder layer and decoder layer are both 12 layers. In this project, these two parameters are modified to 10 layers.
Model parameters: 0.2B. Word list size: 29298, including only Chinese and a small amount of English.
hardware:
# 预训练阶段:
CPU: 28 vCPU Intel(R) Xeon(R) Gold 6330 CPU @ 2.00GHz
内存:60 GB
显卡:RTX A5000(24GB) * 2
# sft及dpo阶段:
CPU: Intel(R) i5-13600k @ 5.1GHz
内存:32 GB
显卡:NVIDIA GeForce RTX 4060 Ti 16GB * 1 Tokenizer training : The existing tokenizer training library has an OOM problem when encountering large corpus. Therefore, the full corpus is merged and constructed based on word frequency according to a method similar to BPE , which takes half a day to run.
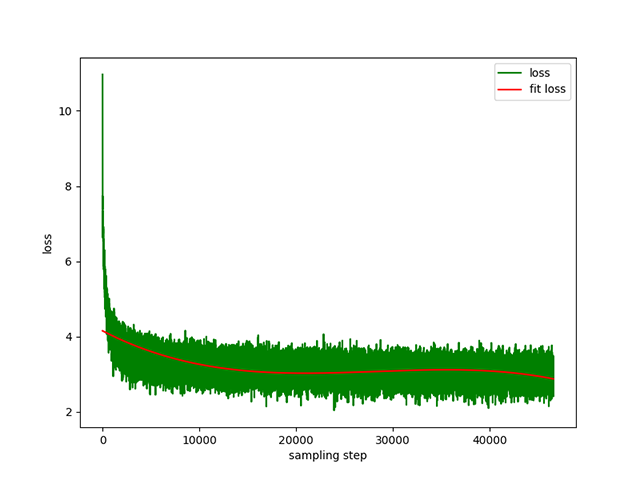
Text-to-Text pre-training : a dynamic learning rate of 1e-4 to 5e-3 , and a pre-training time of 8 days. Training loss:
belle instruction training data set (both instruction and answer lengths are below 512), the learning rate is a dynamic learning rate from 1e-7 to 5e-5 , and the fine-tuning time is 2 days. Fine-tuning loss: 
chosen text. In step 2 , the SFT model batch generate the prompts in the data set and obtains the rejected text. It takes 1 day to optimize the dpo full preference and learn. The rate is le-5 , half-precision fp16 , a total of 2 epoch , and it takes 3 hours. dpo loss: 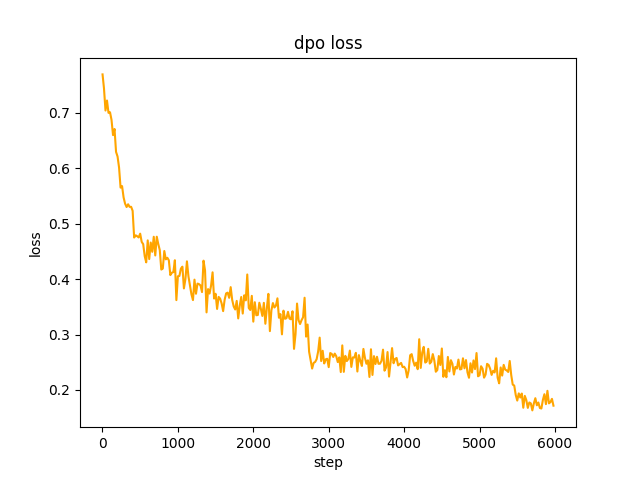
By default, TextIteratorStreamer of huggingface transformers is used to implement streaming dialogue, which only supports greedy search . If you need other generation methods such as beam sample , please change the stream_chat parameter of cli_demo.py to False . 

There are problems: the pre-training data set only has more than 9 million, and the model parameters are only 0.2B. It cannot cover all aspects, and there will be situations where the answer is wrong and the generator is nonsense.
If huggingface cannot be connected, use modelscope.snapshot_download to download the model file from modelscope.
from transformers import AutoTokenizer , AutoModelForSeq2SeqLM
import torch
model_id = 'charent/ChatLM-mini-Chinese'
# 如果无法连接huggingface,打开以下两行代码的注释,将从modelscope下载模型文件,模型文件保存到'./model_save'目录
# from modelscope import snapshot_download
# model_id = snapshot_download(model_id, cache_dir='./model_save')
device = torch . device ( 'cuda' if torch . cuda . is_available () else 'cpu' )
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForSeq2SeqLM . from_pretrained ( model_id , trust_remote_code = True ). to ( device )
txt = '如何评价Apple这家公司?'
encode_ids = tokenizer ([ txt ])
input_ids , attention_mask = torch . LongTensor ( encode_ids [ 'input_ids' ]), torch . LongTensor ( encode_ids [ 'attention_mask' ])
outs = model . my_generate (
input_ids = input_ids . to ( device ),
attention_mask = attention_mask . to ( device ),
max_seq_len = 256 ,
search_type = 'beam' ,
)
outs_txt = tokenizer . batch_decode ( outs . cpu (). numpy (), skip_special_tokens = True , clean_up_tokenization_spaces = True )
print ( outs_txt [ 0 ])Apple是一家专注于设计和用户体验的公司,其产品在设计上注重简约、流畅和功能性,而在用户体验方面则注重用户的反馈和使用体验。作为一家领先的科技公司,苹果公司一直致力于为用户提供最优质的产品和服务,不断推陈出新,不断创新和改进,以满足不断变化的市场需求。
在iPhone、iPad和Mac等产品上,苹果公司一直保持着创新的态度,不断推出新的功能和设计,为用户提供更好的使用体验。在iPad上推出的iPad Pro和iPod touch等产品,也一直保持着优秀的用户体验。
此外,苹果公司还致力于开发和销售软件和服务,例如iTunes、iCloud和App Store等,这些产品在市场上也获得了广泛的认可和好评。
总的来说,苹果公司在设计、用户体验和产品创新方面都做得非常出色,为用户带来了许多便利和惊喜。
Caution
The model of this project is a TextToText model. In the prompt , response and other fields in the pre-training, SFT, and RLFH phases, please be sure to add the [EOS] sequence end mark.
git clone --depth 1 https://github.com/charent/ChatLM-mini-Chinese.git
cd ChatLM-mini-Chinese It is recommended to use python 3.10 for this project. Older python versions may not be compatible with the third-party libraries it depends on.
pip installation:
pip install -r ./requirements.txtIf pip installed the CPU version of pytorch, you can install the CUDA version of pytorch with the following command:
# pip 安装torch + cu118
pip3 install torch --index-url https://download.pytorch.org/whl/cu118conda installation:
conda install --yes --file ./requirements.txt Use the git command to download the model weights and configuration files from Hugging Face Hub . You need to install Git LFS first, and then run:
# 使用git命令下载huggingface模型,先安装[Git LFS],否则下载的模型文件不可用
git clone --depth 1 https://huggingface.co/charent/ChatLM-mini-Chinese
# 如果无法连接huggingface,请从modelscope下载
git clone --depth 1 https://www.modelscope.cn/charent/ChatLM-mini-Chinese.git
mv ChatLM-mini-Chinese model_save You can also manually download it directly from the Hugging Face Hub warehouse ChatLM-Chinese-0.2B and move the downloaded file to the model_save directory.
The corpus requirements should be as complete as possible. It is recommended to add multiple corpora, such as encyclopedias, codes, papers, blogs, conversations, etc.
This project is mainly based on wiki Chinese encyclopedia. How to obtain Chinese wiki corpus: Chinese Wiki download address: zhwiki, download zhwiki-[存档日期]-pages-articles-multistream.xml.bz2 file, about 2.7GB, convert the downloaded bz2 file into wiki.txt reference: WikiExtractor, Then use python's OpenCC library to convert it to Simplified Chinese, and finally put the obtained wiki.simple.txt in the data directory of the project root directory. Please merge multiple corpora into one txt file yourself.
Since training tokenizer consumes a lot of memory, if your corpus is very large (the merged txt file exceeds 2G), it is recommended to sample the corpus according to categories and proportions to reduce training time and memory consumption. Training a 1.7GB txt file requires about 48GB of memory (estimated, I only have 32GB, swap is triggered frequently, the computer is stuck for a long time T_T), and 13600k CPU takes about 1 hour.
The difference between char level and byte level is as follows (please search for information on your own for specific usage differences). The tokenizer trains char level by default. If byte level is required, just set token_type='byte' in train_tokenizer.py .
# 原始文本
txt = '这是一段中英混输的句子, (chinese and English, here are words.)'
tokens = charlevel_tokenizer . tokenize ( txt )
print ( tokens )
# char level tokens输出
# ['▁这是', '一段', '中英', '混', '输', '的', '句子', '▁,', '▁(', '▁ch', 'inese', '▁and', '▁Eng', 'lish', '▁,', '▁h', 'ere', '▁', 'are', '▁w', 'ord', 's', '▁.', '▁)']
tokens = bytelevel_tokenizer . tokenize ( txt )
print ( tokens )
# byte level tokens输出
# ['Ġè¿Ļæĺ¯', 'ä¸Ģ段', 'ä¸Ńèĭ±', 'æ··', 'è¾ĵ', 'çļĦ', 'åı¥åŃIJ', 'Ġ,', 'Ġ(', 'Ġch', 'inese', 'Ġand', 'ĠEng', 'lish', 'Ġ,', 'Ġh', 'ere', 'Ġare', 'Ġw', 'ord', 's', 'Ġ.', 'Ġ)']Start training:
# 确保你的训练语料`txt`文件已经data目录下
python train_tokenizer . py {
"prompt" : "对于花园街,你有什么了解或看法吗? " ,
"response" : "花园街(是香港油尖旺区的一条富有特色的街道,位于九龙旺角东部,北至界限街,南至登打士街,与通菜街及洗衣街等街道平行。现时这条街道是香港著名的购物区之一。位于亚皆老街以南的一段花园街,也就是"波鞋街"整条街约150米长,有50多间售卖运动鞋和运动用品的店舖。旺角道至太子道西一段则为排档区,售卖成衣、蔬菜和水果等。花园街一共分成三段。明清时代,花园街是芒角村栽种花卉的地方。此外,根据历史专家郑宝鸿的考证:花园街曾是1910年代东方殷琴拿烟厂的花园。纵火案。自2005年起,花园街一带最少发生5宗纵火案,当中4宗涉及排档起火。2010年。2010年12月6日,花园街222号一个卖鞋的排档于凌晨5时许首先起火,浓烟涌往旁边住宅大厦,消防接报4 "
}jupyter-lab or jupyter notebook:
See the file train.ipynb . It is recommended to use jupyter-lab to avoid considering the situation where the terminal process is killed after disconnecting from the server.
Console:
Console training needs to consider that the process will be killed after the connection is disconnected. It is recommended to use the process daemon tool Supervisor or screen to establish a connection session.
First, you need to configure accelerate , execute the following command, and select according to the prompts. Refer to accelerate.yaml . Note: DeepSpeed is more troublesome to install on Windows .
accelerate config Start training. If you want to use the configuration provided by the project, please add the parameter --config_file ./accelerate.yaml after the following command accelerate launch . This configuration is based on the single-machine 2xGPU configuration.
There are two scripts for pre-training. The trainer implemented in this project corresponds to train.py , and the trainer implemented by huggingface corresponds to pre_train.py . You can use either one and the effect will be the same. The trainer implemented in this project displays more beautiful training information and makes it easier to modify training details (such as loss functions, log records, etc.). All support breakpoints to continue training. The trainer implemented in this project supports continuing training after a breakpoint at any position. Press ctrl+c will save breakpoint information when exiting the script.
Single machine and single card:
# 本项目实现的trainer
accelerate launch ./train.py train
# 或者使用 huggingface trainer
python pre_train.py Single machine with multiple cards: 2 is the number of graphics cards, please modify it according to your actual situation.
# 本项目实现的trainer
accelerate launch --multi_gpu --num_processes 2 ./train.py train
# 或者使用 huggingface trainer
accelerate launch --multi_gpu --num_processes 2 pre_train.pyContinue training from the breakpoint:
# 本项目实现的trainer
accelerate launch --multi_gpu --num_processes 2 ./train.py train --is_keep_training=True
# 或者使用 huggingface trainer
# 需要在`pre_train.py`中的`train`函数添加`resume_from_checkpoint=True`
accelerate launch --multi_gpu --num_processes 2 pre_train.pyThe SFT data set all comes from the contribution of BELLE boss, thank you. The SFT data sets are: generated_chat_0.4M, train_0.5M_CN and train_2M_CN, with approximately 1.37 million rows remaining after cleaning. Example of fine-tuning data set with sft command:
{
"prompt" : "解释什么是欧洲启示录" ,
"response" : "欧洲启示录(The Book of Revelation)是新约圣经的最后一卷书,也被称为《启示录》、《默示录》或《约翰默示录》。这本书从宗教的角度描述了世界末日的来临,以及上帝对世界的审判和拯救。 书中的主题包括来临的基督的荣耀,上帝对人性的惩罚和拯救,以及魔鬼和邪恶力量的存在。欧洲启示录是一个充满象征和暗示的文本,对于解读和理解有许多不同的方法和观点。 "
} Make your own data set by referring to the sample parquet file in the data directory. The data set format is: parquet file is divided into two columns, one column of prompt text, which represents the prompt, and one column of response text, which represents the expected model output. For fine-tuning details, see the train method under model/trainer.py . When is_finetune is set to True , fine-tuning will be performed. Fine-tuning will freeze the embedding layer and encoder layer by default, and only train the decoder layer. If you need to freeze other parameters, please adjust the code yourself.
Run SFT fine-tuning:
# 本项目实现的trainer, 添加参数`--is_finetune=True`即可, 参数`--is_keep_training=True`可从任意断点处继续训练
accelerate launch --multi_gpu --num_processes 2 ./train.py --is_finetune=True
# 或者使用 huggingface trainer, 多GPU请用accelerate launch --multi_gpu --num_processes gpu个数 sft_train.py
python sft_train.pyHere are two common preferred methods: PPO and DPO. Please search papers and blogs for specific implementations.
PPO method (approximate preference optimization, Proximal Policy Optimization)
Step 1: Use the fine-tuning data set to do supervised fine-tuning (SFT, Supervised Finetuning).
Step 2: Use the preference data set (a prompt contains at least 2 responses, one wanted response and one unwanted response. Multiple responses can be sorted by score, and the most wanted one has the highest score) to train the reward model (RM, Reward Model). You can use the peft library to quickly build the Lora reward model.
Step 3: Use RM to perform supervised PPO training on the SFT model so that the model meets preferences.
Use DPO (Direct Preference Optimization) fine-tuning ( this project uses the DPO fine-tuning method, which saves video memory ). On the basis of obtaining the SFT model, there is no need to train the reward model to obtain positive answers (chosen) and negative answers (rejected). ) to start fine-tuning. The fine-tuned chosen text comes from the original data set alpaca-gpt4-data-zh, and the rejected text comes from the model output after SFT fine-tuning for 1 epoch. The other two data sets: huozi_rlhf_data_json and rlhf-reward-single-round-trans_chinese, after merging A total of 80,000 dpo data.
For the dpo data set processing process, see utils/dpo_data_process.py .
DPO preference optimization data set example:
{
"prompt" : "为给定的产品创建一个创意标语。,输入:可重复使用的水瓶。 " ,
"chosen" : " "保护地球,从拥有可重复使用的水瓶开始! " " ,
"rejected" : " "让你的水瓶成为你的生活伴侣,使用可重复使用的水瓶,让你的水瓶成为你的伙伴" "
}Run preference optimization:
# 多GPU请用accelerate launch --multi_gpu --num_processes gpu个数 dpo_train.py
python dpo_train.py Make sure there are the following files in the model_save directory. These files can be found in the Hugging Face Hub warehouse ChatLM-Chinese-0.2B:
ChatLM-mini-Chinese
├─model_save
| ├─config.json
| ├─configuration_chat_model.py
| ├─generation_config.json
| ├─model.safetensors
| ├─modeling_chat_model.py
| ├─special_tokens_map.json
| ├─tokenizer.json
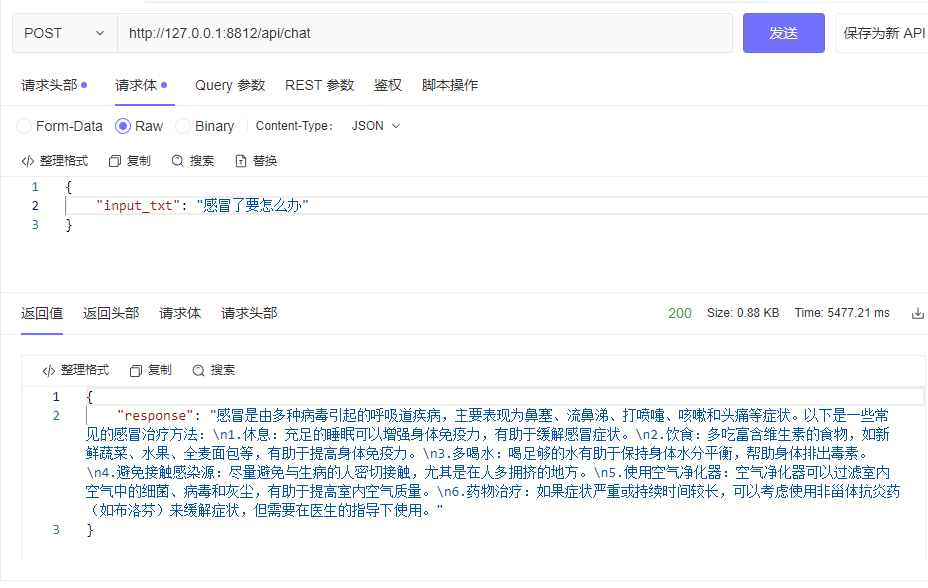
| └─tokenizer_config.jsonpython cli_demo.pypython api_demo.pyAPI call example:
curl --location ' 127.0.0.1:8812/api/chat '
--header ' Content-Type: application/json '
--header ' Authorization: Bearer Bearer '
--data ' {
"input_txt": "感冒了要怎么办"
} ' 
Here we take the triplet information in the text as an example to do downstream fine-tuning. For the traditional deep learning extraction method for this task, see the warehouse pytorch_IE_model. Extract all the triples in a piece of text, such as the sentence 《写生随笔》是冶金工业2006年出版的图书,作者是张来亮, extract the triples (写生随笔,作者,张来亮) and (写生随笔,出版社,冶金工业) .
The original data set is: Baidu triple extraction data set. Example of the processed fine-tuned data set format:
{
"prompt" : "请抽取出给定句子中的所有三元组。给定句子:《家乡的月亮》是宋雪莱演唱的一首歌曲,所属专辑是《久违的哥们》 " ,
"response" : " [(家乡的月亮,歌手,宋雪莱),(家乡的月亮,所属专辑,久违的哥们)] "
} You can directly use the sft_train.py script for fine-tuning. The script finetune_IE_task.ipynb contains the detailed decoding process. The training data set has about 17000 items, the learning rate 5e-5 , and the training epoch 5 . The dialogue capabilities of other tasks have not disappeared after fine-tuning.

Fine-tuning effect: Use the dev data set published百度三元组抽取数据集as the test set to compare with the traditional method pytorch_IE_model.
| Model | F1 score | Precision P | Recall R |
|---|---|---|---|
| ChatLM-Chinese-0.2B fine-tuning | 0.74 | 0.75 | 0.73 |
| ChatLM-Chinese-0.2B without pre-training | 0.51 | 0.53 | 0.49 |
| Traditional deep learning methods | 0.80 | 0.79 | 80.1 |
Note: ChatLM-Chinese-0.2B无预训练means directly initializing random parameters and starting training with a learning rate of 1e-4 . Other parameters are consistent with fine-tuning.
The model itself is not trained using a larger data set, nor is it fine-tuned for the instructions for answering multiple-choice questions. The C-Eval score is basically a baseline level and can be used as a reference if necessary. C-Eval evaluation code see: eval/c_eavl.ipynb
| category | correct | question_count | accuracy |
|---|---|---|---|
| Humanities | 63 | 257 | 24.51% |
| Other | 89 | 384 | 23.18% |
| STEM | 89 | 430 | 20.70% |
| Social Science | 72 | 275 | 26.18% |
If you think this project is helpful to you, please quote it.
@misc{Charent2023,
author={Charent Chen},
title={A small chinese chat language model with 0.2B parameters base on T5},
year={2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/charent/ChatLM-mini-Chinese}},
}
This project does not bear the risks and responsibilities of data security and public opinion risks caused by open source models and codes, or the risks and responsibilities arising from any model being misled, abused, disseminated, or improperly exploited.


