dialog eval
1.0.0
A lightweight repo for automatic evaluation of dialog models using 17 metrics.
? Choose which metrics you want to be computed
Evaluation can automatically run either on a response file or a directory containing multiple files
? Metrics are saved in a pre-defined easy to process format
Run this command to install required packages:
pip install -r requirements.txt
The main file can be called from anywhere, but when specifying paths to directories you should give them from the root of the repository.
python code/main.py -h
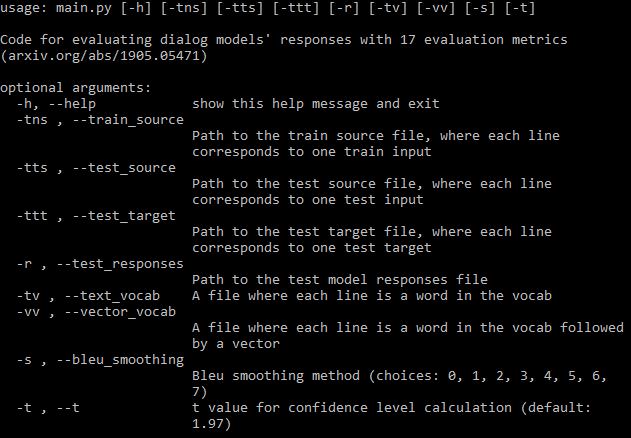
For the complete documentation visit the wiki.
You should provide as many of the argument paths required (image above) as possible. If you miss some the program will still run, but it will not compute some metrics which require those files (it will print these metrics). If you have a training data file the program can automatically generate a vocabulary and download fastText embeddings.
If you don't want to compute all the metrics you can set which metrics should be computed in the config file very easily.
A file will be saved to the directory where the response file(s) is. The first row contains the names of the metrics, then each row contains the metrics for one file. The name of the file is followed by the individual metric values separated by spaces. Each metric consists of three numbers separated by commas: the mean, standard deviation, and confidence interval. You can set the t value of the confidence interval in the arguments, the default is for 95% confidence.
Interestingly all 17 metrics improve until a certain point and then stagnate with no overfitting occuring during the training of a Transformer model on DailyDialog. Check the appendix of the paper for figures.
TRF is the Transformer model evaluated at the validation loss minimum and TRF-O is the Transformer model evaluated after 150 epochs of training, where the metrics start stagnating. RT means randomly selected responses from the training set and GT means ground truth responses.

TRF is the Transformer model, while RT means randomly selected responses from the training set and GT means ground truth responses. These results are on measured on the test set at a checkpoint where the validation loss was minimal.

TRF is the Transformer model, while RT means randomly selected responses from the training set and GT means ground truth responses. These results are on measured on the test set at a checkpoint where the validation loss was minimal.
New metrics can be added by making a class for the metric, which handles the computation of the metric given data. Check BLEU metrics for an example. Normally the init function handles any data setup which is needed later, and the update_metrics updates the metrics dict using the current example from the arguments. Inside the class you should define the self.metrics dict, which stores lists of metric values for a given test file. The names of these metrics (keys of the dictionary) should also be added in the config file to self.metrics. Finally you need to add an instance of your metric class to self.objects. Here at initialization you can make use of paths to data files if your metric requires any setup. After this your metric should be automatically computed and saved.
However, you should also add some constraints to your metric, e.g. if a file required for the computation of the metric is missing the user should be notified, as here.
This project is licensed under the MIT License - see the LICENSE file for details.
Please include a link to this repo if you use it in your work and consider citing the following paper:
@inproceedings{Csaky:2019,
title = "Improving Neural Conversational Models with Entropy-Based Data Filtering",
author = "Cs{'a}ky, Rich{'a}rd and Purgai, Patrik and Recski, G{'a}bor",
booktitle = "Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics",
month = jul,
year = "2019",
address = "Florence, Italy",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/P19-1567",
pages = "5650--5669",
}


