MiniGPT 3D
1.0.0
Yuan Tang Xu Han Xianzhi Li* Qiao Yu Yixue Hao Long Hu Min Chen
Huazhong University of Science and Technology South China University of Technology
ACM MM 2024
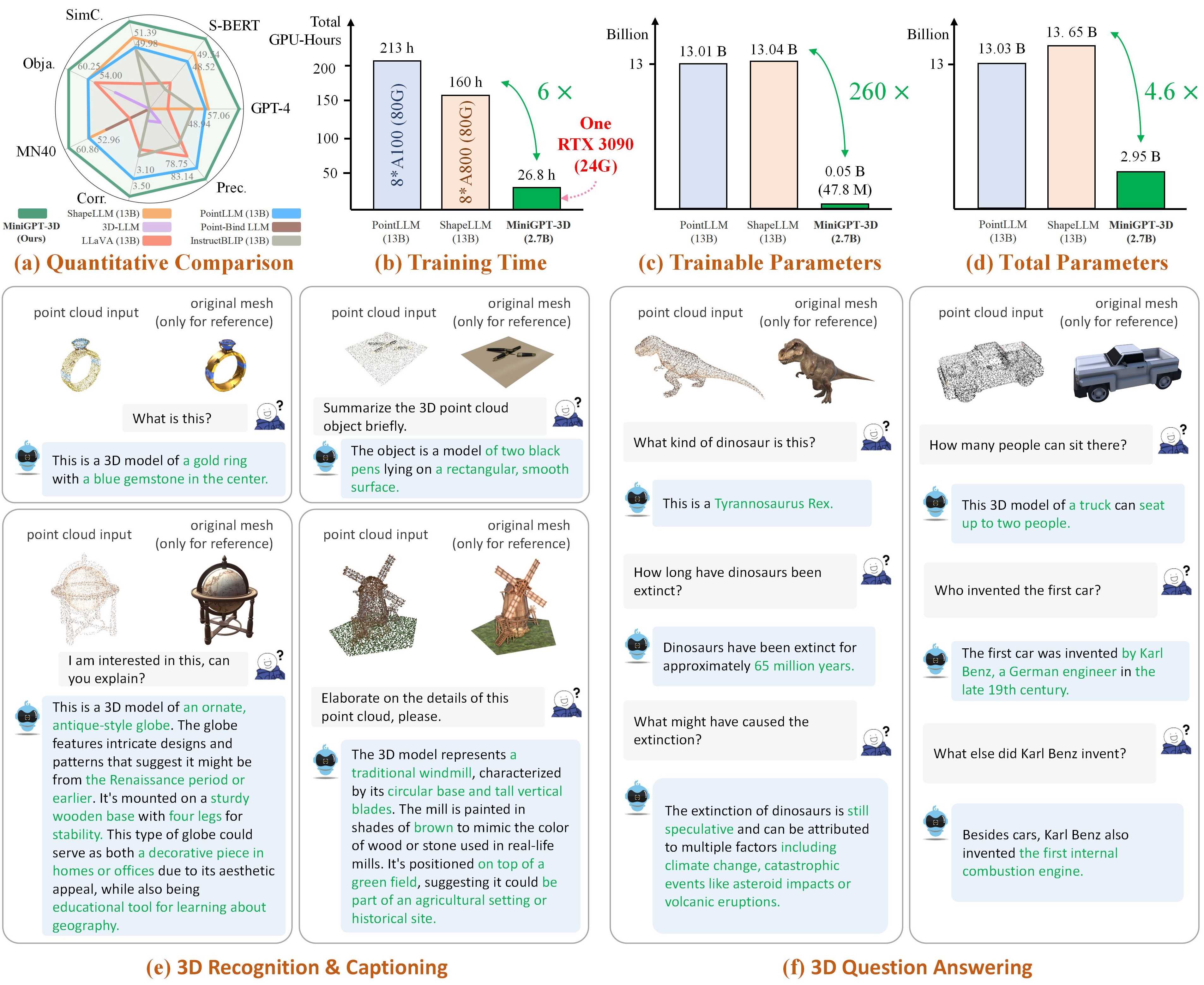

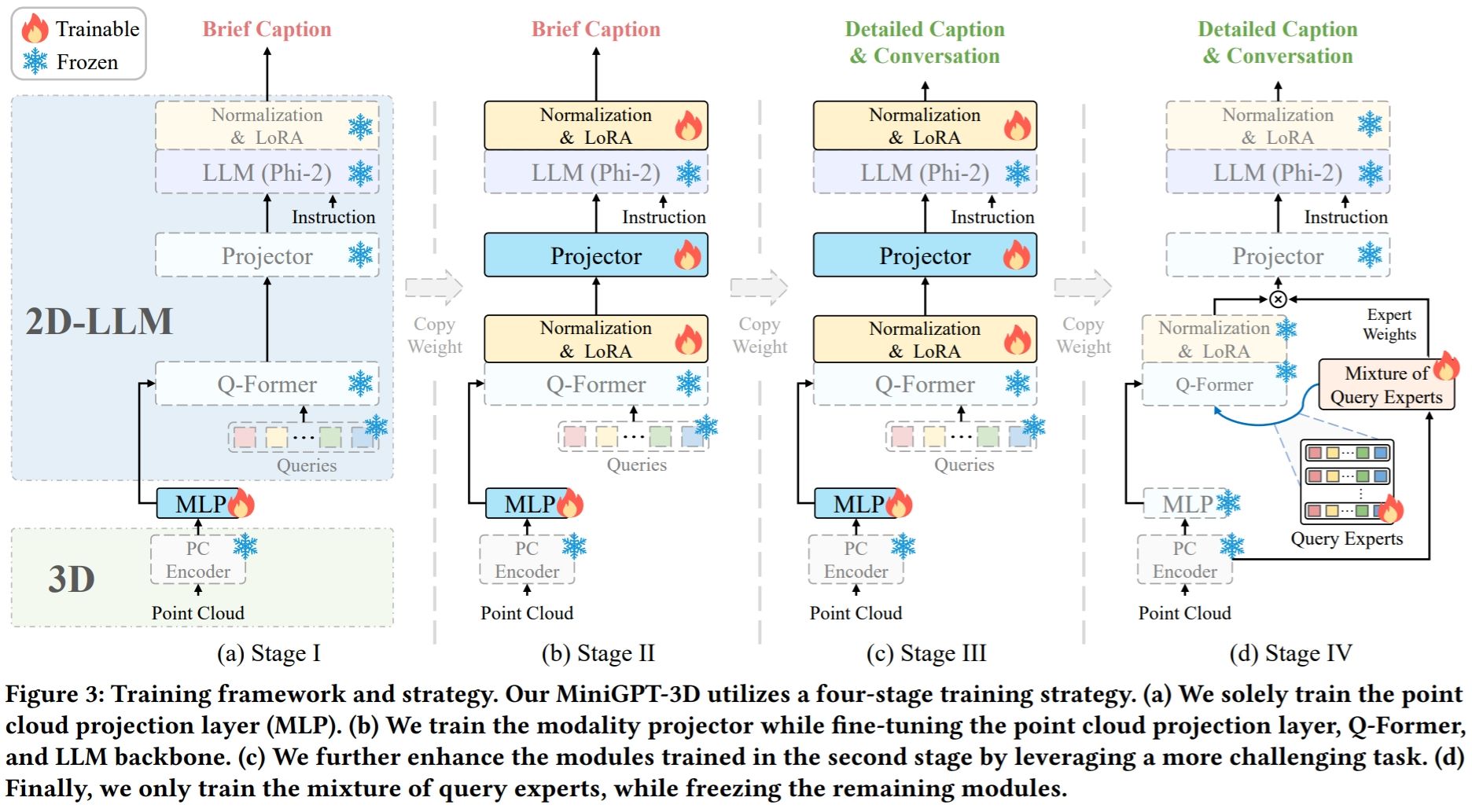
Note: MiniGPT-3D takes the first step in efficient 3D-LLM, we hope that MiniGPT-3D can bring new insights to this community.
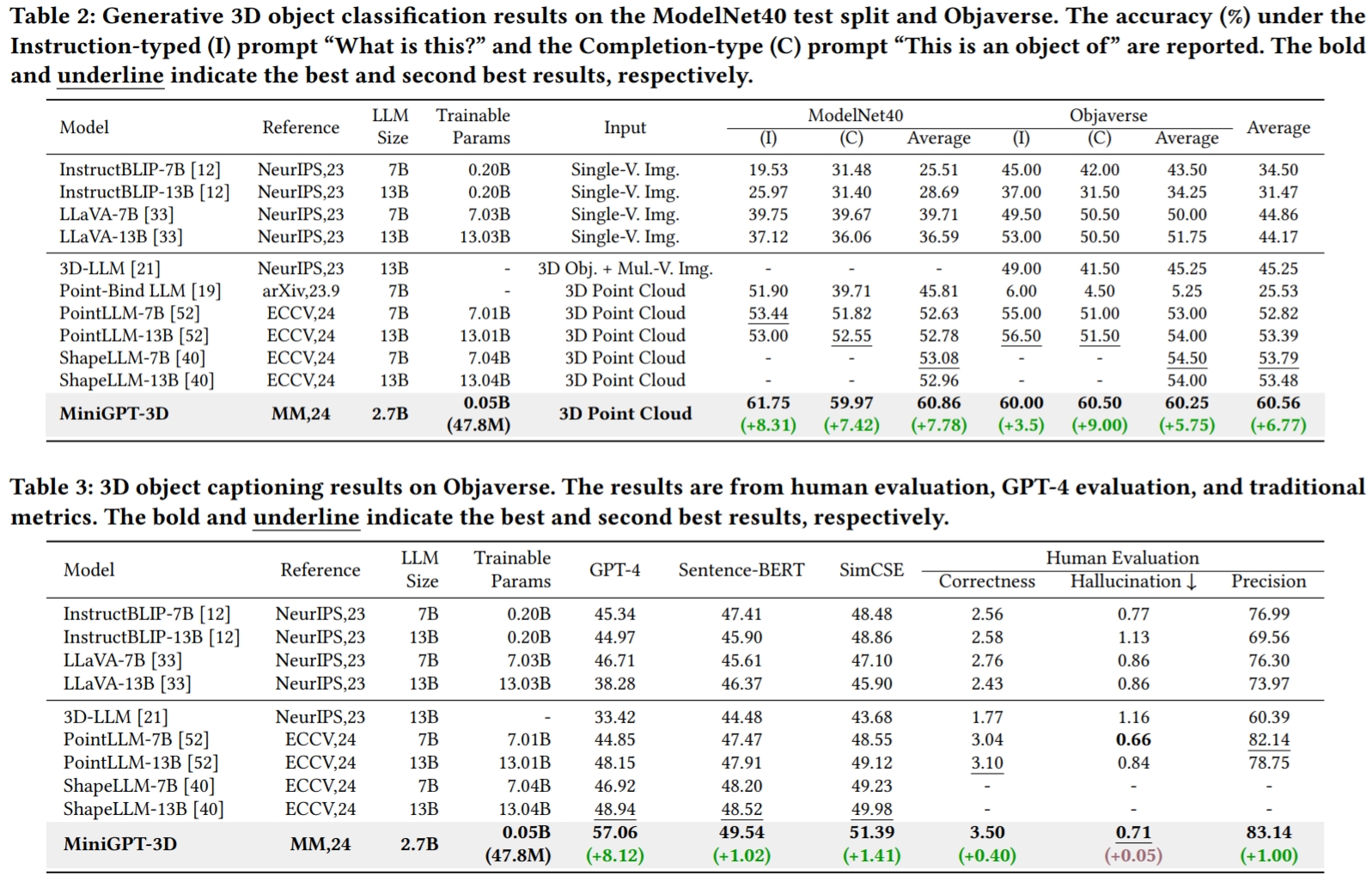
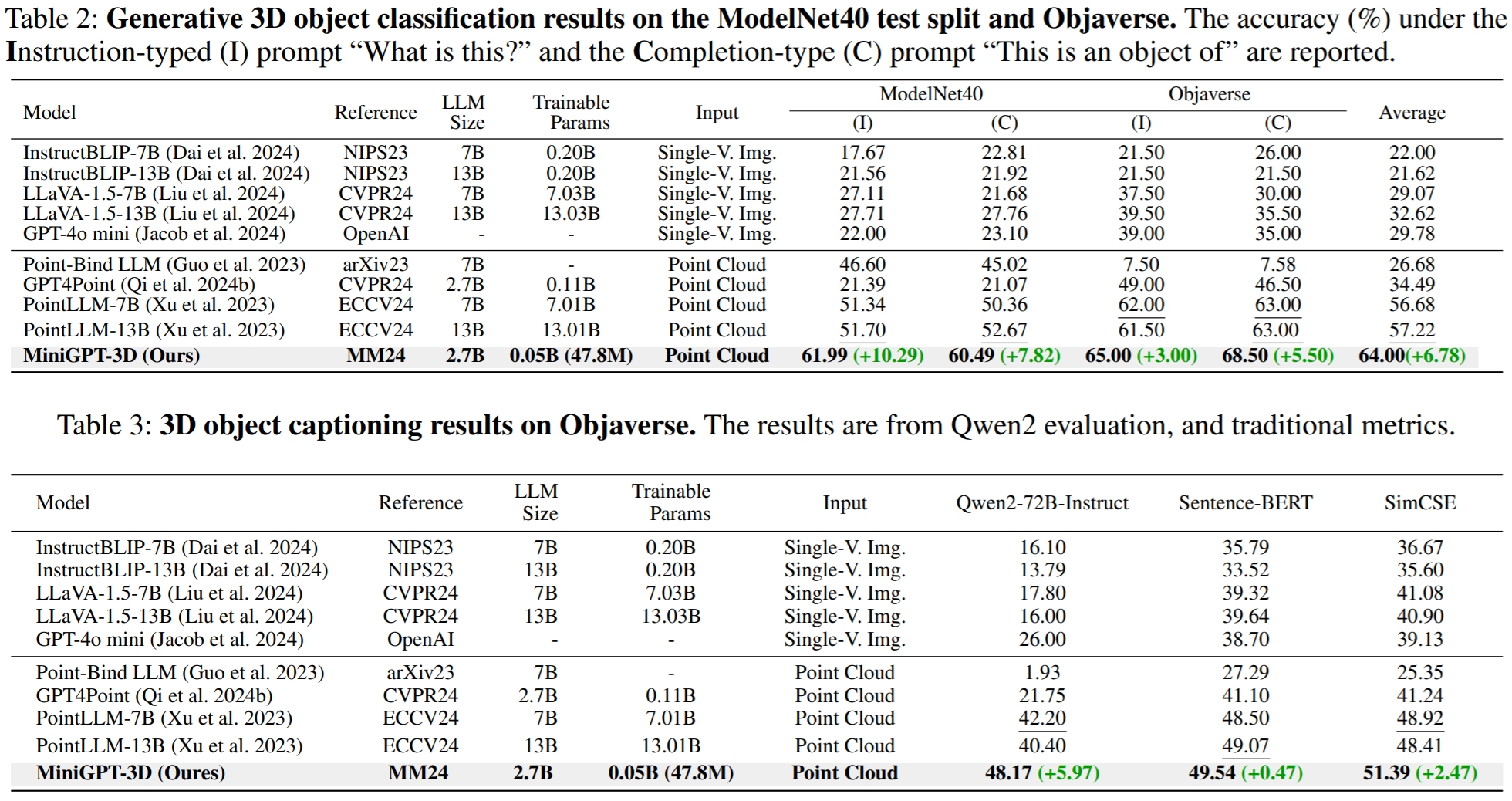
The results refer from GreenPLM.

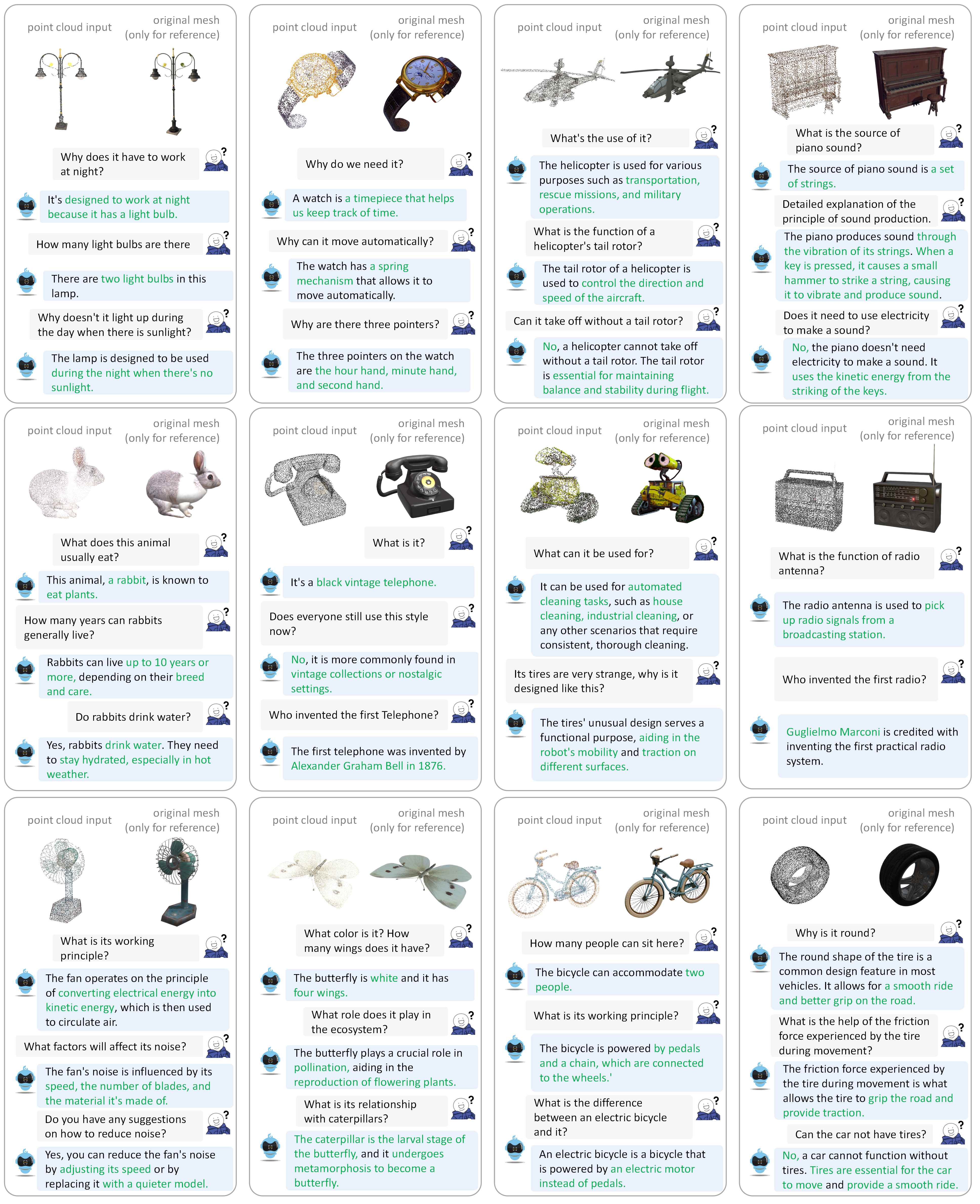
Please refer to our paper for more dialogue examples.
We test our codes under the following environment:
To start:
Clone this repository.
git clone https://github.com/TangYuan96/MiniGPT-3D.git
cd MiniGPT-3DInstall packages
By default, you have installed conda.
conda env create -f environment.yml
conda activate minigpt_3d
bash env_install.sh8192_npy containing 660K point cloud files named {Objaverse_ID}_8192.npy. Each file is a numpy array with dimensions (8192, 6), where the first three dimensions are xyz and the last three dimensions are rgb in [0, 1] range.
cat Objaverse_660K_8192_npy_split_a* > Objaverse_660K_8192_npy.tar.gz
tar -xvf Objaverse_660K_8192_npy.tar.gz8192_npy folder to ./data/objaverse_data folder../data/anno_data folder.modelnet40_test_8192pts_fps.dat to ./data/modelnet40_data folder.Finally, the overall data directory structure should be:
MiniGPT-3D/data
|-- anno_data
| |-- PointLLM_brief_description_660K.json
| |-- PointLLM_brief_description_660K_filtered.json
| |-- PointLLM_brief_description_val_200_GT.json
| |-- PointLLM_complex_instruction_70K.json
| |-- object_ids_660K.txt
| `-- val_object_ids_3000.txt
|-- modelnet40_data
| |-- modelnet40_test_8192pts_fps.dat
|-- objaverse_data
| |-- 00000054c36d44a2a483bdbff31d8edf_8192.npy
| |-- 00001ec0d78549e1b8c2083a06105c29_8192.npy
| .......
We sort out the model weights required by MiniGPT-3D during training and inference.
params_weight folder to MiniGPT-3D project folder.Finally, the overall data directory structure should be:
MiniGPT-3D
|-- params_weight
| |-- MiniGPT_3D_stage_3 # Our MiniGPT-3D stage III weight, needed to verify the results of paper
| |-- MiniGPT_3D_stage_4 # Our MiniGPT-3D stage IV weight, Needed to verify the results of paper
| |-- Phi_2 # LLM weight
| |-- TinyGPT_V_stage_3 # 2D-LLM weights including loRA & Norm of LLM and projector
| |-- all-mpnet-base-v2 # Used in the caption traditional evaluation
| |-- bert-base-uncased # Used in initialize Q-former
| |-- pc_encoder # point cloud encoder
| `-- sup-simcse-roberta-large # Used in the caption traditional evaluation
|-- train_configs
| `-- MiniGPT_3D
| .......
You can run the following command to start a local gradio conversation demo:
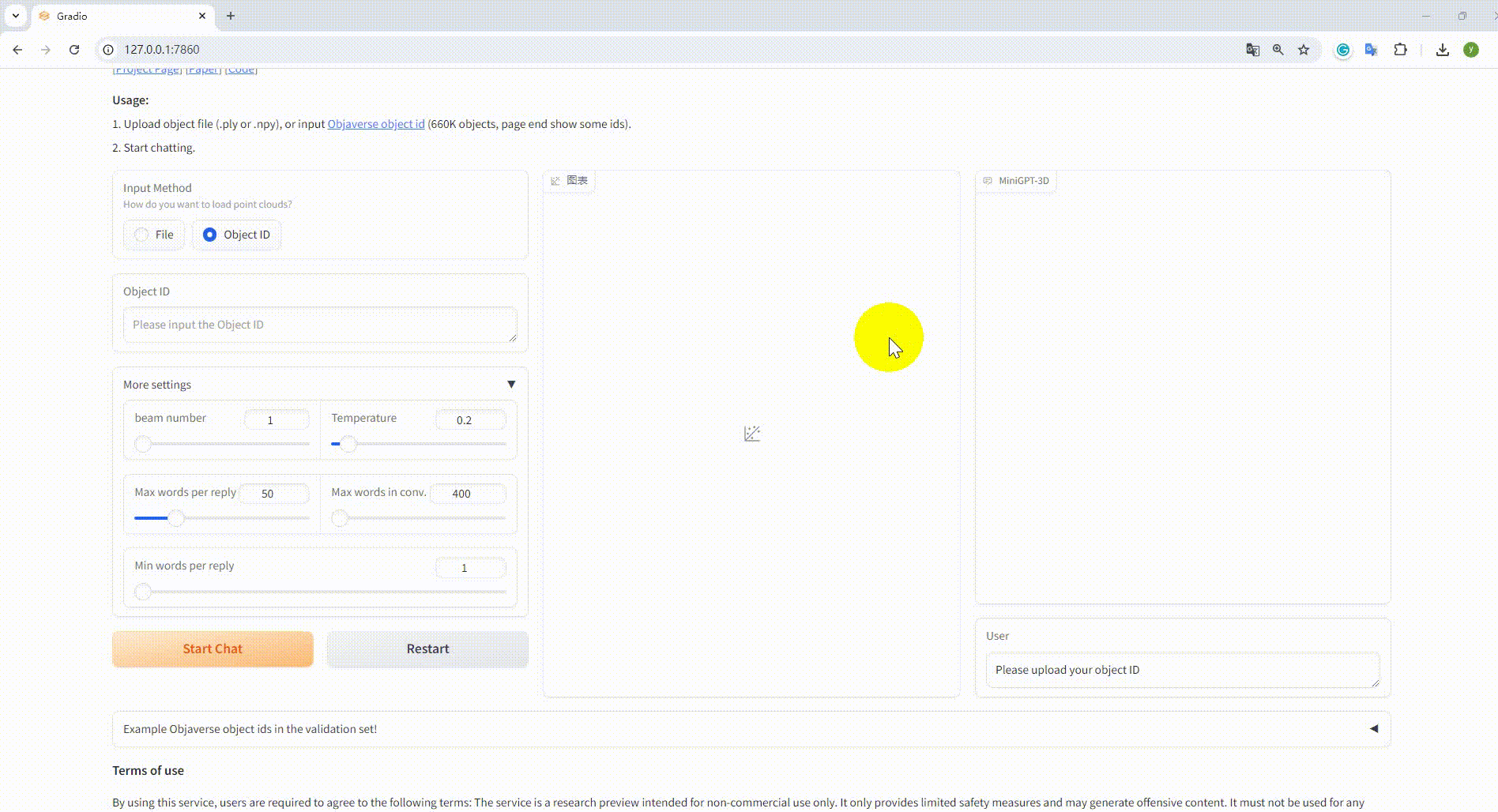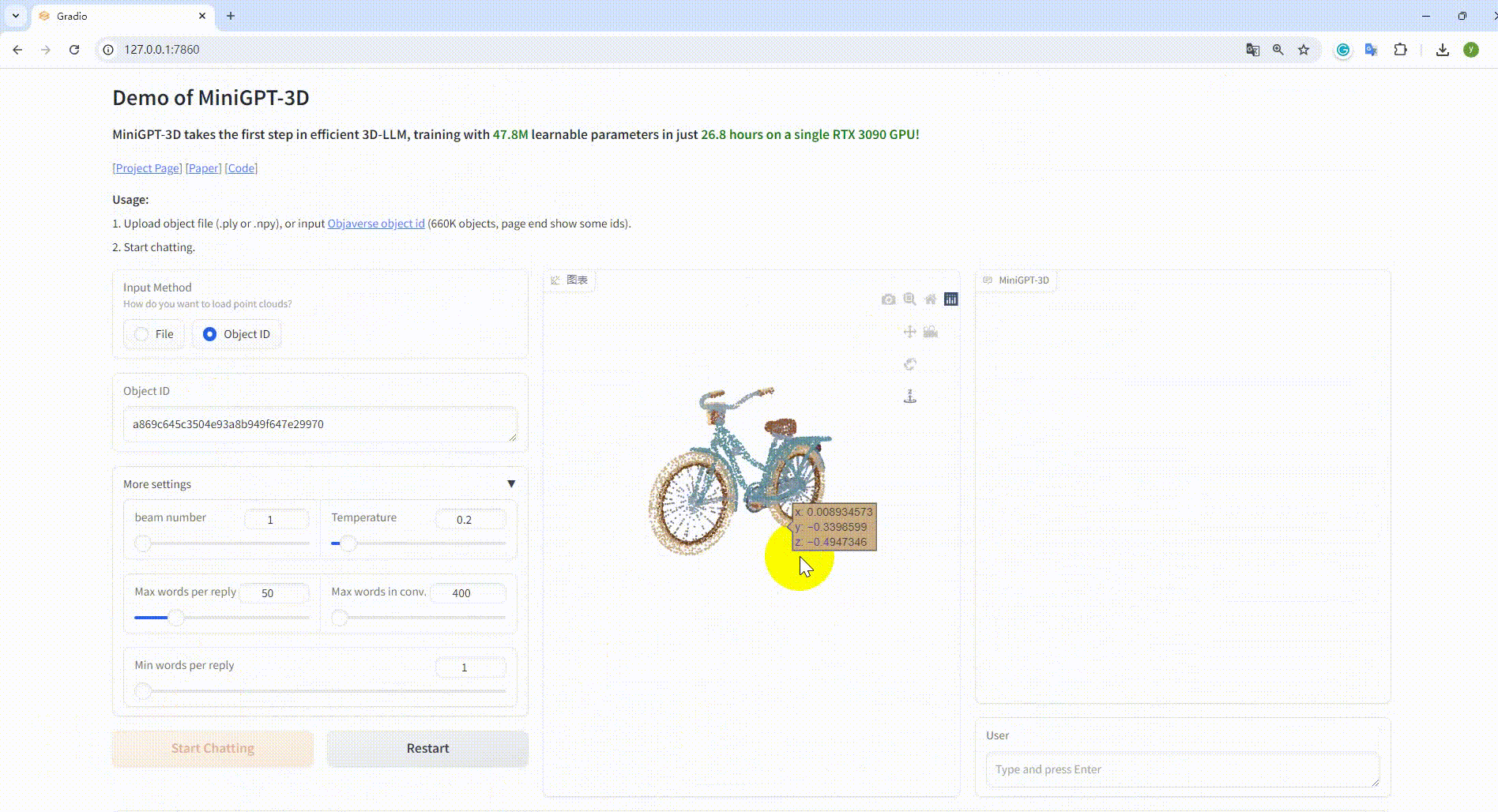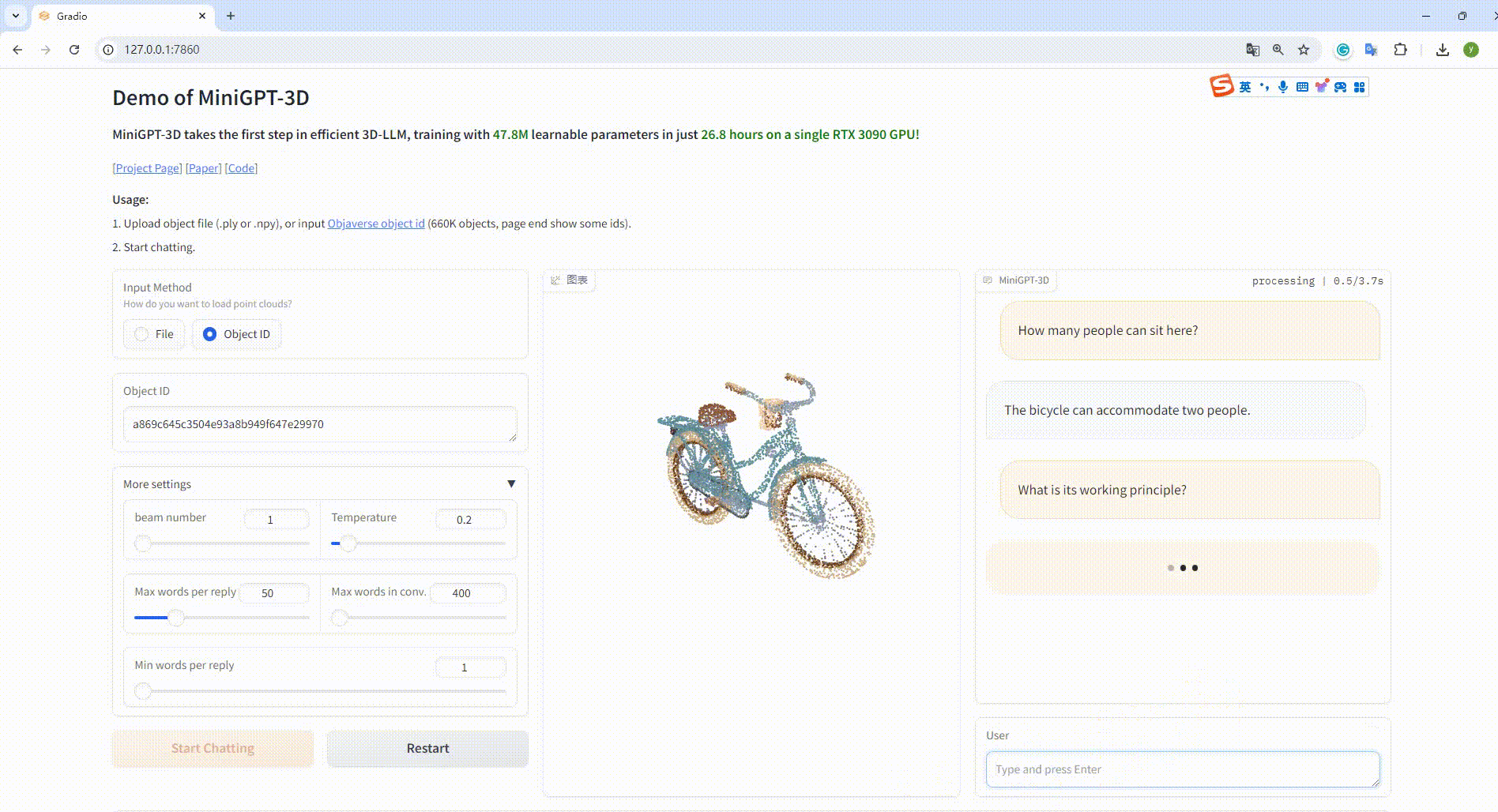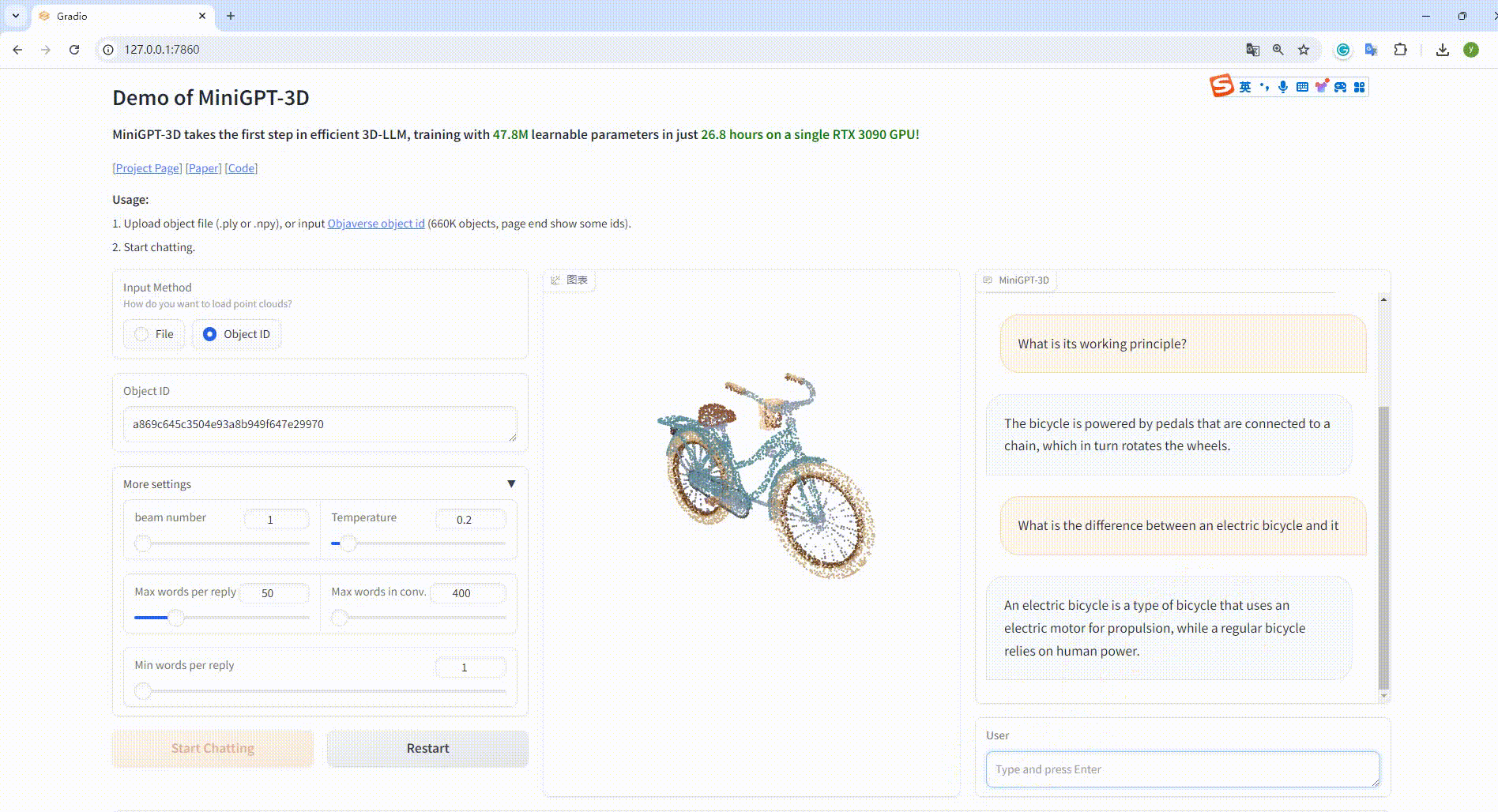
python UI_demo.py --cfg-path ./eval_configs/MiniGPT_3D_conv_UI_demo.yaml --gpu-id 0Then, copy the link http://127.0.0.1:7860/ to your browser, you can input the supported Objaverse object id (660K objects) or upload one object file (.ply or .npy) to talk with our MiniGPT-3D.
Example: Input the object ID:
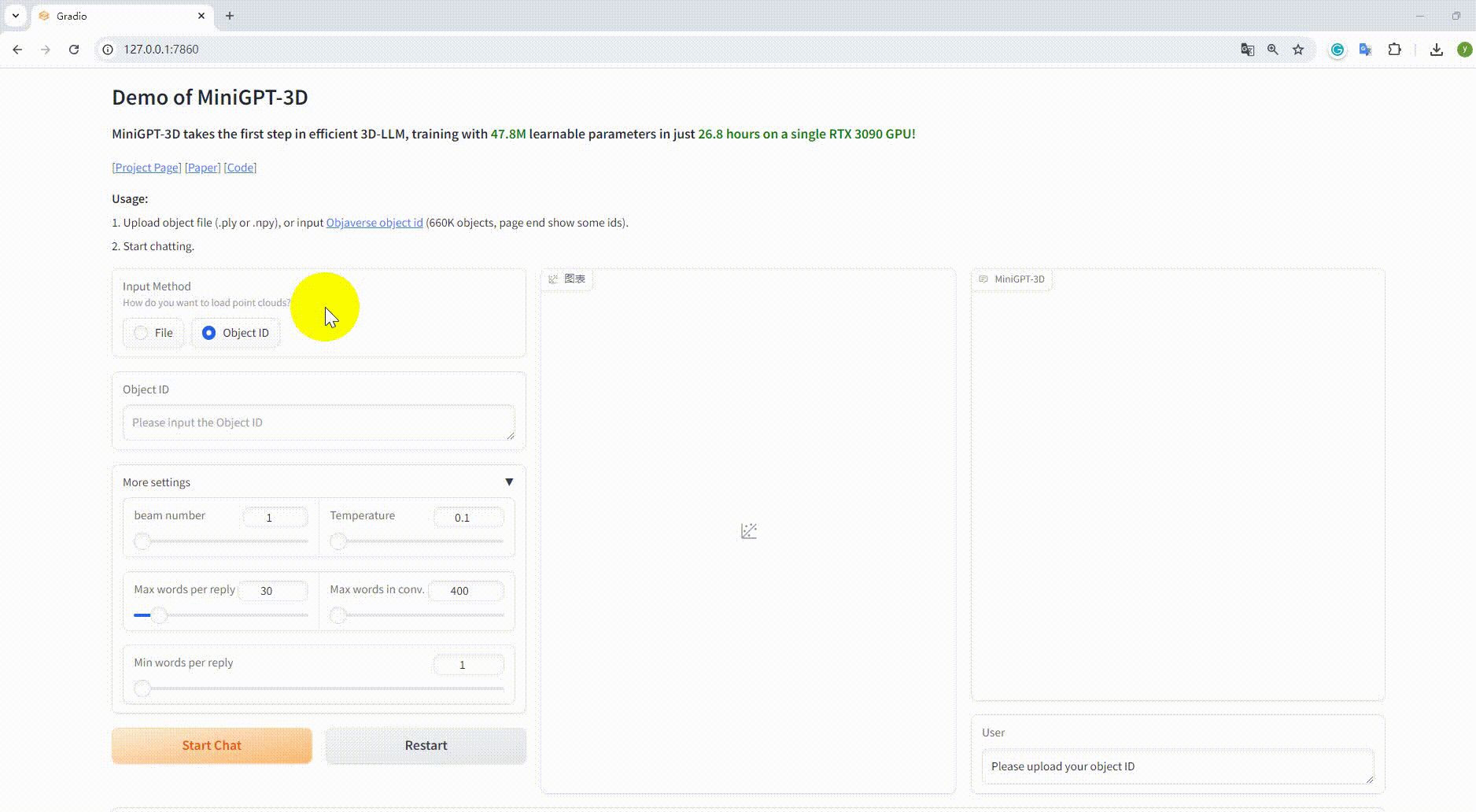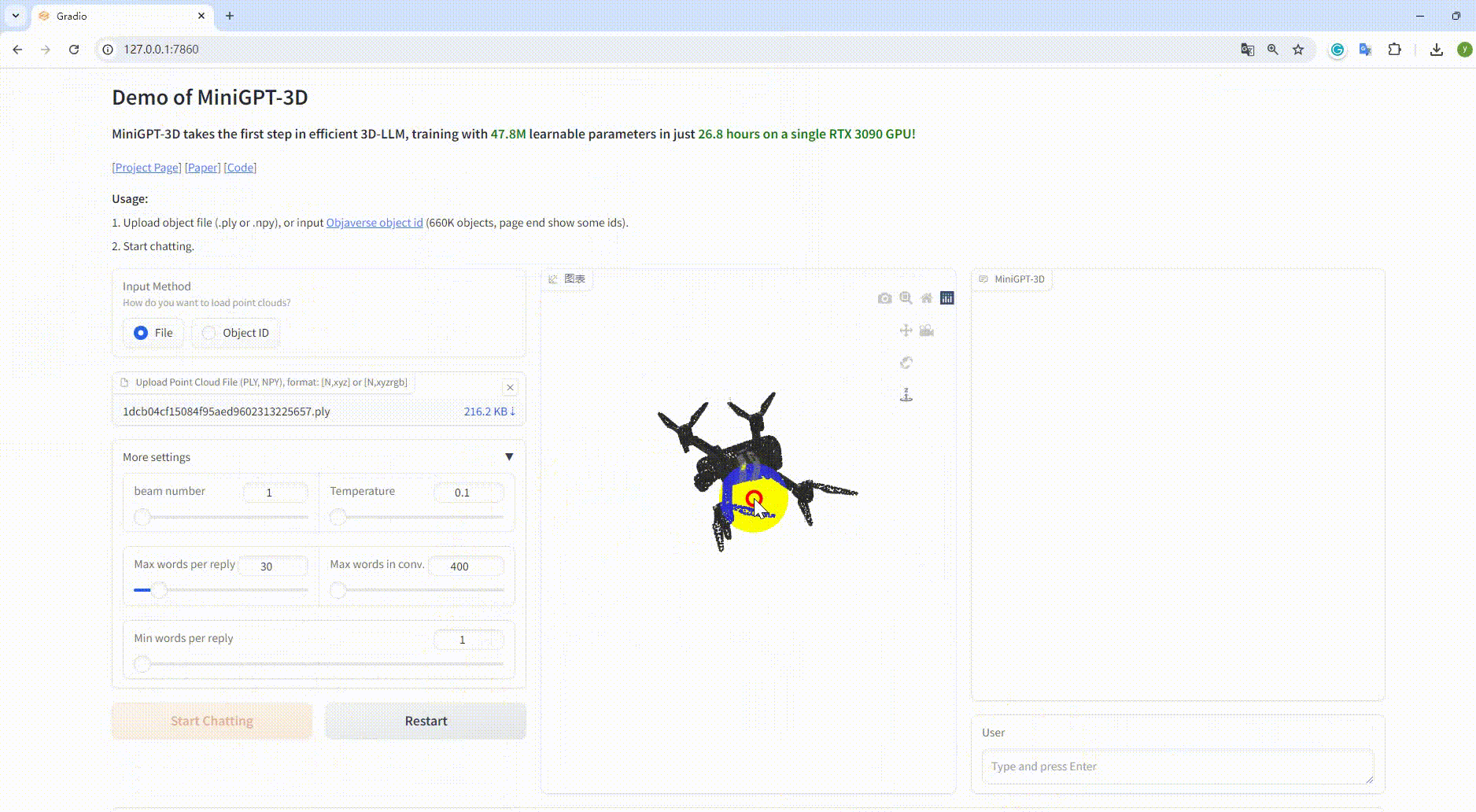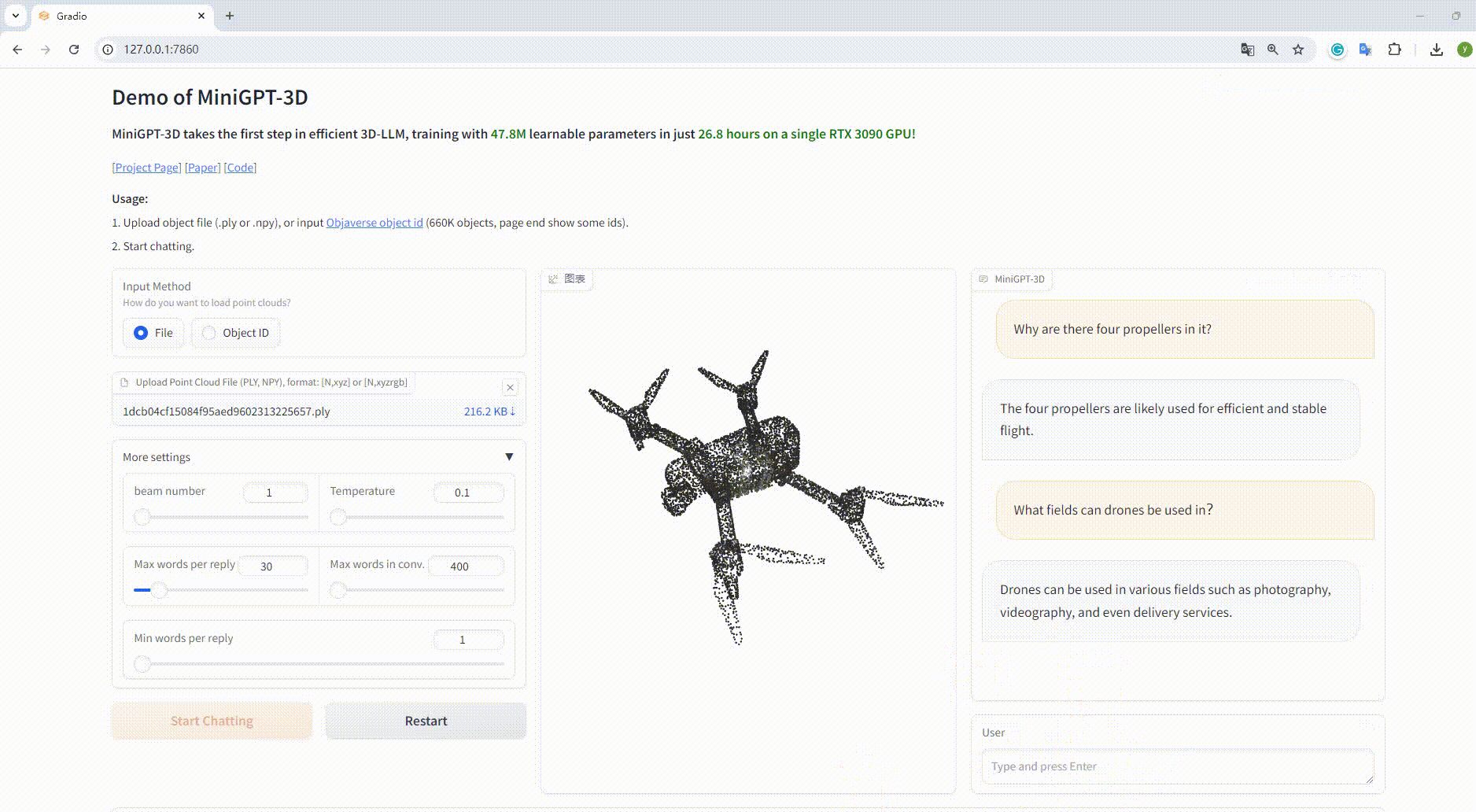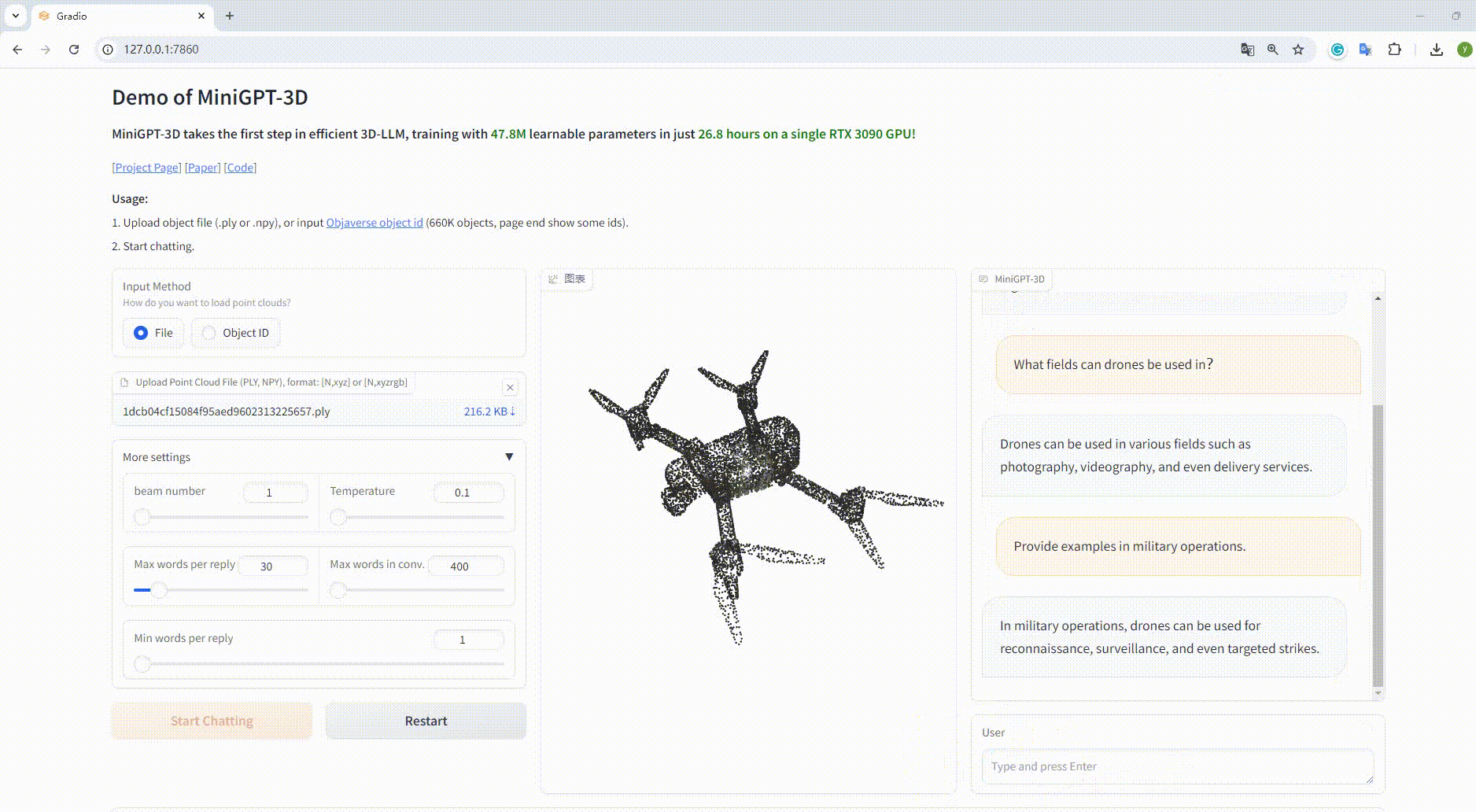
Example: Upload the object file:
If you want to use the default output path of each Stages, you can ignore the following steps.
CUDA_VISIBLE_DEVICES=0 python train.py --cfg-path ./train_configs/MiniGPT_3D/stage_1.yaml
CUDA_VISIBLE_DEVICES=0 python train.py --cfg-path ./train_configs/MiniGPT_3D/stage_2.yaml
CUDA_VISIBLE_DEVICES=0 python train.py --cfg-path ./train_configs/MiniGPT_3D/stage_3.yaml
CUDA_VISIBLE_DEVICES=0 python train.py --cfg-path ./train_configs/MiniGPT_3D/stage_4.yaml
If you just want to verify the results of our paper, you can ignore the following steps:
Set your the output path of Stage III to here at Line 8.
Set your the output path of Stage IV to here at Line 9.
Output the result of open vocabulary classification on objaverse
# Prompt 0:
export PYTHONPATH=$PWD
CUDA_VISIBLE_DEVICES=0 python pointllm/eval/eval_objaverse.py --out_path ./output/test --task_type classification --cfg-path ./eval_configs/benchmark_evaluation_paper.yaml --prompt_index 0 # Prompt 1:
export PYTHONPATH=$PWD
CUDA_VISIBLE_DEVICES=0 python pointllm/eval/eval_objaverse.py --out_path ./output/test --task_type classification --cfg-path ./eval_configs/benchmark_evaluation_paper.yaml --prompt_index 1Output the result of close-set zero-shot classification on ModelNet40
# Prompt 0:
export PYTHONPATH=$PWD
CUDA_VISIBLE_DEVICES=0 python pointllm/eval/eval_modelnet_cls.py --out_path ./output/test --cfg-path ./eval_configs/benchmark_evaluation_paper.yaml --prompt_index 0# Prompt 1:
export PYTHONPATH=$PWD
CUDA_VISIBLE_DEVICES=0 python pointllm/eval/eval_modelnet_cls.py --out_path ./output/test --cfg-path ./eval_configs/benchmark_evaluation_paper.yaml --prompt_index 1Output the result of object captioning on objaverse
export PYTHONPATH=$PWD
CUDA_VISIBLE_DEVICES=0 python pointllm/eval/eval_objaverse.py --out_path ./output/test --task_type captioning --cfg-path ./eval_configs/benchmark_evaluation_paper.yaml --prompt_index 2In GreenPLM, we have noticed that the close-source LLMs GPT-3.5 and GPT-4 have two major drawbacks: inconsistent API versions and high evaluation costs (~35 CNY or 5 USD per one evaluation). For instance, the GPT-3.5-turbo-0613 model used in PointLLM and our MiniGPT-3D is no longer maintained, making it difficult to replicate the results.
export PYTHONPATH=$PWD
export OPENAI_API_KEY=sk-****
python pointllm/eval/evaluator.py --results_path /path/to/evaluation/PointLLM_brief_description_val_200_GT_Objaverse_classification_prompt0.json --model_type gpt-4-0613 --eval_type open-free-form-classification --parallel --num_workers 15 export PYTHONPATH=$PWD
export OPENAI_API_KEY=sk-****
python pointllm/eval/evaluator.py --results_path /path/to/evaluation/PointLLM_brief_description_val_200_GT_Objaverse_classification_prompt1.json --model_type gpt-4-0613 --eval_type open-free-form-classification --parallel --num_workers 15 export PYTHONPATH=$PWD
export OPENAI_API_KEY=sk-****
python pointllm/eval/evaluator.py --results_path /path/to/evaluation/ModelNet_classification_prompt0.json --model_type gpt-3.5-turbo-0613 --eval_type modelnet-close-set-classification --parallel --num_workers 15 export PYTHONPATH=$PWD
export OPENAI_API_KEY=sk-****
python pointllm/eval/evaluator.py --results_path /path/to/evaluation/ModelNet_classification_prompt1.json --model_type gpt-3.5-turbo-0613 --eval_type modelnet-close-set-classification --parallel --num_workers 15export PYTHONPATH=$PWD
export OPENAI_API_KEY=sk-****
python pointllm/eval/evaluator.py --results_path /path/to/evaluation/PointLLM_brief_description_val_200_GT_Objaverse_captioning_prompt2.json --model_type gpt-4-0613 --eval_type object-captioning --parallel --num_workers 15In GreenPLM, we propose new 3D object classification and caption benchmarks using GPT-4 level open-source Qwen2-72B-Instruct to make evaluations cost-effective and results consistently reproducible.
export PYTHONPATH=$PWD
export DASHSCOPE_API_KEY=sk-xxx
python ./pointllm/eval/evaluator_opensource_llm_QwenAPI.py
--results_path /path/to/evaluation/PointLLM_brief_description_val_200_GT_Objaverse_classification_prompt0.json
--eval_type open-free-form-classification
--model_type qwen2-72b-instruct
--parallel --num_workers 4export PYTHONPATH=$PWD
export DASHSCOPE_API_KEY=sk-xxx
python ./pointllm/eval/evaluator_opensource_llm_QwenAPI.py
--results_path /path/to/evaluation/PointLLM_brief_description_val_200_GT_Objaverse_classification_prompt1.json
--eval_type open-free-form-classification
--model_type qwen2-72b-instruct
--parallel --num_workers 4export PYTHONPATH=$PWD
export DASHSCOPE_API_KEY=sk-xxx
python ./pointllm/eval/evaluator_opensource_llm_QwenAPI.py
--results_path /path/to/evaluation/ModelNet_classification_prompt0.json
--eval_type modelnet-close-set-classification
--model_type qwen2-72b-instruct
--parallel --num_workers 4export PYTHONPATH=$PWD
export DASHSCOPE_API_KEY=sk-xxx
python ./pointllm/eval/evaluator_opensource_llm_QwenAPI.py
--results_path /path/to/evaluation/ModelNet_classification_prompt1.json
--eval_type modelnet-close-set-classification
--model_type qwen2-72b-instruct
--parallel --num_workers 4export PYTHONPATH=$PWD
export DASHSCOPE_API_KEY=sk-xxx
python ./pointllm/eval/evaluator_opensource_llm_QwenAPI.py
--results_path /path/to/evaluation/PointLLM_brief_description_val_200_GT_Objaverse_captioning_prompt2.json
--eval_type object-captioning
--model_type qwen2-72b-instruct
--parallel --num_workers 4For the object captioning task, run the following command to evaluate model outputs with traditional metrics Sentence-BERT and SimCSE.
CUDA_VISIBLE_DEVICES=0 python pointllm/eval/traditional_evaluator.py --results_path /path/to/evaluation/PointLLM_brief_description_val_200_GT_Objaverse_captioning_prompt2.jsonSet your the output path of Stage III here at Line 8.
Set your the output path of Stage IV here at Line 9.
You can run the following command to start a local gradio conversation demo:
python UI_demo.py --cfg-path ./eval_configs/MiniGPT_3D_conv_UI_demo.yaml --gpu-id 0If you find our work helpful, please consider citing:
@article{tang2024minigpt,
title={MiniGPT-3D: Efficiently Aligning 3D Point Clouds with Large Language Models using 2D Priors},
author={Tang, Yuan and Han, Xu and Li, Xianzhi and Yu, Qiao and Hao, Yixue and Hu, Long and Chen, Min},
journal={arXiv preprint arXiv:2405.01413},
year={2024}
}
This work is under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Together, Let's make LLM for 3D great!
We would like to thank the authors of PointLLM, TinyGPT-V, MiniGPT-4, and Octavius for their great works and repos.


