gutenberg dialog
1.0.0
Code for downloading and building your own version of the Gutenberg Dialog Dataset. Easily extendable with new languages. Try trained chatbots in various languages here: https://ricsinaruto.github.io/chatbot.html.
| Download link | Number of utterances | Average utterance length | Number of dialogues | Average dialogue length |
|---|---|---|---|---|
| English | 14 773 741 | 22.17 | 2 526 877 | 5.85 |
| German | 226 015 | 24.44 | 43 440 | 5.20 |
| Dutch | 129 471 | 24.26 | 23 541 | 5.50 |
| Spanish | 58 174 | 18.62 | 6 912 | 8.42 |
| Italian | 41 388 | 19.47 | 6 664 | 6.21 |
| Hungarian | 18 816 | 14.68 | 2 826 | 6.66 |
| Portuguese | 16 228 | 21.40 | 2 233 | 7.27 |
? Generate your own dataset by tuning parameters affecting the size-quality trade-off of the dataset
The modular interface makes it easy to extend the dataset to other languages
? You can easily exclude books manually when building the dataset
Run setup.py which installs required packages.
python setup.py
The main file should be called from the root of the repo. The command below runs the dataset building pipeline for the comma-separated languages given as argument. Currently English, German, Dutch, Spanish, Portuguese, Italian, and Hungarian are supported.
python code/main.py -l=en,de,nl,es,pt,it,hu -a
All settable arguments can bee seen below:
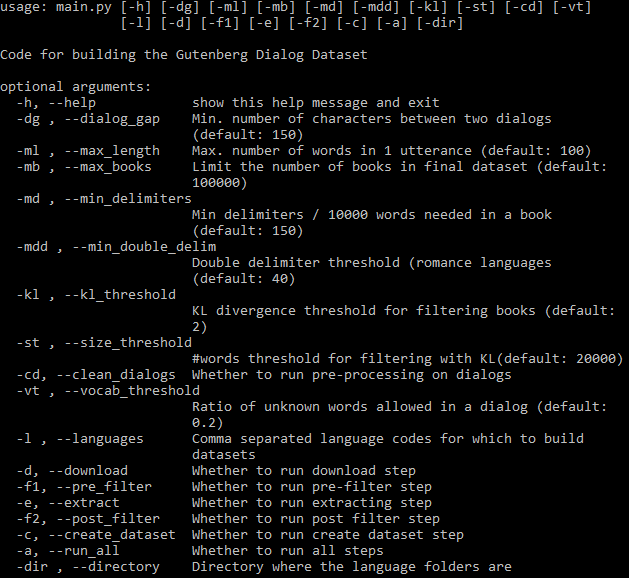
The -a flag controls whether to run the whole pipeline automatically. If -a is omitted a subset of steps have to be specified using flags (see help above). Once a step is finished its output can be used in subsequent steps and it only has run again if parameters or code related to that step is changed. All steps run separately for each language.
Download books for given languages.
Note: if all books fail to download with the error "Could not download book", a likely cause is that the default mirror used by the gutenberg package has become inaccessible. In the event that this occurs, it is possible to use any of the alternate mirrors listed at https://www.gutenberg.org/MIRRORS.ALL via the GUTENBERG_MIRROR environment variable. For example:
export GUTENBERG_MIRROR="https://gutenberg.pglaf.org"
python code/main.py ...
Pre-filtering removes some old books and noise.
Dialogs are extracted from books. When extending the dataset to new languages (see section below), this is the step that can be modified, thus previous steps can be skipped once finished.
A second filtering step removing some dialogs based on vocabulary.
Putting together the final dataset and splitting into train/dev/test data. The final step creates the author_and_title.txt file in the output directory containing all books (plus titles and authors) used to extract the final dataset. Users can manually copy lines from this file to banned_books.txt corresponding to books which should not be allowed in the dataset. In subsequent runs of any steps, books in this file will not be taken into account.
The code can be easily extended to process other languages. A file named <language code>.py has to be created in the languages folder. Here a class should be defined named the upper-case language code (e.g. En for English), with LANG or any of the other subclasses as parent. With self.cfg config parameters can be accessed. Inside this class the 3 functions below have to be defined. Please see it.py for an example.
Languages statistics
This function should return a dictionary where the keys are potential delimiters. For each delimiter a function should be defined (values in dictionary), which takes as input a line and returns a number. This number can be for example the count of delimiters, a flag whether there is a delimiter in the line, etc. Usually a weighted count is advisable, depending on the importance of different delimiters. The values will be used to determine the delimiter that should be used in the respective book (passed to the function below), and for filtering books which contain a low amount of delimiters. en.py contains examples of multiple delimiters.
This function should extract the dialogs from a book and append them to self.dialogs, which is a list of dialogs, and each dialog is a list of consecutive utterances. paragraph_list contains the book as a list of consecutive paragraphs. delimiter is the most common delimiter in this file which should be used to extract dialogs.
This function is used for post-processing dialogs (e.g. remove certain characters). It takes as input an utterance. Please note that nltk word tokenization is run automatically.
This project is licensed under the MIT License - see the LICENSE file for details.
Please include a link to this repo if you use any of the dataset or code in your work and consider citing the following paper:
@inproceedings{Csaky:2021,
title = "The Gutenberg Dialogue Dataset",
author = "Cs{'a}ky, Rich{'a}rd and Recski, G{'a}bor",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics",
month = apr,
year = "2021",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/2004.12752",
}


