amazon bedrock rag
1.0.0
Retrieval-Augmented Generation (RAG) is the process of optimizing the output of a large language model, so it references an authoritative knowledge base outside of its training data sources before generating a response. Large Language Models (LLMs) are trained on vast volumes of data and use billions of parameters to generate original output for tasks like answering questions, translating languages, and completing sentences. RAG extends the already powerful capabilities of LLMs to specific domains or an organization's internal knowledge base, all without the need to retrain the model. It is a cost-effective approach to improving LLM output so it remains relevant, accurate, and useful in various contexts. Learn more about RAG here.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon via a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI. Using Amazon Bedrock, you can easily experiment with and evaluate top FMs for your use case, privately customize them with your data using techniques such as fine-tuning and RAG, and build agents that execute tasks using your enterprise systems and data sources. Since Amazon Bedrock is serverless, you don't have to manage any infrastructure, and you can securely integrate and deploy generative AI capabilities into your applications using the AWS services you are already familiar with.
Knowledge Bases for Amazon Bedrock is a fully managed capability that helps you implement the entire RAG workflow from ingestion to retrieval and prompt augmentation without having to build custom integrations to data sources and manage data flows. Session context management is built in, so your app can readily support multi-turn conversations.
As part of creating a knowledge base, you configure a data source and a vector store of your choice. A data source connector allows you to connect your proprietary data to a knowledge base. Once you’ve configured a data source connector, you can sync or keep your data up to date with your knowledge base and make your data available for querying. Amazon Bedrock first splits your documents or content into manageable chunks for efficient data retrieval. The chunks are then converted to embeddings and written to a vector index (vector representation of the data), while maintaining a mapping to the original document. The vector embeddings allow the texts to be mathematically compared for similarity.
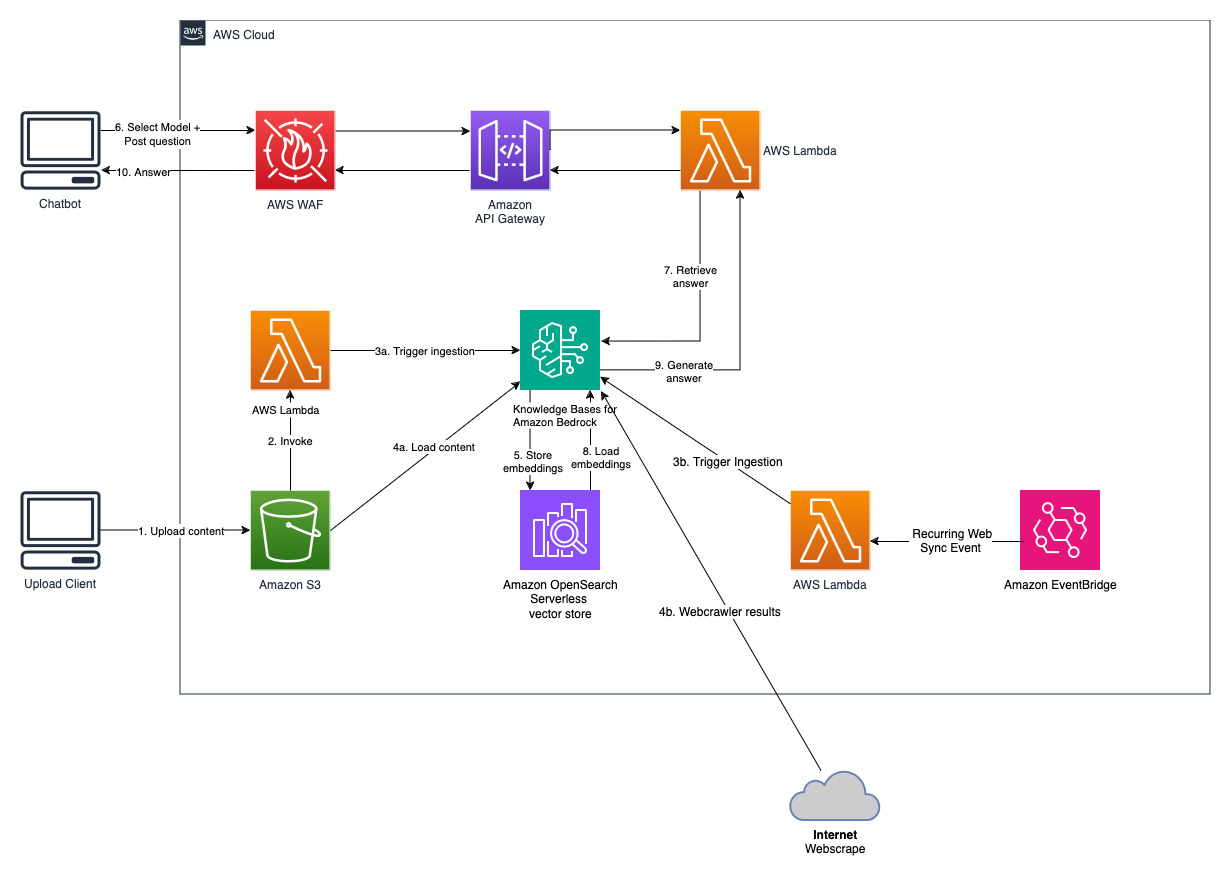
This project is implemented with two data sources; a data source for documents stored in Amazon S3 and another data source for content published on a website. A vector search collection is created in Amazon OpenSearch Serverless for vector storage.
Q&A Chatbot
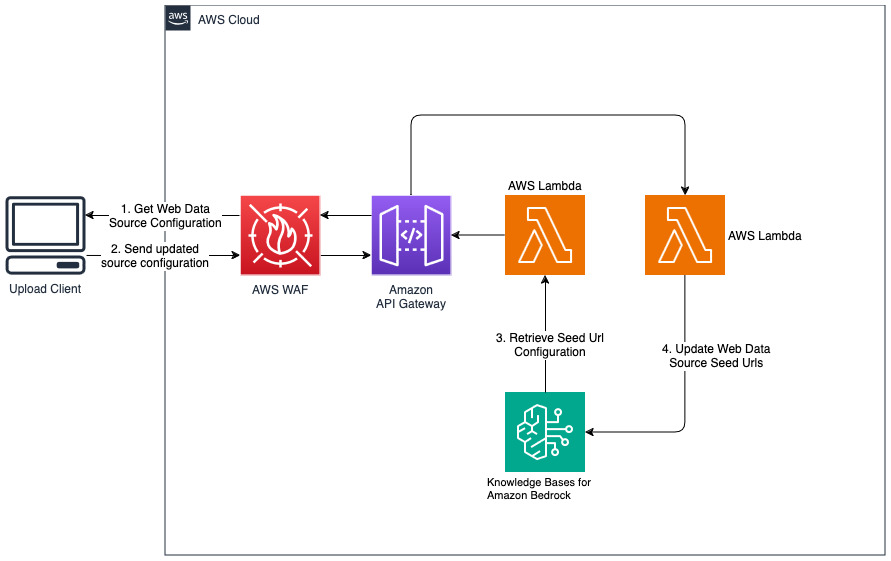
Add new websites for web datasource
cdk deploy --context allowedip="xxx.xxx.xxx.xxx/32"
Provide an client IP address that is allowed to access the API Gateway in CIDR format as part of the 'allowedip' context variable.
When the deployment completes,
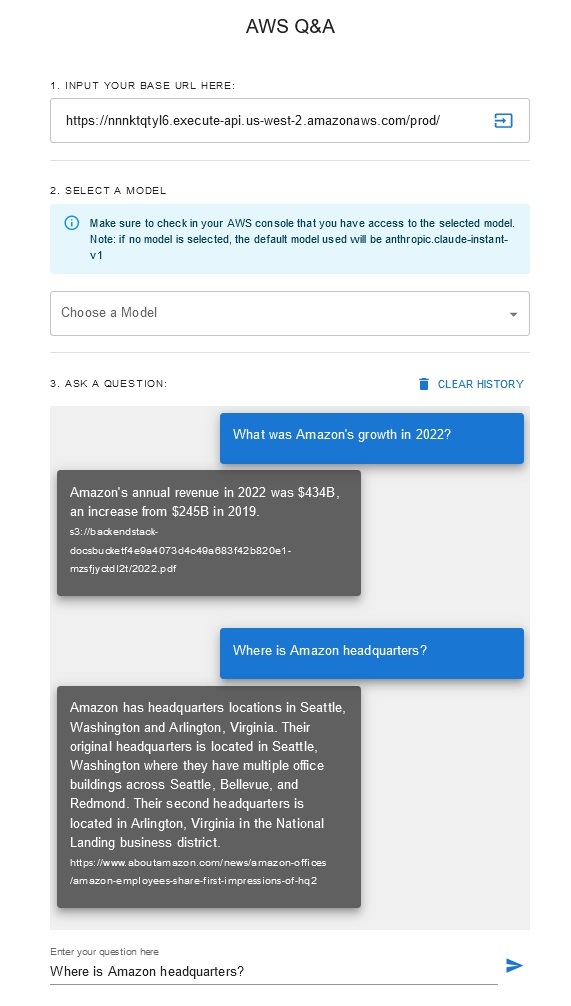
This solution allows users to select which foundational model they want to use during the retrieval and generation phase. The default model is Anthropic Claude Instant. For the knowledge base embedding model, this solution uses Amazon Titan Embeddings G1 - Text model. Make sure you have access to these foundation models.
Get a recent publicly available Amazon's annual report and copy it to the S3 bucket name noted previously. For a quick test, you can copy the Amazon's 2022 annual report using the AWS S3 Console. The content from the S3 bucket will be automatically synchronized with the knowledgebase because the solution deployment watches for new content in the S3 bucket and triggers an ingestion workflow.
The deployed solution initializes the web data source called "WebCrawlerDataSource" with the url https://www.aboutamazon.com/news/amazon-offices. You need to synchronize this Web Crawler data source with the knowledgebase from the AWS console manually to search against the website content because the website ingestion is scheduled to happen in the future time. Select this data source from the Knowledge based on Amazon Bedrock console and initiate a "Sync" operation. See Sync your data source with your Amazon Bedrock knowledge base for details. Note that the website content will be available to the Q&A chatbot only after the synchronization is completed. Please use this guidance when setting up websites as a datasource.
Use "cdk destroy" to delete the stack of cloud resources created in this solution deployment.


