DeepMorphy
1.0.0
DeepMorphy is a neural network based morphological analyzer for Russian language.
DeepMorphy is a morphological analyzer for the Russian language. Available as .Net Standard 2.0 library. Can:
The terminology in DeepMorphy is partially borrowed from the pymorphy2 morphological analyzer.
Grammeme (English grammeme) - the meaning of one of the grammatical categories of a word (for example, past tense, singular, masculine).
A grammatical category is a set of mutually exclusive grammes that characterize some common feature (for example, gender, tense, case, etc.). A list of all categories and grammars supported in DeepMorphy is here.
Tag (English tag) - a set of grammes that characterize a given word (for example, a tag for the word hedgehog - noun, singular, nominative case, masculine).
Lemma (English lemma) is the normal form of a word.
Lemmatization (eng. lemmatization) - bringing a word to its normal form.
A lexeme is a set of all forms of one word.
The core element of DeepMorphy is the neural network. For most words, morphological analysis and lemmatization are performed by the network. Some types of words are processed by preprocessors.
There are 3 preprocessors:
The network was built and trained on the tensorflow framework. The Opencorpora dictionary serves as a dataset. Integrated into .Net via TensorFlowSharp.
The computation graph for word parsing in DeepMorphy consists of 11 “subnets”:
The problem of changing the form of words is solved by a 1 seq2seq network.
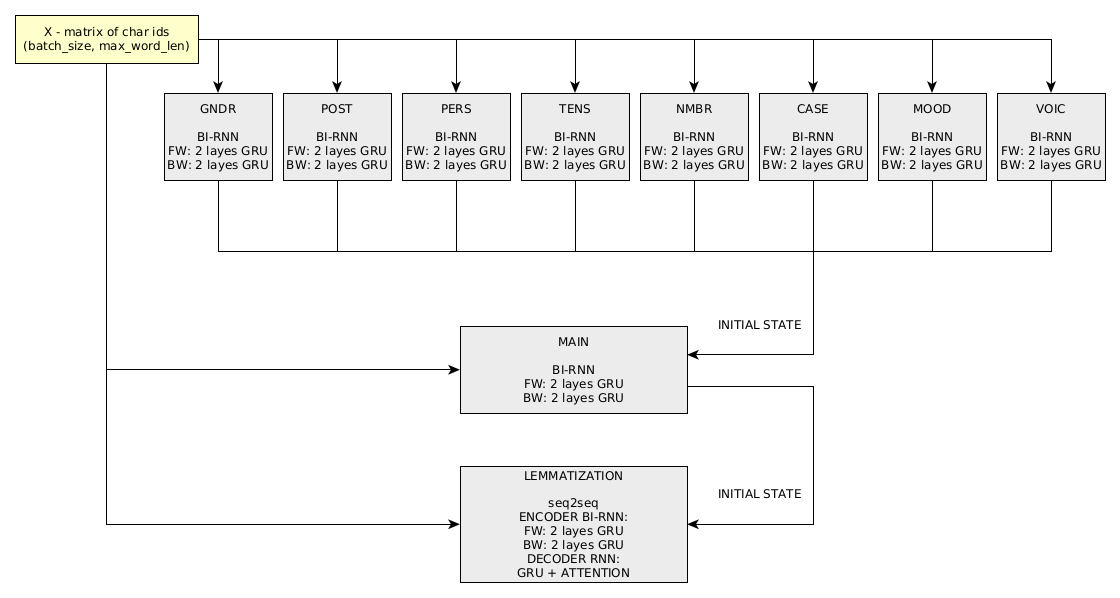
Training is carried out sequentially, first the networks are trained by category (the order does not matter). Next, the main classification by tags, lemmatization and a network for changing the form of words are trained. The training was carried out on 3 Titan X GPUs. Network performance metrics on the test dataset for the latest release can be viewed here.
DeepMorphy for .NET is a .Net Standard 2.0 library. The only dependencies are the TensorflowSharp library (the neural network is launched through it).
The library is published in Nuget, so it is easiest to install through it.
If there is a package manager:
Install-Package DeepMorphy
If the project supports PackageReference:
<PackageReference Include="DeepMorphy"/>
If someone wants to build from sources, then the C# sources are here. Rider is used for development (everything should be assembled in the studio without any problems).
All actions are carried out through the MorphAnalyzer class object:
var morph = new MorphAnalyzer ( ) ;Ideally, it is better to use it as a singleton; when creating an object, some time is spent loading dictionaries and the network. Thread safe. When creating, you can pass the following parameters to the constructor:
For parsing, the Parse method is used (it takes an IEnumerable with words for analysis as input, returns an IEnumerable with the result of the analysis).
var results = morph . Parse ( new string [ ]
{
"королёвские" ,
"тысячу" ,
"миллионных" ,
"красотка" ,
"1-ый"
} ) . ToArray ( ) ;
var morphInfo = results [ 0 ] ;The list of supported grammatical categories, grammes and their keys is here. If you need to find out the most probable combination of grammemes (tag), then you need to use the BestTag property of the MorphInfo object.
// выводим лучшую комбинацию граммем для слова
Console . WriteLine ( morphInfo . BestTag ) ;Based on the word itself, it is not always possible to unambiguously determine the meaning of its grammatical categories (see homonyms), so DeepMorphy allows you to view the top tags for a given word (Tags property).
// выводим все теги для слова + их вероятность
foreach ( var tag in morphInfo . Tags )
Console . WriteLine ( $ " { tag } : { tag . Power } " ) ;Is there a combination of grammes in any of the tags:
// есть ли в каком-нибудь из тегов прилагательные единственного числа
morphInfo . HasCombination ( "прил" , "ед" ) ;Is there a combination of grammes in the most likely tag:
// ясляется ли лучший тег прилагательным единственного числа
morphInfo . BestTag . Has ( "прил" , "ед" ) ;Retrieving specific grammar categories from the best tag:
// выводит часть речи лучшего тега и число
Console . WriteLine ( morphInfo . BestTag [ "чр" ] ) ;
Console . WriteLine ( morphInfo . BestTag [ "число" ] ) ;Tags are used when you need information about several grammatical categories at once (for example, part of speech and number). If you are only interested in one category, then you can use the interface to the probabilities of the meanings of grammatical categories of MorphInfo objects.
// выводит самую вероятную часть речи
Console . WriteLine ( morphInfo [ "чр" ] . BestGramKey ) ;You can also get the probability distribution by grammatical category:
// выводит распределение вероятностей для падежа
foreach ( var gram in morphInfo [ "падеж" ] . Grams )
{
Console . WriteLine ( $ " { gram . Key } : { gram . Power } " ) ;
}If, together with morphological analysis, you need to obtain lemmas of words, then the analyzer must be created as follows:
var morph = new MorphAnalyzer ( withLemmatization : true ) ;Lemmas can be obtained from word tags:
Console . WriteLine ( morphInfo . BestTag . Lemma ) ;Checking whether a given word has a lemma:
morphInfo . HasLemma ( "королевский" ) ;The CanBeSameLexeme method can be used to find words of a single lexeme:
// выводим все слова, которые могут быть формой слова королевский
var words = new string [ ]
{
"королевский" ,
"королевские" ,
"корабли" ,
"пересказывают" ,
"королевского"
} ;
var results = morph . Parse ( words ) . ToArray ( ) ;
var mainWord = results [ 0 ] ;
foreach ( var morphInfo in results )
{
if ( mainWord . CanBeSameLexeme ( morphInfo ) )
Console . WriteLine ( morphInfo . Text ) ;
}If you only need lemmatization without morphological parsing, then you need to use the Lemmatize method:
var tasks = new [ ]
{
new LemTask ( "синяя" , morph . TagHelper . CreateTag ( "прил" , gndr : "жен" , nmbr : "ед" , @case : "им" ) ) ,
new LemTask ( "гуляя" , morph . TagHelper . CreateTag ( "деепр" , tens : "наст" ) )
} ;
var lemmas = morph . Lemmatize ( tasks ) . ToArray ( ) ;
foreach ( var lemma in lemmas )
Console . WriteLine ( lemma ) ;DeepMorphy can change the form of a word within a lexeme; the list of supported inflections is here. Dictionary words can only be changed within those forms that are available in the dictionary. To change the form of words, the Inflect method is used; it takes as input an enumeration of InflectTask objects (contains the source word, the tag of the source word, and the tag in which the word should be placed). The output is an enumeration with the required forms (if the form could not be processed, then null).
var tasks = new [ ]
{
new InflectTask ( "синяя" ,
morph . TagHelper . CreateTag ( "прил" , gndr : "жен" , nmbr : "ед" , @case : "им" ) ,
morph . TagHelper . CreateTag ( "прил" , gndr : "муж" , nmbr : "ед" , @case : "им" ) ) ,
new InflectTask ( "гулять" ,
morph . TagHelper . CreateTag ( "инф_гл" ) ,
morph . TagHelper . CreateTag ( "деепр" , tens : "наст" ) )
} ;
var results = morph . Inflect ( tasks ) ;
foreach ( var result in results )
Console . WriteLine ( result ) ;It is also possible to get all its forms for a word using the Lexeme method (for dictionary words it returns everything from the dictionary, for others all forms from supported inflections).
var word = "лемматизировать" ;
var tag = m . TagHelper . CreateTag ( "инф_гл" ) ;
var results = m . Lexeme ( word , tag ) . ToArray ( ) ;One of the features of the algorithm is that when changing the form or generating a lexeme, the network can “invent” a non-existent (hypothetical) form of the word, a form that is not used in the language. For example, below you get the word “will run,” although at the moment it is not particularly used in the language.
var tasks = new [ ]
{
new InflectTask ( "победить" ,
m . TagHelper . CreateTag ( "инф_гл" ) ,
m . TagHelper . CreateTag ( "гл" , nmbr : "ед" , tens : "буд" , pers : "1л" , mood : "изъяв" ) )
} ;
Console . WriteLine ( m . Inflect ( tasks ) . First ( ) ) ; 


