Hibernate SpringBoot
1.0.0
| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
|
Hibernate & Spring Boot Samples
Description: This application is a sample of how to store date, time, and timestamps in UTC time zone. The second setting, useLegacyDatetimeCode is needed only for MySQL. Otherwise, set only hibernate.jdbc.time_zone.
Key points:
spring.jpa.properties.hibernate.jdbc.time_zone=UTCspring.datasource.url=jdbc:mysql://localhost:3306/screenshotdb?useLegacyDatetimeCode=falseDescription: View the prepared statement binding/extracted parameters via Log4J 2 logger setting.
Key points:
pom.xml, exclude Spring Boot's Default Loggingpom.xml, Add Log4j 2 Dependencylog4j2.xml add, <Logger name="org.hibernate.type.descriptor.sql" level="trace"/>Output example:

Description: View the query details (query type, binding parameters, batch size, execution time, etc) via DataSource-Proxy
Key points:
pom.xml the datasource-proxy dependencyDataSource beanDataSource bean via ProxyFactory and an implementation of MethodInterceptorOutput example:

saveAll(Iterable<S> entities) in MySQLDescription: Batch inserts via SimpleJpaRepository#saveAll(Iterable<S> entities) method in MySQL
Key points:
application.properties set spring.jpa.properties.hibernate.jdbc.batch_sizeapplication.properties set spring.jpa.properties.hibernate.generate_statistics (just to check that batching is working)application.properties set JDBC URL with rewriteBatchedStatements=true (optimization for MySQL)application.properties set JDBC URL with cachePrepStmts=true (enable caching and is useful if you decide to set prepStmtCacheSize, prepStmtCacheSqlLimit, etc as well; without this setting the cache is disabled)application.properties set JDBC URL with useServerPrepStmts=true (this way you switch to server-side prepared statements (may lead to signnificant performance boost))spring.jpa.properties.hibernate.order_inserts=true to optimize the batching by ordering insertsIDENTITY will cause insert batching to be disabled@Version property to avoid extra-SELECT statements fired before batching (also prevent lost updates in multi-request transactions). Extra-SELECT statements are the effect of using merge() instead of persist(); behind the scene, saveAll() uses save(), which in case of non-new entities (entities that have IDs) will call merge(), which instruct Hibernate to fire a SELECT statement to make sure that there is no record in the database having the same identifiersaveAll() to not "overwhelm" the Persistence Context; normally the EntityManager should be flushed and cleared from time to time, but during the saveAll() execution you simply cannot do that, so if in saveAll() there is a list with a high amount of data, all that data will hit the Persistence Context (1st Level Cache) and will remain in memory until the flush time; using relatively small amount of data should be ok (in this example, each batch of 30 entities run in a separate transaction and Persistent Context)saveAll() method return a List<S> containing the persisted entities; each persisted entity is added into this list; if you just don't need this List then it is created for nothingspring.jpa.properties.hibernate.cache.use_second_level_cache=falseDescription: This application is a sample of batching inserts via EntityManager in MySQL. This way you can easily control the flush() and clear() cycles of the Persistence Context (1st Level Cache) inside the current transaction. This is not possible via Spring Boot, saveAll(Iterable<S> entities), since this method executes a single flush per transaction. Another advantage is that you can call persist() instead of merge() - this is used behind the scene by the SpringBoot saveAll(Iterable<S> entities) and save(S entity).
If you want to execute a batch per transaction (recommended) then check this example.
Key points:
application.properties set spring.jpa.properties.hibernate.jdbc.batch_sizeapplication.properties set spring.jpa.properties.hibernate.generate_statistics (just to check that batching is working)application.properties set JDBC URL with rewriteBatchedStatements=true (optimization for MySQL)application.properties set JDBC URL with cachePrepStmts=true (enable caching and is useful if you decide to set prepStmtCacheSize, prepStmtCacheSqlLimit, etc as well; without this setting the cache is disabled)application.properties set JDBC URL with useServerPrepStmts=true (this way you switch to server-side prepared statements (may lead to signnificant performance boost))spring.jpa.properties.hibernate.order_inserts=true to optimize the batching by ordering insertsIDENTITY will cause insert batching to be disabledspring.jpa.properties.hibernate.cache.use_second_level_cache=falseOutput example:

Description: Batch inserts via JpaContext/EntityManager in MySQL.
Key points:
application.properties set spring.jpa.properties.hibernate.jdbc.batch_sizeapplication.properties set spring.jpa.properties.hibernate.generate_statistics (just to check that batching is working)application.properties set JDBC URL with rewriteBatchedStatements=true (optimization for MySQL)application.properties set JDBC URL with cachePrepStmts=true (enable caching and is useful if you decide to set prepStmtCacheSize, prepStmtCacheSqlLimit, etc as well; without this setting the cache is disabled)application.properties set JDBC URL with useServerPrepStmts=true (this way you switch to server-side prepared statements (may lead to signnificant performance boost))spring.jpa.properties.hibernate.order_inserts=true to optimize the batching by ordering insertsIDENTITY will cause insert batching to be disabledEntityManager is obtain per entity type via, JpaContext#getEntityManagerByManagedType(Class<?> entity)spring.jpa.properties.hibernate.cache.use_second_level_cache=falseOutput example:

Description: Batch inserts via Hibernate session-level batching (Hibernate 5.2 or higher) in MySQL.
Key points:
application.properties set spring.jpa.properties.hibernate.generate_statistics (just to check that batching is working)application.properties set JDBC URL with rewriteBatchedStatements=true (optimization for MySQL)application.properties set JDBC URL with cachePrepStmts=true (enable caching and is useful if you decide to set prepStmtCacheSize, prepStmtCacheSqlLimit, etc as well; without this setting the cache is disabled)application.properties set JDBC URL with useServerPrepStmts=true (this way you switch to server-side prepared statements (may lead to signnificant performance boost))spring.jpa.properties.hibernate.order_inserts=true to optimize the batching by ordering insertsIDENTITY will cause insert batching to be disabledSession is obtained by un-wrapping it via EntityManager#unwrap(Session.class)Session#setJdbcBatchSize(Integer size) and get via Session#getJdbcBatchSize()spring.jpa.properties.hibernate.cache.use_second_level_cache=falseOutput example:

findById(), JPA EntityManager And Hibernate SessionDescription: Direct fetching via Spring Data, EntityManager and Hibernate Session examples.
Key points:
findById()EntityManager uses find()Session uses get()Note: You may also like to read the recipe, "How To Enrich DTOs With Virtual Properties Via Spring Projections"
Description: Fetch only the needed data from the database via Spring Data Projections (DTO).
Key points:
List<projection>LIMIT)Note: Using projections is not limited to use query builder mechanism built into Spring Data repository infrastructure. We can fetch projections via JPQL or native queries as well. For example, in this application we use a JPQL.
Output example (select first 2 rows; select only "name" and "age"):

| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
|
Description: By default, the attributes of an entity are loaded eagerly (all at once). But, we can load them lazy as well. This is useful for column types that store large amounts of data: CLOB, BLOB, VARBINARY, etc or details that should be loaded on demand. In this application, we have an entity named Author. Its properties are: id, name, genre, avatar and age. And, we want to load the avatar lazy. So, the avatar should be loaded on demand.
Key points:
pom.xml, activate Hibernate bytecode enhancement (e.g. use Maven bytecode enhancement plugin)@Basic(fetch = FetchType.LAZY)application.properties, disable Open Session in ViewCheck as well:
- Default Values For Lazy Loaded Attributes
- Attribute Lazy Loading And Jackson Serialization
Description: A Hibernate proxy can be useful when a child entity can be persisted with a reference to its parent (@ManyToOne or @OneToOne association). In such cases, fetching the parent entity from the database (execute the SELECT statement) is a performance penalty and a pointless action, because Hibernate can set the underlying foreign key value for an uninitialized proxy.
Key points:
EntityManager#getReference()JpaRepository#getOne() -> used in this exampleload()Author and Book, involved in a unidirectional @ManyToOne association (Author is the parent-side)SELECT), we create a new book, we set the proxy as the author for this book and we save the book (this will trigger an INSERT in the book table)Output example:
INSERT is triggered, and no SELECTDescription: The N+1 is an issue of lazy fetching (but, eager is not exempt). This application reproduce the N+1 behavior.
Key points:
Author and Book in a lazy bidirectional @OneToMany associationBook lazy, so without Author (results in 1 query)Book collection and for each entry fetch the corresponding Author (results N queries)Author lazy, so without Book (results in 1 query)Author collection and for each entry fetch the corresponding Book (results N queries)Output example:
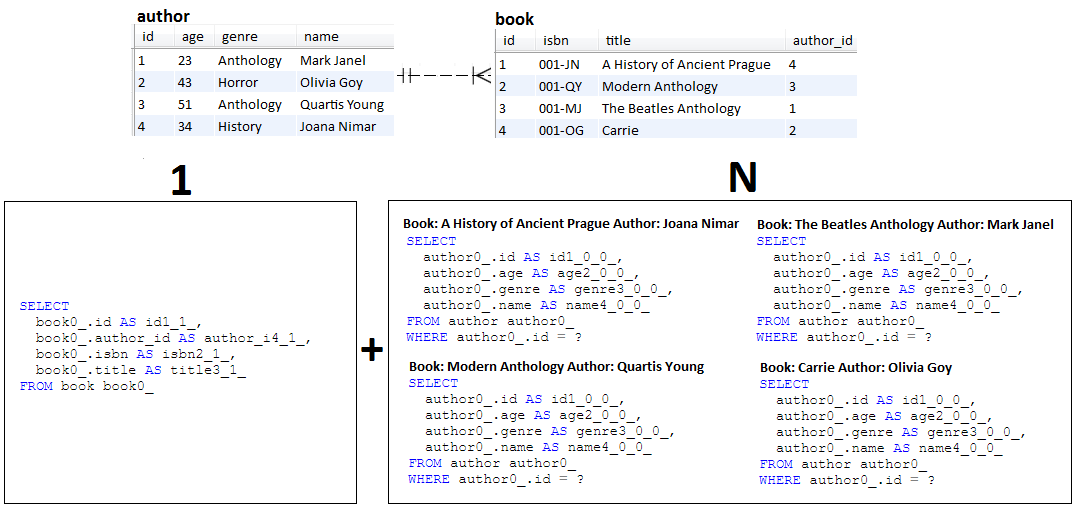
SELECT DISTINCT Via Hibernate HINT_PASS_DISTINCT_THROUGH HintDescription: Starting with Hibernate 5.2.2, we can optimize JPQL (HQL) query entites of type SELECT DISTINCT via HINT_PASS_DISTINCT_THROUGH hint. Keep in mind that this hint is useful only for JPQL (HQL) JOIN FETCH-ing queries. Is not useful for scalar queries (e.g., List<Integer>), DTO or HHH-13280. In such cases, the DISTINCT JPQL keyword is needed to be passed to the underlying SQL query. This will instruct the database to remove duplicates from the result set.
Key points:
@QueryHints(value = @QueryHint(name = HINT_PASS_DISTINCT_THROUGH, value = "false"))Output example:

Note: The Hibernate Dirty Checking mechanism is responsible to identify the entitites modifications at flush-time and to trigger the corresponding UPDATE statements in our behalf.
Description: Prior to Hibernate version 5, the Dirty Checking mechanism relies on Java Reflection API for checking every property of every managed entity. Starting with Hibernate version 5, the Dirty Checking mechanism can rely on the Dirty Tracking mechanism (which is the capability of an entity to track its own attributes changes) which requires Hibernate Bytecode Enhancement to be present in the application. The Dirty Tracking mechanism sustain a better performance, especially when you have a relatively large number of entitites.
For Dirty Tracking, during Bytecode Enhancement process, the entity classes bytecode is instrumented by Hibernate by adding a tracker, $$_hibernate_tracker. At flush time, Hibernate will use this tracker to discover the entities changes (each entity tracker will report the changes). This is better than checking every property of every managed entity.
Commonly (by default), the instrumentation takes place at build-time, but it can be configured to take place at runtime or deploy-time as well. It is preferable to take place at build-time for avoiding an overhead in the runtime.
Adding Bytecode Enhancement and enabling Dirty Tracking can be done via a plugin added via Maven or Gradle (Ant can be used as well). We use Maven, therefore we add it in pom.xml.
Key points:
pom.xml fileOutput example:

The Bytecode Enhancement effect can be seen on Author.class here. Notice how the bytecode was instrumented with $$_hibernate_tracker.
Optional In Entities And QueriesDescription: This application is an example of how is correct to use the Java 8 Optional in entities and queries.
Key points:
Optional (e.g., findById())OptionalOptional in entities gettersdata-mysql.sql@OneToMany Bidirectional AssociationDescription: This application is a proof of concept of how is correct to implement the bidirectional @OneToMany association from the performance perspective.
Key points:
mappedBy on the parentorphanRemoval on parent in order to remove children without references@NaturalId)) and/or database-generated identifiers and override (on child-side) properly the equals() and hashCode() methods as heretoString() need to be overridden, then pay attention to involve only the basic attributes fetched when the entity is loaded from the databaseNote: Pay attention to remove operations, especially to removing child entities. The CascadeType.REMOVE and orphanRemoval=true may produce too many queries. In such scenarios, relying on bulk operations is most of the time the best way to go for deletions.
Description: This application is an example of how to write a query via JpaRepository, EntityManager and Session.
Key points:
JpaRepository use @Query or Spring Data Query CreationEntityManager and Session use the createQuery() methodAUTO Generator Type In Hibernate 5 And MySQLDescription: In MySQL & Hibernate 5, the GenerationType.AUTO generator type will result in using the TABLE generator. This adds a significant performance penalty. Turning this behavior to IDENTITY generator can be obtained by using GenerationType.IDENTITY or the native generator.
Key points:
GenerationType.IDENTITY instead of GenerationType.AUTOOutput example:

Description: This application is an example when calling save() for an entity is redundant (not necessary).
Key points:
UPDATE statement without the need to explicitly call the save() methodsave() when is not necessarily) doesn't affect the number of triggered queries, but it implies a performance penalty in the underlying Hibernate processes| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
|
BIG)SERIAL In Batching Inserts Via HibernateDescription: In PostgreSQL, using GenerationType.IDENTITY will disable insert batching. The (BIG)SERIAL is acting "almost" like MySQL, AUTO_INCREMENT. In this application, we use the GenerationType.SEQUENCE which permits insert batching, and we optimize it via the hi/lo optimization algorithm.
Key points:
GenerationType.SEQUENCE instead of GenerationType.IDENTITYhi/lo algorithm to fetch a hi value in a database roundtrip (the hi value is useful for generating a certain/given number of identifiers in-memory; until you haven't exhausted all in-memory identifiers there is no need to fetch another hi)pooled and pooled-lo identifier generators (these are optimizations of hi/lo that allows external services to use the database without causing duplication keys errors)spring.datasource.hikari.data-source-properties.reWriteBatchedInserts=trueOutput example:
SINGLE_TABLEDescription: This application is a sample of using JPA Single Table inheritance strategy (SINGLE_TABLE).
Key points:
@Inheritance(strategy=InheritanceType.SINGLE_TABLE))@NotNull and MySQL triggersTINYINTOutput example (below is a single table obtained from 3 entities):

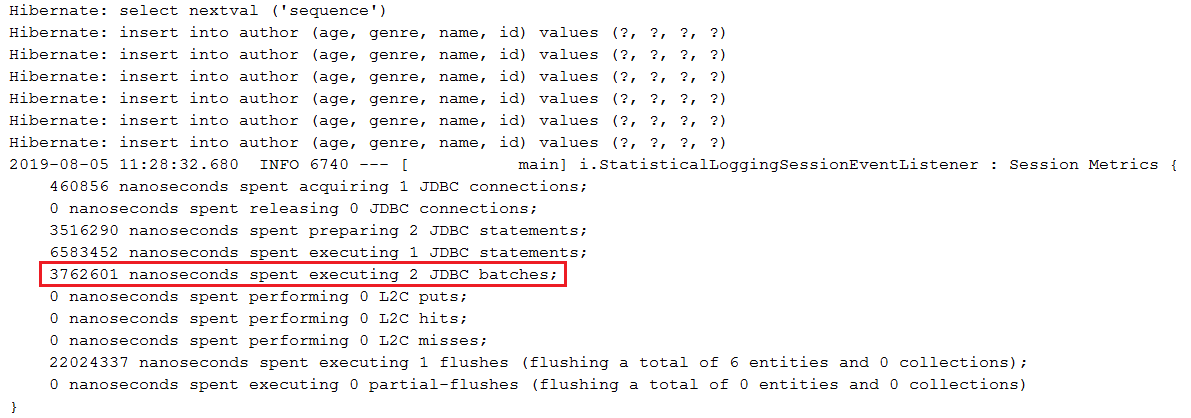
Description: This application is a sample of counting and asserting SQL statements triggered "behind the scene". Is very useful to count the SQL statements in order to ensure that your code is not generating more SQL statements that you may think (e.g., N+1 can be easily detected by asserting the number of expected statements).
Key points:
pom.xml, add dependencies for DataSource-Proxy library and Vlad Mihalcea's db-util libraryProxyDataSourceBuilder with countQuery()SQLStatementCountValidator.reset()INSERT, UPDATE, DELETE and SELECT via assertInsert/Update/Delete/Select/Count(long expectedNumberOfSql)Output example (when the number of expected SQLs is not equal with the reality an exception is thrown):
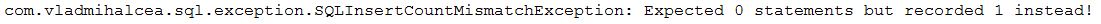
Description: This application is a sample of setting the JPA callbacks (Pre/PostPersist, Pre/PostUpdate, Pre/PostRemove and PostLoad).
Key points:
void and take no argumentsOutput example:

@MapsId For Sharing Identifier In @OneToOne RelationshipDescription: Instead of regular unidirectional/bidirectional @OneToOne better rely on an unidirectional @OneToOne and @MapsId. This application is a proof of concept.
Key points:
@MapsId on child side@JoinColumn to customize the name of the primary key column@OneToOne associations, @MapsId will share the primary key with the parent table (id property acts as both primary key and foreign key)Note:
@MapsId can be used for @ManyToOne as wellSqlResultSetMapping And EntityManagerDescription: Fetching more data than needed is prone to performance penalities. Using DTO allows us to extract only the needed data. In this application we rely on SqlResultSetMapping and EntityManager.
Key points:
SqlResultSetMapping and EntityManagerSqlResultSetMapping And NamedNativeQueryNote: If you want to rely on the {EntityName}.{RepositoryMethodName} naming convention for simply creating in the repository interface methods with the same name as of native named query then skip this application and check this one.
Description: Fetching more data than needed is prone to performance penalities. Using DTO allows us to extract only the needed data. In this application we rely on SqlResultSetMapping, NamedNativeQuery.
Key points:
SqlResultSetMapping, NamedNativeQueryjavax.persistence.Tuple And Native SQLDescription: Fetching more data than needed is prone to performance penalities. Using DTO allows us to extract only the needed data. In this application we rely on javax.persistence.Tuple and native SQL.
Key points:
java.persistence.Tuple in a Spring repository and mark the query as nativeQuery = truejavax.persistence.Tuple and JPQLDescription: Fetching more data than needed is prone to performance penalities. Using DTO allows us to extract only the needed data. In this application we rely on javax.persistence.Tuple and JPQL.
Key points:
java.persistence.Tuple in a Spring repositoryDescription: Fetching more data than needed is prone to performance penalities. Using DTO allows us to extract only the needed data. In this application we rely on Constructor Expression and JPQL.
Key points:
SELECT new com.bookstore.dto.AuthorDto(a.name, a.age) FROM Author aSee also:
How To Fetch DTO Via Constructor And Spring Data Query Builder Mechanism
| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
|
ResultTransformer And Native SQLDescription: Fetching more data than needed is prone to performance penalties. Using DTO allows us to extract only the needed data. In this application we rely on Hibernate, ResultTransformer and native SQL.
Key points:
AliasToBeanConstructorResultTransformer for DTO without setters, but with constructorTransformers.aliasToBean() for DTO with settersEntityManager.createNativeQuery() and unwrap(org.hibernate.query.NativeQuery.class)ResultTransformer is deprecated, but until a replacement will be available (probably in Hibernate 6.0) it can be used (read further)ResultTransformer and JPQLDescription: Fetching more data than needed is prone to performance penalties. Using DTO allows us to extract only the needed data. In this application we rely on Hibernate, ResultTransformer and JPQL.
Key points:
AliasToBeanConstructorResultTransformer for DTO without setters, with constructorTransformers.aliasToBean() for DTO with settersEntityManager.createQuery() and unwrap(org.hibernate.query.Query.class)ResultTransformer is deprecated, but until a replacement will be available (in Hibernate 6.0) it can be used (read further)Description: Fetching more data than needed is prone to performance penalities. Using DTO allows us to extract only the needed data. In this application we rely on Blaze-Persistence entity views.
Key points:
pom.xml the dependencies specific to Blaze-PersistenceCriteriaBuilderFactory and EntityViewManagerEntityViewRepositoryfindAll(), findOne(), etc@ElementCollection (Without @OrderColumn) WorksDescription: This application reveals the possible performance penalties of using @ElementCollection. In this case, without @OrderColumn. As you can see in the next item (34) adding @OrderColumn can mitigate some performance penalties.
Key points:
@ElementCollection doesn't have a primary key@ElementCollection is mapped in a separate table@ElementCollection when you have a lot of inserts/deletes on this collection; inserts/deletes will cause Hibernate to delete all the existing table rows, process the collection in-memory, and re-insert the remaining table rows to mirror the collection from memoryOutput example:

@ElementCollection With @OrderColumn WorksDescription: This application reveals the performance penalties of using @ElementCollection. In this case, with @OrderColumn. But, as you can see in this application (in comparison with item 33), by adding @OrderColumn can mitigate some performance penalties when operations takes place near the collection tail (e.g., add/remove at/from the end of the collection). Mainly, all elements situated before the adding/removing entry are left untouched, so the performance penalty can be ignored if we affect rows close to the collection tail.
Key points:
@ElementCollection doesn't have a primary key@ElementCollection is mapped in a separate table@ElementCollection with @OrderColumn when you have a lot of inserts and deletes near the collection tailOutput example:

Note: Before reading this item try to see if Hibernate5Module is not what you are looking for.
Description: The Open-Session in View anti-pattern is activated by default in SpringBoot. Now, imagine a lazy association (e.g., @OneToMany) between two entities, Author and Book (an author has associated more books). Next, a REST controller endpoint fetches an Author without the associated Book. But, the View (more precisely, Jackson), forces the lazy loading of the associated Book as well. Since OSIV will supply the already opened Session, the proxies initializations take place successfully. The solution to avoid this performance penalty starts by disabling the OSIV. Further, explicitly initialize the un-fetched lazy associations. This way, the View will not force lazy loading.
Key points:
application.properties this setting: spring.jpa.open-in-view=falseAuthor entity and initialize its associated Book explicitly with (default) values (e.g., null)@JsonInclude(Include.NON_EMPTY) on this entity-level to avoid rendering null or what is considered empty in the resulted JSONNOTE: If OSIV is enabled, the developer can still initialize the un-fetched lazy associations manually as long as he does this outside of a transaction to avoid flushing. But, why is this working? Since the Session is open, why the manually initialization of the associations of a managed entity doesn't trigger the flush? The answer can be found in the documentation of OpenSessionInViewFilter which specifies that: This filter will by default not flush the Hibernate Session, with the flush mode set to FlushMode.NEVER. It assumes to be used in combination with service layer transactions that care for the flushing: The active transaction manager will temporarily change the flush mode to FlushMode.AUTO during a read-write transaction, with the flush mode reset to FlushMode.NEVER at the end of each transaction. If you intend to use this filter without transactions, consider changing the default flush mode (through the "flushMode" property).

Description: This application is a proof of concept for using Spring Projections(DTO) and inner joins written via JPQL and native SQL (for MySQL).
Key points:
Author and Book in a (lazy) bidirectional @OneToMany association)resources/data-mysql.sql)AuthorNameBookTitle.java)
Description: This application is a proof of concept for using Spring Projections(DTO) and left joins written via JPQL and native SQL (for MySQL).
Key points:
Author and Book in a (lazy) bidirectional @OneToMany association)resources/data-mysql.sql)AuthorNameBookTitle.java)
Description: This application is a proof of concept for using Spring Projections(DTO) and right joins written via JPQL and native SQL (for MySQL).
Key points:
Author and Book in a (lazy) bidirectional @OneToMany association)resources/data-mysql.sql)AuthorNameBookTitle.java)
Description: This application is a proof of concept for using Spring Projections(DTO) and inclusive full joins written via JPQL and native SQL (for PostgreSQL).
Key points:
Author and Book in a (lazy) bidirectional @OneToMany association)resources/data-mysql.sql)AuthorNameBookTitle.java)| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
|

Description: This application is a proof of concept for using Spring Projections(DTO) and exclusive left joins written via JPQL and native SQL (for MySQL).
Key points:
Author and Book in a (lazy) bidirectional @OneToMany association)resources/data-mysql.sql)AuthorNameBookTitle.java)
Description: This application is a proof of concept for using Spring Projections(DTO) and exclusive right joins written via JPQL and native SQL (for MySQL).
Key points:
Author and Book in a (lazy) bidirectional @OneToMany association)resources/data-mysql.sql)AuthorNameBookTitle.java)
Description: This application is a proof of concept for using Spring Projections(DTO) and exclusive full joins written via JPQL and native SQL (for PostgreSQL).
Key points:
Author and Book in a (lazy) bidirectional @OneToMany association)resources/data-mysql.sql)AuthorNameBookTitle.java)Description: This application is a proof of concept for using Spring post-commit hooks and how they may affect the persistence layer performance.
Key points:
Description: This application is a proof of concept for using Spring Projections (DTO) and join unrelated entities. Hibernate 5.1 introduced explicit joins on unrelated entities and the syntax and behaviour are similar to SQL JOIN statements.
Key points:
Author and Book unrelated entities)resources/data-mysql.sql)BookstoreDto)@EqualsAndHashCode And @Data In Entities And How To Override equals() And hashCode()Description: Entities should implement equals() and hashCode() as here. The main idea is that Hibernate requires that an entity is equal to itself across all its state transitions (transient, attached, detached and removed). Using Lombok @EqualsAndHashCode (or @Data) will not respect this requirment.
Key points:
AVOID THESE APPROACHES
@EqualsAndHashCode
(entity: LombokDefaultBook, test: LombokDefaultEqualsAndHashCodeTest)@EqualsAndHashCode with primary key only
(entity: LombokIdBook, test: LombokEqualsAndHashCodeWithIdOnlyTest)equals() and hashCode()
(entity: DefaultBook, test: DefaultEqualsAndHashCodeTest)equals() and hashCode() containing only the database-generated identifier
(entity: IdBook, test: IdEqualsAndHashCodeTest)PREFER THESE APPROACHES
BusinessKeyBook, test: BusinessKeyEqualsAndHashCodeTest)@NaturalId (entity: NaturalIdBook, test: NaturalIdEqualsAndHashCodeTest)IdManBook, test: IdManEqualsAndHashCodeTest)IdGenBook, test: IdGenEqualsAndHashCodeTest)
LazyInitializationException Via JOIN FETCHSee also:
Description: Typically, when we get a LazyInitializationException we tend to modify the association fetching type from LAZY to EAGER. That is very bad! This is a code smell. Best way to avoid this exception is to rely on JOIN FETCH (if you plan to modify the fetched entities) or JOIN + DTO (if the fetched data is only read). JOIN FETCH allows associations to be initialized along with their parent objects using a single SELECT. This is particularly useful for fetching associated collections.
This application is a JOIN FETCH example for avoiding LazyInitializationException.
Key points:
Author and Book in a @OneToMany lazy-bidirectional association)JOIN FETCH to fetch an author including his booksJOIN FETCH (or JOIN) to fetch a book including its authorOutput example:

Description: This is a Spring Boot example based on the following article. Is a functional implementation of the Vlad's example. It is highly recommended to read that article.
Key points:
Description: This is a Spring Boot example that exploits Hibernate 5.2.10 capability of delaying the connection acquisition as needed. By default, in resource-local mode, a database connection is aquried immediately after calling a method annotated with @Transactional. If this method contains some time-consuming tasks before the first SQL statement then the connection is hold open for nothing. But, Hibernate 5.2.10 allows us to delay the connection acquisition as needed. This example rely on HikariCP as the default connection pool for Spring Boot.
Key points:
spring.datasource.hikari.auto-commit=false in application.propertiesspring.jpa.properties.hibernate.connection.provider_disables_autocommit=true in application.propertiesOutput example:


hi/lo AlgorithmNote: If systems external to your application need to insert rows in your tables then don't rely on hi/lo algorithm since, in such cases, it may cause errors resulted from generating duplicated identifiers. Rely on pooled or pooled-lo algorithms (optimizations of hi/lo).
Description: This is a Spring Boot example of using the hi/lo algorithm for generating 1000 identifiers in 10 database roundtrips for batching 1000 inserts in batches of 30.
Key points:
SEQUENCE generator type (e.g., in PostgreSQL)hi/lo algorithm as in Author.java entityOutput example:

| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
|
@ManyToMany AssociationDescription: This application is a proof of concept of how it is correct to implement the bidirectional @ManyToMany association from the performance perspective.
Key points:
mappedBy sideSet not ListCascadeType.PERSIST and CascadeType.MERGE, but avoid CascadeType.REMOVE/ALL@ManyToMany is lazy by default; keep it this way!@NaturalId)) and/or database-generated identifiers and override (on both sides) properly the equals() and hashCode() methods as heretoString() need to be overridden, then pay attention to involve only for the basic attributes fetched when the entity is loaded from the databaseSet Instead of List in @ManyToMany AssociationsDescription: This is a Spring Boot example of removing rows in case of a bidirectional @ManyToMany using List, respectively Set. The conclusion is that Set is much better! This applies to unidirectional as well!
Key points:
Set is much more efficent than ListOutput example:

log4jdbcDescription: View the query details via log4jdbc.
Key points:
pom.xml, add log4jdbc dependencyOutput sample:

Description: View the prepared statement binding/extracted parameters via TRACE.
Key points:
application.properties add: logging.level.org.hibernate.type.descriptor.sql=TRACEOutput sample:

java.time.YearMonth As Integer Or Date Via Hibernate Types LibraryDescription: Hibernate Types is a set of extra types not supported by default in Hibernate Core. One of these types is java.time.YearMonth. This is a Spring Boot application that uses Hibernate Type to store this YearMonth in a MySQL database as integer or date.
Key points:
pom.xml@TypeDef to map typeClass to defaultForTypeOutput example:

Note: Using SQL functions in the WHERE part (not in the SELECT part) of query in JPA 2.1 can be done via function() as here.
Description: Trying to use SQL functions (standard or defined) in JPQL queries may result in exceptions if Hibernate will not recognize them and cannot parse the JPQL query. For example, the MySQL, concat_ws function is not recognized by Hibernate. This application is a Spring Boot application based on Hibernate 5.3, that registers the concat_ws function via MetadataBuilderContributor and inform Hibernate about it via, metadata_builder_contributor property. This example uses @Query and EntityManager as well, so you can see two use cases.
Key points:
MetadataBuilderContributor and register the concat_ws MySQL functionapplication.properties, set spring.jpa.properties.hibernate.metadata_builder_contributor to point out Hibernate to MetadataBuilderContributor implementationOutput example:

Description: This application is a sample of logging only slow queries via DataSource-Proxy. A slow query is a query that has an execution time bigger than a specificed threshold in milliseconds.
Key points:
pom.xml the DataSource-Proxy dependencyDataSource beanDataSource bean via ProxyFactory and an implementation of MethodInterceptorafterQuery()Output example:

SELECT COUNT Subquery And Return Page<dto>Description: This application fetches data as Page<dto> via Spring Boot offset pagination. Most of the time, the data that should be paginated is read-only data. Fetching the data into entities should be done only if we plan to modify that data, therefore, fetching read only data as Page<entity> is not preferable since it may end up in a significant performance penalty. The SELECT COUNT triggered for counting the total number of records is a subquery of the main SELECT. Therefore, there will be a single database roundtrip instead of two (typically, there is one query needed for fetching the data and one for counting the total number of records).
Key points:
PagingAndSortingRepositoryList<dto>List<dto> and the proper Pageable to create a Page<dto>SELECT COUNT Subquery And Return List<dto>Description: This application fetches data as List<dto> via Spring Boot offset pagination. Most of the time, the data that should be paginated is read-only data. Fetching the data into entities should be done only if we plan to modify that data, therefore, fetching read only data as List<entity> is not preferable since it may end up in a significant performance penalty. The SELECT COUNT triggered for counting the total number of records is a subquery of the main SELECT. Therefore, there will be a single database roundtrip instead of two (typically, there is one query needed for fetching the data and one for counting the total number of records).
Key points:
PagingAndSortingRepositoryList<dto>If you use the spring-boot-starter-jdbc or spring-boot-starter-data-jpa "starters", you automatically get a dependency to HikariCP
Note: The best way to tune the connection pool parameters consist in using Flexy Pool by Vlad Mihalcea. Via Flexy Pool you can find the optim settings that sustain high-performance of your connection pool.
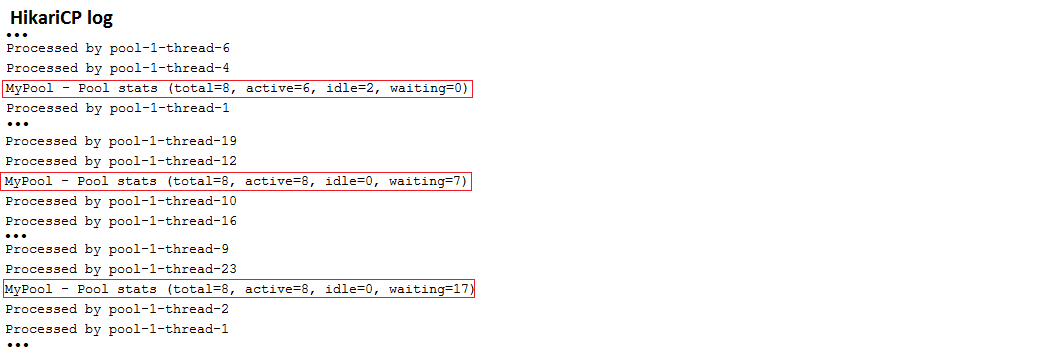
Description: This is a kickoff application that set up HikariCP via application.properties only. The jdbcUrl is set up for a MySQL database. For testing purposes, the application uses an ExecutorServicefor simulating concurrent users. Check the HickariCP report revealing the connection pool status.
Key points:
application.properties, rely on spring.datasource.hikari.* to configure HikariCPOutput sample:
| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
|
DataSourceBuilderIf you use the spring-boot-starter-jdbc or spring-boot-starter-data-jpa "starters", you automatically get a dependency to HikariCP
Note: The best way to tune the connection pool parameters consist in using Flexy Pool by Vlad Mihalcea. Via Flexy Pool you can find the optim settings that sustain high-performance of your connection pool.
Description: This is a kickoff application that set up HikariCP via DataSourceBuilder. The jdbcUrl is set up for a MySQL database. For testing purposes, the application uses an ExecutorService for simulating concurrent users. Check the HickariCP report revealing the connection pool status.
Key points:
application.properties, configure HikariCP via a custom prefix, e.g., app.datasource.*@Bean that returns the DataSourceOutput sample:
This application is detailed in this DZone article.
DataSourceBuilderNote: The best way to tune the connection pool parameters consist in using Flexy Pool by Vlad Mihalcea. Via Flexy Pool you can find the optim settings that sustain high-performance of your connection pool.
Description: This is a kickoff application that set up BoneCP via DataSourceBuilder. The jdbcUrl is set up for a MySQL database. For testing purposes, the application uses an ExecutorService for simulating concurrent users.
Key points:
pom.xml add the BoneCP dependencyapplication.properties, configure BoneCP via a custom prefix, e.g., app.datasource.*@Bean that returns the DataSourceOutput sample:

DataSourceBuilderNote: The best way to tune the connection pool parameters consist in using Flexy Pool by Vlad Mihalcea. Via Flexy Pool you can find the optim settings that sustain high-performance of your connection pool.
Description: This is a kickoff application that set up ViburDBCP via DataSourceBuilder. The jdbcUrl is set up for a MySQL database. For testing purposes, the application uses an ExecutorService for simulating concurrent users.
Key points:
pom.xml add the ViburDBCP dependencyapplication.properties, configure ViburDBCP via a custom prefix, e.g., app.datasource.*@Bean that returns the DataSourceOutput sample:

DataSourceBuilderNote: The best way to tune the connection pool parameters consist in using Flexy Pool by Vlad Mihalcea. Via Flexy Pool you can find the optim settings that sustain high-performance of your connection pool.
Description: This is a kickoff application that set up C3P0 via DataSourceBuilder. The jdbcUrl is set up for a MySQL database. For testing purposes, the application uses an ExecutorService for simulating concurrent users.
Key points:
pom.xml add the C3P0 dependencyapplication.properties, configure C3P0 via a custom prefix, e.g., app.datasource.*@Bean that returns the DataSourceOutput sample:

DataSourceBuilderNote: The best way to tune the connection pool parameters consist in using Flexy Pool by Vlad Mihalcea. Via Flexy Pool you can find the optim settings that sustain high-performance of your connection pool.
Description: This is a kickoff application that set up DBCP2 via DataSourceBuilder. The jdbcUrl is set up for a MySQL database. For testing purposes, the application uses an ExecutorService for simulating concurrent users.
Key points:
pom.xml add the DBCP2 dependencyapplication.properties, configure DBCP2 via a custom prefix, e.g., app.datasource.*@Bean that returns the DataSourceDataSourceBuilderNote: The best way to tune the connection pool parameters consist in using Flexy Pool by Vlad Mihalcea. Via Flexy Pool you can find the optim settings that sustain high-performance of your connection pool.
Description: This is a kickoff application that set up Tomcat via DataSourceBuilder. The jdbcUrl is set up for a MySQL database. For testing purposes, the application uses an ExecutorService for simulating concurrent users.
Key points:
pom.xml add the Tomcat dependencyapplication.properties, configure Tomcat via a custom prefix, e.g., app.datasource.*@Bean that returns the DataSourceOutput sample:

Note: The best way to tune the connection pool parameters consist in using Flexy Pool by Vlad Mihalcea. Via Flexy Pool you can find the optim settings that sustain high-performance of your connection pool.
Description: This is a kickoff application that uses two data sources (two MySQL databases, one named authorsdb and one named booksdb) with two connection pools (each database uses its own HikariCP connection pool with different settings). Based on the above items is pretty easy to configure two connection pools from two different providers as well.
Key points:
application.properties, configure two HikariCP connection pools via a two custom prefixes, e.g., app.datasource.ds1 and app.datasource.ds2@Bean that returns the first DataSource and mark it as @Primary@Bean that returns the second DataSourceEntityManagerFactory and point out the packages to scan for each of themEntityManager in the right packagesOutput sample:

Note: If you want yo provide a Fluent API without altering setters then consider this item.
Description: This is a sample application that alter the entities setters methods in order to empower a Fluent API.
Key points:
this instead of void in settersFluent API example:

Note: If you want yo provide a Fluent API by altering setters then consider this item.
Description: This is a sample application that add in entities additional methods (e.g., for setName, we add name) methods in order to empower a Fluent API.
Key points:
this instead of voidFluent API example:

| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
|
Slice<T> findAll()Most probably this is all you want: How To Fetch Slice<entity>/Slice<dto> Via fetchAll/fetchAllDto
Some implementations of Slice<T> findAll():
"SELECT e FROM " + entityClass.getSimpleName() + " e;"CriteriaBuilder instead of hard-coded SQLSort, so sorting results is possibleSort and a Spring Data SpecificationSort, a LockModeType, a QueryHints and a Spring Data SpecificationPageable and/or Specification by extending the SimpleJpaRepository from Spring Data. Bascially, this implementation is the only one that returns Page<T> instead of Slice<T>, but it doesn't trigger the extra SELECT COUNT since it was eliminated by overriding the Page<T> readPage(...) method from SimpleJpaRepository. The main drawback is that by returing a Page<T> you don't know if there is a next page or the current one is the last. Nevertheless, there are workarounds to have this as well. In this implementation you cannot set LockModeType or query hints.Story: Spring Boot provides an offset based built-in paging mechanism that returns a Page or Slice. Each of these APIs represents a page of data and some metadata. The main difference is that Page contains the total number of records, while Slice can only tell if there is another page available. For Page, Spring Boot provides a findAll() method capable to take as arguments a Pageable and/or a Specification or Example. In order to create a Page that contains the total number of records, this method triggers an SELECT COUNT extra-query next to the query used to fetch the data of the current page. This can be a performance penalty since the SELECT COUNT query is triggered every time we request a page. In order to avoid this extra-query, Spring Boot provides a more relaxed API, the Slice API. Using Slice instead of Page removes the need of this extra SELECT COUNT query and returns the page (records) and some metadata without the total number of records. So, while Slice doesn't know the total number of records, it still can tell if there is another page available after the current one or this is the last page. The problem is that Slice work fine for queries containing the SQL, WHERE clause (including those that uses the query builder mechanism built into Spring Data), but it doesn't work for findAll(). This method will still return a Page instead of Slice therefore the SELECT COUNT query is triggered for Slice<T> findAll(...);.
Description: This is a suite of samples applications that provides different versions of a Slice<T> findAll(...) method. We have from a minimalist implementation that relies on a hardcoded query as: "SELECT e FROM " + entityClass.getSimpleName() + " e"; (this recipe), to a custom implementation that supports sorting, specification, lock mode and query hints to an implementation that relies on extending SimpleJpaRepository.
Key points:
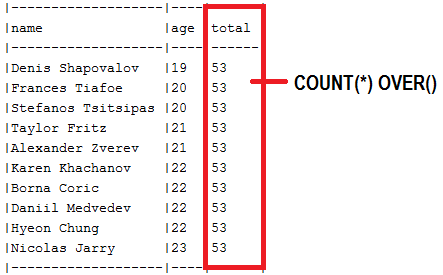
abstract class that expose the Slice<T> findAll(...) methods (SlicePagingRepositoryImplementation)findAll() methods to return Slice<T> (or Page<T>, but without the total number of elements)SliceImpl (Slice<T>) or a PageImpl (Page<T>) without the total number of elementsreadSlice() method or override the SimpleJpaRepository#readPage() page to avoid SELECT COUNTAuthor.class) to this abstract class via a class repository (AuthorRepository)COUNT(*) OVER And Return List<dto>Description: Typically, in offset pagination, there is one query needed for fetching the data and one for counting the total number of records. But, we can fetch this information in a single database rountrip via a SELECT COUNT subquery nested in the main SELECT. Even better, for databases vendors that support Window Functions there is a solution relying on COUNT(*) OVER() as in this application that uses this window function in a native query against MySQL 8. So, prefer this one instead of SELECT COUNT subquery.
Key points:
COUNT(*) OVER() window functionExample:
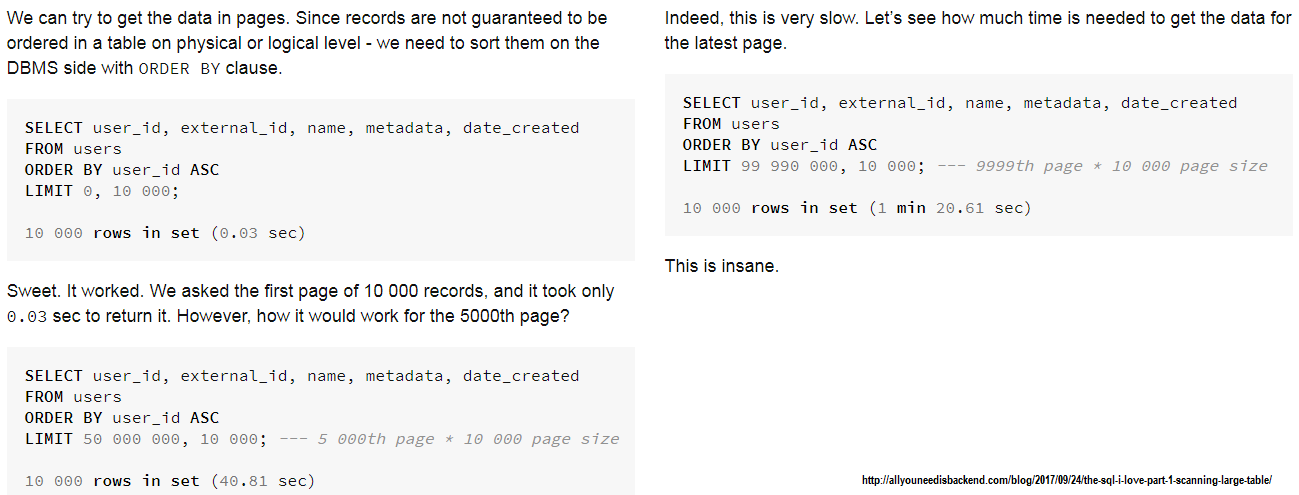
Description: When we rely on an offset paging we have the performance penalty induced by throwing away n records before reached the desired offset. Larger n leads to a significant performance penalty. When we have a large n is better to rely on keyset pagination which maintain a "constant" time for large datasets. In order to understand how bad offset can perform please check this article:
Screenshot from that article (offset pagination):
Need to know if there are more records?
By its nature, keyset doesn't use a SELECT COUNT to fetch the number of total records. But, with a little tweak, we can easily say if there are more records, therefore to show a button of type Next Page. Mainly, if you need such a thing then consider this application whose climax is listed below:
public AuthorView fetchNextPage(long id, int limit) {
List<Author> authors = authorRepository.fetchAll(id, limit + 1);
if (authors.size() == (limit + 1)) {
authors.remove(authors.size() - 1);
return new AuthorView(authors, true);
}
return new AuthorView(authors, false);
}
Or, like this (rely on Author.toString() method):
public Map<List<Author>, Boolean> fetchNextPage(long id, int limit) {
List<Author> authors = authorRepository.fetchAll(id, limit + 1);
if(authors.size() == (limit + 1)) {
authors.remove(authors.size() -1);
return Collections.singletonMap(authors, true);
}
return Collections.singletonMap(authors, false);
}
A Previous Page button can be implemented easily based on the first record.
Key points:
id)WHERE and ORDER BY clauses of your SQLDescription: This is a classical Spring Boot offset pagination example. However, is not advisable to use this approach in production because of its performance penalties explained further.
When we rely on an offset pagination, we have the performance penalty induced by throwing away n records before reaching the desired offset. Larger n leads to a significant performance penalty. Another penalty is the extra-SELECT needed to count the total number of records. In order to understand how bad offset pagination can perform please check this article. A screenshot from that article is below:
Nevertheless, maybe this example is a little bit extreme. For relatively small datasets, offset pagination is not so bad (it is close in performance to keyset pagination), and, since Spring Boot provides built-in support for offset pagination via the Page API, it is very easy to use it. However, depending on the case, we can optimize a little bit the offset pagination as in the following examples:
Fetch a page as a Page:
COUNT(*) OVER And Return Page<dto>COUNT(*) OVER And Return Page<entity> Via Extra ColumnSELECT COUNT Subquery And Return Page<dto>SELECT COUNT Subquery And Return Page<entity> Via Extra ColumnSELECT COUNT Subquery And Return Page<projection> That Maps Entities And The Total Number Of Records Via ProjectionFetch a page as a List:
COUNT(*) OVER And Return List<dto>COUNT(*) OVER And Return List<entity> Via Extra ColumnSELECT COUNT Subquery And Return List<dto>SELECT COUNT Subquery And Return List<entity> Via Extra ColumnSELECT COUNT Subquery And Return List<projection> That Maps Entities And The Total Number Of Records Via ProjectionBut: If offset pagination is causing you performance issues and you decide to go with keyset pagination then please check here (keyset pagination).
Key points of classical offset pagination:
PagingAndSortingRepositoryPage<entity>Examples of classical offset pagination:
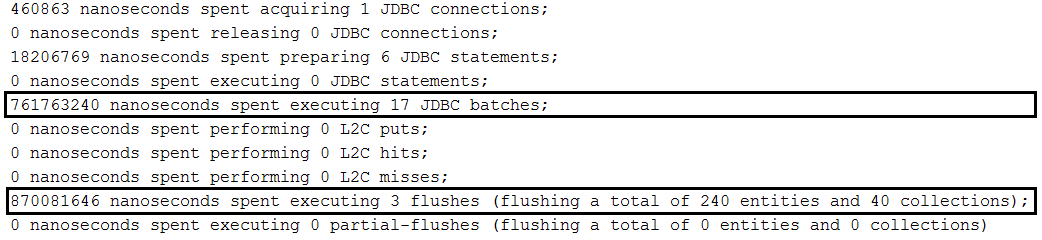
findAll(Pageable) without sorting:repository.findAll(PageRequest.of(page, size));findAll(Pageable) with sorting:repository.findAll(PageRequest.of(page, size, new Sort(Sort.Direction.ASC, "name")));Page<Author> findByName(String name, Pageable pageable);Page<Author> queryFirst10ByName(String name, Pageable pageable);Description: Let's suppose that we have a one-to-many relationship between Author and Book entities. When we save an author, we save his books as well thanks to cascading all/persist. We want to create a bunch of authors with books and save them in the database (e.g., a MySQL database) using the batch technique. By default, this will result in batching each author and the books per author (one batch for the author and one batch for the books, another batch for the author and another batch for the books, and so on). In order to batch authors and books, we need to order inserts as in this application.
Key points:
Beside all setting specific to batching inserts in MySQL, we need to set up in application.properties the following property: spring.jpa.properties.hibernate.order_inserts=true
Example without ordered inserts:

Example with ordered inserts:
Implementations:
Description: Batch updates in MySQL.
Key points:
application.properties set spring.jpa.properties.hibernate.jdbc.batch_sizeapplication.properties set JDBC URL with rewriteBatchedStatements=true (optimization for MySQL, statements get rewritten into a single string buffer and sent in a single request)application.properties set JDBC URL with cachePrepStmts=true (enable caching and is useful if you decide to set prepStmtCacheSize, prepStmtCacheSqlLimit, etc as well; without this setting the cache is disabled)application.properties set JDBC URL with useServerPrepStmts=true (this way you switch to server-side prepared statements (may lead to signnificant performance boost))spring.jpa.properties.hibernate.order_updates=true to optimize the batching by ordering updatesapplication.properties a setting for enabling batching for versioned entities during update and delete operations (entities that contains @Version for implicit optimistic locking); this setting is: spring.jpa.properties.hibernate.jdbc.batch_versioned_data=true; starting with Hibernate 5, this setting should be true by defaultOutput example for single entity:
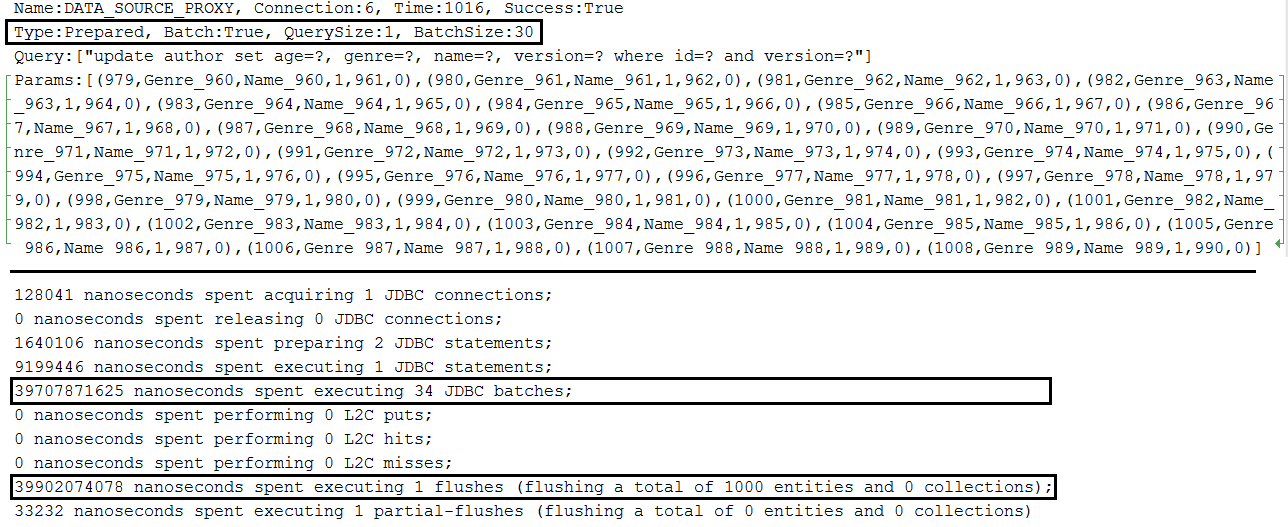
Output example for parent-child relationship:

Description: Batch deletes that don't involve associations in MySQL.
Note: Spring deleteAllInBatch() and deleteInBatch() don't use delete batching and don't take advantage of automatic optimstic locking mechanism to prevent lost updates (e.g., @Version is ignored). They rely on Query.executeUpdate() to trigger bulk operations. These operations are fast, but Hibernate doesn’t know which entities are removed, therefore, the Persistence Context is not updated accordingly (it's up to you to flush (before delete) and close/clear (after delete) the Persistence Context accordingly to avoid issues created by unflushed (if any) or outdated (if any) entities). The first one (deleteAllInBatch()) simply triggers a delete from entity_name statement and is very useful for deleting all records. The second one (deleteInBatch()) triggers a delete from entity_name where id=? or id=? or id=? ... statement, therefore, is prone to cause issues if the generated DELETE statement exceedes the maximum accepted size. This issue can be controlled by deleting the data in chunks, relying on IN operator, and so on. Bulk operations are faster than batching which can be achieved via the deleteAll(), deleteAll(Iterable<? extends T> entities) or delete() method. Behind the scene, the two flavors of deleteAll() relies on delete(). The delete()/deleteAll() methods rely on EntityManager.remove() therefore the Persistence Context is synchronized accordingly. Moreover, if automatic optimstic locking mechanism (to prevent lost updates) is enabled then it will be used.
Key points for regular delete batching:
deleteAll(), deleteAll(Iterable<? extends T> entities) or delete() methodapplication.properties set spring.jpa.properties.hibernate.jdbc.batch_sizeapplication.properties set JDBC URL with rewriteBatchedStatements=true (optimization for MySQL, statements get rewritten into a single string buffer and sent in a single request)application.properties set JDBC URL with cachePrepStmts=true (enable caching and is useful if you decide to set prepStmtCacheSize, prepStmtCacheSqlLimit, etc as well; without this setting the cache is disabled)application.properties set JDBC URL with useServerPrepStmts=true (this way you switch to server-side prepared statements (may lead to signnificant performance boost))application.properties a setting for enabling batching for versioned entities during update and delete operations (entities that contains @Version for implicit optimistic locking); this setting is: spring.jpa.properties.hibernate.jdbc.batch_versioned_data=true; starting with Hibernate 5, this setting should be true by defaultOutput example:

Description: Batch deletes in MySQL via orphanRemoval=true.
Note: Spring deleteAllInBatch() and deleteInBatch() don't use delete batching and don't take advantage of cascading removal, orphanRemoval and automatic optimstic locking mechanism to prevent lost updates (e.g., @Version is ignored). They rely on Query.executeUpdate() to trigger bulk operations. These operations are fast, but Hibernate doesn’t know which entities are removed, therefore, the Persistence Context is not updated accordingly (it's up to you to flush (before delete) and close/clear (after delete) the Persistence Context accordingly to avoid issues created by unflushed (if any) or outdated (if any) entities). The first one (deleteAllInBatch()) simply triggers a delete from entity_name statement and is very useful for deleting all records. The second one (deleteInBatch()) triggers a delete from entity_name where id=? or id=? or id=? ... statement, therefore, is prone to cause issues if the generated DELETE statement exceedes the maximum accepted size. This issue can be controlled by deleting the data in chunks, relying on IN operator, and so on. Bulk operations are faster than batching which can be achieved via the deleteAll(), deleteAll(Iterable<? extends T> entities) or delete() method. Behind the scene, the two flavors of deleteAll() relies on delete(). The delete()/deleteAll() methods rely on EntityManager.remove() therefore the Persistence Context is synchronized accordingly. If automatic optimstic locking mechanism (to prevent lost updates) is enabled then it will be used. Moreover, cascading removals and orphanRemoval works as well.
Key points for using deleteAll()/delete():
Author entity and each author can have several Book (one-to-many)orphanRemoval=true and CascadeType.ALLBook from the corresponding AuthororphanRemoval=true to enter into the scene; thanks to this setting, all disassociated books will be deleted; the generated DELETE statements are batched (if orphanRemoval is set to false, a bunch of updates will be executed instead of deletes)Author via the deleteAll() or delete() method (since we have dissaciated all Book, the Author deletion will take advantage of batching as well)ON DELETE CASCADEDescription: Batch deletes in MySQL via ON DELETE CASCADE. Auto-generated database schema will contain the ON DELETE CASCADE directive.
Note: Spring deleteAllInBatch() and deleteInBatch() don't use delete batching and don't take advantage of cascading removal, orphanRemoval and automatic optimistic locking mechanism to prevent lost updates (e.g., @Version is ignored), but both of them take advantage on ON DELETE CASCADE and are very efficient. They trigger bulk operations via Query.executeUpdate(), therefore, the Persistence Context is not synchronized accordingly (it's up to you to flush (before delete) and close/clear (after delete) the Persistence Context accordingly to avoid issues created by unflushed (if any) or outdated (if any) entities). The first one simply triggers a delete from entity_name statement, while the second one triggers a delete from entity_name where id=? or id=? or id=? ... statement. For delete in batches rely on deleteAll(), deleteAll(Iterable<? extends T> entities) or delete() method. Behind the scene, the two flavors of deleteAll() relies on delete(). Mixing batching with database automatic actions (ON DELETE CASCADE) will result in a partially synchronized Persistent Context.
Key points:
Author entity and each author can have several Book (one-to-many)orphanRemoval or set it to falseCascadeType.PERSIST and CascadeType.MERGE@OnDelete(action = OnDeleteAction.CASCADE) next to @OneToManyspring.jpa.properties.hibernate.dialect to org.hibernate.dialect.MySQL5InnoDBDialect (or, MySQL8Dialect)deleteFoo() methods that uses bulk and batching deletes as wellOutput example:

@NaturalId In Spring Boot StyleAlternative implementation: In case that you want to avoid extending SimpleJpaRepository check this implementation.
Description: This is a SpringBoot application that maps a natural business key using Hibernate @NaturalId. This implementation allows us to use @NaturalId as it was provided by Spring.
Key points:
Book), mark the properties (business keys) that should act as natural IDs with @NaturalId; commonly, there is a single such property, but multiple are suppored as well as here@NaturalId(mutable = false) and @Column(nullable = false, updatable = false, unique = true, ...)@NaturalId(mutable = true) and @Column(nullable = false, updatable = true, unique = true, ...)equals() and hashCode() using the natural id(s)@NoRepositoryBean interface (NaturalRepository) to define two methods, named findBySimpleNaturalId() and findByNaturalId()NaturalRepositoryImpl) relying on Hibernate, Session, bySimpleNaturalId() and byNaturalId() methods@EnableJpaRepositories(repositoryBaseClass = NaturalRepositoryImpl.class) to register this implementation as the base classfindBySimpleNaturalId() or findByNaturalId()| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
|
Description: This is a Spring Boot application that uses P6Spy. P6Spy is a framework that enables database data to be seamlessly intercepted and logged with no code changes to the application.
Key points:
pom.xml, add the P6Spy Maven dependencyapplication.properties, set up JDBC URL as, jdbc:p6spy:mysql://localhost:3306/db_usersapplication.properties, set up driver class name as, com.p6spy.engine.spy.P6SpyDriverspy.properties (this file contains P6Spy configurations); in this application, the logs will be outputed to console, but you can easy switch to a file; more details about P6Spy configurations can be found in documentationOutput sample:

OptimisticLockException Exception (@Version)Note: Optimistic locking mechanism via @Version works for detached entities as well.
Description: This is a Spring Boot application that simulates a scenario that leads to an optimistic locking exception. When such exception occur, the application retry the corresponding transaction via db-util library developed by Vlad Mihalcea.
Key points:
pom.xml, add the db-util dependencyOptimisticConcurrencyControlAspect bean@Transactional) that is prone to throw (or that calls a method that is prone to throw (this method can be annotated with @Transactional)) an optimistic locking exception with @Retry(times = 10, on = OptimisticLockingFailureException.class)Output sample:

OptimisticLockException Exception (Hibernate Version-less Optimistic Locking Mechanism)Note: Optimistic locking mechanism via Hibernate version-less doesn't work for detached entities (don't close the Persistent Context).
Description: This is a Spring Boot application that simulates a scenario that leads to an optimistic locking exception (e.g., in Spring Boot, OptimisticLockingFailureException) via Hibernate version-less optimistic locking. When such exception occur, the application retry the corresponding transaction via db-util library developed by Vlad Mihalcea.
Key points:
pom.xml, add the db-util library dependencyOptimisticConcurrencyControlAspect beanInventory) with @DynamicUpdate and @OptimisticLocking(type = OptimisticLockType.DIRTY)@Transactional) that is prone to throw (or that calls a method that is prone to throw (this method can be annotated with @Transactional)) an optimistic locking exception with @Retry(times = 10, on = OptimisticLockingFailureException.class)Note: You may also like to read the recipe, "How To Create DTO Via Spring Data Projections"
Description: This is an application sample that fetches only the needed columns from the database via Spring Data Projections (DTO) and enrich the result via virtual properties.
Key points:
name and ageAuthorNameAge, use the @Value and Spring SpEL to point to a backing property from the domain model (in this case, the domain model property age is exposed via the virtual property years)AuthorNameAge, use the @Value and Spring SpEL to enrich the result with two virtual properties that don't have a match in the domain model (in this case, rank and books)Output example:

Description: Spring Data comes with the query creation mechanism for JPA that is capable to interpret a query method name and convert it into a SQL query in the proper dialect. This is possible as long as we respect the naming conventions of this mechanism. This is an application that exploit this mechanism to write queries that limit the result size. Basically, the name of the query method instructs Spring Data how to add the LIMIT (or similar clauses depending on the RDBMS) clause to the generated SQL queries.
Key points:
AuthorRepository)Examples:
- List<Author> findFirst5ByAge(int age);
- List<Author> findFirst5ByAgeGreaterThanEqual(int age);
- List<Author> findFirst5ByAgeLessThan(int age);
- List<Author> findFirst5ByAgeOrderByNameDesc(int age);
- List<Author> findFirst5ByGenreOrderByAgeAsc(String genre);
- List<Author> findFirst5ByAgeGreaterThanEqualOrderByNameAsc(int age);
- List<Author> findFirst5ByGenreAndAgeLessThanOrderByNameDesc(String genre, int age);
- List<AuthorDto> findFirst5ByOrderByAgeAsc();
- Page<Author> queryFirst10ByName(String name, Pageable p);
- Slice<Author> findFirst10ByName(String name, Pageable p);
The list of supported keywords is listed below:

schema-*.sql In MySQLNote: As a rule, in real applications avoid generating schema via hibernate.ddl-auto or set it to validate. Use schema-*.sql file or better Flyway or Liquibase migration tools.
Description: This application is an example of using schema-*.sql to generate a schema(database) in MySQL.
Key points:
application.properties, set the JDBC URL (e.g., spring.datasource.url=jdbc:mysql://localhost:3306/bookstoredb?createDatabaseIfNotExist=true)application.properties, disable DDL auto (just don't add explicitly the hibernate.ddl-auto setting)application.properties, instruct Spring Boot to initialize the schema from schema-mysql.sql fileschema-*.sql And Match Entities To Them Via @Table In MySQLNote: As a rule, in real applications avoid generating schema via hibernate.ddl-auto or set it to validate. Use schema-*.sql file or better Flyway or Liquibase.
Description: This application is an example of using schema-*.sql to generate two databases in MySQL. The databases are matched at entity mapping via @Table.
Key points:
application.properties, set the JDBC URL without the database, e.g., spring.datasource.url=jdbc:mysql://localhost:3306application.properties, disable DDL auto (just don't specify hibernate.ddl-auto)aaplication.properties, instruct Spring Boot to initialize the schema from schema-mysql.sql fileAuthor entity, specify that the corresponding table (author) is in the database authorsdb via @Table(schema="authorsdb")Book entity, specify that the corresponding table (book) is in the database booksdb via @Table(schema="booksdb")Output example:
Author results in the following SQL: insert into authorsdb.author (age, genre, name) values (?, ?, ?)Book results the following SQL: insert into booksdb.book (isbn, title) values (?, ?)Note: For web-applications, pagination should be the way to go, not streaming. But, if you choose streaming then keep in mind the golden rule: keep th result set as small as posible. Also, keep in mind that the Execution Plan might not be as efficient as when using SQL-level pagination.
Description: This application is an example of streaming the result set via Spring Data and MySQL. This example can be adopted for databases that fetches the entire result set in a single roundtrip causing performance penalties.
Key points:
@Transactional(readOnly=true))Integer.MIN_VALUE (recommended in MySQL))Statement fetch-size to Integer.MIN_VALUE, or add useCursorFetch=true to the JDBC URL and set Statement fetch-size to a positive integer (e.g., 30)createDatabaseIfNotExistNote: For production, don't rely on hibernate.ddl-auto (or counterparts) to export schema DDL to the database. Simply remove (disable) hibernate.ddl-auto or set it to validate. Rely on Flyway or Liquibase.
Description: This application is an example of migrating a MySQL database via Flyway when the database exists (it is created before migration via MySQL specific parameter, createDatabaseIfNotExist=true).
Key points:
pom.xml, add the Flyway dependencyspring.jpa.hibernate.ddl-autoapplication.properties, set the JDBC URL as follows: jdbc:mysql://localhost:3306/bookstoredb?createDatabaseIfNotExist=trueclasspath:db/migrationV1.1__Description.sql, V1.2__Description.sql, ...spring.flyway.schemasNote: For production, don't rely on hibernate.ddl-auto (or counterparts) to export schema DDL to the database. Simply remove (disable) hibernate.ddl-auto or set it to validate. Rely on Flyway or Liquibase.
Description: This application is an example of migrating a MySQL database when the database is created by Flyway via spring.flyway.schemas. In this case, the entities should be annotated with @Table(schema = "bookstoredb") or @Table(catalog = "bookstoredb"). Here, the database name is bookstoredb.
Key points:
pom.xml, add the Flyway dependencyspring.jpa.hibernate.ddl-autoapplication.properties, set the JDBC URL as follows: jdbc:mysql://localhost:3306/application.properties, add spring.flyway.schemas=bookstoredb, where bookstoredb is the database that should be created by Flyway (feel free to add your own database name)@Table(schema/catalog = "bookstoredb")classpath:db/migrationV1.1__Description.sql, V1.2__Description.sql, ...Output of migration history example:

| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
|
Note: For production don't rely on hibernate.ddl-auto to create your schema. Remove (disable) hibernate.ddl-auto or set it to validate. Rely on Flyway or Liquibase.
Description: This application is an example of auto-creating and migrating schemas for MySQL and PostgreSQL. In addition, each data source uses its own HikariCP connection pool. In case of MySQL, where schema=database, we auto-create the schema (authorsdb) based on createDatabaseIfNotExist=true. In case of PostgreSQL, where a database can have multiple schemas, we use the default postgres database and auto-create in it the schema, booksdb. For this we rely on Flyway, which is capable to create a missing schema.
Key points:
pom.xml, add the Flyway dependencyspring.jpa.hibernate.ddl-auto or set it to validateapplication.properties, configure the JDBC URL for MySQL as, jdbc:mysql://localhost:3306/authorsdb?createDatabaseIfNotExist=true and for PostgreSQL as, jdbc:postgresql://localhost:5432/postgres?currentSchema=booksdbapplication.properties, set spring.flyway.enabled=false to disable default behaviorDataSource for MySQL and one for PostgreSQLFlywayDataSource for MySQL and one for PostgreSQLEntityManagerFactory for MySQL and one for PostgreSQLdbmigrationmysqldbmigrationpostgresqlNote: For production, don't rely on hibernate.ddl-auto (or counterparts) to export schema DDL to the database. Simply remove (disable) hibernate.ddl-auto or set it to validate. Rely on Flyway or Liquibase.
Description: This application is an example of auto-creating and migrating two schemas in PostgreSQL using Flyway. In addition, each data source uses its own HikariCP connection pool. In case of PostgreSQL, where a database can have multiple schemas, we use the default postgres database and auto-create two schemas, authors and books. For this we rely on Flyway, which is capable to create the missing schemas.
Key points:
pom.xml, add the Flyway dependencyspring.jpa.hibernate.ddl-auto or set it to validateapplication.properties, configure the JDBC URL for books as jdbc:postgresql://localhost:5432/postgres?currentSchema=books and for authors as jdbc:postgresql://localhost:5432/postgres?currentSchema=authorsapplication.properties, set spring.flyway.enabled=false to disable default behaviorDataSource, one for books and one for authorsFlywayDataSource, one for books and one for authorsEntityManagerFactory, one for books and one for authorsbooks, place the migration SQLs files in dbmigrationbooksauthors, place the migration SQLs files in dbmigrationauthorsJOIN FETCH an @ElementCollectionDescription: This application is an example applying JOIN FETCH to fetch an @ElementCollection.
Key points:
@ElementCollection is loaded lazy, keep it lazyJOIN FETCH in the repository@Subselect) in a Spring Boot ApplicationNote: Consider using @Subselect only if using DTO, DTO and extra queries, or map a database view to an entity is not a solution.
Description: This application is an example of mapping an entity to a query via Hibernate, @Subselect. Mainly, we have two entities in a bidirectional one-to-many association. An Author has wrote several Book. The idea is to write a read-only query to fetch from Author only some fields (e.g., DTO), but to have the posibility to call getBooks() and fetch the Book in a lazy manner as well. As you know, a classic DTO cannot be used, since such DTO is not managed and we cannot navigate the associations (don’t support any managed associations to other entities). Via Hibernate @Subselect we can map a read-only and immutable entity to a query. This time, we can lazy navigate the associations.
Key points:
Author (including association to Book)@Immutable since no write operations are allowed@Synchronize@Subselect to write the needed query, map an entity to an SQL queryDescription: This application is an example of using Hibernate soft deletes in a Spring Boot application.
Key points:
abstract class BaseEntity with a field named deletedAuthor and Book entities) that should take advantage of soft deletes should extend BaseEntity@Where annotation like this: @Where(clause = "deleted = false")@SQLDelete annotation to trigger UPDATE SQLs in place of DELETE SQLs, as follows: @SQLDelete(sql = "UPDATE author SET deleted = true WHERE id = ?")Output example:

DataSourceBuilderIf you use the spring-boot-starter-jdbc or spring-boot-starter-data-jpa "starters", you automatically get a dependency to HikariCP
Note: The best way to tune the connection pool parameters consist in using Flexy Pool by Vlad Mihalcea. Via Flexy Pool you can find the optim settings that sustain high-performance of your connection pool.
Description: This is a kickoff application that set up HikariCP via DataSourceBuilder. The jdbcUrl is set up for a MySQL database. For testing purposes, the application uses an ExecutorService for simulating concurrent users. Check the HickariCP report revealing the connection pool status.
Key points:
@Bean that returns the DataSource programmaticallyDescription: Auditing is useful for maintaining history records. This can later help us in tracking user activities.
Key points:
abstract base entity (e.g., BaseEntity) and annotate it with @MappedSuperclass and @EntityListeners({AuditingEntityListener.class})@CreatedDate protected LocalDateTime created;@LastModifiedDate protected LocalDateTime lastModified;@CreatedBy protected U createdBy;@LastModifiedBy protected U lastModifiedBy;@EnableJpaAuditing(auditorAwareRef = "auditorAware")AuditorAware (this is needed for persisting the user that performed the modification; use Spring Security to return the currently logged-in user)@Beanspring.jpa.hibernate.ddl-auto=create)Description: Auditing is useful for maintaining history records. This can later help us in tracking user activities.
Key points:
@Audited@AuditTable to rename the table used for auditingValidityAuditStrategy for fast database reads, but slower writes (slower than the default DefaultAuditStrategy)Description: By default, the attributes of an entity are loaded eager (all at once). This application is an alternative to How To Use Hibernate Attribute Lazy Loading from here. This application uses a base class to isolate the attributes that should be loaded eagerly and subentities (entities that extends the base class) for isolating the attributes that should be loaded on demand.
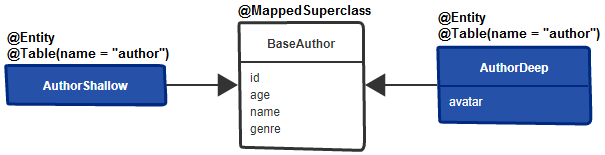
Key points:
BaseAuthor, and annotate it with @MappedSuperclassAuthorShallow subentity of BaseAuthor and don't add any attribute in it (this will inherit the attributes from the superclass)AuthorDeep subentity of BaseAuthor and add to it the attributes that should be loaded on demand (e.g., avatar)@Table(name = "author")AuthorShallowRepository and AuthorDeepRepositoryRun the following requests (via BookstoreController):
localhost:8080/authors/shallowlocalhost:8080/authors/deepCheck as well:
Description: Fetching more data than needed is prone to performance penalities. Using DTO allows us to extract only the needed data. In this application we rely on constructor and Spring Data Query Builder Mechanism.
Key points:
See also:
Dto Via Constructor Expression and JPQL
| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
|
JOINDescription: Using JOIN is very useful for fetching DTOs (data that is never modified, not in the current or subsequent requests). For example, consider two entities, Author and Book in a lazy-bidirectional @OneToMany association. And, we want to fetch a subset of columns from the parent table (author) and a subset of columns from the child table (book). This job is a perfect fit for JOIN which can pick up columns from different tables and build a raw result set. This way we fetch only the needed data. Moreover, we may want to serve the result set in pages (e.g., via LIMIT). This application contains several approaches for accomplishing this task with offset pagination.
Key points:
Page (with SELECT COUNT and COUNT(*) OVER() window function)Slice and ListDENSE_RANK() for avoiding the truncation of the result set (an author can be fetched with only a subset of his books)LEFT JOIN FETCHSee also:
Description: Let's assume that we have two entities engaged in a one-to-many (or many-to-many) lazy bidirectional (or unidirectional) relationship (e.g., Author has more Book). And, we want to trigger a single SELECT that fetches all Author and the corresponding Book. This is a job for JOIN FETCH which is converted behind the scene into a INNER JOIN. Being an INNER JOIN, the SQL will return only Author that have Book. If we want to return all Author, including those that doesn't have Book, then we can rely on LEFT JOIN FETCH. Similar, we can fetch all Book, including those with no registered Author. This can be done via LEFT JOIN FETCH or LEFT JOIN.
Key points:
Author and Book in a one-to-many lazy bidirectional relationship)LEFT JOIN FETCH to fetch all authors and books (fetch authors even if they don't have registered books)LEFT JOIN FETCH to fetch all books and authors (fetch books even if they don't have registered authors)JOIN VS. JOIN FETCHSee also:
Description: This is an application meant to reveal the differences between JOIN and JOIN FETCH. The important thing to keep in mind is that, in case of LAZY fetching, JOIN will not be capable to initialize the associated collections along with their parent objects using a single SQL SELECT. On the other hand, JOIN FETCH is capable to accomplish this kind of task. But, don't underestimate JOIN, because JOIN is the proper choice when we need to combine/join the columns of two (or more) tables in the same query, but we don't need to initialize the associated collections on the returned entity (e.g., very useful for fetching DTO).
Key points:
Author and Book in a one-to-many lazy-bidirectional relationship)JOIN and JOIN FETCH to fetch an author including his booksJOIN to fetch a book (1)JOIN to fetch a book including its author (2)JOIN FETCH to fetch a book including its authorNotice that:
JOIN, fetching Book of Author requires additional SELECT statements being prone to N+1 performance penaltyJOIN (1), fetching Author of Book requires additional SELECT statements being prone to N+1 performance penaltyJOIN (2), fetching Author of Book works exactly as JOIN FETCH (requires a single SELECT)JOIN FETCH, fetching each Author of a Book requires a single SELECTDescription: If, for some reason, you need an entity in your Spring projection (DTO), then this application shows you how to do it via an example. In this case, there are two entities, Author and Book, involved in a lazy bidirectional one-to-many association (it can be other association as well, or even no materialized association). And, we want to fetch in a Spring projection the authors as entities, Author, and the title of the books.
Key points:
Author and Book in a one-to-many lazy bidirectional relationship)public Author getAuthor() and public String getTitle()Description: If, for some reason, you need an entity in your Spring projection (DTO), then this application shows you how to do it via an example. In this case, there are two entities, Author and Book, that have no materialized association between them, but, they share the genre attribute. We use this attribute to join authors with books via JPQL. And, we want to fetch in a Spring projection the authors as entities, Author, and the title of the books.
Key points:
Author and Book)public Author getAuthor() and public String getTitle()Description: Let's assume that we have two entities, Author and Book. There is no materialized association between them, but, both entities shares an attribute named, genre. We want to use this attribute to join the tables corresponding to Author and Book, and fetch the result in a DTO. The result should contain the Author entity and only the title attribute from Book. Well, when you are in a scenario as here, it is strongly advisable to avoid fetching the DTO via constructor expression. This approach cannot fetch the data in a single SELECT, and is prone to N+1. Way better than this consists of using Spring projections, JPA Tuple or even Hibernate ResultTransformer. These approaches will fetch the data in a single SELECT. This application is a DON'T DO THIS example. Check the number of queries needed for fetching the data. In place, do it as here: Entity Inside Spring Projection (no association).
@ElementCollectionDescription: This application is an example of fetching a DTO that includes attributes from an @ElementCollection.
Key points:
@ElementCollection is loaded lazy, keep it lazyJOIN in the repositorySet Of Associated Entities In @ManyToMany Association Via @OrderByDescription: In case of @ManyToMany association, we always should rely on Set (not on List) for mapping the collection of associated entities (entities of the other parent-side). Why? Well, please see Prefer Set Instead of List in @ManyToMany Relationships. But, is well-known that HashSet doesn't have a predefined entry order of elements. If this is an issue then this application relies on @OrderBy which adds an ORDER BY clause in the SQL statement. The database will handle the ordering. Further, Hibernate will preserve the order via a LinkedHashSet.
This application uses two entities, Author and Book, involved in a lazy bidirectional many-to-many relationship. First, we fetch a Book by title. Further, we call getAuthors() to fetch the authors of this book. The fetched authors are ordered descending by name. The ordering is done by the database as a result of adding @OrderBy("name DESC"), and is preserved by Hibernate.
Key points:
@OrderByHashSet, but doesn't provide consistency across all transition states (e.g., transient state)LinkedHashSet instead of HashSetNote: Alternatively, we can use @OrderColumn. This gets materialized in an additional column in the junction table. This is needed for maintaining a permanent ordering of the related data.
Description: This is a sample application that shows how versioned (@Version) optimistic locking and detached entity works. Running the application will result in an optimistic locking specific exception (e.g., the Spring Boot specific, OptimisticLockingFailureException).
Key points:
findById(1L); commit transaction and close the Persistence ContextfindById(1L) and update it; commit the transaction and close the Persistence Contextsave() and pass to it the detached entity; trying to merge (EntityManager.merge()) the entity will end up in an optimistic locking exception since the version of the detached and just loaded entity don't matchOptimisticLockException Shaped Via @VersionNote: Optimistic locking via @Version works for detached entities as well.
Description: This is a Spring Boot application that simulates a scenario that leads to an optimistic locking exception. So, running the application should end up with a Spring specific ObjectOptimisticLockingFailureException exception.
Key points:
@Transactional method used for updating data| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
|
TransactionTemplate After OptimisticLockException Exception (@Version)Note: Optimistic locking via @Version works for detached entities as well.
Description: This is a Spring Boot application that simulates a scenario that leads to an optimistic locking exception. When such exception occurs, the application retry the corresponding transaction via db-util library developed by Vlad Mihalcea.
Key points:
pom.xml, add the db-util dependencyOptimisticConcurrencyControlAspect beanTransactionTemplateOptimisticLockException In Version-less Optimistic LockingNote: Version-less optimistic locking doesn't work for detached entities (do not close the Persistence Context).
Description: This is a Spring Boot application that simulates a scenario that leads to an optimistic locking exception. So, running the application should end up with a Spring specific ObjectOptimisticLockingFailureException exception.
Key points:
@Transactional method used for updating dataTransactionTemplate After OptimisticLockException Shaped Via Hibernate Version-less Optimistic Locking MechanismNote: Version-less optimistic locking doesn't work for detached entities (do not close the Persistence Context).
Description: This is a Spring Boot application that simulates a scenario that leads to an optimistic locking exception. When such exception occur, the application retry the corresponding transaction via db-util library developed by Vlad Mihalcea.
Key points:
pom.xml, add the db-util dependencyOptimisticConcurrencyControlAspect beanTransactionTemplateDescription: This is a sample application that shows how to take advantage of versioned optimistic locking and detached entities in HTTP long conversations. The climax consists of storing the detached entities across multiple HTTP requests. Commonly, this can be accomplished via HTTP session.
Key points:
@Version@SessionAttributes for storing the detached entitiesSample output (check the message caused by optimistic locking exception):
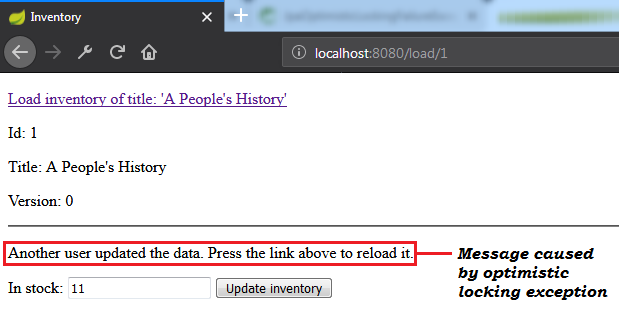
@WhereNote: Rely on this approach only if you simply cannot use JOIN FETCH WHERE or @NamedEntityGraph.
Description: This application is a sample of using Hibernate @Where for filtering associations.
Key points:
@Where(clause = "condition to be met") in entity (check the Author entity)Description: Batch inserts (in MySQL) in Spring Boot style.
Key points:
application.properties set spring.jpa.properties.hibernate.jdbc.batch_sizeapplication.properties set spring.jpa.properties.hibernate.generate_statistics (just to check that batching is working)application.properties set JDBC URL with rewriteBatchedStatements=true (optimization for MySQL)application.properties set JDBC URL with cachePrepStmts=true (enable caching and is useful if you decide to set prepStmtCacheSize, prepStmtCacheSqlLimit, etc as well; without this setting the cache is disabled)application.properties set JDBC URL with useServerPrepStmts=true (this way you switch to server-side prepared statements (may lead to signnificant performance boost))spring.jpa.properties.hibernate.order_inserts=true to optimize the batching by ordering insertsIDENTITY will cause insert batching to be disabledspring.jpa.properties.hibernate.cache.use_second_level_cache=falseOutput example:

COUNT(*) OVER And Return Page<entity> Via Extra ColumnDescription: Typically, in offset pagination, there is one query needed for fetching the data and one for counting the total number of records. But, we can fetch this information in a single database rountrip via a SELECT COUNT subquery nested in the main SELECT. Even better, for databases vendors that support Window Functions there is a solution relying on COUNT(*) OVER() as in this application that uses this window function in a native query against MySQL 8. So, prefer this one instead of SELECT COUNT subquery.This application fetches data as Page<entity> via Spring Boot offset pagination, but, if the fetched data is read-only, then rely on Page<dto> as here.
Key points:
PagingAndSortingRepository@Column(insertable = false, updatable = false)List<entity>List<entity> and Pageable to create a Page<entity>SELECT COUNT Subquery And Return List<entity> Via Extra ColumnDescription: This application fetches data as List<entity> via Spring Boot offset pagination. The SELECT COUNT triggered for counting the total number of records is a subquery of the main SELECT. Therefore, there will be a single database roundtrip instead of two (typically, one query is needed for fetching the data and one for counting the total number of records).
Key points:
PagingAndSortingRepositoryentity, add an extra column for representing the total number of records and annotate it as @Column(insertable = false, updatable = false)SELECT COUNT subquery) into a List<entity>SELECT COUNT Subquery And Return List<projection> That Maps Entities And The Total Number Of Records Via ProjectionDescription: This application fetches data as List<projection> via Spring Boot offset pagination. The projection maps the entity and the total number of records. This information is fetched in a single database rountrip because the SELECT COUNT triggered for counting the total number of records is a subquery of the main SELECT. Therefore, there will be a single database roundtrip instead of two (typically, there is one query needed for fetching the data and one for counting the total number of records). Use this approch only if the fetched data is not read-only. Otherwise, prefer List<dto> as here.
Key points:
PagingAndSortingRepositorySELECT COUNT subquery) into a List<projection>COUNT(*) OVER And Return List<entity> Via Extra ColumnDescription: Typically, in offset pagination, there is one query needed for fetching the data and one for counting the total number of records. But, we can fetch this information in a single database rountrip via a SELECT COUNT subquery nested in the main SELECT. Even better, for databases vendors that support Window Functions there is a solution relying on COUNT(*) OVER() as in this application that uses this window function in a native query against MySQL 8. So, prefer this one instead of SELECT COUNT subquery.This application fetches data as List<entity> via Spring Boot offset pagination, but, if the fetched data is read-only, then rely on List<dto> as here.
Key points:
PagingAndSortingRepositoryentity, add an extra column for representing the total number of records and annotate it as @Column(insertable = false, updatable = false)COUNT(*) OVER subquery) into a List<entity>| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
|
SELECT COUNT Subquery And Return Page<entity> Via Extra ColumnDescription: This application fetches data as Page<entity> via Spring Boot offset pagination. Use this only if the fetched data will be modified. Otherwise, fetch Page<dto> as here. The SELECT COUNT triggered for counting the total number of records is a subquery of the main SELECT. Therefore, there will be a single database roundtrip instead of two (typically, there is one query needed for fetching the data and one for counting the total number of records).
Key points:
PagingAndSortingRepository@Column(insertable = false, updatable = false)List<entity>List<entity> and Pageable to create a Page<entity>SELECT COUNT Subquery And Return Page<projection> That Maps Entities And The Total Number Of Records Via ProjectionDescription: This application fetches data as Page<projection> via Spring Boot offset pagination. The projection maps the entity and the total number of records. This information is fetched in a single database rountrip because the SELECT COUNT triggered for counting the total number of records is a subquery of the main SELECT.
Key points:
PagingAndSortingRepositoryList<projection>List<projection> and Pageable to create a Page<projection>COUNT(*) OVER And Return Page<dto>Description: Typically, in offset pagination, there is one query needed for fetching the data and one for counting the total number of records. But, we can fetch this information in a single database rountrip via a SELECT COUNT subquery nested in the main SELECT. Even better, for databases vendors that support Window Functions there is a solution relying on COUNT(*) OVER() as in this application that uses this window function in a native query against MySQL 8. So, prefer this one instead of SELECT COUNT subquery. This application return a Page<dto>.
Key points:
PagingAndSortingRepositoryList<dto>List<dto> and Pageable to create a Page<dto>Example:
Slice<entity>/Slice<dto> Via fetchAll/fetchAllDtoStory: Spring Boot provides an offset based built-in paging mechanism that returns a Page or Slice. Each of these APIs represents a page of data and some metadata. The main difference is that Page contains the total number of records, while Slice can only tell if there is another page available. For Page, Spring Boot provides a findAll() method capable to take as arguments a Pageable and/or a Specification or Example. In order to create a Page that contains the total number of records, this method triggers an SELECT COUNT extra-query next to the query used to fetch the data of the current page . This can be a performance penalty since the SELECT COUNT query is triggered every time we request a page. In order to avoid this extra-query, Spring Boot provides a more relaxed API, the Slice API. Using Slice instead of Page removes the need of this extra SELECT COUNT query and returns the page (records) and some metadata without the total number of records. So, while Slice doesn't know the total number of records, it still can tell if there is another page available after the current one or this is the last page. The problem is that Slice work fine for queries containing the SQL, WHERE clause (including those that uses the query builder mechanism built into Spring Data), but it doesn't work for findAll(). This method will still return a Page instead of Slice therefore the SELECT COUNT query is triggered for Slice<T> findAll(...);.
Workaround:
The trick is to simply define a method named fetchAll() that uses JPQL and Pageable to return Slice<entity>, and a method named fetchAllDto() that uses JPQL and Pageable as well to return Slice<dto>. So, avoid naming the method findAll().
Usage example:
public Slice<Author> fetchNextSlice(int page, int size) {
return authorRepository.fetchAll(PageRequest.of(page, size, new Sort(Sort.Direction.ASC, "age")));
}
public Slice<AuthorDto> fetchNextSliceDto(int page, int size) {
return authorRepository.fetchAllDto(PageRequest.of(page, size, new Sort(Sort.Direction.ASC, "age")));
}

Description: This application is a proof of concept for using Spring Projections(DTO) and inclusive full joins written in native SQL (for MySQL).
Key points:
Author and Book in a lazy bidirectional @OneToMany relationship)resources/data-mysql.sql)AuthorNameBookTitle.java)EhCache)Description: This application is a sample of declaring an immutable entity. Moreover, the immutable entity will be stored in Second Level Cache via EhCache implementation.
Key points of declaring an immutable entity:
@Immutable (org.hibernate.annotations.Immutable)hibernate.cache.use_reference_entries configuration to trueDataSourceBuilderIf you use the spring-boot-starter-jdbc or spring-boot-starter-data-jpa "starters", you automatically get a dependency to HikariCP
Note: The best way to tune the connection pool parameters consist in using Flexy Pool by Vlad Mihalcea. Via Flexy Pool you can find the optim settings that sustain high-performance of your connection pool.
Description: This is a kickoff application that set up HikariCP via DataSourceBuilder. The jdbcUrl is set up for a MySQL database. For testing purposes, the application uses an ExecutorService for simulating concurrent users. Check the HickariCP report revealing the connection pool status.
Key points:
@Bean that returns the DataSource programmaticallyOutput sample:
@NaturalIdCache For Skipping The Entity Identifier RetrievalDescription: This is a SpringBoot - MySQL application that maps a natural business key using Hibernate @NaturalId. This implementation allows us to use @NaturalId as it was provided by Spring. Moreover, this application uses Second Level Cache (EhCache) and @NaturalIdCache for skipping the entity identifier retrieval from the database.
Key points:
EhCache)@NaturalIdCache for caching natural ids@Cache(usage = CacheConcurrencyStrategy.READ_WRITE, region = "Book") for caching entites as wellOutput sample (for MySQL with IDENTITY generator, @NaturalIdCache and @Cache):

@PostLoadDescription: This application is an example of calculating a non-persistent property of an entity based on the persistent entity attributes. In this case, we will use JPA, @PostLoad.
Key points:
@Transient@PostLoad that calculates this non-persistent property based on the persistent entity attributes@GeneratedDescription: This application is an example of calculating an entity persistent property at INSERT and/or UPDATE time via Hibernate, @Generated.
Key points:
Calculate at INSERT time:
@Generated(value = GenerationTime.INSERT)@Column(insertable = false)Calculate at INSERT and UPDATE time:
@Generated(value = GenerationTime.ALWAYS)@Column(insertable = false, updatable = false)Further, apply:
Method 1:
columnDefinition element of @Column to specify as an SQL query expression the formula for calculating the persistent propertyMethod 2:
CREATE TABLENote: In production, you should not rely on columnDefinition. You should disable hibernate.ddl-auto (by omitting it) or set it to validate, and add the SQL query expression in CREATE TABLE (in this application, check the discount column in CREATE TABLE, file schema-sql.sql). Nevertheless, not even schema-sql.sql is ok in production. The best way is to rely on Flyway or Liquibase.
| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
|
@FormulaDescription: This application is an example of calculating a non-persistent property of an entity based on the persistent entity attributes. In this case, we will use Hibernate, @Formula.
Key points:
@Transient@Formula@Formula add the SQL query expression that calculates this non-persistent property based on the persistent entity attributescreated, createdBy, lastModified And lastModifiedBy In Entities Via HibernateNote: The same thing can be obtained via Spring Data JPA auditing as here.
Description: This application is an example of adding in an entity the fields, created, createdBy, lastModified and lastModifiedBy via Hibernate support. These fields will be automatically generated/populated.
Key points:
abstract class (e.g., BaseEntity) annotated with @MappedSuperclassabstract class, define a field named created and annotate it with the built-in @CreationTimestamp annotationabstract class, define a field named lastModified and annotate it with the built-in @UpdateTimestamp annotationabstract class, define a field named createdBy and annotate it with the @CreatedBy annotationabstract class, define a field named lastModifiedBy and annotate it with the @ModifiedBy annotation@CreatedBy annotation via AnnotationValueGeneration@ModifiedBy annotation via AnnotationValueGenerationcreated, createdBy, lastModified and lastModifiedBy will extend the BaseEntityschema-mysql.sql)Description: Auditing is useful for maintaining history records. This can later help us in tracking user activities.
Key points:
@Audited@AuditTable to rename the table used for auditingValidityAuditStrategy for fast database reads, but slower writes (slower than the default DefaultAuditStrategy)spring.jpa.hibernate.ddl-auto or set it to validate for avoiding schema generated from JPA annotationsschema-mysql.sql and provide the SQL statements needed by Hibernate Enversspring.jpa.properties.org.hibernate.envers.default_catalog for MySQL or spring.jpa.properties.org.hibernate.envers.default_schema for the restDataSourceNote: For production, don't rely on hibernate.ddl-auto (or counterparts) to export schema DDL to the database. Simply remove (disable) hibernate.ddl-auto or set it to validate. Rely on Flyway or Liquibase.
Description: This application is a kickoff for setting Flyway and MySQL DataSource programmatically.
Key points:
pom.xml, add the Flyway dependencyspring.jpa.hibernate.ddl-auto or set it to validateDataSource and Flyway programmaticallypostgres And Schema publicNote: For production, don't rely on hibernate.ddl-auto (or counterparts) to export schema DDL to the database. Simply remove (disable) hibernate.ddl-auto or set it to validate. Rely on Flyway or Liquibase.
Description: This application is an example of migrating a PostgreSQL database via Flyway for the default database postgres and schema public.
Key points:
pom.xml, add the Flyway dependencyspring.jpa.hibernate.ddl-auto or set it to validateapplication.properties, set the JDBC URL as follows: jdbc:postgresql://localhost:5432/postgresclasspath:db/migrationV1.1__Description.sql, V1.2__Description.sql, ...postgres And Schema Created Via spring.flyway.schemasNote: For production, don't rely on hibernate.ddl-auto (or counterparts) to export schema DDL to the database. Simply remove (disable) hibernate.ddl-auto or set it to validate. Rely on Flyway or Liquibase.
Description: This application is an example of migrating a schema (bookstore) created by Flyway via spring.flyway.schemas in the default postgres database. In this case, the entities should be annotated with @Table(schema = "bookstore").
Key points:
pom.xml, add the Flyway dependencyspring.jpa.hibernate.ddl-auto or set it to validateapplication.properties, set the JDBC URL as follows: jdbc:postgresql://localhost:5432/postgresapplication.properties, add spring.flyway.schemas=bookstore, where bookstore is the schema that should be created by Flyway in the postgres database (feel free to add your own database name)@Table(schema = "bookstore")classpath:db/migrationV1.1__Description.sql, V1.2__Description.sql, ...DataSourceNote: For production, don't rely on hibernate.ddl-auto (or counterparts) to export schema DDL to the database. Simply remove (disable) hibernate.ddl-auto or set it to validate. Rely on Flyway or Liquibase.
Description: This application is a kickoff for setting Flyway and PostgreSQL DataSource programmatically.
Key points:
pom.xml, add the Flyway dependencyspring.jpa.hibernate.ddl-auto or set it to validateDataSource and Flyway programmaticallyNote: For production, don't rely on hibernate.ddl-auto (or counterparts) to export schema DDL to the database. Simply remove (disable) hibernate.ddl-auto or set it to validate. Rely on Flyway or Liquibase.
Description: This application is an example of auto-creating and migrating two databases in MySQL using Flyway. In addition, each data source uses its own HikariCP connection pool. In case of MySQL, where a database is the same thing with schema, we create two databases, authorsdb and booksdb.
Key points:
pom.xml, add the Flyway dependencyspring.jpa.hibernate.ddl-auto or set it to validateapplication.properties, configure the JDBC URL for booksdb as jdbc:mysql://localhost:3306/booksdb?createDatabaseIfNotExist=true and for authorsdb as jdbc:mysql://localhost:3306/authorsdb?createDatabaseIfNotExist=trueapplication.properties, set spring.flyway.enabled=false to disable default behaviorDataSource, one for booksdb and one for authorsdbFlywayDataSource, one for booksdb and one for authorsdbEntityManagerFactory, one for booksdb and one for authorsdbbooksdb, place the migration SQLs files in dbmigrationbooksdbauthorsdb, place the migration SQLs files in dbmigrationauthorsdbhi/lo Algorithm And External Systems IssueDescription: This is a Spring Boot sample that exemplifies how the hi/lo algorithm may cause issues when the database is used by external systems as well. Such systems can safely generate non-duplicated identifiers (e.g., for inserting new records) only if they know about the hi/lo presence and its internal work. So, better rely on pooled or pooled-lo algorithm which doesn't cause such issues.
Key points:
SEQUENCE generator type (e.g., in PostgreSQL)hi/lo algorithm as in Author.java entityhi/loNEXTVAL('hilo_sequence') and is not aware of hi/lo presence and/or behavior)Output sample: Running this application should result in the following error:
ERROR: duplicate key value violates unique constraint "author_pkey"
Detail: Key (id)=(2) already exists.
pooled AlgorithmNote: Rely on pooled-lo or pooled especially if, beside your application, external systems needs to insert rows in your tables. Don't rely on hi/lo since, in such cases, it may cause errors resulted from generating duplicated identifiers.
Description: This is a Spring Boot example of using the pooled algorithm. The pooled is an optimization of hi/lo. This algorithm fetched from the database the current sequence value as the top boundary identifier (the current sequence value is computed as the previous sequence value + increment_size). This way, the application will use in-memory identifiers generated between the previous top boundary exclusive (aka, lowest boundary) and the current top boundary inclusive.
Key points:
SEQUENCE generator type (e.g., in PostgreSQL)pooled algorithm as in Author.java entitypooledNEXTVAL('hilo_sequence') and is not aware of pooled presence and/or behavior)Conclusion: In contrast to the classical hi/lo algorithm, the Hibernate pooled algorithm doesn't cause issues to external systems that wants to interact with our tables. In other words, external systems can concurrently insert rows in the tables relying on pooled algorithm. Nevertheless, old versions of Hibernate can raise exceptions caused by INSERT statements triggered by external systems that uses the lowest boundary as identifier. This is a good reason to update to Hibernate latest versions (e.g., Hibernate 5.x), which have fixed this issue.
| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
|
pooled-lo AlgorithmNote: Rely on pooled-lo or pooled especially if, beside your application, external systems needs to insert rows in your tables. Don't rely on hi/lo since, in such cases, it may cause errors resulted from generating duplicated identifiers.
Description: This is a Spring Boot example of using the pooled-lo algorithm. The pooled-lo is an optimization of hi/lo similar with pooled. Only that, the strategy of this algorithm fetches from the database the current sequence value and use it as the in-memory lowest boundary identifier. The number of in-memory generated identifiers is equal to increment_size.
Key points:
SEQUENCE generator type (e.g., in PostgreSQL)pooled-lo algorithm as in Author.java entitypooled-loNEXTVAL('hilo_sequence') and is not aware of pooled-lo presence and/or behavior)@BatchSizeDescription: This application uses Hibernate specific @BatchSize at class/entity-level and collection-level. Consider Author and Book entities invovled in a bidirectional-lazy @OneToMany association.
First use case fetches all Author entities via a SELECT query. Further, calling the getBooks() method of the first Author entity will trigger another SELECT query that initializes the collections of the first three Author entities returned by the previous SELECT query. This is the effect of @BatchSize at Author's collection-level.
Second use case fetches all Book entities via a SELECT query. Further, calling the getAuthor() method of the first Book entity will trigger another SELECT query that initializes the authors of the first three Book entities returned by the previous SELECT query. This is the effect of @BatchSize at Author class-level.
Note: Fetching associated collections in the same query with their parent can be done via JOIN FETCH or entity graphs as well. Fetching children with their parents in the same query can be done via JOIN FETCH, entity graphs and JOIN as well.
Key points:
Author and Book are in a lazy relationship (e.g., @OneToMany bidirectional relationship)Author entity is annotated with @BatchSize(size = 3)Author's collection is annotated with @BatchSize(size = 3)@NamedEntityGraph) In Spring BootNote: In a nutshell, entity graphs (aka, fetch plans) is a feature introduced in JPA 2.1 that help us to improve the performance of loading entities. Mainly, we specify the entity’s related associations and basic fields that should be loaded in a single SELECT statement. We can define multiple entity graphs for the same entity and chain any number of entities and even use sub-graphs to create complex fetch plans. To override the current FetchType semantics there are properties that can be set:
Fetch Graph (default), javax.persistence.fetchgraph
The attributes present in attributeNodes are treated as FetchType.EAGER. The remaining attributes are treated as FetchType.LAZY regardless of the default/explicit FetchType.
Load Graph, javax.persistence.loadgraph
The attributes present in attributeNodes are treated as FetchType.EAGER. The remaining attributes are treated according to their specified or default FetchType.
Nevertheless, the JPA specs doesn't apply in Hibernate for the basic (@Basic) attributes.. More details here.
Description: This is a sample application of using entity graphs in Spring Boot.
Key points:
Author and Book, involved in a lazy bidirectional @OneToMany associationAuthor entity use the @NamedEntityGraph to define the entity graph (e.g., load in a single SELECT the authors and the associatated books)AuthorRepositry rely on Spring @EntityGraph annotation to indicate the entity graph defined at the previous stepNote: In a nutshell, entity graphs (aka, fetch plans) is a feature introduced in JPA 2.1 that help us to improve the performance of loading entities. Mainly, we specify the entity’s related associations and basic fields that should be loaded in a single SELECT statement. We can define multiple entity graphs for the same entity and chain any number of entities and even use sub-graphs to create complex fetch plans. To override the current FetchType semantics there are properties that can be set:
Fetch Graph (default), javax.persistence.fetchgraph
The attributes present in attributeNodes are treated as FetchType.EAGER. The remaining attributes are treated as FetchType.LAZY regardless of the default/explicit FetchType.
Load Graph, javax.persistence.loadgraph
The attributes present in attributeNodes are treated as FetchType.EAGER. The remaining attributes are treated according to their specified or default FetchType.
Nevertheless, the JPA specs doesn't apply in Hibernate for the basic (@Basic) attributes.. More details here.
Description: This is a sample application of using entity sub-graphs in Spring Boot. There is one example based on @NamedSubgraph and one based on the dot notation (.) in an ad-hoc entity graph.
Key points:
Author, Book and Publisher (Author and Book are involved in a lazy bidirectional @OneToMany relationship, Book and Publisher are also involved in a lazy bidirectional @OneToMany relationship; between Author and Publisher there is no relationship)Using @NamedSubgraph
Author entity define an entity graph via @NamedEntityGraph; load the authors and the associatated books and use @NamedSubgraph to define a sub-graph for loading the publishers associated with these booksAuthorRepository rely on Spring @EntityGraph annotation to indicate the entity graph defined at the previous stepUsing the dot notation (.)
PublisherRepository define an ad-hoc entity graph that fetches all publishers with associated books, and further, the authors associated with these books (e.g., @EntityGraph(attributePaths = {"books.author"}).Note: In a nutshell, entity graphs (aka, fetch plans) is a feature introduced in JPA 2.1 that help us to improve the performance of loading entities. Mainly, we specify the entity’s related associations and basic fields that should be loaded in a single SELECT statement. We can define multiple entity graphs for the same entity and chain any number of entities and even use sub-graphs to create complex fetch plans. To override the current FetchType semantics there are properties that can be set:
Fetch Graph (default), javax.persistence.fetchgraph
The attributes present in attributeNodes are treated as FetchType.EAGER. The remaining attributes are treated as FetchType.LAZY regardless of the default/explicit FetchType.
Load Graph, javax.persistence.loadgraph
The attributes present in attributeNodes are treated as FetchType.EAGER. The remaining attributes are treated according to their specified or default FetchType.
Nevertheless, the JPA specs doesn't apply in Hibernate for the basic (@Basic) attributes.. More details here.
Description: This is a sample application of defining ad-hoc entity graphs in Spring Boot.
Key points:
Author and Book, involved in a lazy bidirectional @OneToMany relationshipSELECT the authors and the associatated booksAuthorRepository rely on Spring @EntityGraph(attributePaths = {"books"}) annotation to indicate the ad-hoc entity graph@Basic Attributes In Hibernate And Spring BootNote: In a nutshell, entity graphs (aka, fetch plans) is a feature introduced in JPA 2.1 that help us to improve the performance of loading entities. Mainly, we specify the entity’s related associations and basic fields that should be loaded in a single SELECT statement. We can define multiple entity graphs for the same entity and chain any number of entities and even use sub-graphs to create complex fetch plans. To override the current FetchType semantics there are properties that can be set:
Fetch Graph (default), javax.persistence.fetchgraph
The attributes present in attributeNodes are treated as FetchType.EAGER. The remaining attributes are treated as FetchType.LAZY regardless of the default/explicit FetchType.
Load Graph, javax.persistence.loadgraph
The attributes present in attributeNodes are treated as FetchType.EAGER. The remaining attributes are treated according to their specified or default FetchType.
Nevertheless, the JPA specs doesn't apply in Hibernate for the basic (@Basic) attributes. In other words, by default, attributes are annotated with @Basic which rely on the default fetch policy. The default fetch policy is FetchType.EAGER. These attributes are also loaded in case of fetch graph even if they are not explicitly specified via @NamedAttributeNode. Annotating the basic attributes that should not be fetched with @Basic(fetch = FetchType.LAZY) it is not enough. Both, fetch graph and load graph will ignore these settings as long as we don't add bytecode enhancement as well.
The main drawback consists of the fact the these basic attributes are fetched LAZY by all other queries (e.g., findById()) not only by the queries using the entity graph, and most probably, you will not want this behavior.
Description: This is a sample application of using entity graphs with @Basic attributes in Spring Boot.
Key points:
Author and Book, involved in a lazy bidirectional @OneToMany associationAuthor entity use the @NamedEntityGraph to define the entity graph (e.g., load the authors names (only the name basic attribute; ignore the rest) and the associatated books)@Basic(fetch = FetchType.LAZY)AuthorRepository rely on Spring @EntityGraph annotation to indicate the entity graph defined at the previous stepSoftDeleteRepository In Spring Boot ApplicationNote: Spring Data built-in support for soft deletes is discussed in DATAJPA-307.
Description: This application is an example of implementing soft deletes in Spring Data style via a repository named, SoftDeleteRepository.
Key points:
abstract class, BaseEntity, annotated with @MappedSuperclassBaseEntity define a flag-field named deleted (default this field to false or in other words, not deleted)BaseEntity classs@NoRepositoryBean named SoftDeleteRepository and extend JpaRepositorySoftDeleteRepositoryOutput example:
SKIP_LOCKED In MySQL 8Description: This application is an example of how to implement concurrent table based queue via SKIP_LOCKED in MySQL 8. SKIP_LOCKED can skip over locks achieved by other concurrent transactions, therefore is a great choice for implementing job queues. In this application, we run two concurrent transactions. The first transaction will lock the records with ids 1, 2 and 3. The second transaction will skip the records with ids 1, 2 and 3 and will lock the records with ids 4, 5 and 6.
Key points:
Book entity)BookRepository setup @Lock(LockModeType.PESSIMISTIC_WRITE)BookRepository use @QueryHint to setup javax.persistence.lock.timeout to SKIP_LOCKEDorg.hibernate.dialect.MySQL8Dialect dialectSKIP_LOCKEDSKIP_LOCKED In PostgreSQLDescription: This application is an example of how to implement concurrent table based queue via SKIP_LOCKED in PostgreSQL. SKIP_LOCKED can skip over locks achieved by other concurrent transactions, therefore is a great choice for implementing job queues. In this application, we run two concurrent transactions. The first transaction will lock the records with ids 1, 2 and 3. The second transaction will skip the records with ids 1, 2 and 3 and will lock the records with ids 4, 5 and 6.
Key points:
Book entity)BookRepository setup @Lock(LockModeType.PESSIMISTIC_WRITE)BookRepository use @QueryHint to setup javax.persistence.lock.timeout to SKIP_LOCKEDorg.hibernate.dialect.PostgreSQL95Dialect dialectSKIP_LOCKEDJOINEDDescription: This application is a sample of JPA Join Table inheritance strategy (JOINED)
Key points:
@Inheritance(strategy=InheritanceType.JOINED)@PrimaryKeyJoinColumn| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
|
TABLE_PER_CLASSDescription: This application is a sample of JPA Table-per-class inheritance strategy (TABLE_PER_CLASS)
Key points:
IDENTITY generator@Inheritance(strategy=InheritanceType.TABLE_PER_CLASS)@MappedSuperclassDescription: This application is a sample of using the JPA @MappedSuperclass.
Key points:
abstract, and is annotated with @MappedSuperclass@MappedSuperclass is the proper alternative to the JPA table-per-class inheritance strategyNote: Hibernate5Module is an add-on module for Jackson JSON processor which handles Hibernate datatypes; and specifically aspects of lazy-loading.
Description: By default, in Spring Boot, the Open Session in View anti-pattern is enabled. Now, imagine a lazy relationship (e.g., @OneToMany) between two entities, Author and Book (an author has associated more books). Next, a REST controller endpoint fetches an Author without the associated Book. But, the View (more precisely, Jackson), forces the lazy loading of the associated Book as well. Since OSIV will supply the already opened Session, the Proxy initializations take place successfully.
Of course, the correct decision is to disable OSIV by setting it to false, but this will not stop Jackson to try to force the lazy initialization of the associated Book entities. Running the code again will result in an exception of type: Could not write JSON: failed to lazily initialize a collection of role: com.bookstore.entity.Author.books, could not initialize proxy - no Session; nested exception is com.fasterxml.jackson.databind.JsonMappingException: failed to lazily initialize a collection of role: com.bookstore.entity.Author.books, could not initialize proxy - no Session.
Well, among the Hibernate5Module features we have support for dealing with this aspect of lazy loading and eliminate this exception. Even if OSIV will continue to be enabled (not recommended), Jackson will not use the Session opened via OSIV.
Key points:
pom.xml@Bean that returns an instance of Hibernate5ModuleAuthor bean with @JsonInclude(Include.NON_EMPTY) to exclude null or what is considered empty from the returned JSONNote: The presence of Hibernate5Module instructs Jackson to initialize the lazy associations with default values (e.g., a lazy associated collection will be initialized with null). Hibernate5Module doesn't work for lazy loaded attributes. For such case consider this item.
profileSQL=true In MySQLDescription: View the prepared statement binding parameters via profileSQL=true in MySQL.
Key points:
application.properties append logger=Slf4JLogger&profileSQL=true to the JDBC URL (e.g., jdbc:mysql://localhost:3306/bookstoredb?createDatabaseIfNotExist=true&logger=Slf4JLogger&profileSQL=true)Output sample:

Description: This application is an example of shuffling small results sets. DO NOT USE this technique for large results sets, since is extremely expensive.
Key points:
SELECT query and append to it ORDER BY RAND()RAND() (e.g., in PostgreSQL is random())Description: Commonly, deleting a parent and the associated children via CascadeType.REMOVE and/or orphanRemoval=true involved several SQL statements (e.g., each child is deleted in a dedicated DELETE statement). When the number of entities is significant, this is far from being efficient, therefore other approaches should be employed.
Consider Author and Book in a bidirectional-lazy @OneToMany association. This application exposes the best way to delete the parent(s) and the associated children in four scenarios listed below. These approaches relies on bulk deletions, therefore they are not useful if you want the deletions to take advantage of automatic optimistic locking mechanisms (e.g., via @Version):
Best way to delete author(s) and the associated books via bulk deletions when:
Author is in Persistent Context, no BookAuthor are in the Persistent Context, no BookAuthor and the associated Book are in Persistent ContextAuthor or Book is in Persistent ContextNote: The most efficient way to delete all entities via a bulk deletion can be done via the built-in deleteAllInBatch().
Description: Bulk operations (updates and deletes) are faster than batching, can benefit from indexing, but they have three main drawbacks:
@Version is ignored), therefore the lost updates are not prevented (it is advisable to signal these updates by explicitly incrementing version (if any is present))CascadeType.REMOVE) and orphanRemovalThis application provides examples of bulk updates for Author and Book entities (between Author and Book there is a bidirectional lazy @OneToMany association). Both, Author and Book, has a version field.
@OneToMany And Prefer Bidirectional @OneToMany RelationshipDescription: As a rule of thumb, unidirectional @OneToMany association is less efficient than the bidirectional @OneToMany or the unidirectional @ManyToOne associations. This application is a sample that exposes the DML statements generated for reads, writes and removal operations when the unidirectional @OneToMany mapping is used.
Key points:
@OneToMany is less efficient than bidirectional @OneToMany association@OrderColumn come with some optimizations for removal operations but is still less efficient than bidirectional @OneToMany association@JoinColumn eliminates the junction table but is still less efficient than bidirectional @OneToMany associationSet instead of List or bidirectional @OneToMany with @JoinColumn relationship (e.g., @ManyToOne @JoinColumn(name = "author_id", updatable = false, insertable = false)) still performs worse than bidirectional @OneToMany associationWHERE/HAVING ClauseDescription: This application is an example of using subqueries in JPQL WHERE clause (you can easily use it in HAVING clause as well).
Key points:
Keep in mind that subqueries and joins queries may or may not be semantically equivalent (joins may returns duplicates that can be removed via DISTINCT).
Even if the Execution Plan is specific to the database, historically speaking joins are faster than subqueries among different databases, but this is not a rule (e.g., the amount of data may significantly influence the results). Of course, do not conclude that subqueries are just a replacement for joins that doesn't deserve attention. Tuning subqueries can increases their performance as well, but this is an SQL wide topic. So, benchmark! Benchmark! Benchmark!
As a rule of thumb, prefer subqueries only if you cannot use joins, or if you can prove that they are faster than the alternative joins.
WHERE Part Of JPQL Query And JPA 2.1Note: Using SQL functions in SELECT part (not in WHERE part) of the query can be done as here.
Description: Starting with JPA 2.1, a JPQL query can call SQL functions in the WHERE part via function(). This application is an example of calling the MySQL, concat_ws function, but user defined (custom) functions can be used as well.
Key points:
function()| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
|
Description: This application is an example of calling a MySQL stored procedure that returns a value (e.g., an Integer).
Key points:
@NamedStoredProcedureQuery to shape the stored procedure in the entity@Procedure in repositoryDescription: This application is an example of calling a MySQL stored procedure that returns a result set. The application fetches entities (e.g., List<Author>) and DTO (e.g., List<AuthorDto>).
Key points:
EntiyManager since Spring Data @Procedure will not workDescription: This application is an example of calling a MySQL stored procedure that returns a result set (entity or DTO) via a native query.
Key points:
@Query(value = "{CALL FETCH_AUTHOR_BY_GENRE (:p_genre)}", nativeQuery = true)JdbcTemplateNote: Most probably you'll like to process the result set via BeanPropertyRowMapper as here. This is less verbose than the approach used here. Nevertheless, this approach is useful to understand how the result set looks like.
Description: This application is an example of calling a MySQL stored procedure that returns a result set via JdbcTemplate.
Key points:
JdbcTemplate and SimpleJdbcCallDescription: This application is an example of retrieving the database auto-generated primary keys.
Key points:
getId()JdbcTemplateSimpleJdbcInsertDescription: A Hibernate proxy can be useful when a child entity can be persisted with a reference to its parent (@ManyToOne or @OneToOne association). In such cases, fetching the parent entity from the database (execute the SELECT statement) is a performance penalty and a pointless action. Hibernate can set the underlying foreign key value for an uninitialized proxy. This topic is discussed here.
A proxy can be unproxied via Hibernate.unproxy(). This method is available starting with Hibernate 5.2.10.
Key points:
JpaRepository#getOne()Hibernate.unproxy()Boolean To Yes/No Via AttributeConverterDescription: This application is an example of converting a Boolean to Yes/No strings via AttributeConverter. This kind of conversions are needed when we deal with legacy databases that connot be changed. In this case, the legacy database stores the booleans as Yes/No.
Key points:
AttributeConverter@OManyToOneNote: The @ManyToOne association maps exactly to the one-to-many table relationship. The underlying foreign key is under child-side control in unidirectional or bidirectional relationship.
Description: This application shows that using only @ManyToOne is quite efficient. On the other hand, using only @OneToMany is far away from being efficient. Always, prefer bidirectional @OneToMany or unidirectional @ManyToOne. Consider two entities, Author and Book in a unidirectional @ManyToOne relationship.
Key points:
JOIN FETCH And Pageable PaginationDescription: Trying to combine JOIN FETCH/LEFT JOIN FETCH and Pageable results in an exception of type org.hibernate.QueryException: query specified join fetching, but the owner of the fetched association was not present in the select list. This application is a sample of how to avoid this exception.
Key points:
countQueryNote: Fixing the above exception will lead to an warning of type HHH000104, firstResult / maxResults specified with collection fetch; applying in memory!. If this warning is a performance issue, and most probably it is, then follow by reading here.
Description: HHH000104 is a Hibernate warning that tell us that pagination of a result set is tacking place in memory. For example, consider the Author and Book entities in a lazy-bidirectional @OneToMany association and the following query:
@Transactional
@Query(value = "SELECT a FROM Author a LEFT JOIN FETCH a.books WHERE a.genre = ?1",
countQuery = "SELECT COUNT(a) FROM Author a WHERE a.genre = ?1")
Page<Author> fetchWithBooksByGenre(String genre, Pageable pageable);
Calling fetchWithBooksByGenre() works fine only that the following warning is signaled: HHH000104: firstResult / maxResults specified with collection fetch; applying in memory! Obviously, having pagination in memory cannot be good from performance perspective. This application implement a solution for moving pagination at database-level.
Key points:
Page of entities in read-write or read-only modeSlice or List of entities in read-write or read-only mode| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
|
@Transactional(readOnly=true) Actually DoDescription: This application is meant to reveal what is the difference between @Transactional(readOnly = false) and @Transactional(readOnly = true). In a nuthsell, readOnly = false (default) fetches entites in read-write mode (managed). Before Spring 5.1, readOnly = true just set FlushType.MANUAL/NEVER, therefore the automatic dirty checking mechanism will not take action since there is no flush. In other words, Hibernate keep in the Persistent Context the fetched entities and the hydrated (loaded) state. By comparing the entity state with the hydrated state, the dirty checking mechanism can decide to trigger UPDATE statements in our behalf. But, the dirty checking mechanism take place at flush time, therefore, without a flush, the hydrated state is kept in Persistent Context for nothing, representing a performance penalty. Starting with Spring 5.1, the read-only mode is propagated to Hibernate, therefore the hydrated state is discarded immediately after loading the entities. Even if the read-only mode discards the hydrated state the entities are still loaded in the Persistent Context, therefore, for read-only data, relying on DTO (Spring projection) is better.
Key points:
readOnly = false load data in read-write mode (managed)readOnly = true discard the hydrated state (starting with Spring 5.1)Description: This application is an example of getting the current database transaction id in MySQL. Only read-write database transactions gets an id in MySQL. Every database has a specific query for getting the transaction id. Here it is a list of these queries.
Key points:
SELECT tx.trx_id FROM information_schema.innodb_trx tx WHERE tx.trx_mysql_thread_id = connection_id()Description: This application is a sample of inspecting the Persistent Context content via org.hibernate.engine.spi.PersistenceContext.
Key points:
SharedSessionContractImplementorPersistenceContext APIDescription: This application is an example of using the Hibernate SPI, org.hibernate.integrator.spi.Integrator for extracting tables metadata.
Key points:
org.hibernate.integrator.spi.Integrator and override integrate() method to return metadata.getDatabase()Integrator via LocalContainerEntityManagerFactoryBean@ManyToOne Relationship To A SQL Query Via The Hibernate @JoinFormulaDescription: This application is an example of mapping the JPA @ManyToOne relationship to a SQL query via the Hibernate @JoinFormula annotation. We start with two entities, Author and Book, involved in a unidirectional @ManyToOne relationship. Each book has a price. While we fetch a book by id (let's call it book A), we want to fetch another book B of the same author whose price is the next smaller price in comparison with book A price.
Key points:
B is done via @JoinFormulaDescription: This application is an example of fetching a read-only MySQL database view in a JPA immutable entity.
Key points:
data-mysql.sql fileGenreAndTitleView.javaDescription: This application is an example of updating, inserting and deleting data in a MySQL database view. Every update/insert/delete will automatically update the contents of the underlying table(s).
Key points:
data-mysql.sql fileWITH CHECK OPTIONDescription: This application is an example of preventing inserts/updates of a MySQL view that are not visible through this view via WITH CHECK OPTION. In other words, whenever you insert or update a row of the base tables through a view, MySQL ensures that the this operation is conformed with the definition of the view.
Key points:
WITH CHECK OPTION to the viewjava.sql.SQLException: CHECK OPTION failed 'bookstoredb.author_anthology_viewDescription: This application is an example of assigning a database temporary sequence of values to rows via the window function, ROW_NUMBER(). This window function is available in almost all databases, and starting with version 8.x is available in MySQL as well.
Key points:
ROW_NUMBER() (you will use it internally, in the query, usually in the WHERE clause and CTEs), but, this time, let's write a Spring projection (DTO) that contains a getter for the column generated by ROW_NUMBERas wellROW_NUMBER() window functionOutput sample:

Description: This application is an example of finding top N rows of every group.
Key points:
ROW_NUMBER() window functionOutput sample:
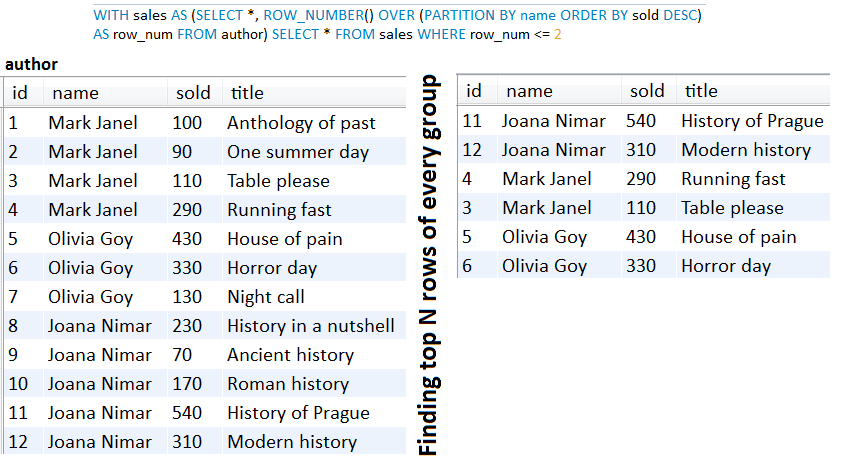
| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
|
ROW_NUMBER() Window FunctionDescription: This application is an example of using ROW_NUMBER() (and COUNT(*) OVER() for counting all elements) window function to implement pagination.
Key points:
ROW_NUMBER()Page or Slice, we return it as List, therefore Pageable is not used@Transactional annotation is being ignoredDescription: This application is an example of fixing the case when @Transactional annotation is ignored. Most of the time, this annotation is ignored in the following scenarios:
@Transactional was added to a private, protected or package-protected method@Transactional was added to a method defined in the same class where it is invokedKey points:
@Transactional methods therepublic@Transactional methods from other servicesDescription: This is a Spring Boot example of using the hi/lo algorithm and a custom implementation of SequenceStyleGenerator for generating custom sequence IDs (e.g, A-0000000001, A-0000000002, ...).
Key points:
SequenceStyleGenerator and override the configure() and generate() methodsClob And Blob To byte[] And StringDescription: This application is an example of mapping Clob and Blob as byte[] and String.
Key points:
LOB Locators Clob And BlobDescription: This application is an example of mapping to JDBC's LOB locators Clob and Blob.
Key points:
SINGLE_TABLE Inheritance HierarchyDescription: This application is a sample of fetching a certain subclass from a SINGLE_TABLE inheritance hierarchy. This is useful when the dedicated repository of the subclass doesn't automatically add in the WHERE clause a dtype based condition for fetching only the needed subclass.
Key points:
WHERE clause a TYPE check@NaturalIdDescription: This is a SpringBoot application that defines a @ManyToOne relationship that doesn't reference a primary key column. It references a Hibernate @NaturalId column.
Key points:
@JoinColumn(referencedColumnName = "natural_id_column")SpecificationDescription: This application is an example of implementing an advanced search via Specification API. Mainly, you can give the search filters to a generic Specification and fetch the result set. Pagination is supported as well. You can chain expressions via logical AND and OR to create compound filters. Nevertheless, there is room for extensions to add brackets support (e.g., (x AND y) OR (x AND z)), more operations, conditions parser and so on and forth.
Key points:
SpecificationSpecification Query Fetch JoinsDescription: This application contains two examples of how to define JOIN in Specification to emulate JPQL join-fetch operations.
Key points:
SELECT statements and the pagination is done in memory (very bad!)SELECT statements but the pagination is done in the databaseJOIN is defined in a Specification implementationNote: You may also like to read the recipe, "How To Enrich DTO With Virtual Properties Via Spring Projections"
Description: Fetch only the needed data from the database via Spring Data Projections (DTO). The projection interface is defined as a static interface (can be non-static as well) in the repository interface.
Key points:
List<projection>LIMIT) - here, we can use query builder mechanism built into Spring Data repository infrastructureNote: Using projections is not limited to use query builder mechanism built into Spring Data repository infrastructure. We can fetch projections via JPQL or native queries as well. For example, in this application we use a JPQL.
Output example (select first 2 rows; select only "name" and "age"):
| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
|
Description: Consider an entity named Review. This entity defines three @ManyToOne relationships to Book, Article and Magazine. A review can be associated with either a book, a magazine or an article. To validate this constraint, we can rely on Bean Validation as in this application.
Key points:
null@JustOneOfMany) added at class-level to the Review entityTRIGGER)Description: This application uses EnumType.ORDINAL and EnumType.STRING for mapping Java enum type to database. As a rule of thumb, strive to keep the data types as small as possible (e.g., for EnumType.ORDINAL use TINYINT/SMALLINT, while for EnumType.STRING use VARCHAR(max_needed_bytes)). Relying on EnumType.ORDINAL should be more efficient but is less expressive than EnumType.STRING.
Key points:
EnumType.ORDINAL set @Column(columnDefinition = "TINYINT"))enum To Database Via AttributeConverterDescription: This application maps a Java enum via AttributeConverter. In other words, it maps the enum values HORROR, ANTHOLOGY and HISTORY to the integers 1, 2 and 3 and viceversa. This allows us to set the column type as TINYINT/SMALLINT which is less space-consuming than VARCHAR(9) needed in this case.
Key points:
AttributeConverter@Converter the corresponding entity fieldenum To PostgreSQL enum TypeDescription: This application maps a Java enum type to PostgreSQL enum type.
Key points:
EnumTypeEnumType via package-info.java@Typeenum To PostgreSQL enum Type Via Hibernate Types LibraryDescription: This application maps a Java enum type to PostgreSQL enum type via Hibernate Types library.
Key points:
pom.xml@TypeDef to specify the needed type class@TypeDescription: Hibernate Types is a library of extra types not supported by Hibernate Core by default. This is a Spring Boot application that uses this library to persist JSON data (JSON Java Object) in a MySQL json column and for querying JSON data from the MySQL json column to JSON Java Object. Updates are supported as well.
Key points:
pom.xml@TypeDef to map typeClass to JsonStringTypeDescription: Hibernate Types is a library of extra types not supported by Hibernate Core by default. This is a Spring Boot application that uses this library to persist JSON data (JSON Java Object) in a PostgreSQL json column and for querying JSON data from the PostgreSQL json column to JSON Java Object. Updates are supported as well.
Key points:
pom.xml@TypeDef to map typeClass to JsonBinaryTypeOPTIMISTIC_FORCE_INCREMENTDescription: This application is a sample of how OPTIMISTIC_FORCE_INCREMENT works in MySQL. This is useful when you want to increment the version of the locked entity even if this entity was not modified. Via OPTIMISTIC_FORCE_INCREMENT the version is updated (incremented) at the end of the currently running transaction.
Key points:
Chapter (which uses @Version)Modification entityModification (child-side) and Chapter (parent-side) there is a lazy unidirectional @ManyToOne associationINSERT statement against the modification table, therefore the chapter table will not be modified by editorsChapter entity version is needed to ensure that modifications are applied sequentially (the author and editor are notified if a modificaton was added since the chapter copy was loaded)version is forcibly increased at each modification (this is materialized in an UPDATE triggered against the chapter table at the end of the currently running transaction)OPTIMISTIC_FORCE_INCREMENT in the corresponding repositoryObjectOptimisticLockingFailureExceptionPESSIMISTIC_FORCE_INCREMENTDescription: This application is a sample of how PESSIMISTIC_FORCE_INCREMENT works in MySQL. This is useful when you want to increment the version of the locked entity even if this entity was not modified. Via PESSIMISTIC_FORCE_INCREMENT the version is updated (incremented) immediately (the entity version update is guaranteed to succeed immediately after acquiring the row-level lock). The incrementation takes place before the entity is returned to the data access layer.
Key points:
Chapter (which uses @Version)Modification entityModification (child-side) and Chapter (parent-side) there is a lazy unidirectional @ManyToOne associationINSERT statement against the modification table, therefore the chapter table will not be modified by editorsChapter entity version is needed to ensure that modifications are applied sequentially (each editor is notified if a modificaton was added since his chapter copy was loaded and he must re-load the chapter)version is forcibly increased at each modification (this is materialized in an UPDATE triggered against the chapter table immediately after aquiring the row-level lock)PESSIMISTIC_FORCE_INCREMENT in the corresponding repositoryOptimisticLockException and one that will lead to QueryTimeoutExceptionNote: Pay attention to the MySQL dialect: MySQL5Dialect (MyISAM) doesn't support row-level locking, MySQL5InnoDBDialect (InnoDB) acquires row-level lock via FOR UPDATE (timeout can be set), MySQL8Dialect (InnoDB) acquires row-level lock via FOR UPDATE NOWAIT.
PESSIMISTIC_READ And PESSIMISTIC_WRITE Works In MySQLDescription: This application is an example of using PESSIMISTIC_READ and PESSIMISTIC_WRITE in MySQL. In a nutshell, each database system defines its own syntax for acquiring shared and exclusive locks and not all databases support both types of locks. Depending on Dialect, the syntax can vary for the same database as well (Hibernate relies on Dialect for chosing the proper syntax). In MySQL, MySQL5Dialect doesn't support locking, while InnoDB engine (MySQL5InnoDBDialect and MySQL8Dialect) supports shared and exclusive locks as expected.
Key points:
@Lock(LockModeType.PESSIMISTIC_READ) and @Lock(LockModeType.PESSIMISTIC_WRITE) on query-levelTransactionTemplate to trigger two concurrent transactions that read and write the same row| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
|
PESSIMISTIC_WRITE Works With UPDATE/INSERT And DELETE OperationsDescription: This application is an example of triggering UPDATE, INSERT and DELETE operations in the context of PESSIMISTIC_WRITE locking against MySQL. While UPDATE and DELETE are blocked until the exclusive lock is released, INSERT depends on the transaction isolation level. Typically, even with exclusive locks, inserts are possible (e.g., in PostgreSQL). In MySQL, for the default isolation level, REPEATABLE READ, inserts are prevented against a range of locked entries, but, if we switch to READ_COMMITTED, then MySQL acts as PostgreSQL as well.
Key points:
SELECT with PESSIMISTIC_WRITE to acquire an exclusive lockUPDATE, INSERT or DELETE on the rows locked by Transaction AUPDATE, DELETE and INSERT + REPEATABLE_READ, Transaction B is blocked until it timeouts or Transaction A releases the exclusive lockINSERT + READ_COMMITTED, Transaction B can insert in the range of rows locked by Transaction A even if Transaction A is holding an exclusive lock on this rangeNote: Do not test transaction timeout via Thread.sleep()! This is not working! Rely on two transactions and exclusive locks or even better rely on SQL sleep functions (e.g., MySQL, SELECT SLEEP(n) seconds, PostgreSQL, SELECT PG_SLEEP(n) seconds). Most RDBMS supports a sleep function flavor.
Description: This application contains several approaches for setting a timeout period for a transaction or query. The timeout is signaled by a specific timeout exception (e.g., .QueryTimeoutException). After timeout, the transaction is rolled back. You can see this in the database (visually or query) and on log via a message of type: Initiating transaction rollback; Rolling back JPA transaction on EntityManager [SessionImpl(... <open>)].
Key points:
spring.transaction.default-timeout in seconds (see, application.properties)@Transactional(timeout = n) in secondsjavax.persistence.query.timeout hint in millisecondsorg.hibernate.timeout hint in secondsNote: If you are using TransactionTemplate then the timeout can be set via TransactionTemplate.setTimeout(n) in seconds.
@EmbeddableDescription: This application is a proof of concept of how to define a composite key via @Embeddable and @EmbeddedId. This application uses two entities, Author and Book involved in a lazy bidirectional @OneToMany association. The identifier of Author is composed by name and age via AuthorId class. The identifier of Book is just a regular auto-generated numeric value.
Key points:
AuthorId) is publicSerializableequals() and hashCode()@IdClassDescription: This application is a proof of concept of how to define a composite key via @IdClass. This application uses two entities, Author and Book involved in a lazy bidirectional @OneToMany association. The identifier of Author is composed by name and age via AuthorId class. The identifier of Book is just a typical auto-generated numeric value.
Key points:
AuthorId) is publicSerializableequals() and hashCode()Note: The @IdClass can be useful when we cannot modify the compsite key class. Otherwise, rely on @Embeddable.
@Embeddable Composite Primary KeyDescription: This application is a proof of concept of how to define a relationship in an @Embeddable composite key. The composite key is AuthorId and it belongs to the Author class.
Key points:
AuthorId) is publicSerializableequals() and hashCode()Description: This is a SpringBoot application that loads multiple entities by id via a @Query based on the IN operator and via the Hibernate 5 MultiIdentifierLoadAccess interface.
Key points:
IN operator in a @Query simply add the query in the proper repositoryMultiIdentifierLoadAccess in Spring Data style provide the proper implementationMultiIdentifierLoadAccess implementation allows us to load entities by multiple ids in batches and by inspecting or not the current Persistent Context (by default, the Persistent Context is not inspected to see if the entities are already loaded or not)Description: This application is a sample of fetching all attributes of an entity (Author) as a Spring projection (DTO). Commonly, a DTO contains a subset of attributes, but, sometimes we need to fetch the whole entity as a DTO. In such cases, we have to pay attention to the chosen approach. Choosing wisely can spare us from performance penalties.
Key points:
List<Object[]> or List<AuthorDto> via a JPQL of type SELECT a FROM Author a WILL fetch the result set as entities in Persistent Context as well - avoid this approachList<Object[]> or List<AuthorDto> via a JPQL of type SELECT a.id AS id, a.name AS name, ... FROM Author a will NOT fetch the result set in Persistent Context - this is efficientList<Object[]> or List<AuthorDto> via a native SQL of type SELECT id, name, age, ... FROM author will NOT fetch the result set in Persistent Context - but, this approach is pretty slowList<Object[]> via Spring Data query builder mechanism WILL fetch the result set in Persistent Context - avoid this approachList<AuthorDto> via Spring Data query builder mechanism will NOT fetch the result set in Persistent ContextfindAll() method) should be considered after JPQL with explicit list of columns to be fetched and query builder mechanism@ManyToOne Or @OneToOne AssociationsDescription: This application fetches a Spring projection including the @ManyToOne association via different approaches. It can be easily adapted for @OneToOne association as well.
Key points:
Description: This application inspect the Persistent Context content during fetching Spring projections that includes collections of associations. In this case, we focus on a @OneToMany association. Mainly, we want to fetch only some attributes from the parent-side and some attributes from the child-side.
Description: This application is a sample of reusing an interface-based Spring projection. This is useful to avoid defining multiple interface-based Spring projections in order to cover a range of queries that fetches different subsets of fields.
Key points:
@JsonInclude(JsonInclude.Include.NON_DEFAULT) annotation to avoid serialization of default fields (e.g., fields that are not available in the current projection and are null - these fields haven't been fetched in the current query)null fields)| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
|
Description: This application is a sample of using dynamic Spring projections.
Key points:
<T> List<T> findByGenre(String genre, Class<T> type);)Description: This application is a sample of batching inserts via EntityManager in MySQL. This way you can easily control the flush() and clear() cycles of the Persistence Context (1st Level Cache) inside the current transaction. This is not possible via Spring Boot, saveAll(Iterable<S> entities), since this method executes a single flush per transaction. Another advantage is that you can call persist() instead of merge() - this is used behind the scene by the SpringBoot saveAll(Iterable<S> entities) and save(S entity).
Moreover, this example commits the database transaction after each batch excecution. This way we avoid long-running transactions and, in case of a failure, we rollback only the failed batch and don't lose the previous batches. For each batch, the Persistent Context is flushed and cleared, therefore we maintain a thin Persistent Context. This way the code is not prone to memory errors and performance penalties caused by slow flushes.
Key points:
application.properties set spring.jpa.properties.hibernate.jdbc.batch_sizeapplication.properties set spring.jpa.properties.hibernate.generate_statistics (just to check that batching is working)application.properties set JDBC URL with rewriteBatchedStatements=true (optimization for MySQL)application.properties set JDBC URL with cachePrepStmts=true (enable caching and is useful if you decide to set prepStmtCacheSize, prepStmtCacheSqlLimit, etc as well; without this setting the cache is disabled)application.properties set JDBC URL with useServerPrepStmts=true (this way you switch to server-side prepared statements (may lead to signnificant performance boost))spring.jpa.properties.hibernate.order_inserts=true to optimize the batching by ordering insertsIDENTITY will cause insert batching to be disabledspring.jpa.properties.hibernate.cache.use_second_level_cache=falseOutput example:
Description: This is a Spring Boot application that reads a relatively big JSON file (200000+ lines) and inserts its content in MySQL via batching using ForkJoinPool, JdbcTemplate and HikariCP.
Key points:
json typeListrewriteBatchedStatements=true -> this setting will force sending the batched statements in a single request;cachePrepStmts=true -> enable caching and is useful if you decide to set prepStmtCacheSize, prepStmtCacheSqlLimit, etc as well; without this setting the cache is disableduseServerPrepStmts=true -> this way you switch to server-side prepared statements (may lead to signnificant performance boost); moreover, you avoid the PreparedStatement to be emulated at the JDBC Driver level;...?cachePrepStmts=true&useServerPrepStmts=true&rewriteBatchedStatements=true&createDatabaseIfNotExist=trueStopWatch to measure the time needed to transfer the file into the databasecitylots.zip in the current location; this is the big JSON file collected from Internet;DatasourceProxyBeanPostProcessor.java component by uncomment the line, // @Component; This is needed because this application relies on DataSource-Proxy (for details, see the following item)CompletableFutureDescription: This application is a sample of using CompletableFuture for batching inserts. This CompletableFuture uses an Executor that has the number of threads equal with the number of your computer cores. Usage is in Spring style.
Description: Let's suppose that we have a one-to-many relationship between Author and Book entities. When we save an author, we save his books as well thanks to cascading all/persist. We want to create a bunch of authors with books and save them in the database (e.g., a MySQL database) using the batch technique. By default, this will result in batching each author and the books per author (one batch for the author and one batch for the books, another batch for the author and another batch for the books, and so on). In order to batch authors and books, we need to order inserts as in this application.
Moreover, this example commits the database transaction after each batch excecution. This way we avoid long-running transactions and, in case of a failure, we rollback only the failed batch and don't lose the previous batches. For each batch, the Persistent Context is flushed and cleared, therefore we maintain a thin Persistent Context. This way the code is not prone to memory errors and performance penalties caused by slow flushes.
Key points:
application.properties the following property: spring.jpa.properties.hibernate.order_inserts=trueExample without ordered inserts:
Example with ordered inserts:
Description: Batch inserts (in MySQL) in Spring Boot style. This example commits the database transaction after each batch excecution. This way we avoid long-running transactions and, in case of a failure, we rollback only the failed batch and don't lose the previous batches.
Key points:
application.properties set spring.jpa.properties.hibernate.jdbc.batch_sizeapplication.properties set spring.jpa.properties.hibernate.generate_statistics (just to check that batching is working)application.properties set JDBC URL with rewriteBatchedStatements=true (optimization for MySQL)application.properties set JDBC URL with cachePrepStmts=true (enable caching and is useful if you decide to set prepStmtCacheSize, prepStmtCacheSqlLimit, etc as well; without this setting the cache is disabled)application.properties set JDBC URL with useServerPrepStmts=true (this way you switch to server-side prepared statements (may lead to signnificant performance boost))spring.jpa.properties.hibernate.order_inserts=true to optimize the batching by ordering insertsIDENTITY will cause insert batching to be disabledspring.jpa.properties.hibernate.cache.use_second_level_cache=falseOutput example:
IN Clause Parameter PaddingDescription: This application is an example of using Hibernate IN cluase parameter padding. This way we can reduce the number of Execution Plans. Mainly, Hibernate is padding parameters as follows:
Key points:
application.properties set spring.jpa.properties.hibernate.query.in_clause_parameter_padding=trueDescription: Fetch only the needed data from the database via Spring Data Projections (DTO). In this case, via class-based projections.
Key points:
equals() and hashCode() only for the columns that should be fetched from the databaseList<projection>LIMIT)Note: Using projections is not limited to use query builder mechanism built into Spring Data repository infrastructure. We can fetch projections via JPQL or native queries as well. For example, in this application we use a JPQL.
Output example (select first 2 rows; select only "name" and "age"):
Description: Batch inserts via Hibernate session-level batching (Hibernate 5.2 or higher) in MySQL. This example commits the database transaction after each batch excecution. This way we avoid long-running transactions and, in case of a failure, we rollback only the failed batch and don't lose the previous batches. For each batch, the Persistent Context is flushed and cleared, therefore we maintain a thin Persistent Context. This way the code is not prone to memory errors and performance penalties caused by slow flushes.
Key points:
application.properties set spring.jpa.properties.hibernate.generate_statistics (just to check that batching is working)application.properties set JDBC URL with rewriteBatchedStatements=true (optimization for MySQL)application.properties set JDBC URL with cachePrepStmts=true (enable caching and is useful if you decide to set prepStmtCacheSize, prepStmtCacheSqlLimit, etc as well; without this setting the cache is disabled)application.properties set JDBC URL with useServerPrepStmts=true (this way you switch to server-side prepared statements (may lead to signnificant performance boost))spring.jpa.properties.hibernate.order_inserts=true to optimize the batching by ordering insertsIDENTITY will cause insert batching to be disabledSession is obtained by un-wrapping it via EntityManager#unwrap(Session.class)Session#setJdbcBatchSize(Integer size) and get via Session#getJdbcBatchSize()spring.jpa.properties.hibernate.cache.use_second_level_cache=falseOutput example:
Description: This application highlights the difference betweeen loading entities in read-write vs. read-only mode. If you plan to modify the entities in a future Persistent Context then fetch them as read-only in the current Persistent Context.
Key points:
Note: If you never plan to modify the fetched result set then use DTO (e.g., Spring projection), not read-only entities.
| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
|
Note: Domain events should be used with extra-caution! The best practices for using them are revealed in my book, Spring Boot Persistence Best Practices.
Description: Starting with Spring Data Ingalls release publishing domain events by aggregate roots becomes easier. Entities managed by repositories are aggregate roots. In a Domain-Driven Design application, these aggregate roots usually publish domain events. Spring Data provides an annotation @DomainEvents you can use on a method of your aggregate root to make that publication as easy as possible. A method annotated with @DomainEvents is automatically invoked by Spring Data whenever an entity is saved using the right repository. Moreover, Spring Data provides the @AfterDomainEventsPublication annotation to indicate the method that should be automatically called for clearing events after publication. Spring Data Commons comes with a convenient template base class (AbstractAggregateRoot) to help to register domain events and is using the publication mechanism implied by @DomainEvents and @AfterDomainEventsPublication. The events are registered by calling the AbstractAggregateRoot.registerEvent() method. The registered domain events are published if we call one of the save methods (e.g., save()) of the Spring Data repository and cleared after publication.
This is a sample application that relies on AbstractAggregateRoot and its registerEvent() method. We have two entities, Book and BookReview involved in a lazy-bidirectional @OneToMany association. A new book review is saved in CHECK status and a CheckReviewEvent is published. This event handler is responsible to check the review grammar, content, etc and switch the review status from CHECK to ACCEPT or REJECT and propagate the new status to the database. So, this event is registered before saving the book review in CHECK status and is published automatically after we call the BookReviewRepository.save() method. After publication, the event is cleared.
Key points:
AbstractAggregateRoot and provide a method for registering eventsCheckReviewEvent), but more can be registeredCheckReviewEventHandler in an asynchronous manner via @AsyncDescription: This application is an example of testing the Hibernate Query Plan Cache (QPC). Hibernate QPC is enabled by default and, for entity queries (JPQL and Criteria API), the QPC has a size of 2048, while for native queries it has a size of 128. Pay attention to alter these values to accommodate all queries executed by your application. If the number of exectued queries is higher than the QPC size (especially for entity queries) then you will start to experiment performance penalties caused by entity compilation time added for each query execution.
In this application, you can adjust the QPC size in application.properties. Mainly, there are 2 JPQL queries and a QPC of size 2. Switching from size 2 to size 1 will cause the compilation of one JPQL query at each execution. Measuring the times for 5000 executions using a QPC of size 2, respectively 1 reveals the importance of QPC in terms of time.
Key points:
hibernate.query.plan_cache_max_sizehibernate.query.plan_parameter_metadata_max_sizeDescription: This is a SpringBoot application that enables Hibernate Second Level Cache and EhCache provider. It contains an example of caching entities and an example of caching a query result.
Key points:
EhCache)@CacheHINT_CACHEABLEDescription: This is a SpringBoot application representing a kickoff application for Spring Boot caching and EhCache.
Key points:
EhCacheSqlResultSetMapping And NamedNativeQueryNote: If you want to rely on the {EntityName}.{RepositoryMethodName} naming convention for simply creating in the repository interface methods with the same name as of native named query then skip this application and check this one.
Description: This is a sample application of using SqlResultSetMapping, NamedNativeQuery and EntityResult for fetching single entity and multiple entities as List<Object[]>.
Key points:
SqlResultSetMapping, NamedNativeQuery and EntityResultDescription: This is a SpringBoot application that loads multiple entities by id via a @Query based on the IN operator and via Specification.
Key points:
IN operator in a @Query simply add the query in the proper repositorySpecification rely on javax.persistence.criteria.Root.in()ResultTransformerDescription: Fetching more read-only data than needed is prone to performance penalties. Using DTO allows us to extract only the needed data. Sometimes, we need to fetch a DTO made of a subset of properties (columns) from a parent-child association. For such cases, we can use SQL JOIN that can pick up the desired columns from the involved tables. But, JOIN returns an List<Object[]> and most probably you will need to represent it as a List<ParentDto>, where a ParentDto instance has a List<ChildDto>. For such cases, we can rely on a custom Hibernate ResultTransformer. This application is a sample of writing a custom ResultTransformer.
Key points:
ResultTransformer interfaceDescription: Is a common scenario to have a big List and to need to chunk it in multiple smaller List of given size. For example, if we want to employee a concurrent batch implementation we need to give to each thread a sublist of items. Chunking a list can be done via Google Guava, Lists.partition(List list, int size) method or Apache Commons Collections, ListUtils.partition(List list, int size) method. But, it can be implemented in plain Java as well. This application exposes 6 ways to do it. The trade-off is between the speed of implementation and speed of execution. For example, while the implementation relying on grouping collector is not performing very well, it is quite simple and fast to write it.
Key points:
Chunk.java class which relies on the built-in List.subList() methodTime-performance trend graphic for chunking 500, 1_000_000, 10_000_000 and 20_000_000 items in lists of 5 items:

Description: Consider the Book and Chapter entities. A book has a maximum accepted number of pages (book_pages) and the author should not exceed this number. When a chapter is ready for review, the author is submitting it. At this point, the publisher should check that the currently total number of pages doesn't exceed the allowed book_pages:
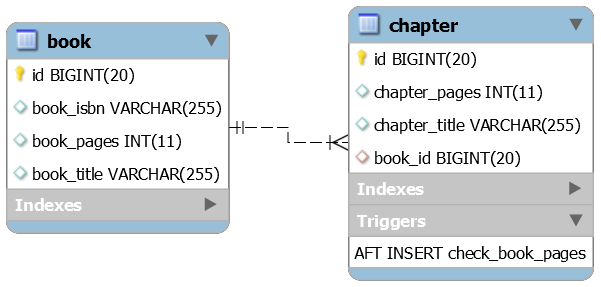
This kind of checks or constraints are easy to implement via database triggers. This application relies on a MySQL trigger to empower our complex contraint (check_book_pages).
Key points:
AFTER INSERT OR AFTER UPDATE)Description: This application is an example of using Spring Data Query By Example (QBE) to check if a transient entity exists in the database. Consider the Book entity and a Spring controller that exposes an endpoint as: public String checkBook(@Validated @ModelAttribute Book book, ...). Beside writting an explicit JPQL, we can rely on Spring Data Query Builder mechanism or, even better, on Query By Example (QBE) API. In this context, QBE API is quite useful if the entity has a significant number of attributes and:
Key points:
BookRepository extends QueryByExampleExecutor<S extends T> boolean exists(Example<S> exmpl) with the proper probe (an entity instance populated with the desired fields values)ExampleMatcher which defines the details on how to match particular fieldsNote: Do not conclude that Query By Example (QBE) defines only the exists() method. Check out all methods here.
| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
|
@TransactionalDescription: This application is meant to highlight that the best place to use @Transactional for user defined query-methods is in repository interface, and afterwards, depending on situation, on service-methods level.
Key points:
JOINED Inheritance Strategy And Visitor Design PatternDescription: This application is an example of using JPA JOINED inheritance strategy and Visitor pattern.
Key points:
JOINED Inheritance Strategy And Strategy Design PatternDescription: This application is an example of using JPA JOINED inheritance strategy and Strategy pattern.
Key points:
Description: This folder holds several applications that shows how each Spring transaction propagation works.
Key points:
GenerationType.AUTO And UUID IdentifiersDescription: This application is an example of using the JPA GenerationType.AUTO for assigning automatically UUID identifiers.
Key points:
BINARY(16) columnDescription: This application is an example of manually assigning UUID identifiers.
Key points:
BINARY(16) columnuuid2 For Generating UUID IdentifiersDescription: This application is an example of using the Hibernate RFC 4122 compliant UUID generator, uuid2.
Key points:
BINARY(16) columnDescription: This Spring Boot application is a sample that reveals how Hibernate session-level repeatable reads works. Persistence Context guarantees session-level repeatable reads. Check out how it works.
Key points:
TransactionTemplateNote: For a detailed explanation of this application consider my book, Spring Boot Persistence Best Practices
hibernate.enable_lazy_load_no_transDescription: This application is an example of using Hibernate-specific hibernate.enable_lazy_load_no_trans. Check out the application log to see how transactions and database connections are used.
Key points:
hibernate.enable_lazy_load_no_transDescription: This application is an example of cloning entities. The best way to achieve this goal relies on copy-constructors. This way we can control what we copy. Here we use a bidirectional-lazy @ManyToMany association between Author and Book.
Key points:
Author (only the genre) and associate the corresponding booksAuthor (only the genre) and clone the books as well| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
|
UPDATE Statement Only The Modified Columns Via Hibernate @DynamicUpdateDescription: This application is an example of using the Hibernate-specific, @DynamicUpdate. By default, even if we modify only a subset of columns, the triggered UPDATE statements will include all columns. By simply annotating the corresponding entity at class-level with @DynamicUpdate the generated UPDATE statement will include only the modified columns.
Key points:
UPDATE for different subsets of columns via JDBC statements caching (each triggered UPDATE string will be cached and reused accordingly)Description: This application is an example of logging execution time for a repository query-method.
Key points:
RepositoryProfiler)Description: This application is an example of using the TransactionSynchronizationAdapter for overriding beforeCommit(), beforeCompletion(), afterCommit() and afterCompletion() callbacks globally (application-level) and at method-level.
Key points:
TransactionProfiler)TransactionSynchronizationManager.registerSynchronization()SqlResultSetMapping And NamedNativeQuery Using {EntityName}.{RepositoryMethodName} Naming ConventionDescription: Fetching more data than needed is prone to performance penalities. Using DTO allows us to extract only the needed data. In this application we rely on SqlResultSetMapping, NamedNativeQuery and the {EntityName}.{RepositoryMethodName} naming convention. This convention allows us to create in the repository interface methods with the same name as of native named query.
Key points:
SqlResultSetMapping, NamedNativeQuerySqlResultSetMapping And NamedNativeQuery Using {EntityName}.{RepositoryMethodName} Naming ConventionDescription: This is a sample application of using SqlResultSetMapping, NamedNativeQuery and EntityResult for fetching single entity and multiple entities as List<Object[]>. In this application we rely on the {EntityName}.{RepositoryMethodName} naming convention. This convention allows us to create in the repository interface methods with the same name as of native named query.
Key points:
SqlResultSetMapping, NamedNativeQuery and EntityResult@NamedQuery And Spring Projection (DTO)Description: This application is an example of combining JPA named queries @NamedQuery and Spring projections (DTO). For queries names we use the {EntityName}.{RepositoryMethodName} naming convention. This convention allows us to create in the repository interface methods with the same name as of named query.
Key points:
@NamedNativeQuery And Spring Projection (DTO)Description: This application is an example of combining JPA named native queries @NamedNativeQuery and Spring projections (DTO). For queries names we use the {EntityName}.{RepositoryMethodName} naming convention. This convention allows us to create in the repository interface methods with the same name as of named native query.
Key points:
Description: JPA named (native) queries are commonly written via @NamedQuery and @NamedNativeQuery annotations in entity classes. Spring Data allows us to write our named (native) queries in a typical *.properties file inside the META-INF folder of your classpath. This way, we avoid modifying our entities. This application shows you how to do it.
Warning: Cannot use native queries with dynamic sorting (Sort). Nevertheless, using Sort in named queries works fine. Moreover, using Sort in Pageable works fine for both, named queries and named native queries. At least this is how it behave in Spring Boot 2.2.2. From this point of view, this approach is better than using @NamedQuery/@NamedNativeQuery or orm.xml file.
Key points:
META-INF/jpa-named-queries.properties{EntityName}.{RepositoryMethodName} naming convention for a quick and slim implementationorm.xml FileDescription: JPA named (native) queries are commonly written via @NamedQuery and @NamedNativeQuery annotations in entity classes. Spring Data allows us to write our named (native) queries in a typical orm.xml file inside the META-INF folder of your classpath. This way, we avoid modifying our entities. This application shows you how to do it.
Warning: Pay attention that, via this approach, we cannot use named (native) queries with dynamic sorting (Sort). Using Sort in Pageable is ignored, therefore you need to explicitly add ORDER BY in the queries. At least this is how it behave in Spring Boot 2.2.2. A better approach relies on using a properties file for listing the named (native) queries. In this case, dynamic Sort works for named queries, but not for named native queries. Using Sort in Pageable works as expected in named (native) queries.
Key points:
META-INF/orm.xml{EntityName}.{RepositoryMethodName} naming convention for a quick and slim implementationDescription: JPA named (native) queries are commonly written via @NamedQuery and @NamedNativeQuery annotations in entity classes. This application shows you how to do it.
Warning: Pay attention that, via this approach, we cannot use named (native) queries with dynamic sorting (Sort). Using Sort in Pageable is ignored, therefore you need to explicitly add ORDER BY in the queries. At least this is how it behave in Spring Boot 2.2.2. A better approach relies on using a properties file for listing the named (native) queries. In this case, dynamic Sort works for named queries, but not for named native queries. Using Sort in Pageable works as expected in named (native) queries. And, you don't need to modify/pollute entitites with the above annotations.
Key points:
@NamedQuery and @NamedNativeQuery annotations in entity classes{EntityName}.{RepositoryMethodName} naming convention for a quick and slim implementationSort and Pageable| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
|
Description: This application is an example of combining JPA named queries listed in a properties file and Spring projections (DTO). For queries names we use the {EntityName}.{RepositoryMethodName} naming convention. This convention allows us to create in the repository interface methods with the same name as of named query.
Key points:
jpa-named-queries.properties) in a folder named META-INF the application classpathDescription: This application is an example of combining JPA named native queries listed in a properties file and Spring projections (DTO). For queries names we use the {EntityName}.{RepositoryMethodName} naming convention. This convention allows us to create in the repository interface methods with the same name as of named native query.
Key points:
jpa-named-queries.properties) in a folder named META-INF the application classpathorm.xml File And Spring Projection (DTO)Description: This application is an example of combining JPA named queries listed in orm.xml file and Spring projections (DTO). For queries names we use the {EntityName}.{RepositoryMethodName} naming convention. This convention allows us to create in the repository interface methods with the same name as of named query.
Key points:
orm.xml file in a folder named META-INF the application classpathorm.xml File And Spring Projection (DTO)Description: This application is an example of combining JPA named native queries listed in orm.xml file and Spring projections (DTO). For queries names we use the {EntityName}.{RepositoryMethodName} naming convention. This convention allows us to create in the repository interface methods with the same name as of named native query.
Key points:
orm.xml file in a folder named META-INF the application classpathorm.xmlDescription: Fetching more data than needed is prone to performance penalities. Using DTO allows us to extract only the needed data. In this application we rely on named native queries and result set mapping via orm.xml and the {EntityName}.{RepositoryMethodName} naming convention. This convention allows us to create in the repository interface methods with the same name as of native named query.
Key points:
<named-native-query/> and <sql-result-set-mapping/> to map the native query to AuthorDto class
Description: This application is a proof of concept for using Spring Projections(DTO) and cross joins written via JPQL and native SQL (for MySQL).
Key points:
Book and Formatresources/data-mysql.sql)BookTitleAndFormatType.java)JdbcTemplate And BeanPropertyRowMapperDescription: This application is an example of calling a MySQL stored procedure that returns a result set via JdbcTemplate and BeanPropertyRowMapper.
Key points:
JdbcTemplate, SimpleJdbcCall and BeanPropertyRowMapper@EntityListenersDescription: This application is a sample of using the JPA @MappedSuperclass and @EntityListeners with JPA callbacks.
Key points:
Book, is not an entity, it can be abstract, and is annotated with @MappedSuperclass and @EntityListeners(BookListener.class)BookListener defines JPA callbacks (e.g., @PrePersist)Book is persisted, loaded, updated, etc the corresponding JPA callbacks are called@Fetch(FetchMode.JOIN) May Causes N+1 IssuesAdvice: Always evaluate JOIN FETCH and entities graphs before deciding to use FetchMode.JOIN. The FetchMode.JOIN fetch mode always triggers an EAGER load so the children are loaded when the parents are. Beside this drawback, FetchMode.JOIN may return duplicate results. You’ll have to remove the duplicates yourself (e.g. storing the result in a Set). But, if you decide to go with FetchMode.JOIN at least pay attention to avoid N+1 issues discussed below.
Note: Let's assume three entities, Author, Book and Publisher. Between Author and Book there is a bidirectional-lazy @OneToMany association. Between Author and Publisher there is a unidirectional-lazy @ManyToOne. Between Book and Publisher there is no association.
Now, we want to fetch a book by id (BookRepository#findById()), including its author, and the author's publisher. In such cases, using Hibernate fetch mode, @Fetch(FetchMode.JOIN) works as expected. Using JOIN FETCH or entity graph is also working as expected.
Next, we want to fetch all books (BookRepository#findAll()), including their authors, and the authors publishers. In such cases, using Hibernate fetch mode, @Fetch(FetchMode.JOIN) will cause N+1 issues. It will not trigger the expected JOIN. In this case, using JOIN FETCH or entity graph should be used.
Key points:
@Fetch(FetchMode.JOIN) doesn't work for query-methods@Fetch(FetchMode.JOIN) works in cases that fetches the entity by id (primary key) like using EntityManager#find(), Spring Data, findById(), findOne().RANK()Description: This application is an example of assigning a database temporary ranking of values to rows via the window function, RANK(). This window function is available in almost all databases, and starting with version 8.x is available in MySQL as well.
Key points:
RANK() (you will use it internally, in the query, usually in the WHERE clause and CTEs), but, this time, let's write a Spring projection (DTO) that contains a getter for the column generated by RANK() as wellRANK() window functionOutput sample:
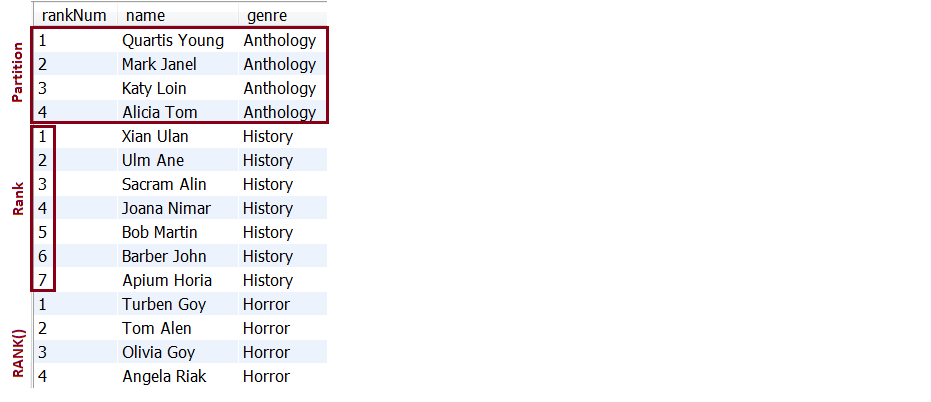
| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
|
DENSE_RANK()Description: This application is an example of assigning a database temporary ranking of values to rows via the window function, DENSE_RANK(). In comparison with the RANK() window function, DENSE_RANK() avoid gaps within partition. This window function is available in almost all databases, and starting with version 8.x is available in MySQL as well.
Key points:
DENSE_RANK() (you will use it internally, in the query, usually in the WHERE clause and CTEs), but, this time, let's write a Spring projection (DTO) that contains a getter for the column generated by DENSE_RANK() as wellDENSE_RANK() window functionOutput sample:
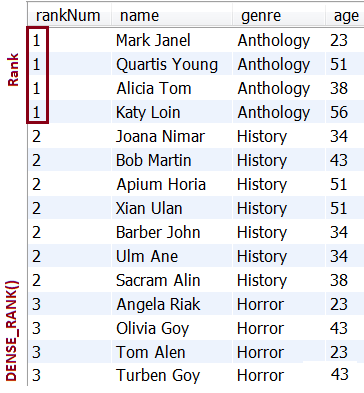
NTILE(N)Description: This application is an example of distributing the number of rows in the specified (N) number of groups via the window function, NTILE(N). This window function is available in almost all databases, and starting with version 8.x is available in MySQL as well.
Key points:
NTILE() (you will use it internally, in the query, usually in the WHERE clause and CTEs), but, this time, let's write a Spring projection (DTO) that contains a getter for the column generated by NTILE() as wellNTILE() window functionOutput sample:
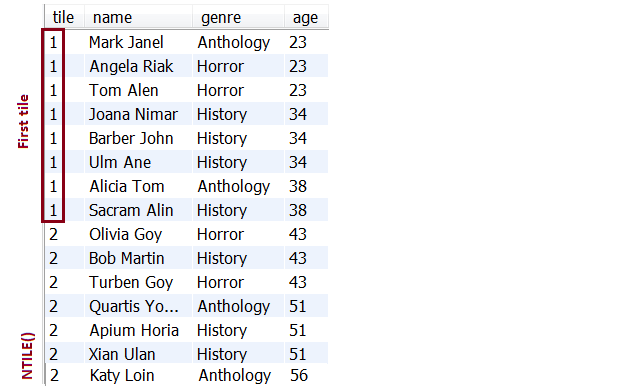
Description: Spring Data comes with the Query Builder mechanism for JPA that is capable to interpret a query method name (known as a derived query) and convert it into a SQL query in the proper dialect. This is possible as long as we respect the naming conventions of this mechanism. Beside the well-known query of type find..., Spring Data supports derived count queries and derived delete queries.
Key points:
count... (e.g., long countByGenre(String genre)) - Spring Data will generate a SELECT COUNT(...) FROM ... querydelete... or remove... and returns long (e.g., long deleteByGenre(String genre)) - Spring Data will trigger first a SELECT to fetch entities in the Persistence Context, and, afterwards, it triggers a DELETE for each entity that must be deleteddelete... or remove... and returns List<entity> (e.g., List<Author> removeByGenre(String genre)) - Spring Data will trigger first a SELECT to fetch entities in the Persistence Context, and, afterwards, it triggers a DELETE for each entity that must be deletedDescription: Property expressions can refer to a direct property of the managed entity. However, you can also define constraints by traversing nested properties. This application is a sample of traversing nested properties for fetching entities and DTOs.
Key points:
Author has several Book and each book has several Review (between Author and Book there is a bidirectional-lazy @oneToMany association, and, between Book and Review there is also a bidirectional-lazy @OneToMany association)Review and we want to know the Author of the Book that has received this ReviewAuthorRepository the following query that will be processed by the Spring Data Query Builder mechanism: Author findByBooksReviews(Review review);SELECT with two LEFT JOINbooks.reviews. The algorithm starts by interpreting the entire part (BooksReviews) as the property and checks the domain class for a property with that name (uncapitalized). If the algorithm succeeds, it uses that property. If not, the algorithm splits up the source at the camel case parts from the right side into a head and a tail and tries to find the corresponding property — in our example, Books and Reviews. If the algorithm finds a property with that head, it takes the tail and continues building the tree down from there, splitting the tail up in the way just described. If the first split does not match, the algorithm moves the split point to the left and continues.Author class has an booksReview property as well. The algorithm would match in the first split round already, choose the wrong property, and fail (as the type of booksReview probably has no code property). To resolve this ambiguity you can use _ inside your method name to manually define traversal points. So our method name would be as follows: Author findByBooks_Reviews(Review review);Note: Fetching read-only data should be done via DTO, not managed entities. But, there is no tragedy to fetch read-only entities in a context as follows:
@Transactional(readOnly = true)Under these circumstances, let's tackle a common case that I saw quite a lot. There is even an SO answer about it (don't do this):

Description: Let's assume that Author and Book are involved in a bidirectional-lazy @OneToMany association. Imagine an user that loads a certain Author (without the associated Book). The user may be interested or not in the Book, therefore, we don't load them with the Author. If the user is interested in the Book then he will click a button of type, View books. Now, we have to return the List<Book> associated to this Author.
So, at first request (query), we fetch an Author. The Author is detached. At second request (query), we want to load the Book associated to this Author. But, we don't want to load the Author again (for example, we don't care about lost updates of Author), we just want to load the associated Book in a single SELECT. A common (not recommended) approach is to load the Author again (e.g., via findById(author.getId())) and call the author.getBooks(). But, this end up in two SELECT statements. One SELECT for loading the Author, and another SELECT after we force the collection initialization. We force collection initialization because it will not be initialize if we simply return it. In order to trigger the collection initialization the developer call books.size() or he rely on Hibernate.initialize(books);.
But, we can avoid such solution by relying on an explicit JPQL or Query Builder property expressions. This way, there will be a single SELECT and no need to call size() or Hibernate.initialize();
Key points:
This item is detailed in my book, Spring Boot Persistence Best Practices.
Description: Behind the built-in Spring Data save() there is a call of EntityManager#persist() or EntityManager#merge(). It is important to know this aspect in several cases. Among this cases, we have the entity update case (simple update or update batching).
Consider Author and Book involved in a bidirectional-lazy @OneToMany association. And, we load an Author, detach it, update it in the detached state, and save it to the database via save() method. Calling save() will come with the following two issues resulting from calling merge() behind the scene:
SELECT (merge) and one UPDATESELECT will contain a LEFT OUTER JOIN to fetch the associated Book as well (we don't need the books!)How about triggering only the UPDATE instead of this? The solution relies on calling Session#update(). Calling Session.update() requires to unwrap the Session via entityManager.unwrap(Session.class).
Key points:
Session.update() will trigger only the UPDATE (there is no SELECT)Session.update() works with versioned optimistic locking mechanism as well (so, lost updates are prevented)StreamableDescription: This application is a sample of fetching Streamable<entity> and Streamable<dto>. But, more important, this application contains three examples of how to not use Streamable. It is very tempting and comfortable to fetch a Streamable result set and chop it via filter(), map(), flatMap(), and so on until we obtain only the needed data instead of writing a query (e.g., JPQL) that fetches exactly the needed result set from the database. Mainly, we just throw away some of the fetched data to keep only the needed data. But, is not advisable to follow such practices because fetching more data than needed can cause significant performance penalties.
Moreover, pay attention to combining two or more Streamable via the and() method. The returned result may be different from what you are expecting to see. Each Streamable produces a separate SQL statement and the final result set is a concatenation of the intermediate results sets (prone to duplicate values).
Key points:
map())filter())Streamable via and(); each Streamable produces a separate SQL statement and the final result set is a concatenation of the intermediate results sets (prone to duplicate values)Streamable Wrapper TypesDescription: A common practice consists of exposing dedicated wrappers types for collections resulted after mapping a query result set. This way, on a single query execution, the API can return multiple results. After we call a query-method that return a collection, we can pass it to a wrapper class by manually instantiation of that wrapper-class. But, we can avoid the manually instantiation if the code respects the following key points.
Key points:
Streamablestatic factory method named of(…) or valueOf(…) taking Streamable as argumentDescription: JPA 2.1 come with schema generation features. This feature can setup the database or export the generated commands to a file. The parameters that we should set are:
spring.jpa.properties.javax.persistence.schema-generation.database.action: Instructs the persistence provider how to setup the database. Possible values include: none, create, drop-and-create, drop
javax.persistence.schema-generation.scripts.action: Instruct the persistence provider which scripts to create. Possible values include: none, create, drop-and-create, drop.
javax.persistence.schema-generation.scripts.create-target: Indicate the target location of the create script generated by the persistence provider. This can be as a file URL or a java.IO.Writer.
javax.persistence.schema-generation.scripts.drop-target: Indicate the target location of the drop script generated by the persistence provider. This can be as a file URL or a java.IO.Writer.
Moreover, we can instruct the persistence provider to load data from a file into the database via: spring.jpa.properties.javax.persistence.sql-load-script-source. The value of this property represents the file location and it can be a file URL or a java.IO.Writer.
Key points:
application.propertiesDescription: Sometimes, we need to write in repositories certain query-methods that return a Map instead of a List or a Set. For example, when we need a Map<Id, Entity> or we use GROUP BY and we need a Map<Group, Count>. This application shows you how to do it via default methods directly in repository.
Key points:
default methods and Collectors.toMap()Description: Consider one of the JPA inheritance strategies (e.g., JOINED). Handling entities inheritance With Spring Data repositories can be done as follows:
Description: This application is a sample of logging only slow queries via Hibernate 5.4.5, hibernate.session.events.log.LOG_QUERIES_SLOWER_THAN_MS property. A slow query is a query that has an execution time bigger than a specificed threshold in milliseconds.
Key points:
application.properties add hibernate.session.events.log.LOG_QUERIES_SLOWER_THAN_MSOutput example:
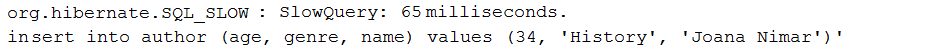
Description: Fetching more data than needed is prone to performance penalities. Using DTO allows us to extract only the needed data. In this application we rely on JDK14 Records feature and Spring Data Query Builder Mechanism.
From Openjdk JEP359:
Records provide a compact syntax for declaring classes which are transparent holders for shallowly immutable data.
Key points:
Define the AuthorDto as:
public record AuthorDto(String name, int age) implements Serializable {}
Description: Fetching more data than needed is prone to performance penalities. Using DTO allows us to extract only the needed data. In this application we rely on JDK 14 Records, Constructor Expression and JPQL.
From Openjdk JEP359:
Records provide a compact syntax for declaring classes which are transparent holders for shallowly immutable data.
Key points:
Define the AuthorDto as:
public record AuthorDto(String name, int age) implements Serializable {}
ResultTransformerDescription: Fetching more read-only data than needed is prone to performance penalties. Using DTO allows us to extract only the needed data. Sometimes, we need to fetch a DTO made of a subset of properties (columns) from a parent-child association. For such cases, we can use SQL JOIN that can pick up the desired columns from the involved tables. But, JOIN returns an List<Object[]> and most probably you will need to represent it as a List<ParentDto>, where a ParentDto instance has a List<ChildDto>. For such cases, we can rely on a custom Hibernate ResultTransformer. This application is a sample of writing a custom ResultTransformer.
As DTO, we rely on JDK 14 Records. From Openjdk JEP359:
Records provide a compact syntax for declaring classes which are transparent holders for shallowly immutable data.
Key points:
AuthorDto and BookDtoResultTransformer interfaceJdbcTemplate And ResultSetExtractorDescription: Fetching more data than needed is prone to performance penalities. Using DTO allows us to extract only the needed data. In this application we rely on JDK14 Records feature, JdbcTemplate and ResultSetExtractor.
From Openjdk JEP359:
Records provide a compact syntax for declaring classes which are transparent holders for shallowly immutable data.
Key points:
AuthorDto and BookDtoJdbcTemplate and ResultSetExtractorDescription: This application is a sample of using dynamic Spring projections via DTO classes.
Key points:
<T> List<T> findByGenre(String genre, Class<T> type);)| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
|
CompletableFuture And Return List<S>Description: This application is a sample of using CompletableFuture for batching inserts. This CompletableFuture uses an Executor that has the number of threads equal with the number of your computer cores. Usage is in Spring style. It returns List<S>:
CompletableFuture And Return List<S> (1)CompletableFuture And Return List<S> (2)Description: This application is an example of causing a database deadlock in MySQL. This application produces an exception of type: com.mysql.cj.jdbc.exceptions.MySQLTransactionRollbackException: Deadlock found when trying to get lock; try restarting transaction. However, the database will retry until transaction (A) succeeds.
Key points:
SELECT with PESSIMISTIC_WRITE to acquire an exclusive lock to table authorauthor genre with success and sleeps for 10sSELECT with PESSIMISTIC_WRITE to acquire an exclusive lock to table bookbook title with success and sleeps for 10sDescription: This application is a proof of concept of how to define a composite key having an explicit part (name) and a generated part (authorId via SEQUENCE generator).
Key points:
@IdClassDescription: Sometimes we need to intercept the generated SQL that originates from Spring Data, EntityManager, Criteria API, JdbcTemplate and so on. This can be done as in this sample application. After interception, you can log, modify or even return a brand new SQL that will be executed in the end.
Key points:
StatementInspector SPIapplication.properties via spring.jpa.properties.hibernate.session_factory.statement_inspector281.Force inline params in Criteria API
NOTE Use this with high precaution since you open the gate for SQL injections.
Description: Sometimes we need to force inline params in Criteria API. By default, numeric parameters are inlined, but string parameters are not.
Key points:
application.properties the setting spring.jpa.properties.hibernate.criteria.literal_handling_mode as inlineDescription: Arthur Gavlyukovskiy provide a suite of Spring Boot starters for quickly integrate P6Spy, Datasource Proxy, and FlexyPool. In this example, we add Datasource Proxy, but please consider this for more details.
Key points:
pom.xml, add the datasource-proxy-spring-boot-starter starterapplication.properties enable DEBUG level for loggingDescription: This application is an example of using Java records as embeddable. This is available starting with Hibernate 6.0, but it was refined to be more accessible and easy to use in Hibernate 6.2
Key points:
Contact)Author) via @EmbeddedAuthorDto)



