bean searcher
v4.3.5

English | 中文
Documentation:https://bs.zhxu.cn
阿里云最低 1 折:https://www.aliyun.com/minisite/goods?userCode=zugtbi5w
JueJin blogs:
Only one line of code to achieve:
Design thinking: Bean Searcher's thinking
Architecture:
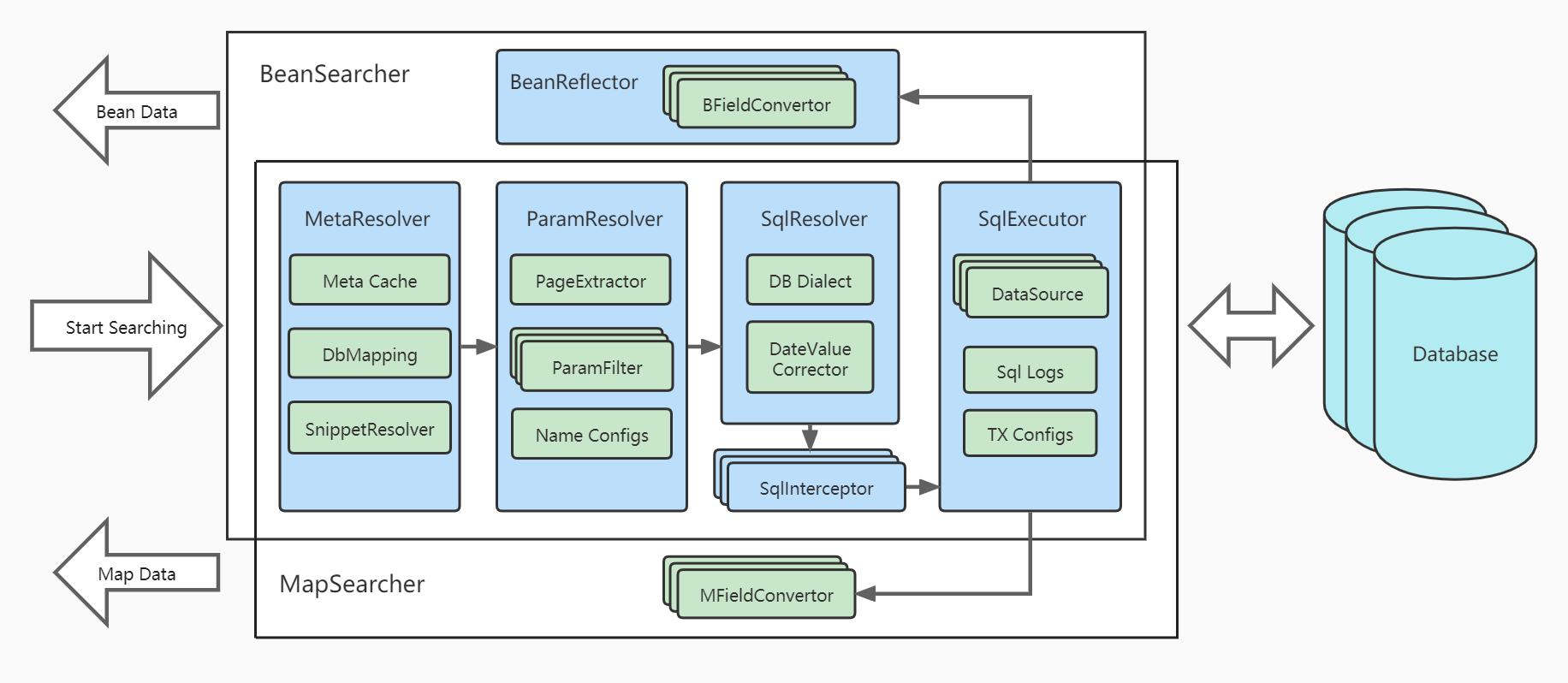
Although CREATE/UPDATE/DELETE are the strengths of Hibernate, MyBatis, DataJDBC and other ORM, queries, especially complex list queries with multi conditions, multi tables, paging, sorting, have always been their weaknesses.
Traditional ORM is difficult to realize a complex list retrieval with less code, but Bean Searcher has made great efforts in this regard. These complex queries can be solved in almost one line of code.
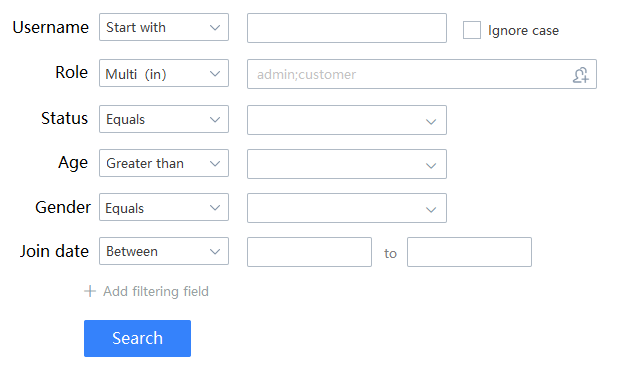
The back-end needs to write a retrieval API, and if it is written with traditional ORM, the complexity of the code is very high
But Bean Searcher can:
First, you have an Entity class:
@SearchBean(tables="user u, role r", joinCond="u.role_id = r.id", autoMapTo="u")
public class User {
private long id;
private String username;
private int status;
private int age;
private String gender;
private Date joinDate;
private int roleId;
@DbField("r.name")
private String roleName;
// Getters and setters...
}Then you can complete the API with one line of code :
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private BeanSearcher beanSearcher; // Inject BeanSearcher
@GetMapping("/index")
public SearchResult<User> index(HttpServletRequest request) {
// Only one line of code written here
return beanSearcher.search(User.class, MapUtils.flat(request.getParameterMap()), new String[]{ "age" });
}
}This line of code can achieve:
age fieldFor example, this API can be requested as follows:
GET: /user/index
Retrieving by default pagination:
{
"dataList": [
{
"id": 1,
"username": "Jack",
"status": 1,
"age": 25,
"gender": "Male",
"joinDate": "2021-10-01",
"roleId": 1,
"roleName": "User"
},
... // 15 records default
],
"totalCount": 100,
"summaries": [
2500 // age statistics
]
}GET: /user/index? page=1 & size=10
Retrieval by specified pagination
GET: /user/index? status=1
Retrieval with status = 1 by default pagination
GET: /user/index? name=Jac & name-op=sw
Retrieval with name starting with Jac by default pagination
GET: /user/index? name=Jack & name-ic=true
Retrieval with name = Jack(case ignored) by default pagination
GET: /user/index? sort=age & order=desc
Retrieval sorting by age descending and by default pagination
GET: /user/index? onlySelect=username,age
Retrieval username,age only by default pagination:
{
"dataList": [
{
"username": "Jack",
"age": 25,
},
... // 15 records default
],
"totalCount": 100,
"summaries": [
2500 // age statistics
]
}GET: /user/index? selectExclude=joinDate
Retrieving joinDate excluded default pagination
Map<String, Object> params = MapUtils.builder()
.selectExclude(User::getJoinDate) // Exclude joinDate field
.field(User::getStatus, 1) // Filter:status = 1
.field(User::getName, "Jack").ic() // Filter:name = 'Jack' (case ignored)
.field(User::getAge, 20, 30).op(Opetator.Between) // Filter:age between 20 and 30
.orderBy(User::getAge, "asc") // Sorting by age ascending
.page(0, 15) // Pagination: page=0 and size=15
.build();
List<User> users = beanSearcher.searchList(User.class, params);Demos:
Using Bean Searcher can greatly save the development time of the complex list retrieval apis!
domain, without defining new Entity
Bean Searcher can work with any JavaWeb frameworks, such as: SpringBoot, SpringMVC, Grails, Jfinal and so on.
All you need is to add a dependence:
implementation 'cn.zhxu:bean-searcher-boot-stater:4.3.4'and then you can inject Searcher into a Controller or Service:
/**
* Inject a MapSearcher, which retrieved data is Map objects
*/
@Autowired
private MapSearcher mapSearcher;
/**
* Inject a BeanSearcher, which retrieved data is generic objects
*/
@Autowired
private BeanSearcher beanSearcher;All you need is to add a dependence:
implementation 'cn.zhxu:bean-searcher-solon-plugin:4.3.4'and then you can inject Searcher into a Controller or Service:
/**
* Inject a MapSearcher, which retrieved data is Map objects
*/
@Inject
private MapSearcher mapSearcher;
/**
* Inject a BeanSearcher, which retrieved data is generic objects
*/
@Inject
private BeanSearcher beanSearcher;Adding this dependence:
implementation 'cn.zhxu:bean-searcher:4.3.4'then you can build a Searcher with SearcherBuilder:
DataSource dataSource = ... // Get the dataSource of the application
// DefaultSqlExecutor suports multi datasources
SqlExecutor sqlExecutor = new DefaultSqlExecutor(dataSource);
// build a MapSearcher
MapSearcher mapSearcher = SearcherBuilder.mapSearcher()
.sqlExecutor(sqlExecutor)
.build();
// build a BeanSearcher
BeanSearcher beanSearcher = SearcherBuilder.beanSearcher()
.sqlExecutor(sqlExecutor)
.build();You can customize and extend any component in Bean Searcher .
For example:
FieldOp to support other field operatorDbMapping to support other ORM‘s annotationsParamResolver to support JSON query paramsFieldConvertor to support any type of fieldDialect to support more databaseReference :https://bs.zhxu.cn
[ Sa-Token ] 一个轻量级 Java 权限认证框架,让鉴权变得简单、优雅!
[ Fluent MyBatis ] MyBatis 语法增强框架, 综合了 MyBatisPlus, DynamicSql,Jpa 等框架的特性和优点,利用注解处理器生成代码
[ OkHttps ] 轻量却强大的 HTTP 客户端,前后端通用,支持 WebSocket 与 Stomp 协议
[ hrun4j ] 接口自动化测试解决方案 --工具选得好,下班回家早;测试用得对,半夜安心睡
[ JsonKit ] 超轻量级 JSON 门面工具,用法简单,不依赖具体实现,让业务代码与 Jackson、Gson、Fastjson 等解耦!
[ Free UI ] 基于 Vue3 + TypeScript,一个非常轻量炫酷的 UI 组件库 !
git checkout -b feat/xxxx
git commit -am 'feat(function): add xxxxx'
git push origin feat/xxxx
pull request


