similarity
1.1.6
similarity, compute similarity score between text strings, Java written.
Similarity, a similarity calculation toolkit, can be used for text similarity calculation, sentiment analysis, etc., written in Java.
Similarity is a Java version of similarity calculation toolkit composed of a series of algorithms. The goal is to spread the similarity calculation method in natural language processing. Similarity has the characteristics of practical tools, efficient performance, clear structure, up-to-date corpus, and customizability.
Similarity provides the following functionality:
Word similarity calculation
Phrase similarity calculation
Sentence similarity calculation
Paragraph similarity calculation
CNKI Yiyuan
sentiment analysis
Approximate words
While providing rich functions, Similarity's internal modules insist on low coupling, models insist on lazy loading, and dictionaries insist on publishing in plain text. They are easy to use and help users train their own corpora.
Introduce Jar package
< repositories >
< repository >
< id >jitpack.io</ id >
< url >https://jitpack.io</ url >
</ repository >
</ repositories >< dependency >
< groupId >com.github.shibing624</ groupId >
< artifactId >similarity</ artifactId >
< version >1.1.6</ version >
</ dependency >Introduction of gradle:
import org . xm . Similarity ;
import org . xm . tendency . word . HownetWordTendency ;
public class demo {
public static void main ( String [] args ) {
double result = Similarity . cilinSimilarity ( "电动车" , "自行车" );
System . out . println ( result );
String word = "混蛋" ;
HownetWordTendency hownetWordTendency = new HownetWordTendency ();
result = hownetWordTendency . getTendency ( word );
System . out . println ( word + " 词语情感趋势值:" + result );
}
}Text length: word granularity
It is recommended to use Cilin similarity: org.xm.Similarity.cilinSimilarity , which is a similarity calculation method based on synonyms Cilin
example: src/test/java/org.xm/WordSimilarityDemo.java
package org . xm ;
public class WordSimilarityDemo {
public static void main ( String [] args ) {
String word1 = "教师" ;
String word2 = "教授" ;
double cilinSimilarityResult = Similarity . cilinSimilarity ( word1 , word2 );
double pinyinSimilarityResult = Similarity . pinyinSimilarity ( word1 , word2 );
double conceptSimilarityResult = Similarity . conceptSimilarity ( word1 , word2 );
double charBasedSimilarityResult = Similarity . charBasedSimilarity ( word1 , word2 );
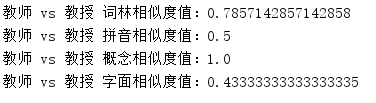
System . out . println ( word1 + " vs " + word2 + " 词林相似度值:" + cilinSimilarityResult );
System . out . println ( word1 + " vs " + word2 + " 拼音相似度值:" + pinyinSimilarityResult );
System . out . println ( word1 + " vs " + word2 + " 概念相似度值:" + conceptSimilarityResult );
System . out . println ( word1 + " vs " + word2 + " 字面相似度值:" + charBasedSimilarityResult );
}
}
Text Length: Phrase Granularity
It is recommended to use phrase similarity: org.xm.Similarity.phraseSimilarity , which is essentially a method of calculating the similarity of two phrases through the same characters and the positions of the same characters.
example: src/test/java/org.xm/PhraseSimilarityDemo.java
public static void main ( String [] args ) {
String phrase1 = "继续努力" ;
String phrase2 = "持续发展" ;
double result = Similarity . phraseSimilarity ( phrase1 , phrase2 );
System . out . println ( phrase1 + " vs " + phrase2 + " 短语相似度值:" + result );
}
Text length: sentence granularity
It is recommended to use word form and word order sentence similarity: org.xm.similarity.morphoSimilarity , a similarity method that not only considers the same text literal of two sentences, but also considers the order in which the same text appears.
example: src/test/java/org.xm/SentenceSimilarityDemo.java
public static void main ( String [] args ) {
String sentence1 = "中国人爱吃鱼" ;
String sentence2 = "湖北佬最喜吃鱼" ;
double morphoSimilarityResult = Similarity . morphoSimilarity ( sentence1 , sentence2 );
double editDistanceResult = Similarity . editDistanceSimilarity ( sentence1 , sentence2 );
double standEditDistanceResult = Similarity . standardEditDistanceSimilarity ( sentence1 , sentence2 );
double gregeorEditDistanceResult = Similarity . gregorEditDistanceSimilarity ( sentence1 , sentence2 );
System . out . println ( sentence1 + " vs " + sentence2 + " 词形词序句子相似度值:" + morphoSimilarityResult );
System . out . println ( sentence1 + " vs " + sentence2 + " 优化的编辑距离句子相似度值:" + editDistanceResult );
System . out . println ( sentence1 + " vs " + sentence2 + " 标准编辑距离句子相似度值:" + standEditDistanceResult );
System . out . println ( sentence1 + " vs " + sentence2 + " gregeor编辑距离句子相似度值:" + gregeorEditDistanceResult );
}
Text length: paragraph granularity (a paragraph, 25 characters < length(text) < 500 characters)
It is recommended to use word form word order sentence similarity: org.xm.similarity.text.CosineSimilarity , a method that considers the same text in two paragraphs, weights it through word segmentation, word frequency and part-of-speech weights, and uses cosine to calculate similarity.
example: src/test/java/org.xm/similarity/text/CosineSimilarityTest.java
@ Test
public void getSimilarityScore () throws Exception {
String text1 = "对于俄罗斯来说,最大的战果莫过于夺取乌克兰首都基辅,也就是现任总统泽连斯基和他政府的所在地。目前夺取基辅的战斗已经打响。" ;
String text2 = "迄今为止,俄罗斯的入侵似乎没有完全按计划成功执行——英国国防部情报部门表示,在乌克兰军队激烈抵抗下,俄罗斯军队已经损失数以百计的士兵。尽管如此,俄军在继续推进。" ;
TextSimilarity cosSimilarity = new CosineSimilarity ();
double score1 = cosSimilarity . getSimilarity ( text1 , text2 );
System . out . println ( "cos相似度分值:" + score1 );
TextSimilarity editSimilarity = new EditDistanceSimilarity ();
double score2 = editSimilarity . getSimilarity ( text1 , text2 );
System . out . println ( "edit相似度分值:" + score2 );
}cos相似度分值:0.399143
edit相似度分值:0.0875example: src/test/java/org/xm/tendency/word/HownetWordTendencyTest.java
@ Test
public void getTendency () throws Exception {
HownetWordTendency hownet = new HownetWordTendency ();
String word = "美好" ;
double sim = hownet . getTendency ( word );
System . out . println ( word + ":" + sim );
System . out . println ( "混蛋:" + hownet . getTendency ( "混蛋" ));
}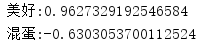
This example is word-granular sentiment polarity analysis based on sememe trees. Regarding text sentiment analysis, there is pytextclassifier, which uses deep neural network models and SVM classification algorithms to achieve better results.
example: src/test/java/org/xm/word2vec/Word2vecTest.java
@ Test
public void testHomoionym () throws Exception {
List < String > result = Word2vec . getHomoionym ( RAW_CORPUS_SPLIT_MODEL , "武功" , 10 );
System . out . println ( "武功 近似词:" + result );
}
@ Test
public void testHomoionymName () throws Exception {
String model = RAW_CORPUS_SPLIT_MODEL ;
List < String > result = Word2vec . getHomoionym ( model , "乔帮主" , 10 );
System . out . println ( "乔帮主 近似词:" + result );
List < String > result2 = Word2vec . getHomoionym ( model , "阿朱" , 10 );
System . out . println ( "阿朱 近似词:" + result2 );
List < String > result3 = Word2vec . getHomoionym ( model , "少林寺" , 10 );
System . out . println ( "少林寺 近似词:" + result3 );
}

Word2vec word vector training is a Java version of the word2vec training tool Word2VEC_java. The training corpus is the novel Tian Long Ba Bu, and synonyms are obtained through word vector implementation. Users can train custom corpus or use Chinese Wikipedia to train universal word vectors.
Text similarity measure

The licensing agreement is The Apache License 2.0, which is free for commercial use. Please attach a similarity link and licensing agreement to the product description.
The project code is still very rough. If you have any improvements to the code, you are welcome to submit it back to this project. Before submitting, please pay attention to the following two points:
testYou can then submit a PR.


