doc genius ai
v1.0

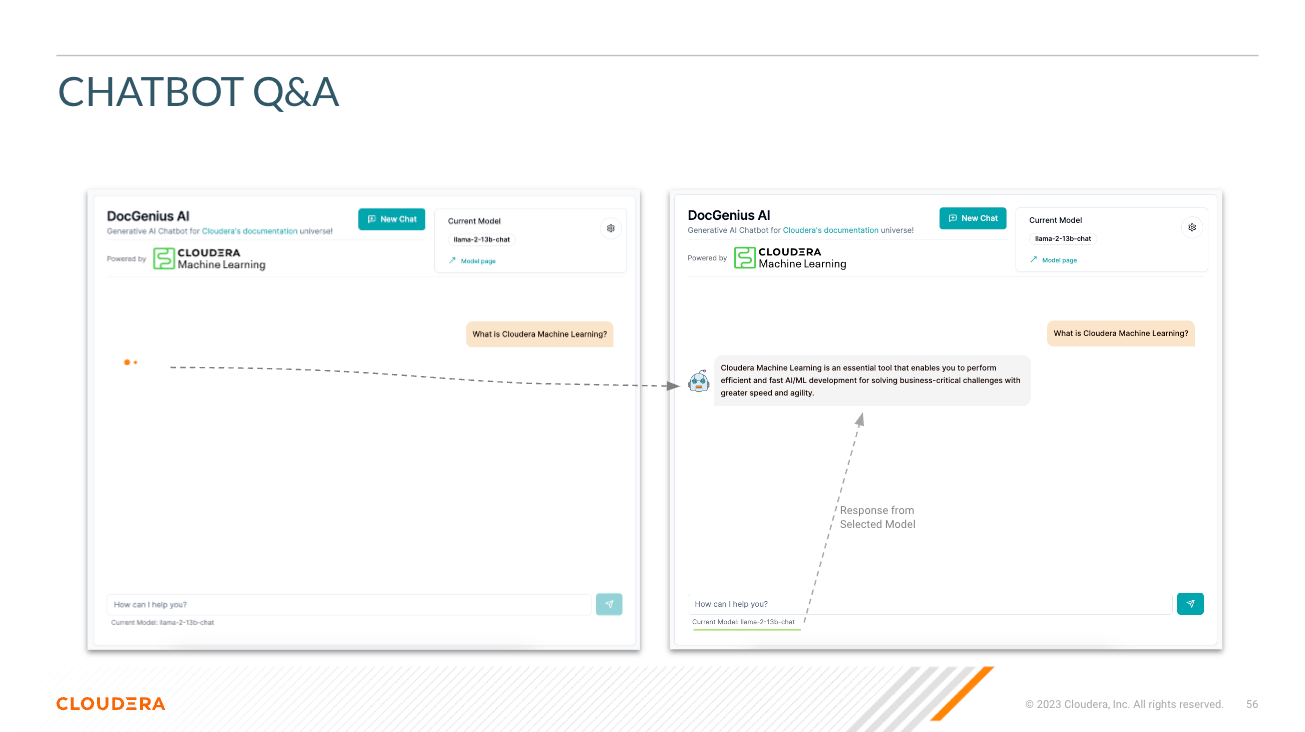
Select Model - Here the user can select the Llama3 70B parameter chat model (llama-3-70b)
Select Temperature (Randomness of Response) - Here the user can scale the randomness of the model's response. Lower numbers ensure a more approximate, objective answer while higher numbers encourage model creativity.
Select Number of Tokens (Length of Response) - Here several options have been provided. The number of tokens the user uses directly correlate with the length of the response the model returns.
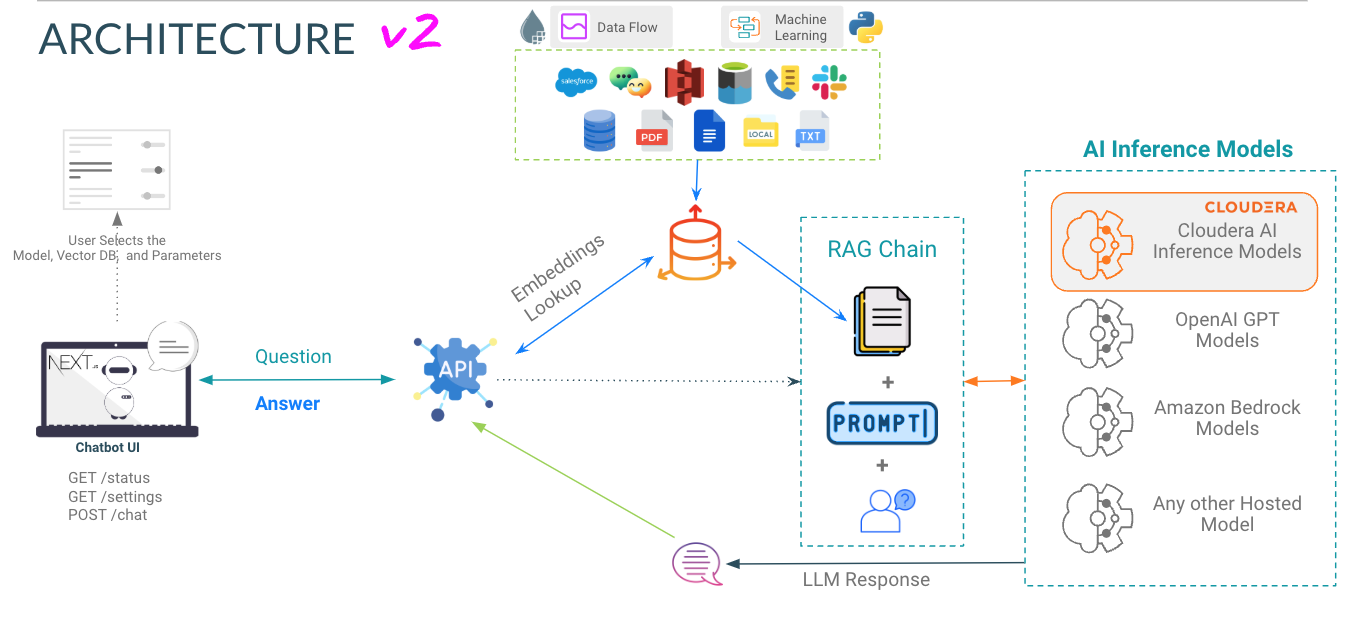
Question - Just as it sounds; this is where the user can provide a question to the model
Response - This is the response generated by the model given the context in your vector database. Note that if the question cannot correlate to content in your knowledge base, you may get hallucinated responses.
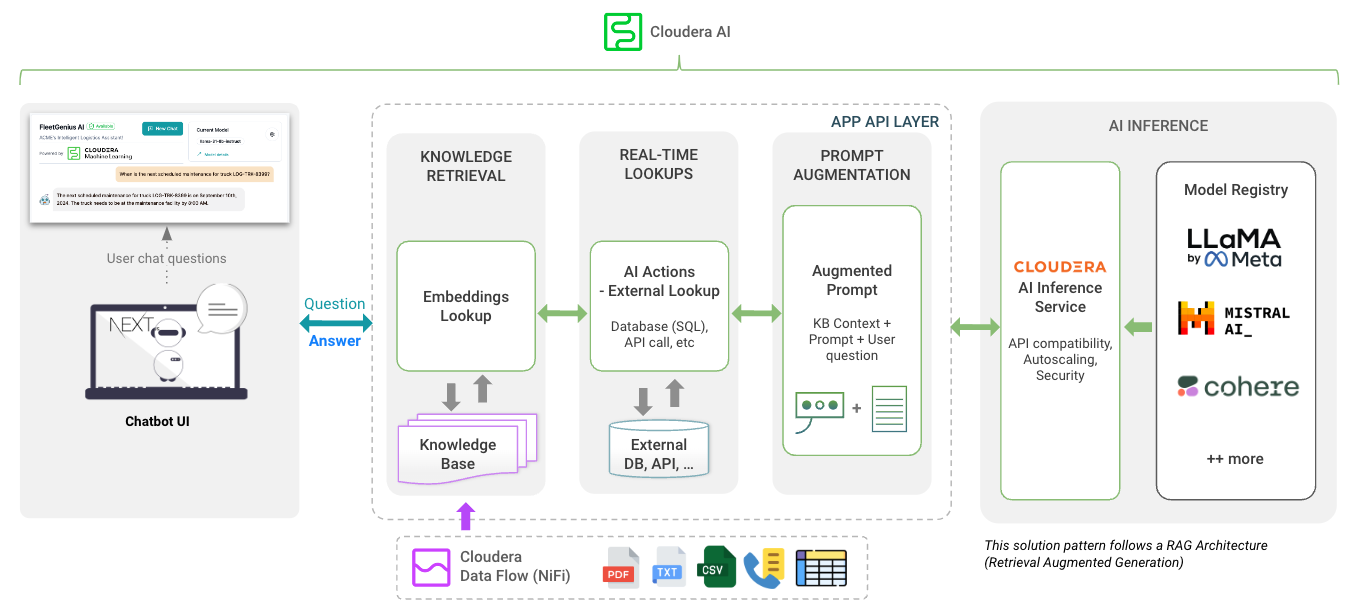
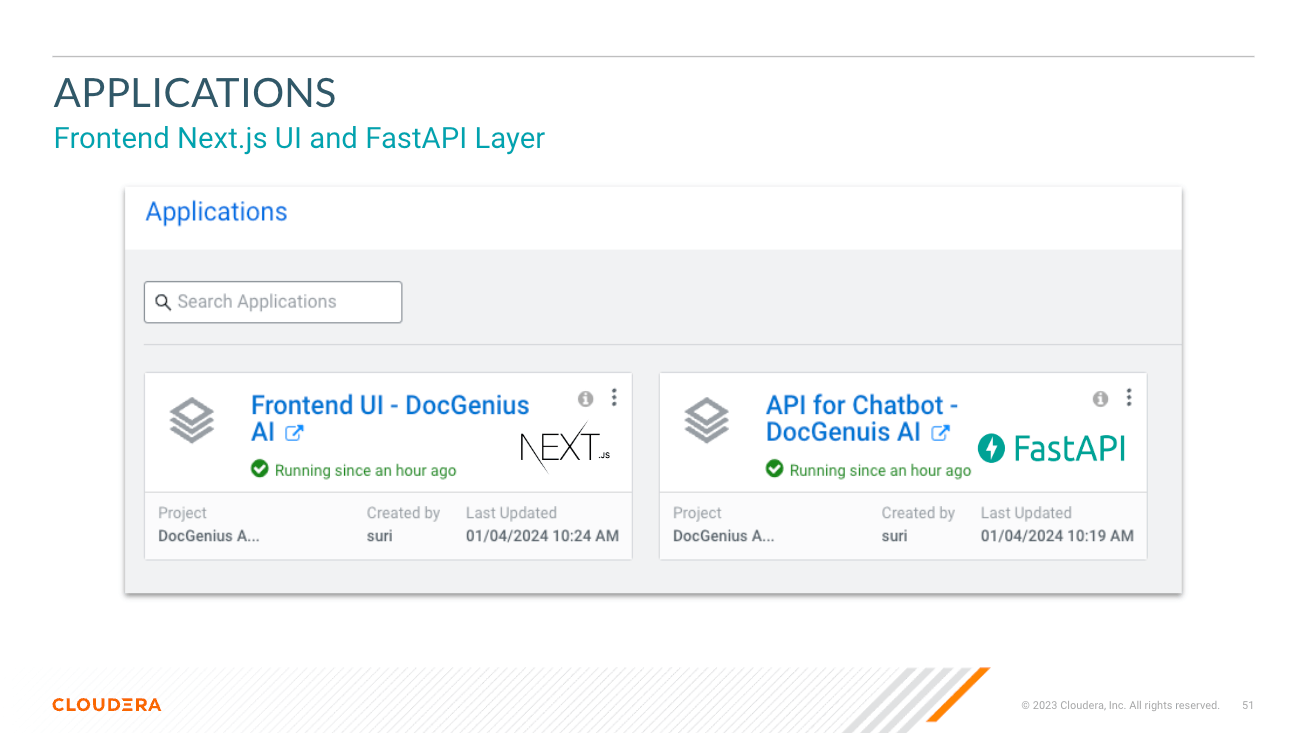
app directrory hosts the FastAPI for your LLMs
chat-ui directrory hosts the code for Chatbot UI.
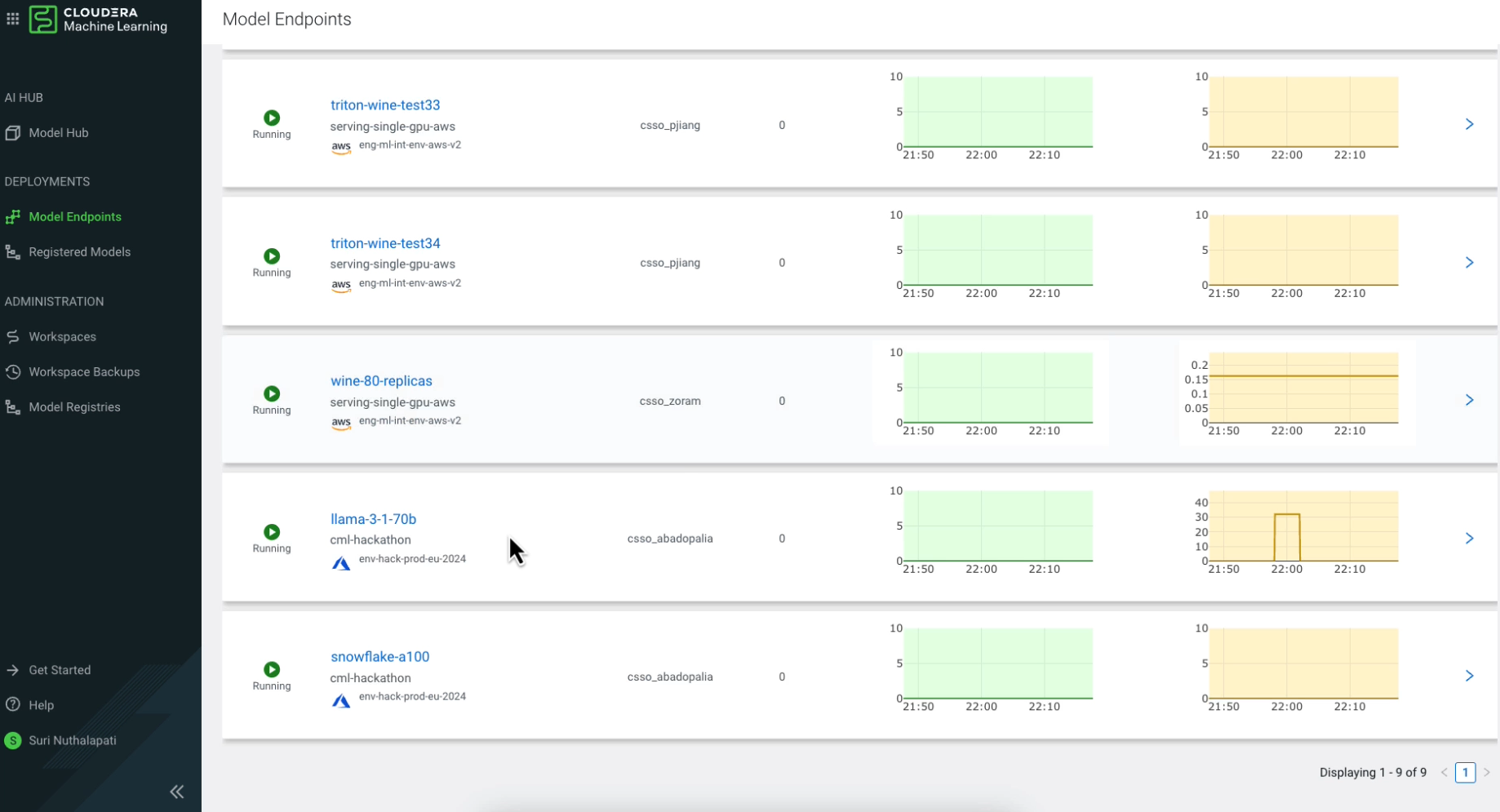
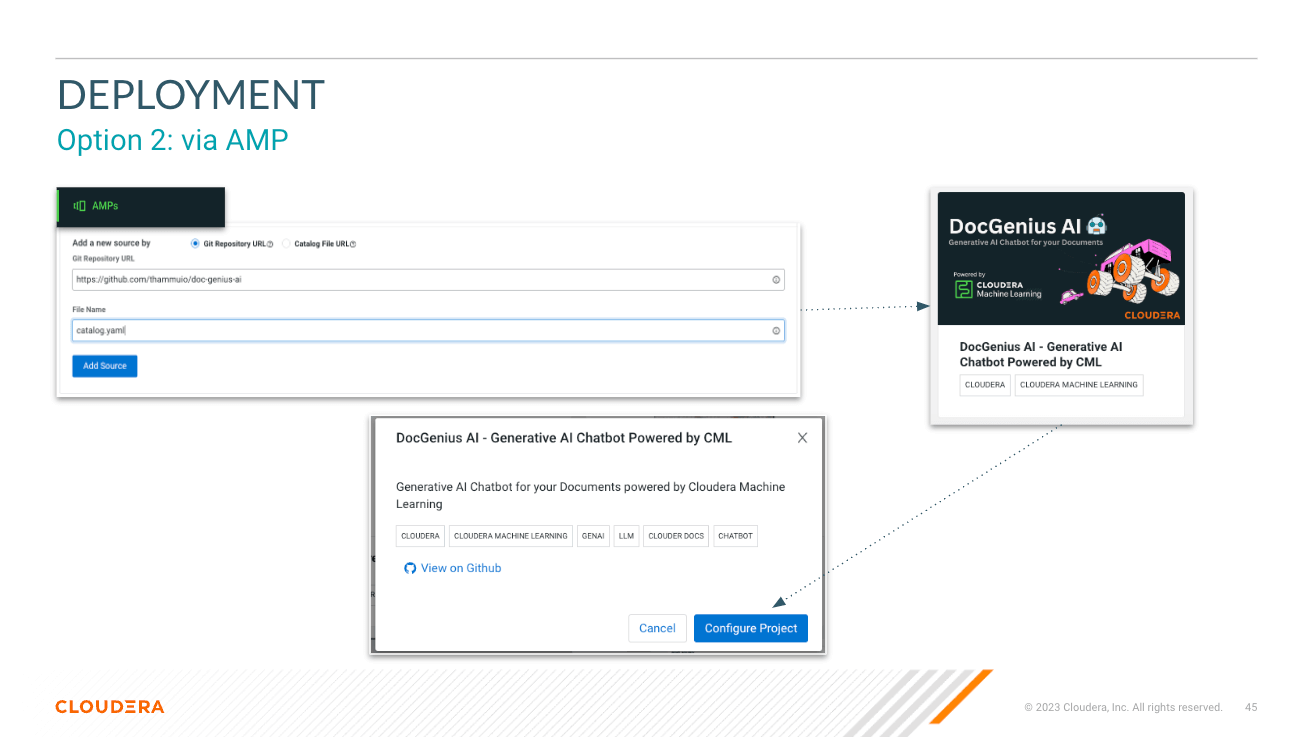
Look at Variables when Deploying the AMP. Refer Cloduera AI Inference Docs to Get Inference endpoint and Key.
JupyterLab - Python 3.11 - Nvidia GPU
https://docs.cloudera.com/machine-learning/cloud/applied-ml-prototypes/topics/ml-amp-project-spec.html
This creates the following workloads with resource requirements:
2 CPU, 16GB MEM
2 CPU, 8GB MEM
2 CPU, 1 GPU, 16GB MEM
doc-genius-ai/
├── app/ # Application directory for API and Model Serving
│ └── [..subdirs..]
│ └── chatbot/ # has the model serving python files for RAG, Prompt, Fine-tuning models
│ └── main.py # main.py file to start the API
├── chat-ui/ # Directory for the chatbot UI in Next.js
│ └── [..subdirs..]
│ └── app.py # app.py file to serve build files in .next directory via Flask
├── pipeline/ # Pipeline directory for data processing or workflow pipelines and vector load
├── data/ # Data directory for storing datasets or data files or RAG KB
├── models/ # Models directory for LLMs / ML models
├── session/ # Scripts for CML Sessions and Validation Tasks
├── images/ # Directory for storing project related images
├── api.md # Documentation for the APIs
├── README.md # Detailed description of the project
├── .gitignore # Specifies intentionally untracked files to ignore
├── catalog.yaml # YAML file that contains descriptive information and metadata for the displaying the AMP projects in the CML Project Catalog.
├─ .project-metadata.yaml # Project metadata file that provides configuration and setup details
├── cdsw-build.sh # Script for building the Model dependencies
└── requirements.txt # Python dependencies for Model Serving
IMPORTANT: Please read the following before proceeding. This AMP includes or otherwise depends on certain third party software packages. Information about such third party software packages are made available in the notice file associated with this AMP. By configuring and launching this AMP, you will cause such third party software packages to be downloaded and installed into your environment, in some instances, from third parties' websites. For each third party software package, please see the notice file and the applicable websites for more information, including the applicable license terms.
If you do not wish to download and install the third party software packages, do not configure, launch or otherwise use this AMP. By configuring, launching or otherwise using the AMP, you acknowledge the foregoing statement and agree that Cloudera is not responsible or liable in any way for the third party software packages.
Copyright (c) 2024 - Cloudera, Inc. All rights reserved.


