php rag
v1.1.0
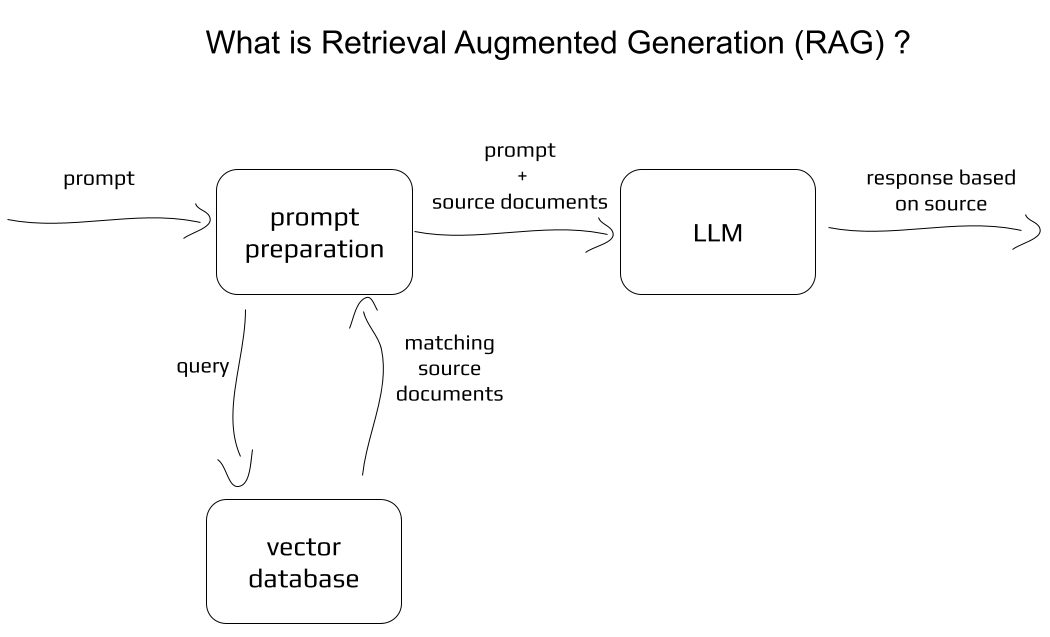
This application uses LLM (Large Language Model) GPT-4o accessed via OpenAI API in order to generate text based on the user input. The user input is used to retrieve relevant information from the database and then the retrieved information is used to generate the text. This approach combines power of transformers and access to source documents.
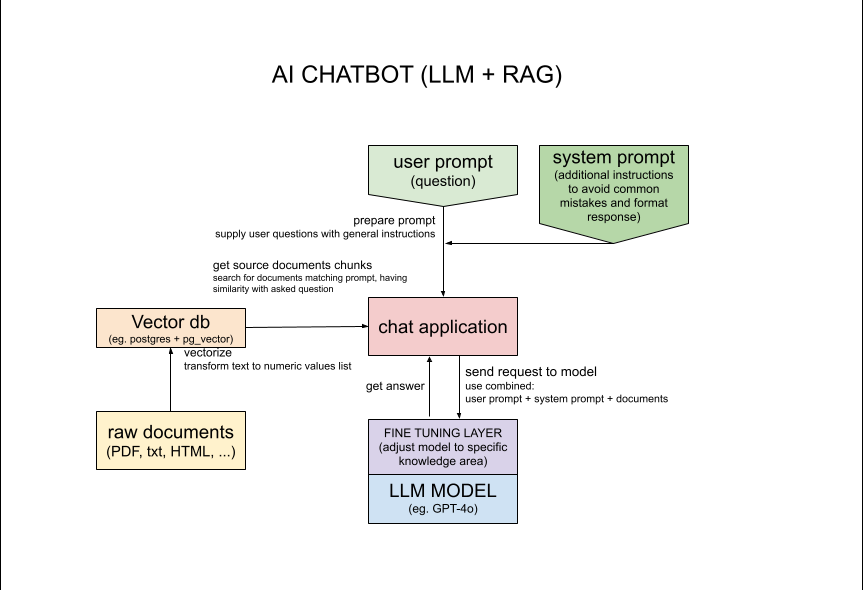
In this particular application the database of over 1000 websites is searched for information related to specific person. The real challenge here is that searched person "Michał Żarnecki" appears in 2 different contexts as 2 different people with same name. The goal is to not only find specific information but also understand the context and avoid mistakes like mixing information about 2 different people with same name.
I described concepts used in this application with more details in article on medium.com https://medium.com/@michalzarnecki88/a-guide-to-using-llm-retrieval-augmented-generation-with-php-3bff25ce6616
For setup you need to first have installed Docker and Docker Compose https://docs.docker.com/compose/install/
Run in CLI: cd app/src && composer install
Setup language model - choose from options below:option with OpenAI API
"A" with free model via local ollama API3
"B" with OpenAI API
Option B is simpler and requires less resources CPU and RAM, but you need OpenAI API key https://platform.openai.com/settings/profile?tab=api-keys
Option A requires more resources CPU and RAM, but you can run it locally using ollama API. For this option it's good to have GPU.
Follow the instructions for preferred option A or B below:
If you want to setup ollama locally, please use instructions at the bottom of this file, but in case of using docker it won't be needed.
*Ollama provides local API serving LLMs:
"Get up and running with large language models."
https://ollama.com/
docker-compose up
*HINT: Script need to transform source documents first which can take even 30 min. I you want to save some time just remove part of documents from app/src/documents.
Wait until containers setup finishes - you should see in the console logs:
php-app | Loaded documents complete
php-app | Postgres is ready - executing command
php-app | [Sat Nov 02 11:32:28.365214 2024] [core:notice] [pid 1:tid 1] AH00094: Command line: 'apache2 -D FOREGROUND'
You can use application as API by using requests as below:
Option A ollama:
curl -d '{"prompt":"what is result of 2+2?"}' -H "Content-Type: application/json" -X POST http://127.0.0.1:2037/processOllama.php?api
Option B OpenAI GPT:
curl -d '{"prompt":"what is result of 2+2?"}' -H "Content-Type: application/json" -X POST http://127.0.0.1:2037/processGpt.php?api
Run docker interactive docker exec -it php-app sh
Run in CLI: php minicli rag
Ask question
##### INPUT:
What is the result of 2 + 2?
##### RESPONSE:
The result of 2 + 2 is 4.
##### INPUT:
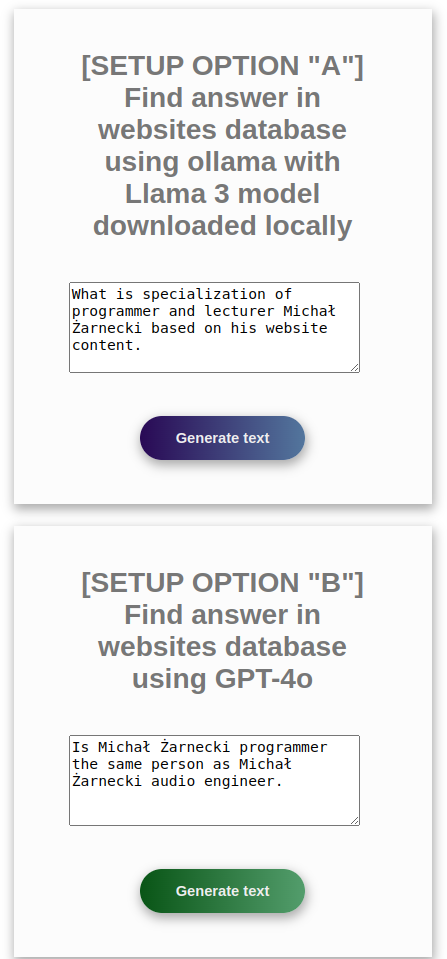
what is specialization of Michał Żarnecki based on his website content
##### RESPONSE:
Michał Żarnecki is a programmer and lecturer specializing in several key areas related to modern software development and data-driven technologies.
His expertise includes:
1. **Programming Languages**: Python, PHP, JavaScript.
2. **AI and Machine Learning**: Designing systems and solutions related to artificial intelligence and machine learning.
3. **Data Mining and Big Data**: Extracting valuable insights from large datasets.
4. **Natural Language Processing (NLP)**: Working on systems that understand and generate human language.
5. **Software Development Frameworks**: Utilizing various tools and frameworks such as Streamlit, TensorFlow, PyTorch, and langchain.
6. **Database Systems**: Implementing and working with databases like PostgreSQL, Elasticsearch, Neo4j, and others.
His portfolio highlights projects such as an AI chatbot for analyzing company documents and a self-driving vehicle based on TensorFlow and Raspberry Pi.
Additionally, he has contributed to conferences and created e-learning courses focused on machine learning, underscoring his dual role as a developer and educator.
##### INPUT:
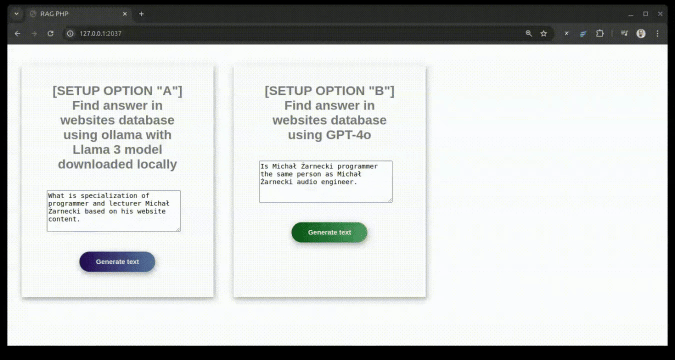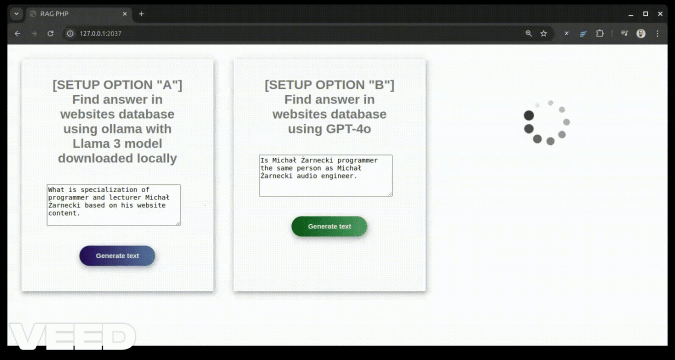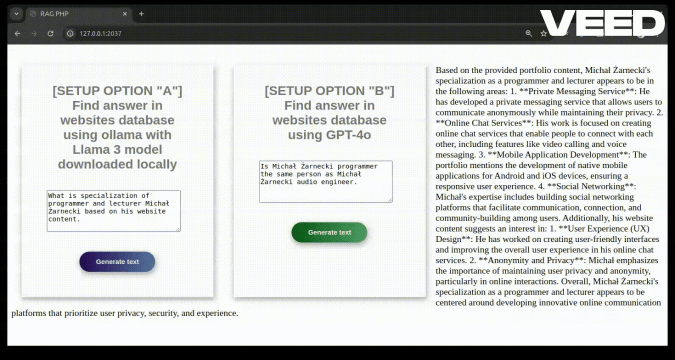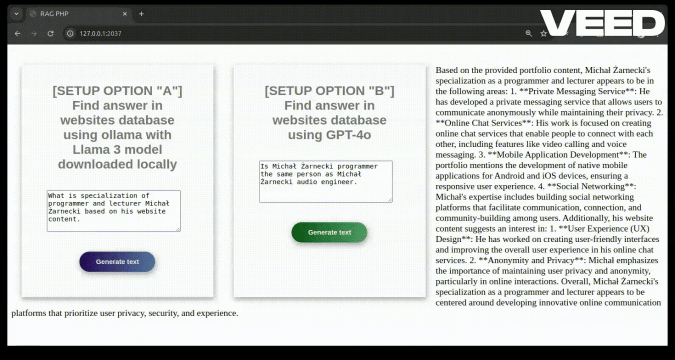
Is Michał Żarnecki programmer the same person as Michał Żarnecki audio engineer?
##### RESPONSE:
Based on the information provided, it appears that Michał Żarnecki the programmer and Michał Żarnecki the audio engineer are not the same person.
Here’s why:
1. **Fields of Expertise**:
- Michał Żarnecki, the audio engineer, was a well-known operator and reżyser dźwięku (sound director) in Poland, with notable contributions to the Polish film industry, as mentioned in the Wikipedia excerpt.
- Michal Żarnecki, the programmer, has a portfolio focused on programming in Python, PHP, and JavaScript, with projects related to AI, machine learning, data mining, and software development.
2. **Lifespan**:
- Michał Żarnecki the audio engineer was born on November 12, 1946, and passed away on November 21, 2016.
- The projects listed in Michał Żarnecki the programmer’s portfolio date from 2014 to 2016, which would be conflicting if he had passed away in 2016 and was actively working in those years.
3. **Occupational Focus**:
- The audio engineer has a career documented in film sound engineering and education.
- The programmer’s career is centered around software development, mobile applications, ERP systems, and consulting in technology.
Given the distinct differences in their professional domains, timelines, and expertise, it is highly unlikely that they are the same individual
Basic concept:
More details for nerds:
To speed up loading documents or use more of them for better retrieval manipulate $skipFirstN value in app/src/service/DocumentLoader.php:20
After changes to PHP scripts rebuild docker with commands:
docker-compose rm
docker rmi -f php-rag
docker-compose up
websites used to fill vector database come from "Website Classification" dataset on Kaggle author: Hetul Mehta link: https://www.kaggle.com/datasets/hetulmehta/website-classification?resource=download
related articles/repositories:
https://medium.com/mlearning-ai/create-a-chatbot-in-python-with-langchain-and-rag-85bfba8c62d2
https://github.com/Krisseck/php-rag
https://ollama.com/download
ollama pull llama3:latest
ollama pull mxbai-embed-large
ollama list
NAME ID SIZE MODIFIED
mxbai-embed-large:latest 468836162de7 669 MB 7 seconds ago
llama3:latest 365c0bd3c000 4.7 GB 17 seconds ago
ollama serve
app/src/loadDocuments.php (default)Please let me know if you find any issues or things to improve. You can contact me on email address [email protected]. Feel free to report bugs and propose upgrades in pull requests.


