Qmedia
1.0.0
English | 简体中文
Changelog - Report Issues - Request Feature
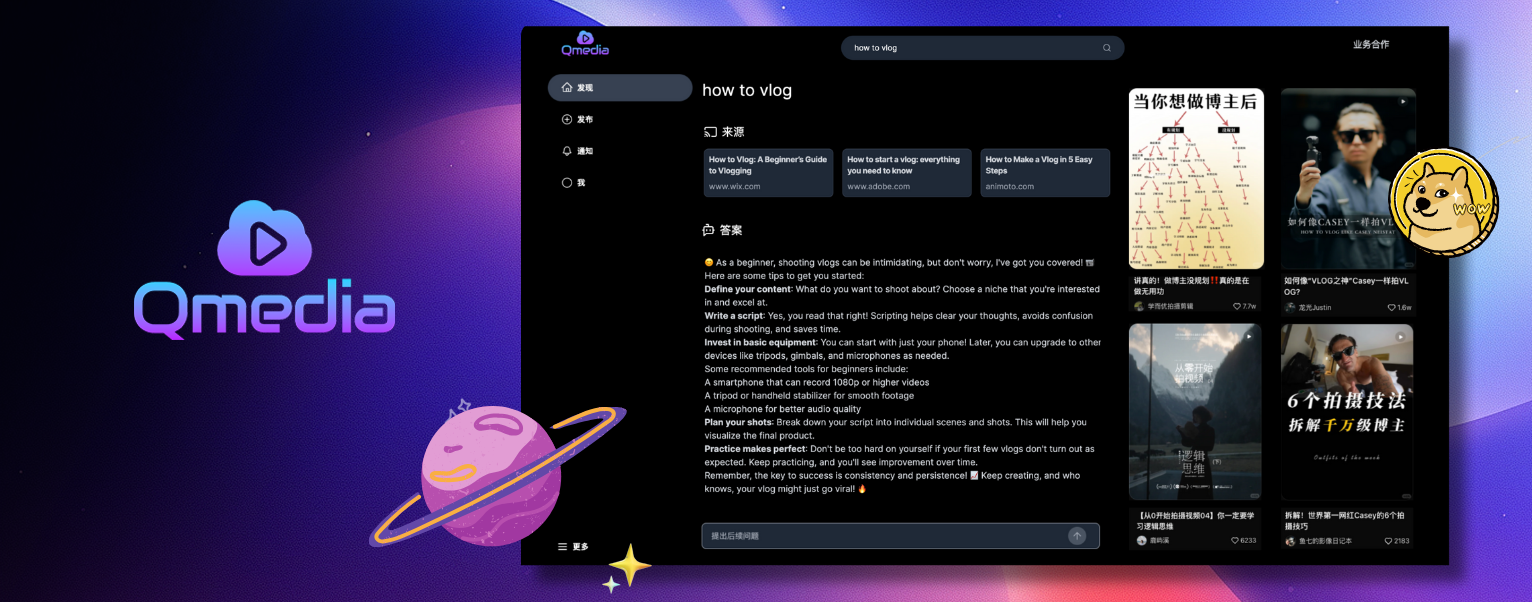
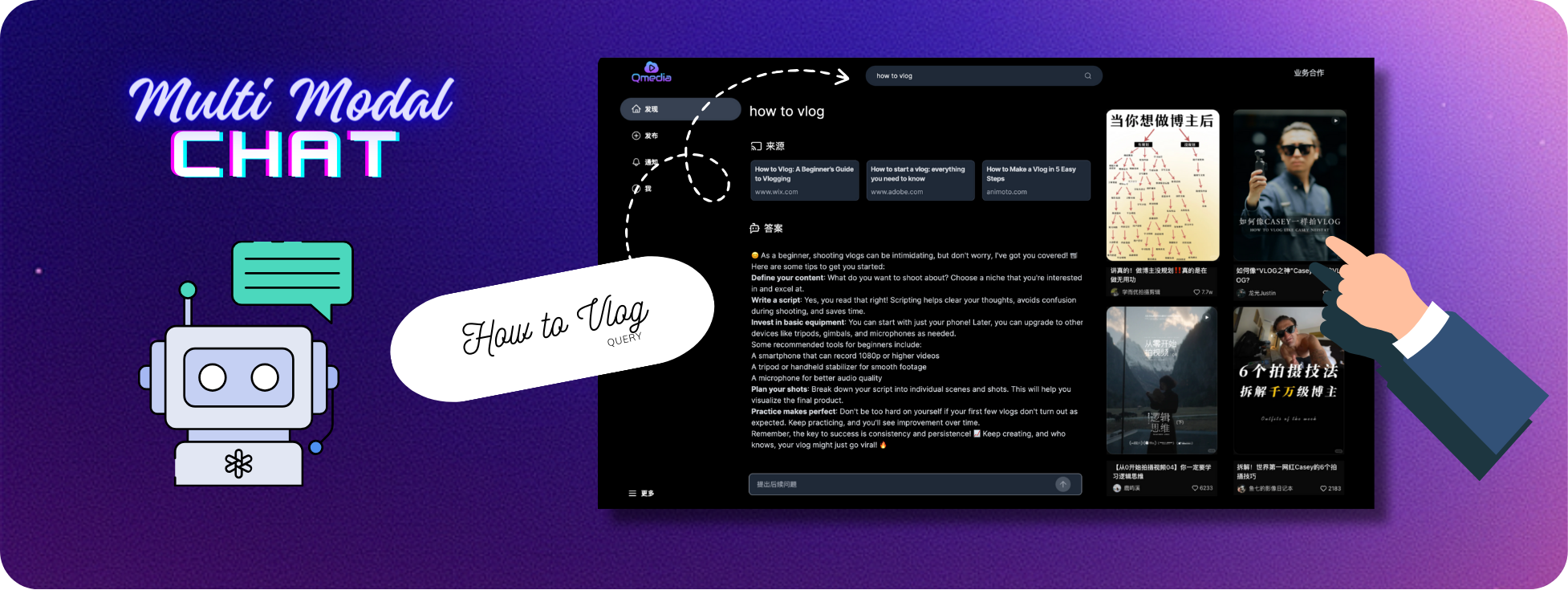
1 content cards2 multimodal content rag3 pure local multimodalmodelsQMedia is an open-source multimedia AI content search engine , provides rich information extraction methods for text/image and short video content. It integrates unstructured text/image and short video information to build a multimodal RAG content Q&A system. The aim is to share and exchange ideas on AI content creation in an open-source manner. issues
Share QMedia with your friends.
Spark new ideas for content creation
| Join our Discord community! | |
|---|---|
 |
Join our WeChat group ! |
Web Service inspired by XHS web version, implemented using the technology stack of Typescript, Next.js, TailwindCSS, and Shadcn/UIRAG Search/Q&A Service and Image/Text/Video Model Service implemented using the Python framework and LlamaIndex applicationsRAG Search/Q&A Service, and Image/Text/Video Model Service can be deployed separately for flexible deployment based on user resources, and can be embedded into other systems for image/text and video content extraction.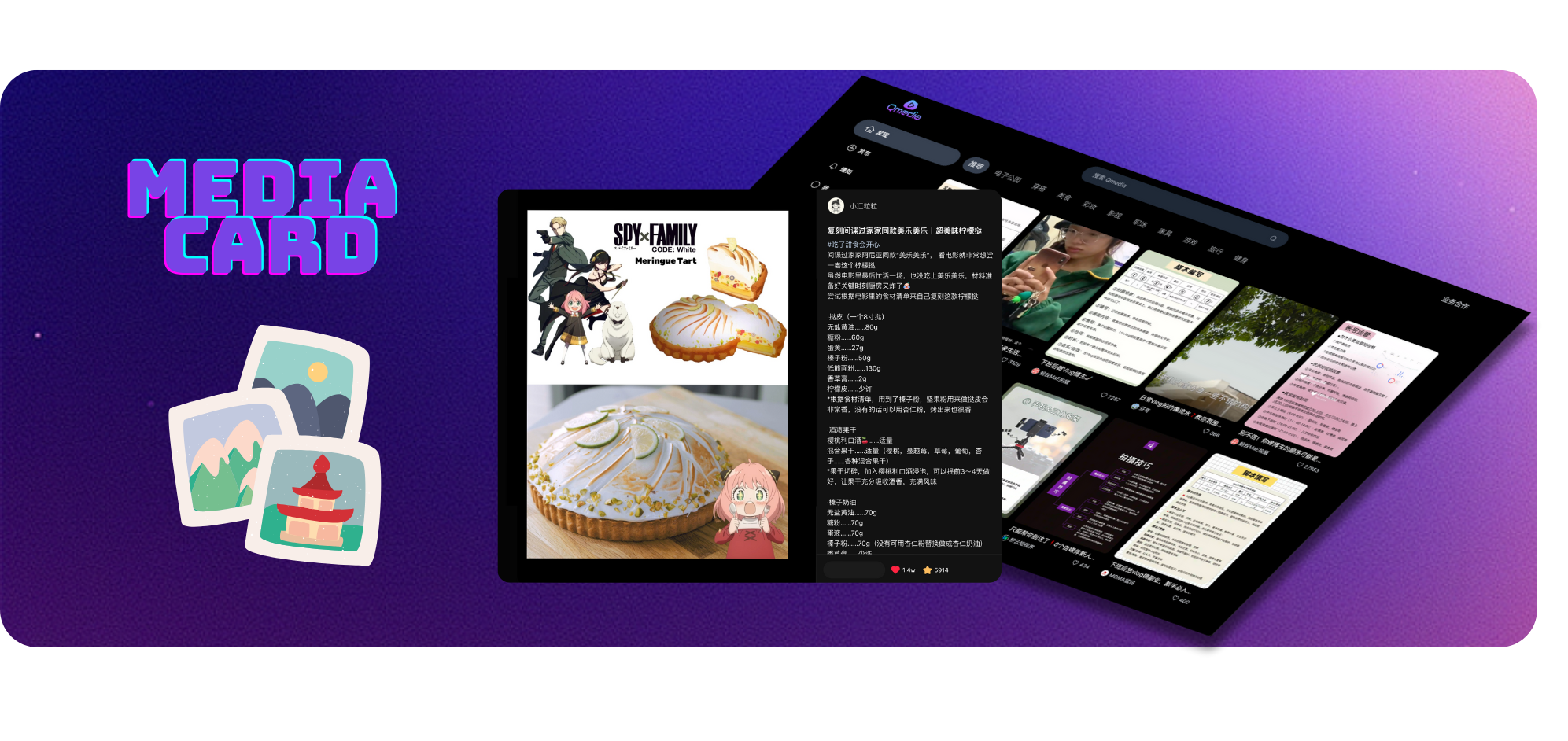
Deployment of various types of models locally Separation from the RAG application layer, making it easy to replace different models Local model lifecycle management, configurable for manual or automatic release to reduce server load
Language Models:
Feature Embedding Models:
Image Models:
Visual Understanding Models:
Video Models
QMedia services: Depending on resource availability, they can be deployed locally or the model services can be deployed in the cloud
Multimodal Model Service mm_server:
Multimodal model deployment and API calls
Ollama LLM models
Image models
Video models
Feature embedding models
Content Search and Q&A Service mmrag_server:
Content Card Display and Query
Image/Text/Short Video Content Extraction, Embedding, and Storage Service
Multimodal Data RAG Retrieval Service
Content Q&A Service
qmedia_web:
Language: TypeScript
Framework: Next.js
Styling: Tailwind CSS
Components: shadcn/uimm_server + qmedia_web + mmrag_server
Web Page Content Display, Content RAG Search and Q&A, Model Service
# Start mm_server service
cd mm_server
source activate qllm
python main.py
# Start mmrag_server service
cd mmrag_server
source activate qmedia
python main.py
# Start qmedia_web service
cd qmedia_web
pnpm devmmrag_server will read pseudo data from assets/medias and assets/mm_pseudo_data.json, and call mm_server to extract and structure the information from text/image and short videos into node information, which is then stored in the db. The retrieval and Q&A will be based on the data in the db.# assets file structure
assets
├── mm_pseudo_data.json # Content card data
└── medias # Image/Video filesReplace the contents in assets and delete the historically stored db file.
assets/medias contains image/video files, which can be replaced with your own image/video files.
assets/mm_pseudo_data.json contains content card data, which can be replaced with your own content card data. After running the service, the model will automatically extract the information and store it in the db.
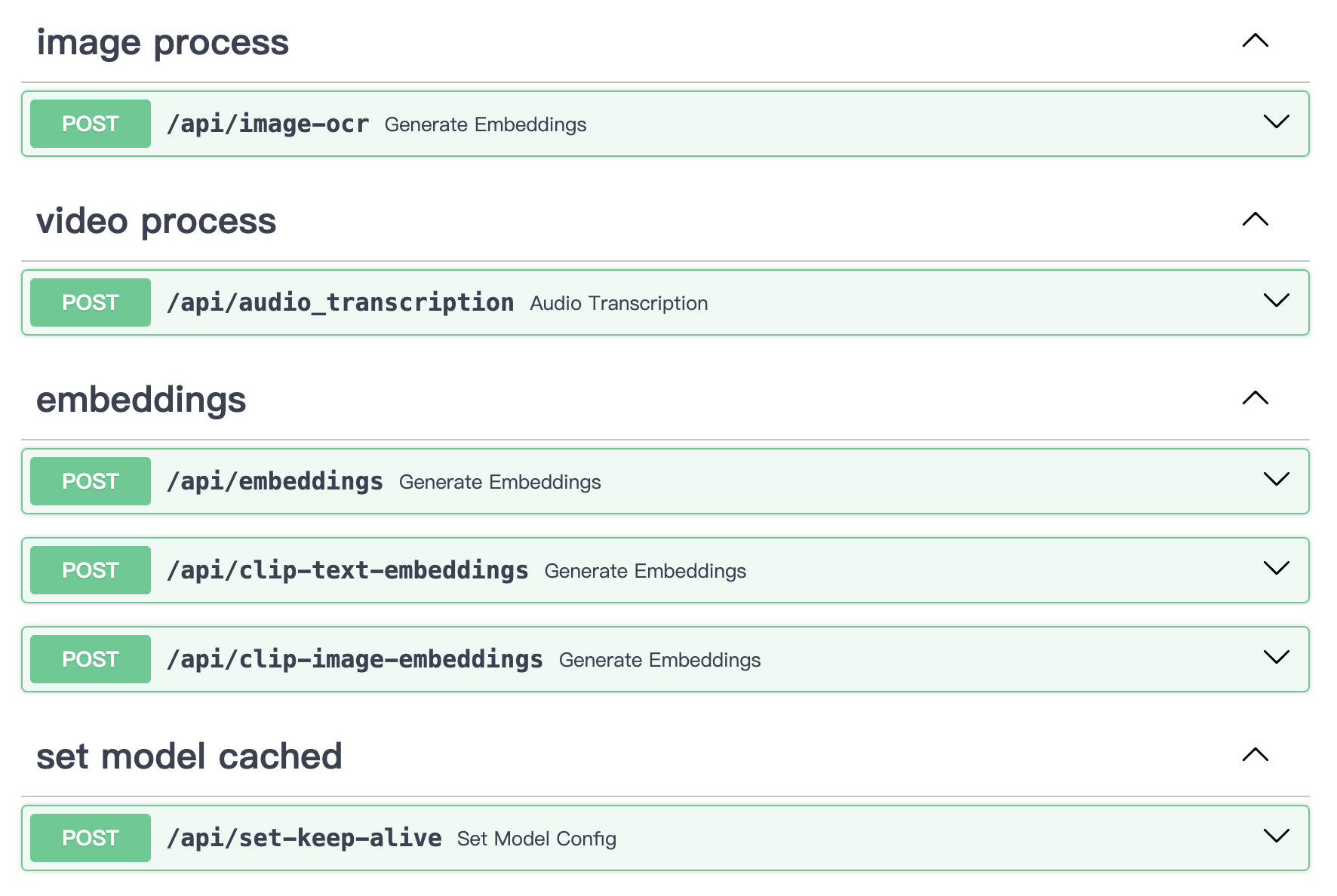
Can use the mm_server local image/text/video information extraction service independently.
It can be used as a standalone image encoding, text encoding, video transcription extraction, and image OCR service, accessible via API in any scenario.
# Start mm_server service independently
cd mm_server
python main.py
# uvicorn main:app --reload --host localhost --port 50110API Content:
Can use mm_server + qmedia_web together to perform content extraction and RAG retrieval in a pure Python environment via APIs.
# Start mmrag_server service independently
cd mmrag_server
python main.py
# uvicorn main:app --reload --host localhost --port 50110API Content:
QMedia is licensed under MIT License
Thanks to QAnything for strong OCR models.
Thanks to llava-llama3 for strong llm vision models.


