korpatbert
1.0.0
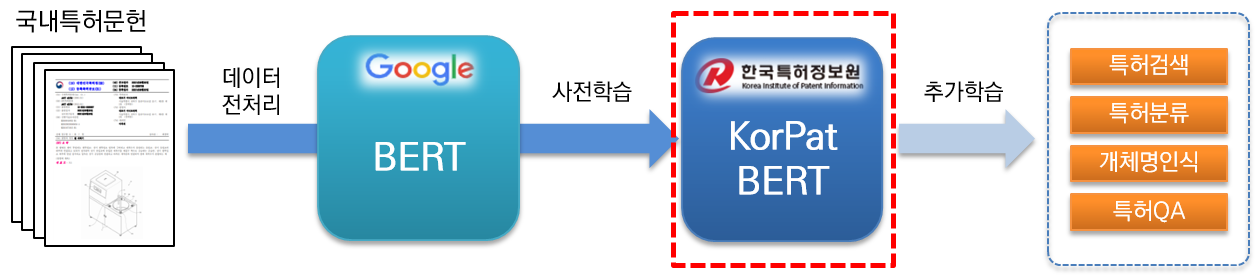
KorPatBERT (Korean Patent BERT) is an AI language model researched and developed by the Korea Patent Information Service.
In order to solve Korean natural language processing problems in the patent field and prepare intelligent information infrastructure in the patent industry, pre-training on a large amount of domestic patent documents (base: about 4.06 million documents, large: about 5.06 million documents) is based on the architecture of the existing Google BERT base model. (pre-training) and is provided free of charge.
It is a high-performance pre-trained language model specialized in the patent field and can be used in various natural language processing tasks.
[KorPatBERT-base]
[KorPatBERT-large]
[KorPatBERT-base]
[KorPatBERT-large]
Approximately 10 million major nouns and compound nouns were extracted from the patent documents used in language model learning, and these were added to the user dictionary of the Korean morpheme analyzer Mecab-ko and then divided into subwords through Google SentencePiece. This is a specialized MSP tokenizer (Mecab-ko Sentencepiece Patent Tokenizer).
| model | Top@1(ACC) |
|---|---|
| Google BERT | 72.33 |
| KorBERT | 73.29 |
| KOBERT | 33.75 |
| KrBERT | 72.39 |
| KorPatBERT-base | 76.32 |
| KorPatBERT-large | 77.06 |
| model | Top@1(ACC) | Top@3(ACC) | Top@5(ACC) |
|---|---|---|---|
| KorPatBERT-base | 61.91 | 82.18 | 86.97 |
| KorPatBERT-large | 62.89 | 82.18 | 87.26 |
| Program name | version | Installation guide path | Required? |
|---|---|---|---|
| python | 3.6 and above | https://www.python.org/ | Y |
| anaconda | 4.6.8 and higher | https://www.anaconda.com/ | N |
| tensorflow | 2.2.0 and higher | https://www.tensorflow.org/install/pip?hl=ko | Y |
| sentence piece | 0.1.96 or higher | https://github.com/google/sentencepiece | N |
| mecab-ko | 0.996-en-0.0.2 | https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/ | Y |
| mecab-ko-dic | 2.1.1 | https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/ | Y |
| mecab-python | 0.996-en-0.9.2 | https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/ | Y |
| python-mecab-ko | 1.0.11 or higher | https://pypi.org/project/python-mecab-ko/ | Y |
| keras | 2.4.3 and higher | https://github.com/keras-team/keras | N |
| bert_for_tf2 | 0.14.4 and higher | https://github.com/kpe/bert-for-tf2 | N |
| tqdm | 4.59.0 and higher | https://github.com/tqdm/tqdm | N |
| soynlp | 0.0.493 or higher | https://github.com/lovit/soynlp | N |
Installation URL: https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/
mecab-ko > 0.996-ko-0.9.2
mecab-ko-dic > 2.1.1
mecab-python > 0.996-ko-0.9.2
from korpat_tokenizer import Tokenizer
# (vocab_path=Vocabulary 파일 경로, cased=한글->True, 영문-> False)
tokenizer = Tokenizer(vocab_path="./korpat_vocab.txt", cased=True)
# 테스트 샘플 문장
example = "본 고안은 주로 일회용 합성세제액을 집어넣어 밀봉하는 세제액포의 내부를 원호상으로 열중착하되 세제액이 배출되는 절단부 쪽으로 내벽을 협소하게 형성하여서 내부에 들어있는 세제액을 잘짜질 수 있도록 하는 합성세제 액포에 관한 것이다."
# 샘플 토크나이즈
tokens = tokenizer.tokenize(example)
# 샘플 인코딩 (max_len=토큰 최대 길이)
ids, _ = tokenizer.encode(example, max_len=256)
# 샘플 디코딩
decoded_tokens = tokenizer.decode(ids)
# 결과 출력
print("Length of Token dictionary ===>", len(tokenizer._token_dict.keys()))
print("Input example ===>", example)
print("Tokenized example ===>", tokens)
print("Converted example to IDs ===>", ids)
print("Converted IDs to example ===>", decoded_tokens)
Length of Token dictionary ===> 21400
Input example ===> 본 고안은 주로 일회용 합성세제액을 집어넣어 밀봉하는 세제액포의 내부를 원호상으로 열중착하되 세제액이 배출되는 절단부 쪽으로 내벽을 협소하게 형성하여서 내부에 들어있는 세제액을 잘짜질 수 있도록 하는 합성세제 액포에 관한 것이다.
Tokenized example ===> ['[CLS]', '본', '고안', '은', '주로', '일회용', '합성', '##세', '##제', '##액', '을', '집', '##어넣', '어', '밀봉', '하', '는', '세제', '##액', '##포', '의', '내부', '를', '원호', '상', '으로', '열', '##중', '착하', '되', '세제', '##액', '이', '배출', '되', '는', '절단부', '쪽', '으로', '내벽', '을', '협소', '하', '게', '형성', '하', '여서', '내부', '에', '들', '어', '있', '는', '세제', '##액', '을', '잘', '짜', '질', '수', '있', '도록', '하', '는', '합성', '##세', '##제', '액', '##포', '에', '관한', '것', '이', '다', '.', '[SEP]']
Converted example to IDs ===> [5, 58, 554, 32, 2716, 6554, 817, 20418, 20308, 20514, 15, 732, 15572, 39, 1634, 12, 11, 5934, 20514, 20367, 9, 315, 16, 5922, 17, 33, 279, 20399, 16971, 26, 5934, 20514, 13, 674, 26, 11, 10132, 1686, 33, 3781, 15, 11950, 12, 64, 87, 12, 3958, 315, 10, 51, 39, 25, 11, 5934, 20514, 15, 1803, 12889, 399, 24, 25, 118, 12, 11, 817, 20418, 20308, 299, 20367, 10, 439, 56, 13, 18, 14, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Converted IDs to example ===> ['본', '고안', '은', '주로', '일회용', '합성', '##세', '##제', '##액', '을', '집', '##어넣', '어', '밀봉', '하', '는', '세제', '##액', '##포', '의', '내부', '를', '원호', '상', '으로', '열', '##중', '착하', '되', '세제', '##액', '이', '배출', '되', '는', '절단부', '쪽', '으로', '내벽', '을', '협소', '하', '게', '형성', '하', '여서', '내부', '에', '들', '어', '있', '는', '세제', '##액', '을', '잘', '짜', '질', '수', '있', '도록', '하', '는', '합성', '##세', '##제', '액', '##포', '에', '관한', '것', '이', '다', '.']
※ It is the same as the Google BERT base learning method, and for usage examples, please refer to section 2.3 특허분야 사전학습 언어모델(KorPatBERT) 사용자 매뉴얼 .
We are disseminating the language model of the Korea Patent Information Institute through certain procedures to organizations, companies, and researchers interested in it. Please fill out the application form and agreement according to the application procedure below and submit the application via email to the person in charge.
| file name | explanation |
|---|---|
| pat_all_mecab_dic.csv | Mecab Patent User Dictionary |
| lm_test_data.tsv | Classification sample data set |
| korpat_tokenizer.py | KorPat Tokenizer Program |
| test_tokenize.py | Tokenizer usage sample |
| test_tokenize.ipynb | Tokenizer usage sample (Jupiter) |
| test_lm.py | Language model usage sample |
| test_lm.ipynb | Language model usage sample (Jupyter) |
| korpat_bert_config.json | KorPatBERT Config File |
| korpat_vocab.txt | KorPatBERT Vocabulary Files |
| model.ckpt-381250.meta | KorPatBERT Model file |
| model.ckpt-381250.index | KorPatBERT Model file |
| model.ckpt-381250.data-00000-of-00001 | KorPatBERT Model file |


