auctus
1.0.0
This project is a web crawler and search engine for datasets, specifically meant for data augmentation tasks in machine learning. It is able to find datasets in different repositories and index them for later retrieval.
Documentation is available here
It is divided in multiple components:
datamart_geo. This contains data about administrative areas extracted from Wikidata and OpenStreetMap. It lives in its own repository and is used here as a submodule.datamart_profiler. This can be installed by clients, will allow the client library to profile datasets locally instead of sending them to the server. It is also used by the apiserver and profiler services.datamart_materialize. This is used to materialize dataset from the various sources that Auctus supports. It can be installed by clients, which will allow them to materialize datasets locally instead of using the server as a proxy.datamart_augmentation. This performs the join or union of two datasets and is used by the apiserver service, but could conceivably be used stand-alone.datamart_core. This contains common code for services. Only used for the server components. The filesystem locking code is separate as datamart_fslock for performance reasons (has to import fast).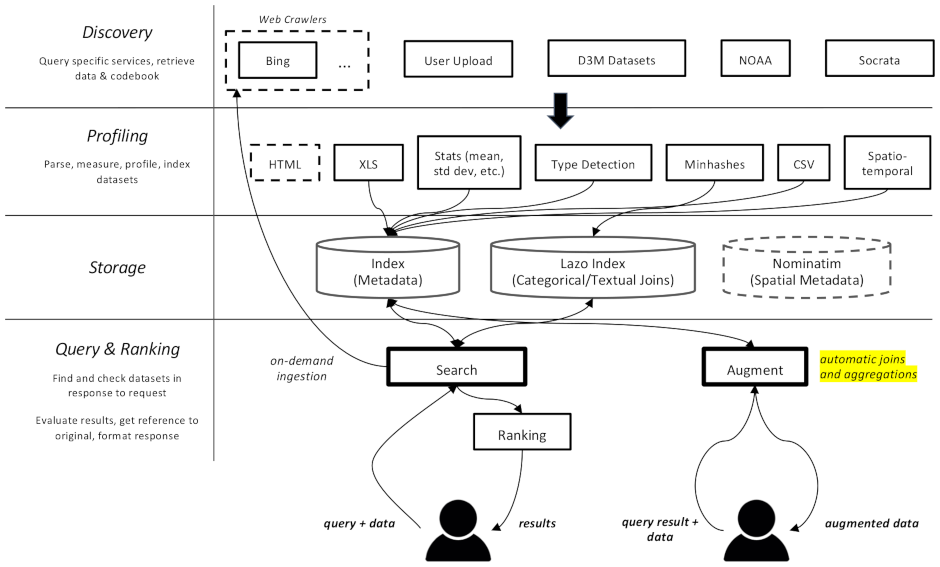
Elasticsearch is used as the search index, storing one document per known dataset.
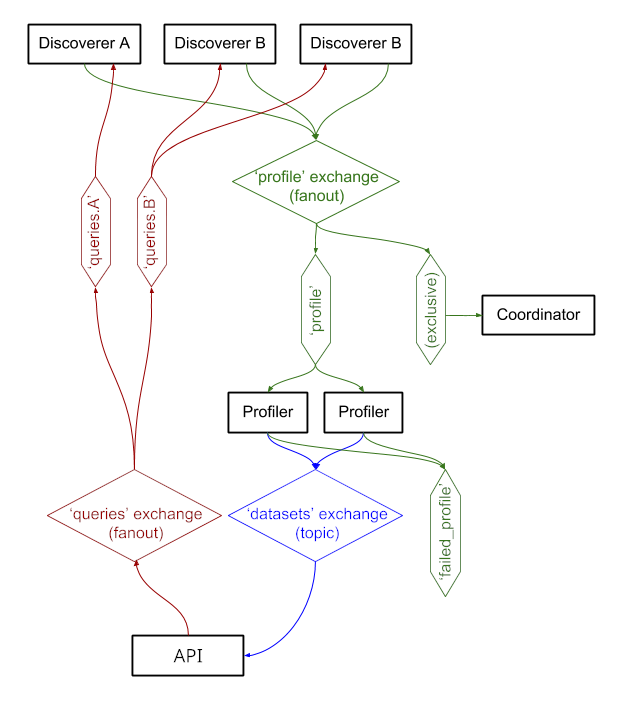
The services exchange messages through RabbitMQ, allowing us to have complex messaging patterns with queueing and retrying semantics, and complex patterns such as the on-demand querying.
The system is currently running at https://auctus.vida-nyu.org/. You can see the system status at https://grafana.auctus.vida-nyu.org/.
To deploy the system locally using docker-compose, follow those step:
Make sure you have checked out the submodule with git submodule init && git submodule update
Make sure you have Git LFS installed and configured (git lfs install)
Copy env.default to .env and update the variables there. You might want to update the password for a production deployment.
Make sure your node is set up for running Elasticsearch. You will probably have to raise the mmap limit.
The API_URL is the URL at which the apiserver containers will be visible to clients. In a production deployment, this is probably a public-facing HTTPS URL. It can be the same URL that the "coordinator" component will be served at if using a reverse proxy (see nginx.conf).
To run scripts locally, you can load the environment variables into your shell by running: . scripts/load_env.sh (that's dot space scripts...)
Run scripts/setup.sh to initialize the data volumes. This will set the correct permissions on the volumes/ subdirectories.
Should you ever want to start from scratch, you can delete volumes/ but make sure to run scripts/setup.sh again afterwards to set permissions.
$ docker-compose build --build-arg version=$(git describe) apiserver
$ docker-compose up -d elasticsearch rabbitmq redis minio lazo
These will take a few seconds to get up and running. Then you can start the other components:
$ docker-compose up -d cache-cleaner coordinator profiler apiserver apilb frontend
You can use the --scale option to start more profiler or apiserver containers, for example:
$ docker-compose up -d --scale profiler=4 --scale apiserver=8 cache-cleaner coordinator profiler apiserver apilb frontend
Ports:
$ scripts/docker_import_snapshot.sh
This will download an Elasticsearch dump from auctus.vida-nyu.org and import it into your local Elasticsearch container.
$ docker-compose up -d socrata zenodo
$ docker-compose up -d elasticsearch_exporter prometheus grafana
Prometheus is configured to automatically find the containers (see prometheus.yml)
A custom RabbitMQ image is used, with added plugins (management and prometheus).


