cape webservices
1.0.0
Entrypoint for all backend cape webservices.
Frontend demo is here (only works if you already launched a Backend).
Cape is a suite of open-source libraries to manage a question-answering model that answers questions by "reading" documents automatically. It is based on state-of-the-art machine reading models trained on massive datasets, and includes several mechanisms to make it easy to use and improve based on user feedback. It has been designed to be portable, i.e. works on a single laptop or on a cluster of parallel machines to speedup computation, and is Open Source friendly to be used at all expertise levels.
It enables users to
There are several ways to use Cape :
from cape_responder.responder_core import Responder
Responder.get_answers_from_documents('my-token','How easy is Cape to use', text ="Cape is an open source large-scale question answering system and is super easy to use!")
python3 -m cape_webservices.run
docker run -p 5050:5050 bloomsburyai/cape
We recommend at least 3GB of RAM and at least 2 modern CPU cores (4 if virtual). If you're using Docker, ensure you increase the memory resource limits in the Docker preferences.
You can run a standalone version of the webapp that includes a management dashboard. After installing docker, update and run the Cape image:
docker pull bloomsburyai/cape && docker run -ti -p 5050:5050 -p 5051:5051 bloomsburyai/cape
This will launch both the backend and the frontend webservices, by default it will also create tunnels for both, outputting the public urls:
RANDOM_STRING_HERE.ngrok.io?configuration={"api":{"backendURL":"https://RANDOM_STRING_HERE.ngrok.io:5050","timeout":"15000"}}Pull the latest version of the Docker image (it will take a few moments to download all dependencies and a machine reading model):
docker pull bloomsburyai/cape
Run the Docker container and launch an IPython console within it using the following command:
docker run -ti -p 5050:5050 -p 5051:5051 bloomsburyai/cape ipython3
Import Responder:
from cape_responder.responder_core import Responder
Ask a question and store the response (which is a list of answers) and display the first answer using: response = Responder.get_answers_from_documents('my-token','How easy is Cape to use?', text="Cape is an open source large-scale question answering system and is super easy to use!"); print(response[0]['answerText'])
If you are interested in understanding a bit more about what the response looks like, display the full response using: print(response)
To natively install Cape on a linux system, take a look at deployment/Dockerfile.
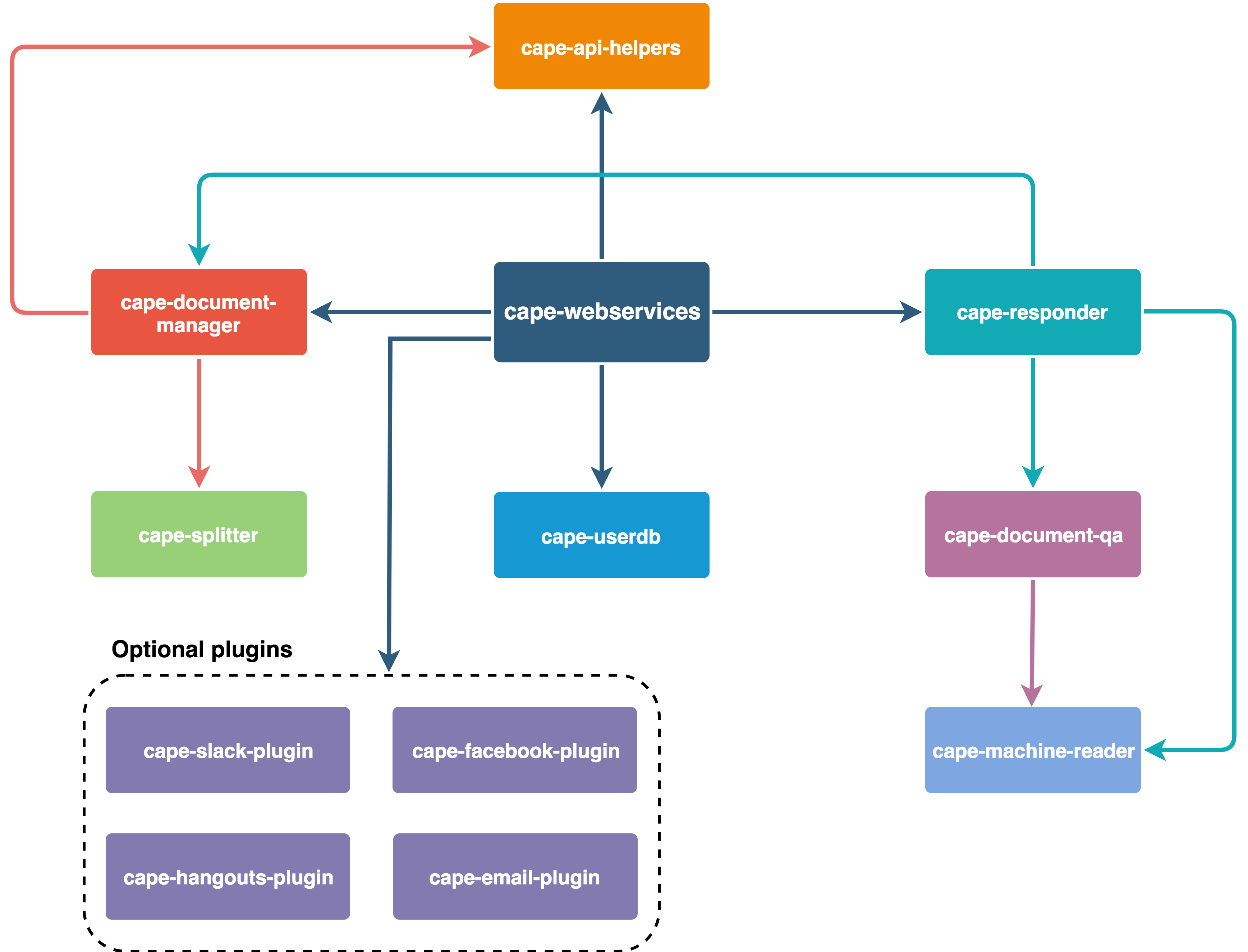
In summary this is how Cape is organized:


