telegram archive server
v0.4.1 - 蔚蓝更新
A Telegram group chat search and archiving robot suitable for CJK environment.

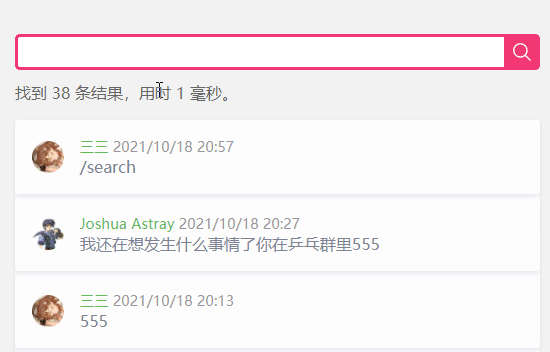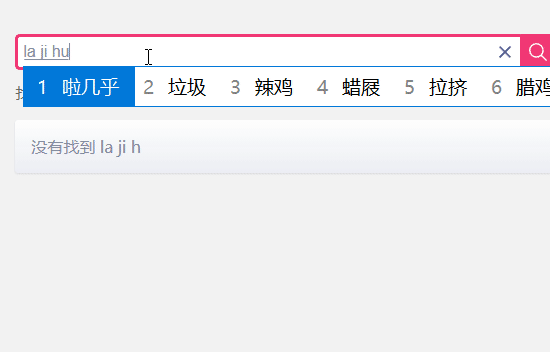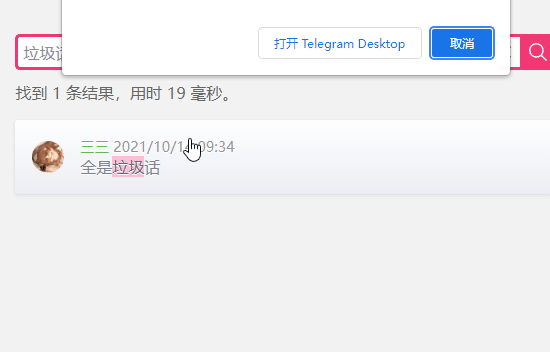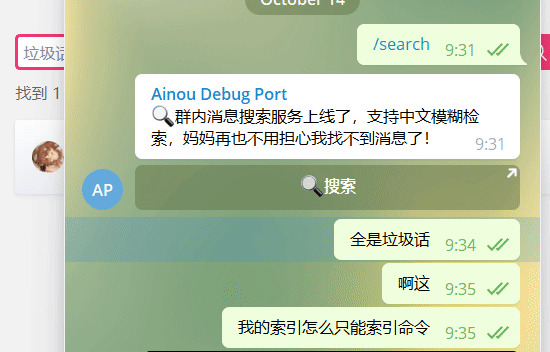
Click the [Search] button to automatically authenticate and open the search interface.
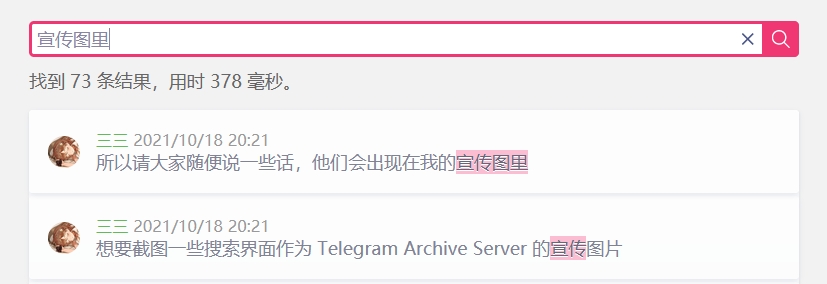
Click the time link to jump to the chat interface.
you need to:
Download the .env.example file, refer to the internal comments, and configure accordingly.
You can save it as .env or configure it as an environment variable.
TAS does not provide a built-in https service. It is recommended to use Caddy or similar software to reverse proxy TAS.
docker run -d --restart=always --env-file=.env quay.io/oott123/telegram-archive-serverOf course, you can also run it using Kubernetes or docker-compose.
If you don't have Docker or don't want to use Docker, you can also compile and deploy from source code. At this point you also need:
git clone https://github.com/oott123/telegram-archive-server.git
cd telegram-archive-server
# git checkout vX.X.X
cp .env.example .env
vim .env
yarn
yarn build
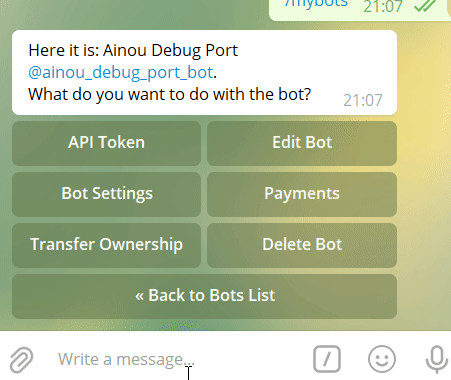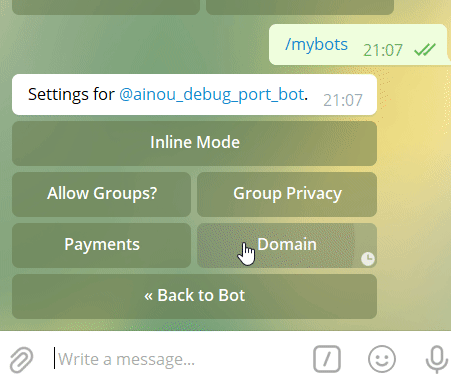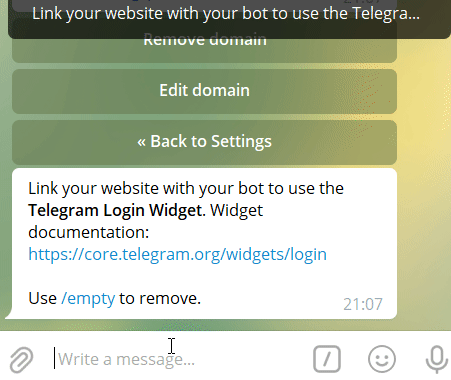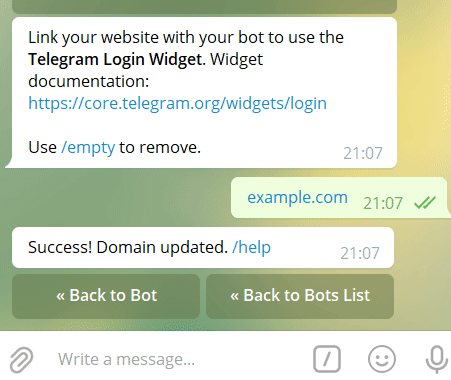
yarn start Send /search in the group. The Bot may prompt you to set the Domain, just follow the prompts.
Users must meet the following criteria in order for their avatar to appear in search results:
Since MeiliSearch has poor indexing efficiency for new messages, messages will only enter the index when any of the following conditions are met:
If redis is not used to persist the message queue, messages that have not entered the queue may be lost when the program is abnormal or the server is restarted.
Currently only supergroup import is supported.
Click the three-dot button on the desktop client - Export chat history, wait for the export to complete, and get result.json .
implement:
curl
-H " Content-Type: application/json "
-H " Authorization: Bearer $AUTH_IMPORT_TOKEN "
-XPOST -T result.json
http://localhost:3100/api/v1/import/fromTelegramGroupExportRecords can be imported. Note that only records from a single group can be imported at a time.
If you enable the OCR queue, Redis is required (can share an instance with the cache) and configure a third-party recognition service. The identification process is as follows:
Recognition and storage can be completed on different role instances: image downloading and text storage will be completed on the Bot instance, and the OCR instance only needs to access the OCR service.
This design allows maintainers to design offline centralized identification (for example, use a preemptible instance to run the identification service and shut it down after the queue is cleared) to reduce identification costs.
If you are using a third-party cloud service, you can directly turn off the OCR queue, or enable the Bot and OCR roles in the same instance.
Refer to Google Cloud Vision text recognition documentation and Google Cloud Vision billing rules. The configuration is as follows:
OCR_DRIVER=google
OCR_ENDPOINT=eu-vision.googleapis.com # 或者 us-vision.googleapis.com ,决定 Google 在何处存储处理数据
GOOGLE_APPLICATION_CREDENTIALS=/path/to/google/credentials.json # 从 GCP 后台下载的 json 鉴权文件You need an instance of paddleocr-web. The configuration is as follows:
OCR_DRIVER=paddle-ocr-web
OCR_ENDPOINT=http://127.0.0.1:8980/apiCreate an Azure Vision resource and configure the resource information as follows:
OCR_DRIVER=azure
OCR_ENDPOINT=https://tas.cognitiveservices.azure.com
OCR_CREDENTIALS=000000000000000000000000000000000docker run [...] dist/main ocr,bot
# or
node dist/main ocr,botDEBUG=app: * ,grammy * yarn start:debug After the search service is authenticated, the server will jump to: $HTTP_UI_URL/index.html with the following URL parameters:
tas_server - Server base URL, in the form http://localhost:3100/api/v1tas_indexName - group number, in the form of supergroup1234567890tas_authKey - JWT issued by the server, which can be used as MeiliSearch's api key. /api/v1/search/compilable/meili can be searched as a normal MeiliSearch instance.
The index name should use a group number in the form of supergroup1234567890 ; the API Key is the JWT issued by the server.
Please note that filter is temporarily unavailable for security reasons.


