mlmm evaluation
1.0.0
Evaluation Framework for Multilingual Large Language Models
This repo contains benchmark datasets and evaluation scripts for Multilingual Large Language Models (LLMs). These datasets can be used to evaluate the models across 26 different languages and encompass three distinct tasks: ARC, HellaSwag, and MMLU. This is released as a part of our Okapi framework for multilingual instruction-tuned LLMs with reinforcement learning from human feedback.
Currently, our datasets support 26 languages: Russian, German, Chinese, French, Spanish, Italian, Dutch, Vietnamese, Indonesian, Arabic, Hungarian, Romanian, Danish, Slovak, Ukrainian, Catalan, Serbian, Croatian, Hindi, Bengali, Tamil, Nepali, Malayalam, Marathi, Telugu, and Kannada.
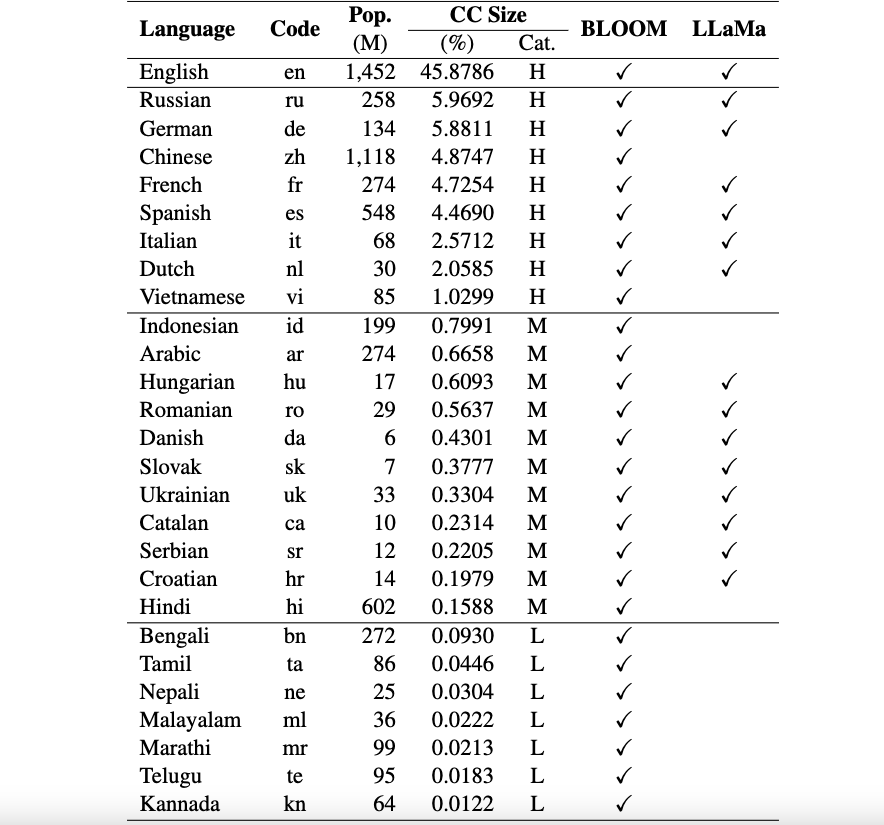
These datasets are translated from the original ARC, HellaSwag, and MMLU datasets in English using ChatGPT. Our technical paper for Okapi to describe the datasets along with evaluation results for several multilingual LLMs (e.g., BLOOM, LLaMa, and our Okapi models) can be found here.
Usage and License Notices: Our evaluation framework is intended and licensed for research use only. The datasets are CC BY NC 4.0 (allowing only non-commercial use) that should not be used outside of research purposes.
To install lm-eval from our repository main branch, run:
git clone https://github.com/nlp-uoregon/mlmm-evaluation.git
cd mlmm-evaluation
pip install -e ".[multilingual]"Firstly, you need to download the multilingual evaluation datasets by using the following script:
bash scripts/download.shTo evaluate your model on three tasks, you can use the following script:
bash scripts/run.sh [LANG] [YOUR-MODEL-PATH]For instance, if you want to evaluate our Okapi Vietnamese model, you could run:
bash scripts/run.sh vi uonlp/okapi-vi-bloomWe maintain a leaderboard for tracking the progress of multilingual LLM.
Our framework inherited largely from the lm-evaluation-harness repo from EleutherAI. Please also kindly cite their repo if you use the code.
If you use the data, model, or code in this repository, please cite:
@article{dac2023okapi,
title={Okapi: Instruction-tuned Large Language Models in Multiple Languages with Reinforcement Learning from Human Feedback},
author={Dac Lai, Viet and Van Nguyen, Chien and Ngo, Nghia Trung and Nguyen, Thuat and Dernoncourt, Franck and Rossi, Ryan A and Nguyen, Thien Huu},
journal={arXiv e-prints},
pages={arXiv--2307},
year={2023}
}

