Phi2 mini Chinese
1.0.0
This project is an experimental project, with open source code and model weights, and less pre-training data. If you need a better Chinese small model, you can refer to the project ChatLM-mini-Chinese
Caution
This project is an experimental project and may be subject to major changes at any time, including training data, model structure, file directory structure, etc. The first version of the model and please check tag v1.0
For example, adding periods at the end of sentences, converting traditional Chinese to simplified Chinese, deleting repeated punctuation marks (for example, some dialogue materials have a lot of "。。。。。" ), NFKC Unicode standardization (mainly the problem of full-width conversion to half-width and web page data u3000 xa0) etc.
For the specific data cleaning process, please refer to the project ChatLM-mini-Chinese.
This project uses the byte level BPE tokenizer. There are two types of training codes provided for word segmenters: char level and byte level .
After training, the tokenizer remembers to check whether there are common special symbols in the vocabulary, such as t , n , etc. You can try to encode and decode a text containing special characters to see if it can be restored. If these special characters are not included, add them through the add_tokens function. Use len(tokenizer) to get the vocabulary size. tokenizer.vocab_size does not count the characters added through the add_tokens function.
Tokenizer training consumes a lot of memory:
Training 100 million characters byte level requires at least 32G of memory (in fact, 32G is not enough, and swap will be triggered frequently). The 13600k training takes about an hour.
char level training of 650 million characters (which is exactly the amount of data in the Chinese Wikipedia) requires at least 32G of memory. Because swap is triggered multiple times, the actual usage is far more than 32G. The 13600K training takes about half an hour.
Therefore, when the data set is large (GB level), it is recommended to sample from the data set when training tokenizer .
Use a large amount of text for unsupervised pre-training, mainly using the data set BELLE from bell open source .
Data set format: one sentence for one sample. If it is too long, it can be truncated and divided into multiple samples.
During the CLM pre-training process, the model input and output are the same, and when calculating the cross-entropy loss, they must be shifted by one bit ( shift ).
When processing encyclopedia corpus, it is recommended to add the '[EOS]' mark at the end of each entry. Other corpus processing is similar. The end of a doc (which can be the end of an article or the end of a paragraph) must be marked with '[EOS]' . The start mark '[BOS]' can be added or not.
Mainly use the data set of bell open source . Thank you boss BELLE.
The data format for SFT training is as follows:
text = f"##提问: n { example [ 'instruction' ] } n ##回答: n { example [ 'output' ][ EOS ]" When the model calculates the loss, it will ignore the part before the mark "##回答:" ( "##回答:" will also be ignored), starting from the end of "##回答:" .
Remember to add the EOS sentence end special mark, otherwise you will not know when to stop when decode the model. The BOS sentence start mark can be filled in or left blank.
Adopt a simpler and more memory-saving DPO preference optimization method.
Fine-tune the SFT model according to personal preferences. The data set should construct three columns: prompt , chosen and rejected . The rejected column has some data from the primary model in the sft stage (for example, sft trains 4 epoch and takes a 0.5 epoch checkpoint model) Generate, if the similarity between the generated rejected and chosen is above 0.9, then this data will not be needed.
There are two models in the DPO process, one is the model to be trained, and the other is the reference model. When loading, it is actually the same model, but the reference model does not participate in parameter updates.
Model weight huggingface repository: Phi2-Chinese-0.2B
from transformers import AutoTokenizer , AutoModelForCausalLM , GenerationConfig
import torch
device = torch . device ( "cuda" ) if torch . cuda . is_available () else torch . device ( "cpu" )
tokenizer = AutoTokenizer . from_pretrained ( 'charent/Phi2-Chinese-0.2B' )
model = AutoModelForCausalLM . from_pretrained ( 'charent/Phi2-Chinese-0.2B' ). to ( device )
txt = '感冒了要怎么办?'
prompt = f"##提问: n { txt } n ##回答: n "
# greedy search
gen_conf = GenerationConfig (
num_beams = 1 ,
do_sample = False ,
max_length = 320 ,
max_new_tokens = 256 ,
no_repeat_ngram_size = 4 ,
eos_token_id = tokenizer . eos_token_id ,
pad_token_id = tokenizer . pad_token_id ,
)
tokend = tokenizer . encode_plus ( text = prompt )
input_ids , attention_mask = torch . LongTensor ([ tokend . input_ids ]). to ( device ),
torch . LongTensor ([ tokend . attention_mask ]). to ( device )
outputs = model . generate (
inputs = input_ids ,
attention_mask = attention_mask ,
generation_config = gen_conf ,
)
outs = tokenizer . decode ( outputs [ 0 ]. cpu (). numpy (), clean_up_tokenization_spaces = True , skip_special_tokens = True ,)
print ( outs ) ##提问:
感冒了要怎么办?
##回答:
感冒是由病毒引起的,感冒一般由病毒引起,以下是一些常见感冒的方法:
- 洗手,特别是在接触其他人或物品后。
- 咳嗽或打喷嚏时用纸巾或手肘遮住口鼻。
- 用手触摸口鼻,特别是喉咙和鼻子。
- 如果咳嗽或打喷嚏,可以用纸巾或手绢来遮住口鼻,但要远离其他人。
- 如果你感冒了,最好不要触摸自己的眼睛、鼻子和嘴巴。
- 在感冒期间,最好保持充足的水分和休息,以缓解身体的疲劳。
- 如果您已经感冒了,可以喝一些温水或盐水来补充体液。
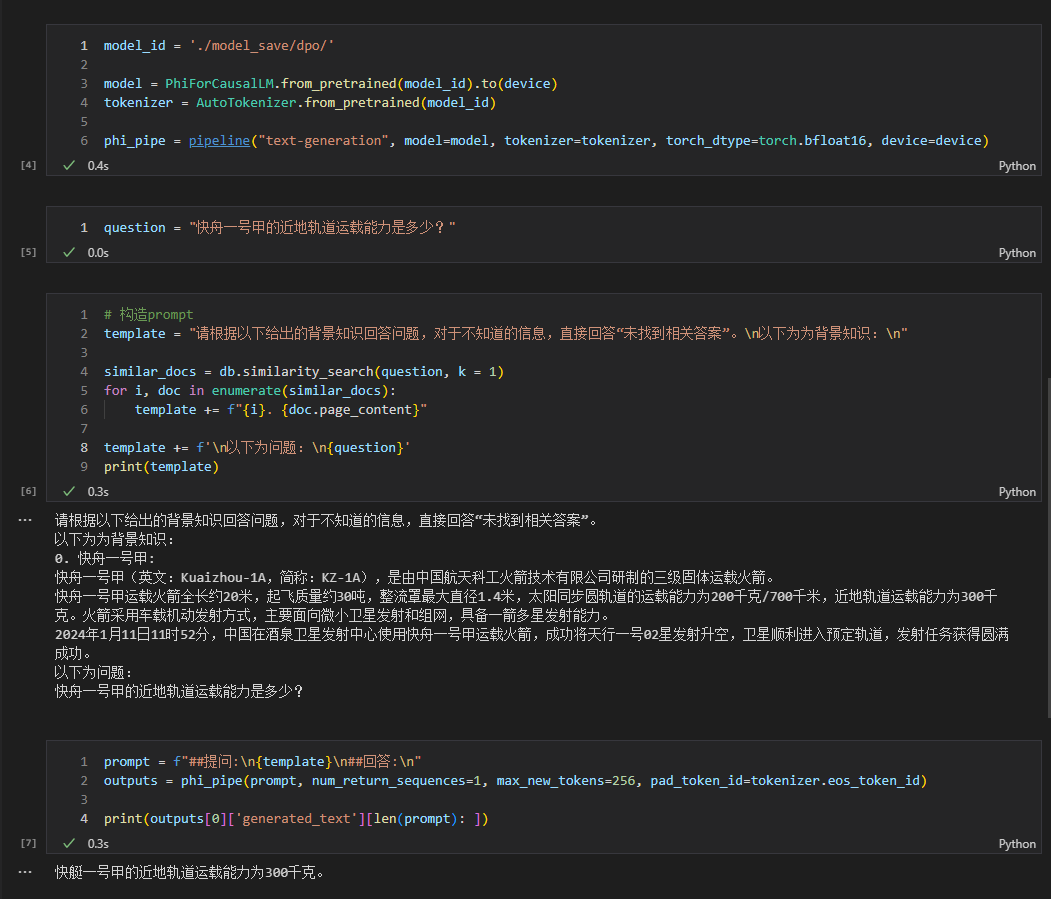
- 另外,如果感冒了,建议及时就医。 See rag_with_langchain.ipynb for the specific code.
If you think this project is helpful to you, please quote it.
@misc{Charent2023,
author={Charent Chen},
title={A small Chinese causal language model with 0.2B parameters base on Phi2},
year={2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/charent/Phi2-mini-Chinese}},
}
This project does not bear the risks and responsibilities of data security and public opinion risks caused by open source models and codes, or the risks and responsibilities arising from any model being misled, abused, disseminated, or improperly exploited.


