ChatGPT, GenerativeAI and LLMs Timeline
This repository organizes a timeline of key events (products, services, papers, GitHub, blog posts and news) that occurred before and after the ChatGPT announcement.
It's curating a variety of information in this timeline, with a particular focus on LLM and Generative AI.
Maybe it's a scene from the hottest history, so I thought it would be important to keep those memories well, so I organized them.
Statistics
These diagrams were generated by ChatGPT's Code Interpreter.
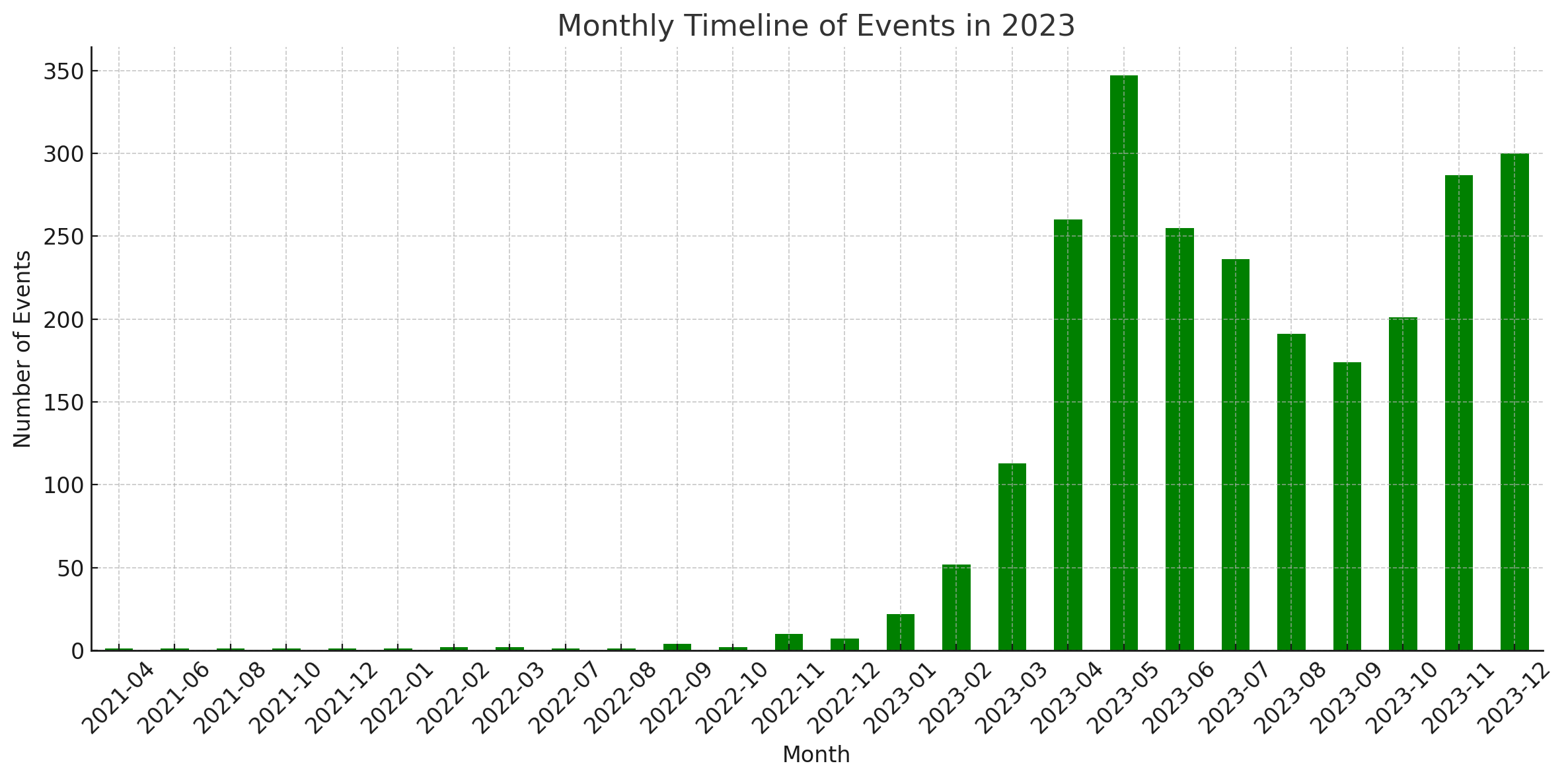
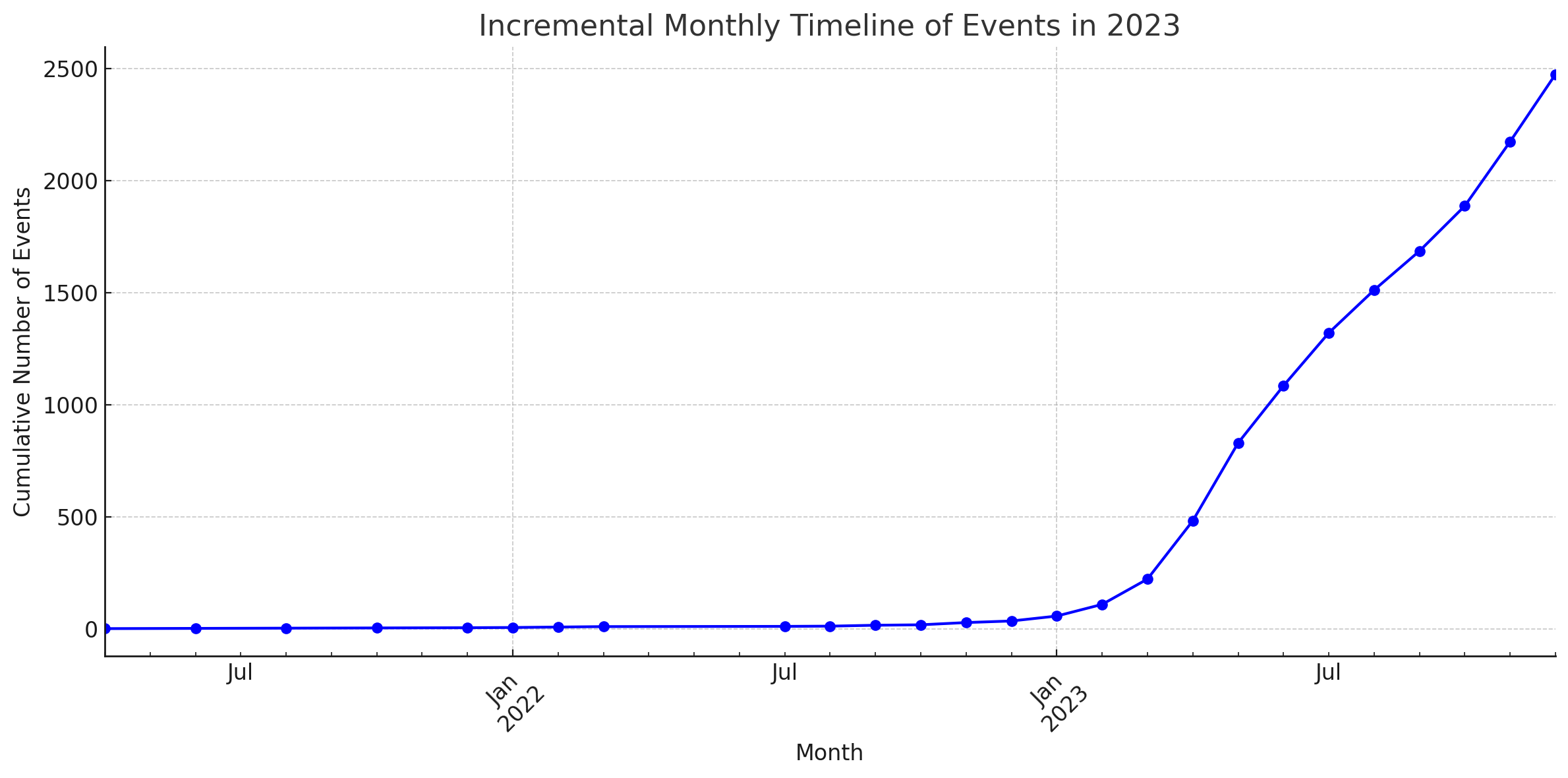
Contributing
Issues and Pull Requests are greatly appreciated. If you've never contributed to an open source project before I'm more than happy to walk you through how to create a pull request.
You can start by opening an issue describing the problem that you're looking to resolve and we'll go from there.
Emoji
arXiv , PDF ?, arxiv-vanity ?, paper page ?, papers with code ✳️, Github
License
This document is licensed under the MIT license © Jonghong Jeon(전종홍)
Timeline V2
2024
- 05/17 - OpenAI strikes Reddit deal to train its AI on your posts
(News),
- 05/17 - OpenAI dissolves team focused on long-term AI risks, less than one year after announcing it
(News),
- 05/17 - International Scientific Report on the Safety of Advanced AI
(Blog),
- 05/16 - TRANSIC: Sim-to-Real Policy Transfer by Learning from Online Correction
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/16 - Toon3D: Seeing Cartoons from a New Perspective
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/16 - Testing the reliability of an AI-based large language model to extract ecological information from the scientific literature
(News),
- 05/16 - Many-Shot In-Context Learning in Multimodal Foundation Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/16 - How to Hit Pause on AI Before It’s Too Late
(News),
- 05/16 - Grounding DINO 1.5: Advance the "Edge" of Open-Set Object Detection
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/16 - GPT Store Mining and Analysis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/16 - Dual3D: Efficient and Consistent Text-to-3D Generation with Dual-mode Multi-view Latent Diffusion
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/16 - Chameleon: Mixed-Modal Early-Fusion Foundation Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/16 - CAT3D: Create Anything in 3D with Multi-View Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/15 - Xmodel-VLM: A Simple Baseline for Multimodal Vision Language Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/15 - LoRA Learns Less and Forgets Less
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/15 - Google’s invisible AI watermark will help identify generative text and video
(News),
- 05/15 - Google I/O 2024: everything announced
(Blog),
- 05/15 - BEHAVIOR Vision Suite: Customizable Dataset Generation via Simulation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/15 - ALPINE: Unveiling the Planning Capability of Autoregressive Learning in Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/14 - Understanding the performance gap between online and offline alignment algorithms
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/14 - SpeechVerse: A Large-scale Generalizable Audio Language Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/14 - SpeechGuard: Exploring the Adversarial Robustness of Multimodal Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/14 - No Time to Waste: Squeeze Time into Channel for Mobile Video Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/14 - Hunyuan-DiT: A Powerful Multi-Resolution Diffusion Transformer with Fine-Grained Chinese Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/14 - Compositional Text-to-Image Generation with Dense Blob Representations
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/14 - Beyond Scaling Laws: Understanding Transformer Performance with Associative Memory
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/13 - SambaNova SN40L: Scaling the AI Memory Wall with Dataflow and Composition of Experts
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/13 - RLHF Workflow: From Reward Modeling to Online RLHF
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/13 - Plot2Code: A Comprehensive Benchmark for Evaluating Multi-modal Large Language Models in Code Generation from Scientific Plots
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/13 - OpenAI unveils newest AI model, GPT-4o
(News),
- 05/13 - MS MARCO Web Search: a Large-scale Information-rich Web Dataset with Millions of Real Click Labels
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/13 - How Much Research Is Being Written by Large Language Models?
(Blog),
- 05/13 - Hello GPT-4o
(Blog),
- 05/13 - Coin3D: Controllable and Interactive 3D Assets Generation with Proxy-Guided Conditioning
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/11 - Piccolo2: General Text Embedding with Multi-task Hybrid Loss Training
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/11 - LogoMotion: Visually Grounded Code Generation for Content-Aware Animation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/10 - INSPECT - An open-source framework for large language model evaluations
(Blog),
- 05/10 - AI Safety Institute releases new AI safety evaluations platform
(News),
- 05/07 - SUTRA: Scalable Multilingual Language Model Architecture
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/07 - Meta Releases Llama 3 Open-Source LLM
(News),
- 05/03 - What matters when building vision-language models?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/02 - WildChat: 1M ChatGPT Interaction Logs in the Wild
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/02 - StoryDiffusion: Consistent Self-Attention for Long-Range Image and Video Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/02 - Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/02 - NeMo-Aligner: Scalable Toolkit for Efficient Model Alignment
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/02 - LLM-AD: Large Language Model based Audio Description System
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/02 - FLAME: Factuality-Aware Alignment for Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/02 - Customizing Text-to-Image Models with a Single Image Pair
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/01 - Spectrally Pruned Gaussian Fields with Neural Compensation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/01 - Self-Play Preference Optimization for Language Model Alignment
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/01 - Is Bigger Edit Batch Size Always Better? -- An Empirical Study on Model Editing with Llama-3
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/01 - Clover: Regressive Lightweight Speculative Decoding with Sequential Knowledge
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 05/01 - A Careful Examination of Large Language Model Performance on Grade School Arithmetic
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/30 - Visual Fact Checker: Enabling High-Fidelity Detailed Caption Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/30 - STT: Stateful Tracking with Transformers for Autonomous Driving
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/30 - SemantiCodec: An Ultra Low Bitrate Semantic Audio Codec for General Sound
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/30 - Octopus v4: Graph of language models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/30 - MotionLCM: Real-time Controllable Motion Generation via Latent Consistency Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/30 - MicroDreamer: Zero-shot 3D Generation in sim20 Seconds by Score-based Iterative Reconstruction
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/30 - Lightplane: Highly-Scalable Components for Neural 3D Fields
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/30 - KAN: Kolmogorov-Arnold Networks
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/30 - Iterative Reasoning Preference Optimization
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/30 - Invisible Stitch: Generating Smooth 3D Scenes with Depth Inpainting
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/30 - InstantFamily: Masked Attention for Zero-shot Multi-ID Image Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/30 - GS-LRM: Large Reconstruction Model for 3D Gaussian Splatting
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/30 - Extending Llama-3's Context Ten-Fold Overnight
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/30 - DOCCI: Descriptions of Connected and Contrasting Images
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/30 - Better & Faster Large Language Models via Multi-token Prediction
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/29 - Stylus: Automatic Adapter Selection for Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/29 - SAGS: Structure-Aware 3D Gaussian Splatting
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/29 - Replacing Judges with Juries: Evaluating LLM Generations with a Panel of Diverse Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/29 - NIST AI RMF Generative AI Profile
(News),
- 04/29 - LoRA Land: 310 Fine-tuned LLMs that Rival GPT-4, A Technical Report
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/29 - Kangaroo: Lossless Self-Speculative Decoding via Double Early Exiting
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/29 - Capabilities of Gemini Models in Medicine
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/28 - Paint by Inpaint: Learning to Add Image Objects by Removing Them First
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/28 - LEGENT: Open Platform for Embodied Agents
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/27 - Ag2Manip: Learning Novel Manipulation Skills with Agent-Agnostic Visual and Action Representations
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/26 - MaPa: Text-driven Photorealistic Material Painting for 3D Shapes
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/26 - BlenderAlchemy: Editing 3D Graphics with Vision-Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/25 - Tele-FLM Technical Report
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/25 - SEED-Bench-2-Plus: Benchmarking Multimodal Large Language Models with Text-Rich Visual Comprehension
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/25 - Revisiting Text-to-Image Evaluation with Gecko: On Metrics, Prompts, and Human Ratings
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/25 - PLLaVA : Parameter-free LLaVA Extension from Images to Videos for Video Dense Captioning
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/25 - Make Your LLM Fully Utilize the Context
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/25 - List Items One by One: A New Data Source and Learning Paradigm for Multimodal LLMs
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/25 - Layer Skip: Enabling Early Exit Inference and Self-Speculative Decoding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/25 - Interactive3D: Create What You Want by Interactive 3D Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/25 - How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/25 - ConsistentID: Portrait Generation with Multimodal Fine-Grained Identity Preserving
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/24 - XC-Cache: Cross-Attending to Cached Context for Efficient LLM Inference
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/24 - The Ethics of Advanced AI Assistants
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/24 - PuLID: Pure and Lightning ID Customization via Contrastive Alignment
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/24 - NeRF-XL: Scaling NeRFs with Multiple GPUs
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/24 - MotionMaster: Training-free Camera Motion Transfer For Video Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/24 - MoDE: CLIP Data Experts via Clustering
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/24 - MMT-Bench: A Comprehensive Multimodal Benchmark for Evaluating Large Vision-Language Models Towards Multitask AGI
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/24 - MaGGIe: Masked Guided Gradual Human Instance Matting
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/24 - ID-Aligner: Enhancing Identity-Preserving Text-to-Image Generation with Reward Feedback Learning
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/24 - Editable Image Elements for Controllable Synthesis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/24 - CatLIP: CLIP-level Visual Recognition Accuracy with 2.7x Faster Pre-training on Web-scale Image-Text Data
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/24 - BASS: Batched Attention-optimized Speculative Sampling
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/23 - Transformers Can Represent n-gram Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/23 - Pegasus-v1 Technical Report
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/23 - Multi-Head Mixture-of-Experts
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/23 - FlashSpeech: Efficient Zero-Shot Speech Synthesis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/22 - SnapKV: LLM Knows What You are Looking for Before Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/22 - SEED-X: Multimodal Models with Unified Multi-granularity Comprehension and Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/22 - Scene Coordinate Reconstruction: Posing of Image Collections via Incremental Learning of a Relocalizer
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/22 - Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/22 - OpenELM: An Efficient Language Model Family with Open-source Training and Inference Framework
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/22 - MultiBooth: Towards Generating All Your Concepts in an Image from Text
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/22 - Learning H-Infinity Locomotion Control
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/22 - How Good Are Low-bit Quantized LLaMA3 Models? An Empirical Study
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/22 - Align Your Steps: Optimizing Sampling Schedules in Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/22 - A Multimodal Automated Interpretability Agent
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/21 - Hyper-SD: Trajectory Segmented Consistency Model for Efficient Image Synthesis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/21 - AdvPrompter: Fast Adaptive Adversarial Prompting for LLMs
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/20 - Music Consistency Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/19 - The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/19 - TextSquare: Scaling up Text-Centric Visual Instruction Tuning
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/19 - PhysDreamer: Physics-Based Interaction with 3D Objects via Video Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/19 - LLM-R2: A Large Language Model Enhanced Rule-based Rewrite System for Boosting Query Efficiency
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/19 - How Real Is Real? A Human Evaluation Framework for Unrestricted Adversarial Examples
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/19 - How Far Can We Go with Practical Function-Level Program Repair?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/19 - Groma: Localized Visual Tokenization for Grounding Multimodal Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/19 - Does Gaussian Splatting need SFM Initialization?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/19 - AutoCrawler: A Progressive Understanding Web Agent for Web Crawler Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/18 - TriForce: Lossless Acceleration of Long Sequence Generation with Hierarchical Speculative Decoding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/18 - Toward Self-Improvement of LLMs via Imagination, Searching, and Criticizing
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/18 - Reuse Your Rewards: Reward Model Transfer for Zero-Shot Cross-Lingual Alignment
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/18 - Reka Core, Flash, and Edge: A Series of Powerful Multimodal Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/18 - OpenBezoar: Small, Cost-Effective and Open Models Trained on Mixes of Instruction Data
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/18 - MeshLRM: Large Reconstruction Model for High-Quality Mesh
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/18 - Introducing v0.5 of the AI Safety Benchmark from MLCommons
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/18 - Introducing Meta Llama 3: The most capable openly available LLM to date
(Blog),
- 04/18 - EdgeFusion: On-Device Text-to-Image Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/18 - BLINK: Multimodal Large Language Models Can See but Not Perceive
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/18 - AniClipart: Clipart Animation with Text-to-Video Priors
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/17 - MoA: Mixture-of-Attention for Subject-Context Disentanglement in Personalized Image Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/17 - FlowMind: Automatic Workflow Generation with LLMs
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/17 - Dynamic Typography: Bringing Words to Life
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/17 - Stable Diffusion 3 API Now Available
(twitter), (Blog), (Demo),
- 04/16 - VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/16 - U.S. Commerce Secretary Gina Raimondo Announces Expansion of U.S. AI Safety Institute Leadership Team
(News),
- 04/16 - Long-form music generation with latent diffusion
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/15 - LLM Evaluators Recognize and Favor Their Own Generations
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/15 - Video2Game: Real-time, Interactive, Realistic and Browser-Compatible Environment from a Single Video
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/15 - Tango 2: Aligning Diffusion-based Text-to-Audio Generations through Direct Preference Optimization
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/15 - Taming Latent Diffusion Model for Neural Radiance Field Inpainting
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/15 - Opus can operate as a Turing machine
(twitter),
- 04/15 - MathGPT: Leveraging Llama 2 to create a platform for highly personalized learning
- 04/15 - HQ-Edit: A High-Quality Dataset for Instruction-based Image Editing
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/15 - Ctrl-Adapter: An Efficient and Versatile Framework for Adapting Diverse Controls to Any Diffusion Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/15 - Compression Represents Intelligence Linearly
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/15 - CompGS: Efficient 3D Scene Representation via Compressed Gaussian Splatting
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/14 - TextHawk: Exploring Efficient Fine-Grained Perception of Multimodal Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/13 - Cathie Wood Muscles Into ChatGPT Boom With New OpenAI Stake
(News),
- 04/12 - Scaling (Down) CLIP: A Comprehensive Analysis of Data, Architecture, and Training Strategies
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/12 - Probing the 3D Awareness of Visual Foundation Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/12 - Pre-training Small Base LMs with Fewer Tokens
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/12 - On the Robustness of Language Guidance for Low-Level Vision Tasks: Findings from Depth Estimation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/12 - MonoPatchNeRF: Improving Neural Radiance Fields with Patch-based Monocular Guidance
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/12 - Megalodon: Efficient LLM Pretraining and Inference with Unlimited Context Length
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/12 - Is ChatGPT Transforming Academics' Writing Style?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/12 - COCONut: Modernizing COCO Segmentation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/12 - AI Chip Trims Energy Budget Back by 99+ Percent
(News),
- 04/12 - AdapterSwap: Continuous Training of LLMs with Data Removal and Access-Control Guarantees
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/12 - Grok-1.5 Vision Preview
(Demo),
- 04/12 - The good, the bad, and the Humane Pin
(News),
- 04/12 - Paid ChatGPT users can now access GPT-4 Turbo
(twitter), (News), , ()
- 04/11 - The Necessity of AI Audit Standards Boards
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/11 - Remembering Transformer for Continual Learning
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/11 - Amazon adds Andrew Ng, a leading voice in artificial intelligence, to its board of directors
(News),
- 04/11 - Adobe Is Buying Videos for $3 Per Minute to Build AI Model
(News),
- 04/11 - UltraEval: A Lightweight Platform for Flexible and Comprehensive Evaluation for LLMs
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/11 - Transferable and Principled Efficiency for Open-Vocabulary Segmentation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/11 - SWE-agent
(twitter), (Demo), , ()
- 04/11 - Sparse Laneformer
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/11 - Rho-1: Not All Tokens Are What You Need
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/11 - ResearchAgent: Iterative Research Idea Generation over Scientific Literature with Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/11 - RecurrentGemma: Moving Past Transformers for Efficient Open Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/11 - OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/11 - LLoCO: Learning Long Contexts Offline
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/11 - Leveraging Large Language Models (LLMs) to Support Collaborative Human-AI Online Risk Data Annotation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/11 - JetMoE: Reaching Llama2 Performance with 0.1M Dollars
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) (Project), (twitter), , (✳️), ()
- 04/11 - HGRN2: Gated Linear RNNs with State Expansion
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/11 - From Words to Numbers: Your Large Language Model Is Secretly A Capable Regressor When Given In-Context Examples
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/11 - Ferret-v2: An Improved Baseline for Referring and Grounding with Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/11 - ControlNet++: Improving Conditional Controls with Efficient Consistency Feedback
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/11 - Context-aware Video Anomaly Detection in Long-Term Datasets
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/11 - ChatGPT-3.5, Claude 3 kick pixelated butt in Street Fighter III tournament for LLMs
(News),
- 04/11 - ChatGPT Can Predict the Future when it Tells Stories Set in the Future About the Past
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/11 - Best Practices and Lessons Learned on Synthetic Data for Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/11 - Benchmark LLMs by fighting in Street Fighter 3
(Demo), , ()
- 04/11 - Audio Dialogues: Dialogues dataset for audio and music understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/11 - Applying Guidance in a Limited Interval Improves Sample and Distribution Quality in Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/11 - AmpleGCG: Learning a Universal and Transferable Generative Model of Adversarial Suffixes for Jailbreaking Both Open and Closed LLMs
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/10 - LM Transparency Tool: Interactive Tool for Analyzing Transformer Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/10 - Gemini 1.5 Pro now understands audio
(twitter),
- 04/10 - Exploring Concept Depth: How Large Language Models Acquire Knowledge at Different Layers?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/10 - Urban Architect: Steerable 3D Urban Scene Generation with Layout Prior
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/10 - RealmDreamer: Text-Driven 3D Scene Generation with Inpainting and Depth Diffusion
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/10 - OpenAI and Meta are on the verge of releasing AI models capable of reasoning like humans, report says
(News),
- 04/10 - MetaCheckGPT -- A Multi-task Hallucination Detector Using LLM Uncertainty and Meta-models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/10 - Meta confirms that its Llama 3 open source LLM is coming in the next month
(News),
- 04/10 - Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/10 - Incremental XAI: Memorable Understanding of AI with Incremental Explanations
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/10 - DreamScene360: Unconstrained Text-to-3D Scene Generation with Panoramic Gaussian Splatting
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/10 - Does Mapo Tofu Contain Coffee? Probing LLMs for Food-related Cultural Knowledge
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/10 - BRAVE: Broadening the visual encoding of vision-language models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/10 - AI startup Mistral launches a 281GB AI model to rival OpenAI, Meta, and Google
(News),
- 04/10 - Agent-driven Generative Semantic Communication for Remote Surveillance
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/10 - Adapting LLaMA Decoder to Vision Transformer
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/10 - A Survey on the Integration of Generative AI for Critical Thinking in Mobile Networks
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/09 - Take a Look at it! Rethinking How to Evaluate Language Model Jailbreak
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/09 - RULER: What's the Real Context Size of Your Long-Context Language Models?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/09 - Revising Densification in Gaussian Splatting
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/09 - Reconstructing Hand-Held Objects in 3D
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/09 - RAR-b: Reasoning as Retrieval Benchmark
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/09 - Privacy Preserving Prompt Engineering: A Survey
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/09 - On Evaluating the Efficiency of Source Code Generated by LLMs
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/09 - OmniFusion Technical Report
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/09 - MuPT: A Generative Symbolic Music Pretrained Transformer
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/09 - MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/09 - Magic-Boost: Boost 3D Generation with Mutli-View Conditioned Diffusion
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/09 - LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/09 - InternLM-XComposer2-4KHD: A Pioneering Large Vision-Language Model Handling Resolutions from 336 Pixels to 4K HD
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/09 - Hash3D: Training-free Acceleration for 3D Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/09 - Google unveils open source projects for generative AI
(News),
- 04/09 - Elephants Never Forget: Memorization and Learning of Tabular Data in Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/09 - Apple just unveiled new Ferret-UI LLM — this AI can read your iPhone screen
(News),
- 04/09 - AEGIS: Online Adaptive AI Content Safety Moderation with Ensemble of LLM Experts
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/08 - YaART: Yet Another ART Rendering Technology
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/08 - WILBUR: Adaptive In-Context Learning for Robust and Accurate Web Agents
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/08 - UniFL: Improve Stable Diffusion via Unified Feedback Learning
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/08 - Unbridled Icarus: A Survey of the Potential Perils of Image Inputs in Multimodal Large Language Model Security
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/08 - The Hallucinations Leaderboard -- An Open Effort to Measure Hallucinations in Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/08 - The Fact Selection Problem in LLM-Based Program Repair
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/08 - SwapAnything: Enabling Arbitrary Object Swapping in Personalized Visual Editing
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/08 - SambaLingo: Teaching Large Language Models New Languages
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/08 - Negative Preference Optimization: From Catastrophic Collapse to Effective Unlearning
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/08 - Naver debuts multilingual HyperCLOVA X LLM it will use to build sovereign AI for Asia
(News),
- 04/08 - MoMA: Multimodal LLM Adapter for Fast Personalized Image Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/08 - MedExpQA: Multilingual Benchmarking of Large Language Models for Medical Question Answering
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/08 - MA-LMM: Memory-Augmented Large Multimodal Model for Long-Term Video Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/08 - LayoutLLM: Layout Instruction Tuning with Large Language Models for Document Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/08 - Ferret-UI: Grounded Mobile UI Understanding with Multimodal LLMs
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/08 - Evaluating Interventional Reasoning Capabilities of Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/08 - Eagle and Finch: RWKV with Matrix-Valued States and Dynamic Recurrence
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/08 - CodecLM: Aligning Language Models with Tailored Synthetic Data
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/08 - AutoCodeRover: Autonomous Program Improvement
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/07 - TimeGPT in Load Forecasting: A Large Time Series Model Perspective
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/07 - OpenAI transcribed over a million hours of YouTube videos to train GPT-4
(News),
- 04/07 - MagicTime: Time-lapse Video Generation Models as Metamorphic Simulators
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/07 - ByteEdit: Boost, Comply and Accelerate Generative Image Editing
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/06 - Majority Voting of Doctors Improves Appropriateness of AI Reliance in Pathology
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/06 - Diffusion-RWKV: Scaling RWKV-Like Architectures for Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/06 - DATENeRF: Depth-Aware Text-based Editing of NeRFs
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/06 - BeyondScene: Higher-Resolution Human-Centric Scene Generation With Pretrained Diffusion
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/06 - Aligning Diffusion Models by Optimizing Human Utility
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/06 - The Case for Developing a Foundation Model for Planning-like Tasks from Scratch
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/05 - Increased LLM Vulnerabilities from Fine-tuning and Quantization
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/05 - SpatialTracker: Tracking Any 2D Pixels in 3D Space
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/05 - Social Skill Training with Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/05 - Sigma: Siamese Mamba Network for Multi-Modal Semantic Segmentation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/05 - Robust Gaussian Splatting
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/05 - PhysAvatar: Learning the Physics of Dressed 3D Avatars from Visual Observations
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/05 - Koala: Key frame-conditioned long video-LLM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/05 - CLUE: A Clinical Language Understanding Evaluation for LLMs
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/05 - Chinese Tiny LLM: Pretraining a Chinese-Centric Large Language Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/05 - Assisting humans in complex comparisons: automated information comparison at scale
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/04 - Embodied AI with Two Arms: Zero-shot Learning, Safety and Modularity
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/04 - Language Model Evolution: An Iterated Learning Perspective
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/04 - Visualization-of-Thought Elicits Spatial Reasoning in Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) (twitter),
- 04/04 - No "Zero-Shot" Without Exponential Data: Pretraining Concept Frequency Determines Multimodal Model Performance
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/04 - Evaluating LLMs at Detecting Errors in LLM Responses
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/04 - Evaluating Generative Language Models in Information Extraction as Subjective Question Correction
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/04 - Direct Nash Optimization: Teaching Language Models to Self-Improve with General Preferences
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/04 - CBR-RAG: Case-Based Reasoning for Retrieval Augmented Generation in LLMs for Legal Question Answering
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/04 - Capabilities of Large Language Models in Control Engineering: A Benchmark Study on GPT-4, Claude 3 Opus, and Gemini 1.0 Ultra
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/04 - CantTalkAboutThis: Aligning Language Models to Stay on Topic in Dialogues
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/04 - AutoWebGLM: Bootstrap And Reinforce A Large Language Model-based Web Navigating Agent
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/04 - Training LLMs over Neurally Compressed Text
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/04 - ReFT: Representation Finetuning for Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/04 - Red Teaming GPT-4V: Are GPT-4V Safe Against Uni/Multi-Modal Jailbreak Attacks?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/04 - RALL-E: Robust Codec Language Modeling with Chain-of-Thought Prompting for Text-to-Speech Synthesis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/04 - PointInfinity: Resolution-Invariant Point Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/04 - MiniGPT4-Video: Advancing Multimodal LLMs for Video Understanding with Interleaved Visual-Textual Tokens
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/04 - CoMat: Aligning Text-to-Image Diffusion Model with Image-to-Text Concept Matching
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/04 - CodeEditorBench: Evaluating Code Editing Capability of Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/04 - AutoWebGLM: Bootstrap And Reinforce A Large Language Model-based Web Navigating Agent
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/03 - Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/03 - On the Scalability of Diffusion-based Text-to-Image Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/03 - Many-shot jailbreaking
()
- 04/03 - LVLM-Intrepret: An Interpretability Tool for Large Vision-Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/03 - Language Models as Compilers: Simulating Pseudocode Execution Improves Algorithmic Reasoning in Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/03 - InstantStyle: Free Lunch towards Style-Preserving in Text-to-Image Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/03 - Freditor: High-Fidelity and Transferable NeRF Editing by Frequency Decomposition
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/03 - Cross-Attention Makes Inference Cumbersome in Text-to-Image Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/03 - ChatGLM-Math: Improving Math Problem-Solving in Large Language Models with a Self-Critique Pipeline
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/02 - UK & United States announce partnership on science of AI safety
(News),
- 04/02 - Large Language Models as Planning Domain Generators
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 04/02 - Poro 34B and the Blessing of Multilinguality
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/02 - Octopus v2: On-device language model for super agent
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/02 - Mixture-of-Depths: Dynamically allocating compute in transformer-based language models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/02 - Long-context LLMs Struggle with Long In-context Learning
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/02 - LLM-ABR: Designing Adaptive Bitrate Algorithms via Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/02 - Large language models could change the future of behavioral healthcare: a proposal for responsible development and evaluation
()
- 04/02 - HyperCLOVA X Technical Report
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/02 - CameraCtrl: Enabling Camera Control for Text-to-Video Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/02 - Advancing LLM Reasoning Generalists with Preference Trees
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/01 - Stream of Search (SoS): Learning to Search in Language
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/01 - LLM as a Mastermind: A Survey of Strategic Reasoning with Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/01 - The Rise and Rise of A.I. Large Language Models (LLMs)
(Blog),
- 04/01 - Streaming Dense Video Captioning
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/01 - Measuring Style Similarity in Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/01 - Getting it Right: Improving Spatial Consistency in Text-to-Image Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/01 - For Data-Guzzling AI Companies, the Internet Is Too Small
(News),
- 04/01 - FlexiDreamer: Single Image-to-3D Generation with FlexiCubes
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/01 - Evalverse: Unified and Accessible Library for Large Language Model Evaluation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/01 - Direct Preference Optimization of Video Large Multimodal Models from Language Model Reward
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 04/01 - DBRX, Continual Pretraining, RewardBench, Faster Inference, and More
(Blog),
- 04/01 - CosmicMan: A Text-to-Image Foundation Model for Humans
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/01 - Condition-Aware Neural Network for Controlled Image Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/01 - Bigger is not Always Better: Scaling Properties of Latent Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 04/01 - Are large language models superhuman chemists?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/31 - WavLLM: Towards Robust and Adaptive Speech Large Language Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/31 - Tired of Plugins? Large Language Models Can Be End-To-End Recommenders
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/30 - Survey on Large Language Model-Enhanced Reinforcement Learning: Concept, Taxonomy, and Methods
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/30 - ST-LLM: Large Language Models Are Effective Temporal Learners
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/30 - Noise-Aware Training of Layout-Aware Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/30 - MaGRITTe: Manipulative and Generative 3D Realization from Image, Topview and Text
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/30 - Aurora-M: The First Open Source Multilingual Language Model Red-teamed according to the U.S. Executive Order
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/29 - Unsolvable Problem Detection: Evaluating Trustworthiness of Vision Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/29 - Transformer-Lite: High-efficiency Deployment of Large Language Models on Mobile Phone GPUs
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/29 - Snap-it, Tap-it, Splat-it: Tactile-Informed 3D Gaussian Splatting for Reconstructing Challenging Surfaces
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/29 - ReALM: Reference Resolution As Language Modeling
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/29 - NVIDIA H200 GPUs Crush MLPerf’s LLM Inferencing Benchmark
(News),
- 03/29 - MambaMixer: Efficient Selective State Space Models with Dual Token and Channel Selection
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/29 - LLaVA-Gemma: Accelerating Multimodal Foundation Models with a Compact Language Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/29 - InstantSplat: Unbounded Sparse-view Pose-free Gaussian Splatting in 40 Seconds
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/29 - Gecko: Versatile Text Embeddings Distilled from Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/29 - DiJiang: Efficient Large Language Models through Compact Kernelization
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/29 - DeepMind develops SAFE, an AI-based app that can fact-check LLMs
(News),
- 03/29 - CtRL-Sim: Reactive and Controllable Driving Agents with Offline Reinforcement Learning
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/29 - Are We on the Right Way for Evaluating Large Vision-Language Models?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/28 - sDPO: Don't Use Your Data All at Once
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/28 - Mesh2NeRF: Direct Mesh Supervision for Neural Radiance Field Representation and Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/28 - Localizing Paragraph Memorization in Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/28 - Jamba: A Hybrid Transformer-Mamba Language Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/28 - GaussianCube: Structuring Gaussian Splatting using Optimal Transport for 3D Generative Modeling
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/28 - Claude 3 overtakes GPT-4 in the duel of the AI bots. Here's how to get in on the action
(News),
- 03/28 - Announcing Grok-1.5
(Blog), (Demo),
- 03/27 - A Path Towards Legal Autonomy: An interoperable and explainable approach to extracting, transforming, loading and computing legal information using large language models, expert systems and Bayesian networks
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/27 - ViTAR: Vision Transformer with Any Resolution
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/27 - Towards a World-English Language Model for On-Device Virtual Assistants
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/27 - TextCraftor: Your Text Encoder Can be Image Quality Controller
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/27 - ObjectDrop: Bootstrapping Counterfactuals for Photorealistic Object Removal and Insertion
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/27 - Mini-Gemini: Mining the Potential of Multi-modality Vision Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/27 - Long-form factuality in large language models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/27 - LITA: Language Instructed Temporal-Localization Assistant
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/27 - Garment3DGen: 3D Garment Stylization and Texture Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/27 - Gamba: Marry Gaussian Splatting with Mamba for single view 3D reconstruction
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/27 - FlexEdit: Flexible and Controllable Diffusion-based Object-centric Image Editing
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/27 - BioMedLM: A 2.7B Parameter Language Model Trained On Biomedical Text
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/26 - MAGIS: LLM-Based Multi-Agent Framework for GitHub Issue Resolution
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/26 - The Unreasonable Ineffectiveness of the Deeper Layers
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/26 - TC4D: Trajectory-Conditioned Text-to-4D Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/26 - Octree-GS: Towards Consistent Real-time Rendering with LOD-Structured 3D Gaussians
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/26 - Introducing DBRX: A New State-of-the-Art Open LLM
(Blog),
- 03/26 - InternLM2 Technical Report
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/26 - Improving Text-to-Image Consistency via Automatic Prompt Optimization
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/26 - Fully-fused Multi-Layer Perceptrons on Intel Data Center GPUs
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/26 - EgoLifter: Open-world 3D Segmentation for Egocentric Perception
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/26 - AniPortrait: Audio-Driven Synthesis of Photorealistic Portrait Animation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/26 - 2D Gaussian Splatting for Geometrically Accurate Radiance Fields
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/25 - Towards Automatic Evaluation for LLMs' Clinical Capabilities: Metric, Data, and Algorithm
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/25 - RepairAgent: An Autonomous, LLM-Based Agent for Program Repair
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/25 - RL for Consistency Models: Faster Reward Guided Text-to-Image Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/25 - VP3D: Unleashing 2D Visual Prompt for Text-to-3D Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/25 - TRIP: Temporal Residual Learning with Image Noise Prior for Image-to-Video Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/25 - SDXS: Real-Time One-Step Latent Diffusion Models with Image Conditions
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/25 - LLM Agent Operating System
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/25 - FlashFace: Human Image Personalization with High-fidelity Identity Preservation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/25 - DreamPolisher: Towards High-Quality Text-to-3D Generation via Geometric Diffusion
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/25 - Be Yourself: Bounded Attention for Multi-Subject Text-to-Image Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/23 - When LLM-based Code Generation Meets the Software Development Process
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/22 - ThemeStation: Generating Theme-Aware 3D Assets from Few Exemplars
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/22 - SiMBA: Simplified Mamba-Based Architecture for Vision and Multivariate Time series
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/22 - LLM2LLM: Boosting LLMs with Novel Iterative Data Enhancement
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/22 - LATTE3D: Large-scale Amortized Text-To-Enhanced3D Synthesis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/22 - InternVideo2: Scaling Video Foundation Models for Multimodal Video Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/22 - FollowIR: Evaluating and Teaching Information Retrieval Models to Follow Instructions
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/22 - DragAPart: Learning a Part-Level Motion Prior for Articulated Objects
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/22 - Can large language models explore in-context?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/22 - AllHands: Ask Me Anything on Large-scale Verbatim Feedback via Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/21 - PeerGPT: Probing the Roles of LLM-based Peer Agents as Team Moderators and Participants in Children's Collaborative Learning
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/21 - StyleCineGAN: Landscape Cinemagraph Generation using a Pre-trained StyleGAN
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/21 - StreamingT2V: Consistent, Dynamic, and Extendable Long Video Generation from Text
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/21 - ReNoise: Real Image Inversion Through Iterative Noising
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/21 - Recourse for reclamation: Chatting with generative language models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/21 - RakutenAI-7B: Extending Large Language Models for Japanese
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/21 - MyVLM: Personalizing VLMs for User-Specific Queries
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/21 - MathVerse: Does Your Multi-modal LLM Truly See the Diagrams in Visual Math Problems?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/21 - GRM: Large Gaussian Reconstruction Model for Efficient 3D Reconstruction and Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/21 - General Assembly adopts landmark resolution on artificial intelligence
(News),
- 03/21 - Gaussian Frosting: Editable Complex Radiance Fields with Real-Time Rendering
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/21 - Explorative Inbetweening of Time and Space
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/21 - Efficient Video Diffusion Models via Content-Frame Motion-Latent Decomposition
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/21 - DreamReward: Text-to-3D Generation with Human Preference
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/21 - Cobra: Extending Mamba to Multi-Modal Large Language Model for Efficient Inference
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/21 - Champ: Controllable and Consistent Human Image Animation with 3D Parametric Guidance
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/21 - AnyV2V: A Plug-and-Play Framework For Any Video-to-Video Editing Tasks
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/20 - Mapping LLM Security Landscapes: A Comprehensive Stakeholder Risk Assessment Proposal
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/20 - ZigMa: Zigzag Mamba Diffusion Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/20 - VSTAR: Generative Temporal Nursing for Longer Dynamic Video Synthesis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/20 - RewardBench: Evaluating Reward Models for Language Modeling
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/20 - Reverse Training to Nurse the Reversal Curse
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/20 - RadSplat: Radiance Field-Informed Gaussian Splatting for Robust Real-Time Rendering with 900+ FPS
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/20 - Mora: Enabling Generalist Video Generation via A Multi-Agent Framework
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/20 - LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/20 - IDAdapter: Learning Mixed Features for Tuning-Free Personalization of Text-to-Image Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/20 - HyperLLaVA: Dynamic Visual and Language Expert Tuning for Multimodal Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/20 - Evaluating Frontier Models for Dangerous Capabilities
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/20 - DepthFM: Fast Monocular Depth Estimation with Flow Matching
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/20 - Compress3D: a Compressed Latent Space for 3D Generation from a Single Image
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/20 - Be-Your-Outpainter: Mastering Video Outpainting through Input-Specific Adaptation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/19 - When Do We Not Need Larger Vision Models?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/19 - Vid2Robot: End-to-end Video-conditioned Policy Learning with Cross-Attention Transformers
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/19 - Towards a general-purpose foundation model for computational pathology
()
- 03/19 - TexDreamer: Towards Zero-Shot High-Fidelity 3D Human Texture Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/19 - SceneScript: Reconstructing Scenes With An Autoregressive Structured Language Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/19 - mPLUG-DocOwl 1.5: Unified Structure Learning for OCR-free Document Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/19 - Magic Fixup: Streamlining Photo Editing by Watching Dynamic Videos
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/19 - LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/19 - GVGEN: Text-to-3D Generation with Volumetric Representation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/19 - GaussianFlow: Splatting Gaussian Dynamics for 4D Content Creation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/19 - FRESCO: Spatial-Temporal Correspondence for Zero-Shot Video Translation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/19 - FouriScale: A Frequency Perspective on Training-Free High-Resolution Image Synthesis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/19 - Evolutionary Optimization of Model Merging Recipes
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ([:octocat:](https://github.com/ sakanaai/evolutionary-model-merge))
- 03/19 - ComboVerse: Compositional 3D Assets Creation Using Spatially-Aware Diffusion Guidance
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/19 - Chart-based Reasoning: Transferring Capabilities from LLMs to VLMs
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/19 - Apple's MM1: A multimodal large language model capable of interpreting both images and text data
(News),
- 03/19 - AnimateDiff-Lightning: Cross-Model Diffusion Distillation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/19 - Agent-FLAN: Designing Data and Methods of Effective Agent Tuning for Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/19 - A visual-language foundation model for computational pathology
() , (✳️)
- 03/19 - Characteristic AI Agents via Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/18 - How Far Are We on the Decision-Making of LLMs? Evaluating LLMs' Gaming Ability in Multi-Agent Environments
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/18 - VideoAgent: A Memory-augmented Multimodal Agent for Video Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/18 - VFusion3D: Learning Scalable 3D Generative Models from Video Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/18 - TnT-LLM: Text Mining at Scale with Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/18 - SV3D: Novel Multi-view Synthesis and 3D Generation from a Single Image using Latent Video Diffusion
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/18 - ROUTERBENCH: A Benchmark for Multi-LLM Routing System
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), (SS)
- 03/18 - Meta-Prompting for Automating Zero-shot Visual Recognition with LLMs
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/18 - LN3Diff: Scalable Latent Neural Fields Diffusion for Speedy 3D Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/18 - LLaVA-UHD: an LMM Perceiving Any Aspect Ratio and High-Resolution Images
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/18 - Larimar: Large Language Models with Episodic Memory Control
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/18 - Infinite-ID: Identity-preserved Personalization via ID-semantics Decoupling Paradigm
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/18 - GPT-4 as Evaluator: Evaluating Large Language Models on Pest Management in Agriculture
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/18 - Generic 3D Diffusion Adapter Using Controlled Multi-View Editing
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/18 - From Pixels to Insights: A Survey on Automatic Chart Understanding in the Era of Large Foundation Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/18 - Fast High-Resolution Image Synthesis with Latent Adversarial Diffusion Distillation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/18 - Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLMs Under Compression
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/18 - Compiler generated feedback for Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/17 - PhD: A Prompted Visual Hallucination Evaluation Dataset
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/17 - MindEye2: Shared-Subject Models Enable fMRI-To-Image With 1 Hour of Data
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/16 - VisionCLIP: An Med-AIGC based Ethical Language-Image Foundation Model for Generalizable Retina Image Analysis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/16 - Do Large Language Models understand Medical Codes?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/15 - VideoAgent: Long-form Video Understanding with Large Language Model as Agent
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/15 - Uni-SMART: Universal Science Multimodal Analysis and Research Transformer
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/15 - Trusting the Search: Unraveling Human Trust in Health Information from Google and ChatGPT
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/15 - RAFT: Adapting Language Model to Domain Specific RAG
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/15 - RAFT: Adapting Language Model to Domain Specific RAG
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/15 - PERL: Parameter Efficient Reinforcement Learning from Human Feedback
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/15 - NeuFlow: Real-time, High-accuracy Optical Flow Estimation on Robots Using Edge Devices
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/15 - MusicHiFi: Fast High-Fidelity Stereo Vocoding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/15 - LightIt: Illumination Modeling and Control for Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/15 - Isotropic3D: Image-to-3D Generation Based on a Single CLIP Embedding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/15 - FDGaussian: Fast Gaussian Splatting from Single Image via Geometric-aware Diffusion Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/15 - Enhancing Human-Centered Dynamic Scene Understanding via Multiple LLMs Collaborated Reasoning
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/15 - EfficientVMamba: Atrous Selective Scan for Light Weight Visual Mamba
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/15 - DiPaCo: Distributed Path Composition
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/15 - Controllable Text-to-3D Generation via Surface-Aligned Gaussian Splatting
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/14 - WavCraft: Audio Editing and Generation with Natural Language Prompts
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/14 - VisionGPT-3D: A Generalized Multimodal Agent for Enhanced 3D Vision Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/14 - Video Mamba Suite: State Space Model as a Versatile Alternative for Video Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/14 - Video Editing via Factorized Diffusion Distillation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/14 - Unlocking the conversion of Web Screenshots into HTML Code with the WebSight Dataset
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/14 - StreamMultiDiffusion: Real-Time Interactive Generation with Region-Based Semantic Control
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/14 - Scaling Instructable Agents Across Many Simulated Worlds
(twitter), (Blog),
- 03/14 - Recurrent Drafter for Fast Speculative Decoding in Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/14 - Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/14 - MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/14 - LocalMamba: Visual State Space Model with Windowed Selective Scan
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/14 - Large Language Models and Causal Inference in Collaboration: A Comprehensive Survey
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/14 - Helpful or Harmful? Exploring the Efficacy of Large Language Models for Online Grooming Prevention
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/14 - Griffon v2: Advancing Multimodal Perception with High-Resolution Scaling and Visual-Language Co-Referring
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/14 - GPT on a Quantum Computer
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/14 - Glyph-ByT5: A Customized Text Encoder for Accurate Visual Text Rendering
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/14 - GiT: Towards Generalist Vision Transformer through Universal Language Interface
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/14 - Exploring the Capabilities and Limitations of Large Language Models in the Electric Energy Sector
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/14 - BurstAttention: An Efficient Distributed Attention Framework for Extremely Long Sequences
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/14 - 3D-VLA: A 3D Vision-Language-Action Generative World Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/13 - Scaling Instructable Agents Across Many Simulated Worlds
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/13 - VLOGGER: Multimodal Diffusion for Embodied Avatar Synthesis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/13 - The Human Factor in Detecting Errors of Large Language Models: A Systematic Literature Review and Future Research Directions
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/13 - SOTOPIA-π: Interactive Learning of Socially Intelligent Language Agents
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/13 - Simple and Scalable Strategies to Continually Pre-train Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/13 - Scaling Up Dynamic Human-Scene Interaction Modeling
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/13 - Language-based game theory in the age of artificial intelligence
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/13 - Language models scale reliably with over-training and on downstream tasks
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/13 - Knowledge Conflicts for LLMs: A Survey
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/13 - Gemma: Open Models Based on Gemini Research and Technology
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/13 - GaussianImage: 1000 FPS Image Representation and Compression by 2D Gaussian Splatting
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/13 - Follow-Your-Click: Open-domain Regional Image Animation via Short Prompts
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/13 - Cultural evolution in populations of Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/13 - Bugs in Large Language Models Generated Code: An Empirical Study
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/12 - Synth^2: Boosting Visual-Language Models with Synthetic Captions and Image Embeddings
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/12 - Motion Mamba: Efficient and Long Sequence Motion Generation with Hierarchical and Bidirectional Selective SSM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/12 - MoAI: Mixture of All Intelligence for Large Language and Vision Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/12 - Learning Generalizable Feature Fields for Mobile Manipulation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/12 - DragAnything: Motion Control for Anything using Entity Representation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/12 - Chronos: Learning the Language of Time Series
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/12 - Branch-Train-MiX: Mixing Expert LLMs into a Mixture-of-Experts LLM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/11 - Transparent AI Disclosure Obligations: Who, What, When, Where, Why, How
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/11 - HILL: A Hallucination Identifier for Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/11 - FAX: Scalable and Differentiable Federated Primitives in JAX
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/11 - FashionReGen: LLM-Empowered Fashion Report Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/11 - VideoMamba: State Space Model for Efficient Video Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/11 - V3D: Video Diffusion Models are Effective 3D Generators
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/11 - Stealing Part of a Production Language Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/11 - Multistep Consistency Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/11 - FaceChain-SuDe: Building Derived Class to Inherit Category Attributes for One-shot Subject-Driven Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/11 - Chain-of-table: Evolving tables in the reasoning chain for table understanding (Blog),
- 03/11 - An Image is Worth 1/2 Tokens After Layer 2: Plug-and-Play Inference Acceleration for Large Vision-Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/11 - Adding NVMe SSDs to Enable and Accelerate 100B Model Fine-tuning on a Single GPU
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/10 - VidProM: A Million-scale Real Prompt-Gallery Dataset for Text-to-Video Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/09 - Algorithmic progress in language models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/08 - Sora as an AGI World Model? A Complete Survey on Text-to-Video Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/08 - On Protecting the Data Privacy of Large Language Models (LLMs): A Survey
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/08 - VideoElevator: Elevating Video Generation Quality with Versatile Text-to-Image Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/08 - Personalized Audiobook Recommendations at Spotify Through Graph Neural Networks
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/08 - Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/08 - ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/08 - DeepSeek-VL: Towards Real-World Vision-Language Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/08 - CRM: Single Image to 3D Textured Mesh with Convolutional Reconstruction Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/08 - CogView3: Finer and Faster Text-to-Image Generation via Relay Diffusion
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/08 - Now available on Poe: Claude 3 (Demo),
- 03/08 - Google - Health-specific embedding tools for dermatology and pathology (Blog),
- 03/07 - Yi: Open Foundation Models by 01.AI
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/07 - Teaching Large Language Models to Reason with Reinforcement Learning
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/07 - StableDrag: Stable Dragging for Point-based Image Editing
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/07 - Radiative Gaussian Splatting for Efficient X-ray Novel View Synthesis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/07 - PixArt-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/07 - Pix2Gif: Motion-Guided Diffusion for GIF Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/07 - Meet ‘Liberated Qwen’, an uncensored LLM that strictly adheres to system prompts (News),
- 03/07 - LLMs in the Imaginarium: Tool Learning through Simulated Trial and Error
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/07 - KAIST develops next-generation ultra-low power LLM accelerator (News),
- 03/07 - Inflection-2.5: meet the world's best personal AI (News),
- 03/07 - How Far Are We from Intelligent Visual Deductive Reasoning?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/07 - GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/07 - Evaluating LLM models at scale (Blog),
- 03/07 - Common 7B Language Models Already Possess Strong Math Capabilities
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/07 - Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/06 - Stop Regressing: Training Value Functions via Classification for Scalable Deep RL
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/06 - ShortGPT: Layers in Large Language Models are More Redundant Than You Expect
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/06 - SaulLM-7B: A pioneering Large Language Model for Law
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/06 - NY hospital exec: Multimodal LLM assistants will create a “paradigm shift” in patient care (News),
- 03/06 - Learning to Decode Collaboratively with Multiple Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/06 - Enhancing Vision-Language Pre-training with Rich Supervisions
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/06 - Backtracing: Retrieving the Cause of the Query
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/06 - AI Prompt Engineering Is Dead (News),
- 03/06 - 3D Diffusion Policy
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/05 - OpenAI and Elon Musk (Blog),
- 03/05 - Caduceus: Bi-Directional Equivariant Long-Range DNA Sequence Modeling
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - WikiTableEdit: A Benchmark for Table Editing by Natural Language Instruction (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Updating the Minimum Information about CLinical Artificial Intelligence (MI-CLAIM) checklist for generative modeling research (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/05 - Tuning-Free Noise Rectification for High Fidelity Image-to-Video Generation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Scaling Rectified Flow Transformers for High-Resolution Image Synthesis (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - RT-Sketch: Goal-Conditioned Imitation Learning from Hand-Drawn Sketches (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/05 - Revisiting Meta-evaluation for Grammatical Error Correction (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Modeling Collaborator: Enabling Subjective Vision Classification With Minimal Human Effort via LLM Tool-Use (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - MathScale: Scaling Instruction Tuning for Mathematical Reasoning (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/05 - KnowAgent: Knowledge-Augmented Planning for LLM-Based Agents (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/05 - Interactive Continual Learning: Fast and Slow Thinking (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - InjecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - In Search of Truth: An Interrogation Approach to Hallucination Detection (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - ImgTrojan: Jailbreaking Vision-Language Models with ONE Image (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Generative Software Engineering (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/05 - Finetuned Multimodal Language Models Are High-Quality Image-Text Data Filters (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Feast Your Eyes: Mixture-of-Resolution Adaptation for Multimodal Large Language Models (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Exploring the Limitations of Large Language Models in Compositional Relation Reasoning (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - EasyQuant: An Efficient Data-free Quantization Algorithm for LLMs (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Design2Code: How Far Are We From Automating Front-End Engineering? (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - ChatGPT and biometrics: an assessment of face recognition, gender detection, and age estimation capabilities (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - ChatCite: LLM Agent with Human Workflow Guidance for Comparative Literature Summary (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Benchmarking the Text-to-SQL Capability of Large Language Models: A Comprehensive Evaluation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - An Empirical Study of LLM-as-a-Judge for LLM Evaluation: Fine-tuned Judge Models are Task-specific Classifiers (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 3/5 - OpenAI - ChatGPT can now read responses to you. (twitter,
- 03/04 - The Claude 3 Model Family: Opus, Sonnet, Haiku
() (twitter), , (✳️)
- 03/04 - Wukong: Towards a Scaling Law for Large-Scale Recommendation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/04 - Large language models surpass human experts in predicting neuroscience results
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/04 - NoteLLM: A Retrievable Large Language Model for Note Recommendation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/04 - MagicClay: Sculpting Meshes With Generative Neural Fields (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/04 - Enhancing LLM Safety via Constrained Direct Preference Optimization (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/04 - DACO: Towards Application-Driven and Comprehensive Data Analysis via Code Generation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/04 - CODE-ACCORD: A Corpus of Building Regulatory Data for Rule Generation towards Automatic Compliance Checking (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/04 - Balancing Enhancement, Harmlessness, and General Capabilities: Enhancing Conversational LLMs with Direct RLHF (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/04 - adaptMLLM: Fine-Tuning Multilingual Language Models on Low-Resource Languages with Integrated LLM Playgrounds (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 3/4 - ViewDiff: 3D-Consistent Image Generation with Text-to-Image Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 3/4 - TripoSR: Fast 3D Object Reconstruction from a Single Image (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 3/4 - RT-H: Action Hierarchies Using Language (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/4 - ResAdapter: Domain Consistent Resolution Adapter for Diffusion Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/4 - OOTDiffusion: Outfitting Fusion based Latent Diffusion for Controllable Virtual Try-on (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 3/4 - Build AI for a Better Future (twitter), (News),
- 3/4 - AtomoVideo: High Fidelity Image-to-Video Generation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 03/03 - Research Papers in February 2024: A LoRA Successor, Small Finetuned LLMs Vs Generalist LLMs, and Transparent LLM Research (Blog),
- 3/3 - Nvidia CEO Jensen Huang says AI could pass most human tests in 5 years (News
- 3/3 - MovieLLM: Enhancing Long Video Understanding with AI-Generated Movies (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/3 - InfiMM-HD: A Leap Forward in High-Resolution Multimodal Understanding (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/3 - Could this be bigger than OpenAI? Microsoft invests billions in French startup — Mistral AI is a multilingual maestro that's almost as good as ChatGPT 4 (News),
- 3/3 - 3DGStream: On-the-Fly Training of 3D Gaussians for Efficient Streaming of Photo-Realistic Free-Viewpoint Videos (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/2 - Nvidia CEO says AI could pass human tests in five years (News
- 3/1 - Elon Musk sues OpenAI and CEO Sam Altman over contract breach (News)
- 3.1 - AtP*: An efficient and scalable method for localizing LLM behaviour to components (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - VisionLLaMA: A Unified LLaMA Interface for Vision Tasks (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - Learning and Leveraging World Models in Visual Representation Learning (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - RealCustom: Narrowing Real Text Word for Real-Time Open-Domain Text-to-Image Customization (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - Multimodal ArXiv: A Dataset for Improving Scientific Comprehension of Large Vision-Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - Resonance RoPE: Improving Context Length Generalization of Large Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 02/29 - OHTA: One-shot Hand Avatar via Data-driven Implicit Priors
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 02/29 - Retrieval-Augmented Generation for AI-Generated Content: A Survey (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 2.29 - DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Panda-70M: Captioning 70M Videos with Multiple Cross-Modality Teachers (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Humanoid Locomotion as Next Token Prediction (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - StarCoder 2 and The Stack v2: The Next Generation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Trajectory Consistency Distillation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.29 - Beyond Language Models: Byte Models are Digital World Simulators (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Syntactic Ghost: An Imperceptible General-purpose Backdoor Attacks on Pre-trained Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - ViewFusion: Towards Multi-View Consistency via Interpolated Denoising (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.29 - MOSAIC: A Modular System for Assistive and Interactive Cooking (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 02/28 - Automatic Creative Selection with Cross-Modal Matching
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 2.28 - Priority Sampling of Large Language Models for Compilers (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.28 - Simple linear attention language models balance the recall-throughput tradeoff (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.28 - Approaching Human-Level Forecasting with Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.28 - Datasets for Large Language Models: A Comprehensive Survey (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.28 - A Survey on Recent Advances in LLM-Based Multi-turn Dialogue Systems (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 02/27 - A High Level Guide to LLM Evaluation Metrics (Blog),
- 2/27 - Users Say Microsoft's AI Has Alternate Personality as Godlike AGI That Demands to Be Worshipped (News)
- 2/27 - Google DeepMind CEO on AGI, OpenAI and Beyond – MWC 2024 (News)
- 2.27 - Large Language Models(LLMs) on Tabular Data: Prediction, Generation, and Understanding -- A Survey (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.27 - Towards Optimal Learning of Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Evaluating Very Long-Term Conversational Memory of LLM Agents (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Seeing and Hearing: Open-domain Visual-Audio Generation with Diffusion Latent Aligners (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - OmniACT: A Dataset and Benchmark for Enabling Multimodal Generalist Autonomous Agents for Desktop and Web (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - EMO: Emote Portrait Alive -- Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - EMO: Emote Portrait Alive - Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Training-Free Long-Context Scaling of Large Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.27 - VastGaussian: Vast 3D Gaussians for Large Scene Reconstruction (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - DiffuseKronA: A Parameter Efficient Fine-tuning Method for Personalized Diffusion Model (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Sora Generates Videos with Stunning Geometrical Consistency (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Playground v2.5: Three Insights towards Enhancing Aesthetic Quality in Text-to-Image Generation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.27 - Video as the New Language for Real-World Decision Making (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 02/27 - On the Societal Impact of Open Foundation Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 02/26 - Set the Clock: Temporal Alignment of Pretrained Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 2/26 - DenseMamba: State Space Models with Dense Hidden Connection for Efficient Large Language Models (), ()(?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 02/26 - Mistral Large is our flagship model, with top-tier reasoning capacities (News)
- 2.26 - Disentangled 3D Scene Generation with Layout Learning (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - Multi-LoRA Composition for Image Generation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - MobiLlama: Towards Accurate and Lightweight Fully Transparent GPT (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.26 - Do Large Language Models Latently Perform Multi-Hop Reasoning? (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - Rainbow Teaming: Open-Ended Generation of Diverse Adversarial Prompts (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - Nemotron-4 15B Technical Report (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - StructLM: Towards Building Generalist Models for Structured Knowledge Grounding (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - Towards Open-ended Visual Quality Comparison (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.25 - ChatMusician: Understanding and Generating Music Intrinsically with LLM (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.25 - FuseChat: Knowledge Fusion of Chat Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 02/24 - Divide-or-Conquer? Which Part Should You Distill Your LLM?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 02/24 - Perplexity.ai Revamps Google SEO Model For LLM Era (News)
- 02/24 - Data Interpreter: An LLM Agent For Data Science
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 2.24 - Empowering Large Language Model Agents through Action Learning (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - Seamless Human Motion Composition with Blended Positional Encodings (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.23 - AgentOhana: Design Unified Data and Training Pipeline for Effective Agent Learning (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - Gen4Gen: Generative Data Pipeline for Generative Multi-Concept Composition (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.23 - API-BLEND: A Comprehensive Corpora for Training and Benchmarking API LLMs (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - Genie: Generative Interactive Environments (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - GPTVQ: The Blessing of Dimensionality for LLM Quantization (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - ChunkAttention: Efficient Self-Attention with Prefix-Aware KV Cache and Two-Phase Partition (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.22 - CLoVe: Encoding Compositional Language in Contrastive Vision-Language Models (), (), (?), (?), (?), (HTML), (AS), (GS), (✳️), ()
- 02/22 - Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 2.22 - Divide-or-Conquer? Which Part Should You Distill Your LLM? (), (), (?), (?), (?), (HTML), (AS), (GS), (✳️)
- 2.22 - MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases (), (), (?), (?), (?), (HTML), (AS), (GS), (✳️)
- 2.22 - Watermarking Makes Language Models Radioactive (), (), (?), (?), (?), (HTML), (AS), (GS), (✳️)
- 2.22 - AutoPrompt - prompt optimization framework ()
- 2.22 - Announcing Stable Diffusion 3 (tweet), (blog)
- 2.22 - DualFocus: Integrating Macro and Micro Perspectives in Multi-modal Large Language Models (), (), (?), (?), (?), (HTML), (✳️) , ()
- 2.22 - RoboScript: Code Generation for Free-Form Manipulation Tasks across Real and Simulation (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - LLMs with Industrial Lens: Deciphering the Challenges and Prospects -- A Survey (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - Vision-Language Navigation with Embodied Intelligence: A Survey (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - Enhancing Robotic Manipulation with AI Feedback from Multimodal Large Language Models (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - Do Machines and Humans Focus on Similar Code? Exploring Explainability of Large Language Models in Code Summarization (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - PALO: A Polyglot Large Multimodal Model for 5B People (), (), (?), (?), (?), (HTML), (✳️) , ()
- 2.22 - GeneOH Diffusion: Towards Generalizable Hand-Object Interaction Denoising via Denoising Diffusion (), (), ([:paperclip:](https://arxiv.org/pdf/2402.148


