YAYI UIE
1.0.0

[README] [?HF Repo] [?Web version]
Chinese | English
[2024.03.28] All models and data are uploaded to the Magic Community.
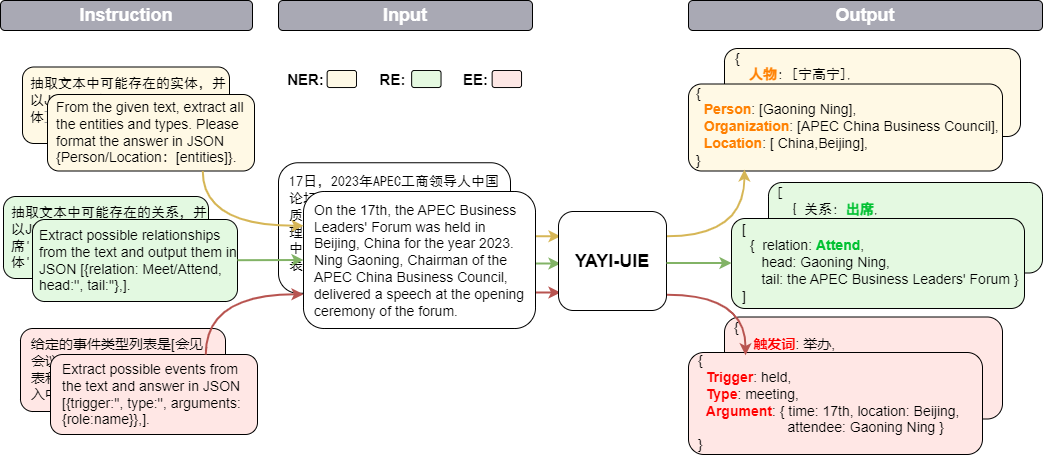
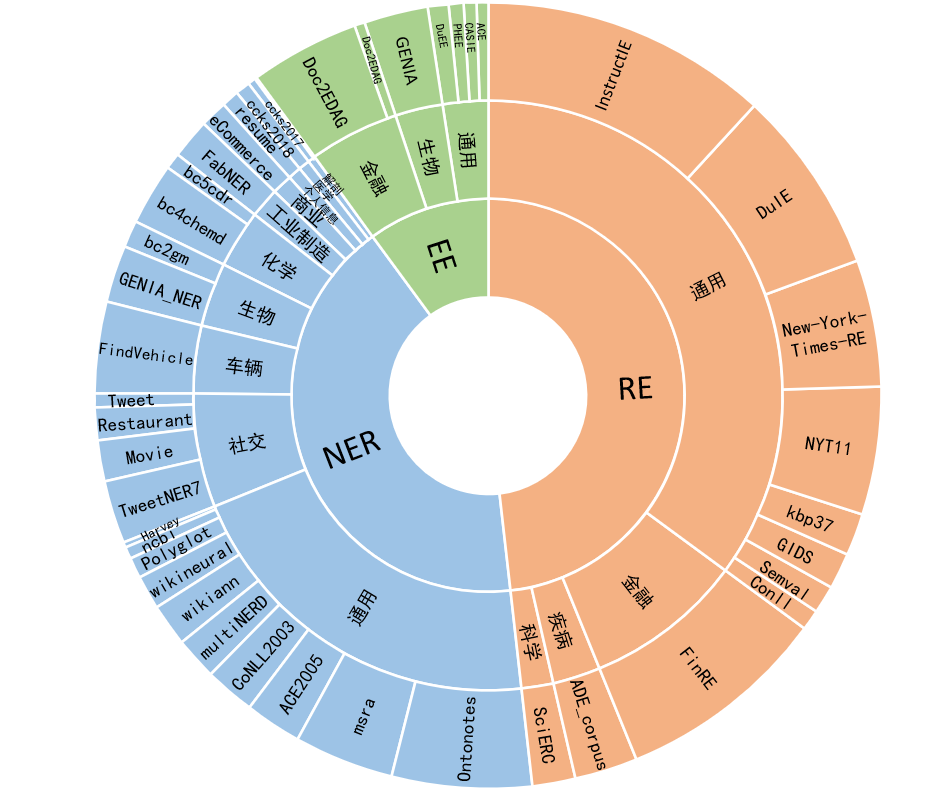
Yayi Information Extraction Unified Large Model (YAYI-UIE) fine-tunes instructions on millions of manually constructed high-quality information extraction data. The unified training information extraction tasks include named entity recognition (NER), relationship extraction (RE) and event extraction ( EE) to achieve structured extraction in general, security, financial, biological, medical, commercial, personal, vehicle, movie, industrial, restaurant, scientific and other scenarios.
Through the open source of the Yayi UIE large model, we will contribute our own efforts to promote the development of the Chinese pre-trained large model open source community. Through open source, we will build the Yayi large model ecosystem with every partner. For more technical details, please read our technical report YAYI-UIE: A Chat-Enhanced Instruction Tuning Framework for Universal Information Extraction.
| name | ? HF model identification | Download address | Magic model logo | Download address |
|---|---|---|---|---|
| YAYI-UIE | wenge-research/yayi-uie | Model download | wenge-research/yayi-uie | Model download |
| YAYI-UIE Data | wenge-research/yayi_uie_sft_data | Data set download | wenge-research/yayi_uie_sft_data | Data set download |
54% of the million-level corpus is Chinese and 46% is English; the data set includes 12 fields including finance, society, biology, commerce, industrial manufacturing, chemistry, vehicles, science, disease and medical treatment, personal life, security and general. Covers hundreds of scenarios
git clone https://github.com/wenge-research/yayi-uie.git
cd yayi-uieconda create --name uie python=3.8
conda activate uiepip install -r requirements.txt The torch and transformers versions are not recommended to be lower than the recommended versions.
The model has been open sourced in our Huggingface model repository, and you are welcome to download and use it. The following is a sample code that simply calls YAYI-UIE for downstream task inference. It can be run on a single GPU such as A100/A800. It takes up about 33GB of video memory when using bf16 precision inference:
> >> import torch
> >> from transformers import AutoModelForCausalLM , AutoTokenizer
> >> from transformers . generation . utils import GenerationConfig
> >> tokenizer = AutoTokenizer . from_pretrained ( "wenge-research/yayi-uie" , use_fast = False , trust_remote_code = True )
> >> model = AutoModelForCausalLM . from_pretrained ( "wenge-research/yayi-uie" , device_map = "auto" , torch_dtype = torch . bfloat16 , trust_remote_code = True )
> >> generation_config = GenerationConfig . from_pretrained ( "wenge-research/yayi-uie" )
> >> prompt = "文本:氧化锆陶瓷以其卓越的物理和化学特性在多个行业中发挥着关键作用。这种材料因其高强度、高硬度和优异的耐磨性,广泛应用于医疗器械、切削工具、磨具以及高端珠宝制品。在制造这种高性能陶瓷时,必须遵循严格的制造标准,以确保其最终性能。这些标准涵盖了从原材料选择到成品加工的全过程,保障产品的一致性和可靠性。氧化锆的制造过程通常包括粉末合成、成型、烧结和后处理等步骤。原材料通常是高纯度的氧化锆粉末,通过精确控制的烧结工艺,这些粉末被转化成具有特定微观结构的坚硬陶瓷。这种独特的微观结构赋予氧化锆陶瓷其显著的抗断裂韧性和耐腐蚀性。此外,氧化锆陶瓷的热膨胀系数与铁类似,使其在高温应用中展现出良好的热稳定性。因此,氧化锆陶瓷不仅在工业领域,也在日常生活中的应用日益增多,成为现代材料科学中的一个重要分支。 n抽取文本中可能存在的实体,并以json{制造品名称/制造过程/制造材料/工艺参数/应用/生物医学/工程特性:[实体]}格式输出。"
> >> # "<reserved_13>" is a reserved token for human, "<reserved_14>" is a reserved token for assistant
>> > prompt = "<reserved_13>" + prompt + "<reserved_14>"
> >> inputs = tokenizer ( prompt , return_tensors = "pt" ). to ( model . device )
> >> response = model . generate ( ** inputs , max_new_tokens = 512 , temperature = 0 )
> >> print ( tokenizer . decode ( response [ 0 ], skip_special_tokens = True ))Note:
文本:xx
【实体抽取】抽取文本中可能存在的实体,并以json{人物/机构/地点:[实体]}格式输出。
文本:xx
【关系抽取】已知关系列表是[注资,拥有,纠纷,自己,增持,重组,买资,签约,持股,交易]。根据关系列表抽取关系三元组,按照json[{'relation':'', 'head':'', 'tail':''}, ]的格式输出。
文本:xx
抽取文本中可能存在的关系,并以json[{'关系':'会见/出席', '头实体':'', '尾实体':''}, ]格式输出。
文本:xx
已知论元角色列表是[时间,地点,会见主体,会见对象],请根据论元角色列表从给定的输入中抽取可能的论元,以json{角色:论元}格式输出。
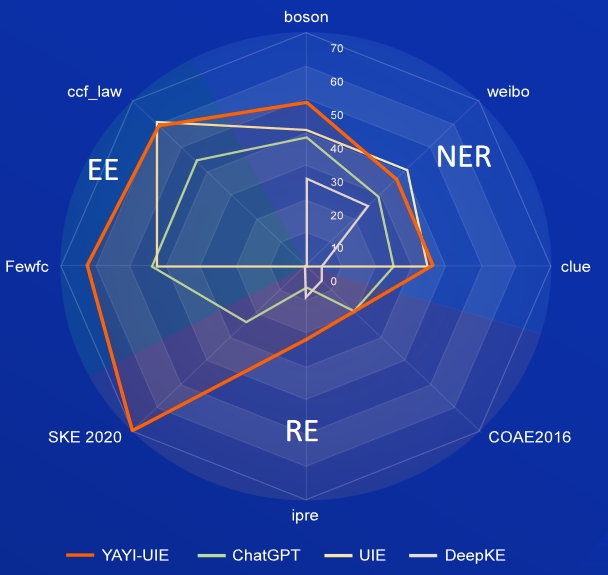
AI, Literature, Music, Politics, and Science are English data sets, and boson, clue, and weibo are Chinese data sets.
| Model | AI | Literature | Music | Politics | Science | English average | boson | clue | Chinese average | |
|---|---|---|---|---|---|---|---|---|---|---|
| davinci | 2.97 | 9.87 | 13.83 | 18.42 | 10.04 | 11.03 | - | - | - | 31.09 |
| ChatGPT 3.5 | 54.4 | 54.07 | 61.24 | 59.12 | 63 | 58.37 | 38.53 | 25.44 | 29.3 | |
| UIE | 31.14 | 38.97 | 33.91 | 46.28 | 41.56 | 38.37 | 40.64 | 34.91 | 40.79 | 38.78 |
| USM | 28.18 | 56 | 44.93 | 36.1 | 44.09 | 41.86 | - | - | - | - |
| InstructUIE | 49 | 47.21 | 53.16 | 48.15 | 49.3 | 49.36 | - | - | - | - |
| KnowLM | 13.76 | 20.18 | 14.78 | 33.86 | 9.19 | 18.35 | 25.96 | 4.44 | 25.2 | 18.53 |
| YAYI-UIE | 52.4 | 45.99 | 51.2 | 51.82 | 50.53 | 50.39 | 49.25 | 36.46 | 36.78 | 40.83 |
FewRe, Wiki-ZSL are English data sets, SKE 2020, COAE2016, IPRE are Chinese data sets
| Model | FewRel | Wiki-ZSL | English average | SKE 2020 | COAE2016 | IPRE | Chinese average |
|---|---|---|---|---|---|---|---|
| ChatGPT 3.5 | 9.96 | 13.14 | 11.55 24.47 | 19.31 | 6.73 | 16.84 | |
| ZETT(T5-small) | 30.53 | 31.74 | 31.14 | - | - | - | - |
| ZETT(T5-base) | 33.71 | 31.17 | 32.44 | - | - | - | - |
| InstructUIE | 39.55 | 35.2 | 37.38 | - | - | - | - |
| KnowLM | 17.46 | 15.33 | 16.40 | 0.4 | 6.56 | 9.75 | 5.57 |
| YAYI-UIE | 36.09 | 41.07 | 38.58 | 70.8 | 19.97 | 22.97 | 37.91 |
commodity news is the English data set, FewFC, ccf_law is the Chinese data set
EET (event type identification)
| Model | commodity news | FewFC | ccf_law | Chinese average |
|---|---|---|---|---|
| ChatGPT 3.5 | 1.41 | 16.15 | 0 | 8.08 |
| UIE | - | 50.23 | 2.16 | 26.20 |
| InstructUIE | 23.26 | - | - | - |
| YAYI-UIE | 12.45 | 81.28 | 12.87 | 47.08 |
EEA (event argument extraction)
| Model | commodity news | FewFC | ccf_law | Chinese average |
|---|---|---|---|---|
| ChatGPT 3.5 | 8.6 | 44.4 | 44.57 | 44.49 |
| UIE | - | 43.02 | 60.85 | 51.94 |
| InstructUIE | 21.78 | - | - | - |
| YAYI-UIE | 19.74 | 63.06 | 59.42 | 61.24 |
The SFT model trained based on current data and basic models still has the following problems in terms of effectiveness:
Based on the above model limitations, we require developers to only use our open source code, data, models and subsequent derivatives generated by this project for research purposes and not for commercial purposes or other uses that will cause harm to society. . Please be careful to identify and use the content generated by Yayi Big Model, and do not spread the generated harmful content to the Internet. If any adverse consequences occur, the communicator will be responsible. This project can only be used for research purposes, and the project developer is not responsible for any harm or loss caused by the use of this project (including but not limited to data, models, codes, etc.). Please refer to the disclaimer for details.
The code and data in this project are open source in accordance with the Apache-2.0 protocol. When the community uses the YAYI UIE model or its derivatives, please follow Baichuan2's community agreement and commercial agreement.
If you use our model in your work, you can cite our paper:
@article{YAYI-UIE,
author = {Xinglin Xiao, Yijie Wang, Nan Xu, Yuqi Wang, Hanxuan Yang, Minzheng Wang, Yin Luo, Lei Wang, Wenji Mao, Dajun Zeng}},
title = {YAYI-UIE: A Chat-Enhanced Instruction Tuning Framework for Universal Information Extraction},
journal = {arXiv preprint arXiv:2312.15548},
url = {https://arxiv.org/abs/2312.15548},
year = {2023}
}


