learning kcp protocol
1.0.0
In certain applications, simply using TCP cannot meet the needs. Direct use of UDP datagrams cannot guarantee data reliability, and it is often necessary to implement a reliable transmission protocol based on UDP at the application layer.
Directly using the KCP protocol is an option, which implements a robust automatic retransmission protocol and provides free parameter adjustment on top of it. Adapt to the needs of different scenarios through configuration parameters and appropriate calling methods.
Introduction to KCP:
KCP is a fast and reliable protocol that can reduce the average delay by 30%-40% and reduce the maximum delay by three times at the cost of 10%-20% more bandwidth than TCP. Pure algorithm implementation is not responsible for the sending and receiving of underlying protocols (such as UDP). Users need to define the sending method of lower-layer data packets and provide it to KCP in the form of callback. Even the clock needs to be passed in externally, and there will not be any system call internally. The entire protocol only has two source files, ikcp.h and ikcp.c, which can be easily integrated into the user's own protocol stack. Maybe you have implemented a P2P or a UDP-based protocol but lack a complete and reliable ARQ protocol implementation. Then simply copy these two files to the existing project, write a few lines of code, and you can use it.
This article briefly introduces the basic sending and receiving process, congestion window, and timeout algorithm of the KCP protocol, and also provides reference sample code.
The version of KCP referenced is the latest version at the time of writing. This article will not completely paste all the source code of KCP, but will add links to the corresponding locations of the source code at key points.
The IKCPSEG structure is used to store the status of sent and received data segments.
Description of all IKCPSEG fields:
struct IKCPSEG
{
/* 队列节点,IKCPSEG 作为一个队列元素,此结构指向了队列后前后元素 */
struct IQUEUEHEAD node;
/* 会话编号 */
IUINT32 conv;
/* 指令类型 */
IUINT32 cmd;
/* 分片号 (fragment)
发送数据大于 MSS 时将被分片,0为最后一个分片.
意味着数据可以被recv,如果是流模式,所有分片号都为0
*/
IUINT32 frg;
/* 窗口大小 */
IUINT32 wnd;
/* 时间戳 */
IUINT32 ts;
/* 序号 (sequence number) */
IUINT32 sn;
/* 未确认的序号 (unacknowledged) */
IUINT32 una;
/* 数据长度 */
IUINT32 len;
/* 重传时间 (resend timestamp) */
IUINT32 resendts;
/* 重传的超时时间 (retransmission timeout) */
IUINT32 rto;
/* 快速确认计数 (fast acknowledge) */
IUINT32 fastack;
/* 发送次数 (transmit) */
IUINT32 xmit;
/* 数据内容 */
char data[1];
};
The data field at the end of the structure is used to index the data at the end of the structure. The additional allocated memory extends the actual length of the data field array at runtime (ikcp.c:173).
The IKCPSEG structure is memory state only, and only some fields are encoded into the transport protocol.
The ikcp_encode_seg function encodes the transport protocol header:
/* 协议头一共 24 字节 */
static char *ikcp_encode_seg(char *ptr, const IKCPSEG *seg)
{
/* 会话编号 (4 Bytes) */
ptr = ikcp_encode32u(ptr, seg->conv);
/* 指令类型 (1 Bytes) */
ptr = ikcp_encode8u(ptr, (IUINT8)seg->cmd);
/* 分片号 (1 Bytes) */
ptr = ikcp_encode8u(ptr, (IUINT8)seg->frg);
/* 窗口大小 (2 Bytes) */
ptr = ikcp_encode16u(ptr, (IUINT16)seg->wnd);
/* 时间戳 (4 Bytes) */
ptr = ikcp_encode32u(ptr, seg->ts);
/* 序号 (4 Bytes) */
ptr = ikcp_encode32u(ptr, seg->sn);
/* 未确认的序号 (4 Bytes) */
ptr = ikcp_encode32u(ptr, seg->una);
/* 数据长度 (4 Bytes) */
ptr = ikcp_encode32u(ptr, seg->len);
return ptr;
}
The IKCPCB structure stores all the context of the KCP protocol, and protocol communication is performed by creating two IKCPCB objects at the opposite end.
struct IKCPCB
{
/* conv: 会话编号
mtu: 最大传输单元
mss: 最大报文长度
state: 此会话是否有效 (0: 有效 ~0:无效)
*/
IUINT32 conv, mtu, mss, state;
/* snd_una: 发送的未确认数据段序号
snd_nxt: 发送的下一个数据段序号
rcv_nxt: 期望接收到的下一个数据段的序号
*/
IUINT32 snd_una, snd_nxt, rcv_nxt;
/* ts_recent: (弃用字段?)
ts_lastack: (弃用字段?)
ssthresh: 慢启动阈值 (slow start threshold)
*/
IUINT32 ts_recent, ts_lastack, ssthresh;
/* rx_rttval: 平滑网络抖动时间
rx_srtt: 平滑往返时间
rx_rto: 重传超时时间
rx_minrto: 最小重传超时时间
*/
IINT32 rx_rttval, rx_srtt, rx_rto, rx_minrto;
/* snd_wnd: 发送窗口大小
rcv_wnd: 接收窗口大小
rmt_wnd: 远端窗口大小
cwnd: 拥塞窗口 (congestion window)
probe: 窗口探测标记位,在 flush 时发送特殊的探测包 (window probe)
*/
IUINT32 snd_wnd, rcv_wnd, rmt_wnd, cwnd, probe;
/* current: 当前时间 (ms)
interval: 内部时钟更新周期
ts_flush: 期望的下一次 update/flush 时间
xmit: 全局重传次数计数
*/
IUINT32 current, interval, ts_flush, xmit;
/* nrcv_buf: rcv_buf 接收缓冲区长度
nsnd_buf: snd_buf 发送缓冲区长度
nrcv_que: rcv_queue 接收队列长度
nsnd_que: snd_queue 发送队列长度
*/
IUINT32 nrcv_buf, nsnd_buf;
IUINT32 nrcv_que, nsnd_que;
/* nodelay: nodelay模式 (0:关闭 1:开启)
updated: 是否调用过 update 函数
*/
IUINT32 nodelay, updated;
/* ts_probe: 窗口探测标记位
probe_wait: 零窗口探测等待时间,默认 7000 (7秒)
*/
IUINT32 ts_probe, probe_wait;
/* dead_link: 死链接条件,默认为 20。
(单个数据段重传次数到达此值时 kcp->state 会被设置为 UINT_MAX)
incr: 拥塞窗口算法的一部分
*/
IUINT32 dead_link, incr;
/* 发送队列 */
struct IQUEUEHEAD snd_queue;
/* 接收队列 */
struct IQUEUEHEAD rcv_queue;
/* 发送缓冲区 */
struct IQUEUEHEAD snd_buf;
/* 接收缓冲区 */
struct IQUEUEHEAD rcv_buf;
/* 确认列表, 包含了序号和时间戳对(pair)的数组元素*/
IUINT32 *acklist;
/* 确认列表元素数量 */
IUINT32 ackcount;
/* 确认列表实际分配长度 */
IUINT32 ackblock;
/* 用户数据指针,传入到回调函数中 */
void *user;
/* 临时缓冲区 */
char *buffer;
/* 是否启用快速重传,0:不开启,1:开启 */
int fastresend;
/* 快速重传最大次数限制,默认为 5*/
int fastlimit;
/* nocwnd: 控流模式,0关闭,1不关闭
stream: 流模式, 0包模式 1流模式
*/
int nocwnd, stream;
/* 日志标记 */
int logmask;
/* 发送回调 */
int (*output)(const char *buf, int len, struct IKCPCB *kcp, void *user);
/* 日志回调 */
void (*writelog)(const char *log, struct IKCPCB *kcp, void *user);
};
typedef struct IKCPCB ikcpcb;
There are only 2 queue structures in KCP:
IQUEUEHEAD is a simple doubly linked list that points to the start (prev) and last (next) elements of the queue:
struct IQUEUEHEAD {
/*
next:
作为队列时: 队列的首元素 (head)
作为元素时: 当前元素所在队列的下一个节点
prev:
作为队列时: 队列的末元素 (last)
作为元素时: 当前元素所在队列的前一个节点
*/
struct IQUEUEHEAD *next, *prev;
};
typedef struct IQUEUEHEAD iqueue_head;
When the queue is empty, next/prev will point to the queue itself, not NULL.
The IKCPSEG structure header as a queue element also reuses the IQUEUEHEAD structure:
struct IKCPSEG
{
struct IQUEUEHEAD node;
/* ... */
}
When used as a queue element, the previous (prev) element and next element (next) in the queue where the current element is located are recorded.
When prev points to the queue, it means that the current element is at the beginning of the queue, and when next points to the queue, it means that the current element is at the end of the queue.
All queue operations are provided as macros.
The configuration methods provided by KCP are:
Working mode options :
int ikcp_nodelay(ikcpcb *kcp, int nodelay, int interval, int resend, int nc)
Maximum window options :
int ikcp_wndsize(ikcpcb *kcp, int sndwnd, int rcvwnd);
The sending window size sndwnd must be greater than 0, and the receiving window size rcvwnd must be greater than 128. The unit is packets, not bytes.
Maximum transmission unit :
KCP is not responsible for detecting MTU. The default value is 1400 bytes. You can use ikcp_setmtu to set this value. This value will affect the maximum transmission unit when combining and fragmenting data packets. A smaller MTU will affect routing priority.
This article provides a code kcp_basic.c that can basically run KCP. The sample code of less than 100 lines is a pure algorithm call to KCP and does not include any network scheduling. ( Important : follow the article to debug it and give it a try!)
You can use it to get a preliminary understanding of the basic structure fields in the IKCPCB structure:
kcp.snd_queue : send queue ( kcp.nsnd_que record length)kcp.snd_buf : send buffer ( kcp.nsnd_buf record length)kcp.rcv_queue : receive queue ( kcp.nrcv_que record length)kcp.rcv_buf : receive buffer ( kcp.nrcv_buf record length)kcp.mtu : maximum transmission unitkcp.mss : Maximum message lengthAnd in the structure IKCPSEG:
seg.sn : serial numberseg.frg : Segment numberCreate the KCP context structure IKCPCB through the ikcp_create function.
IKCPCB internally creates the corresponding IKCPSEG structure to store data and status by externally calling ikcp_send (user input to the sender) and ikcp_input input data (sender input to the receiver).
In addition, the IKCPSEG structure will be removed through ikcp_recv (removed by the user from the receiving end) and ikcp_input confirmation data (received by the sending end from the receiving end).
For detailed data flow direction, see the Queue and Window section.
The creation and destruction of IKCPSEG mainly occurs in the above four situations, and others are common in movements between internal queues and other optimizations.
In the following articles, all the IKCPCB and IKCPSEG structure fields that appear will be highlighted by
标记(markdown browsing only, others may not see it). All fields of the IKCPCB structure will be prefixed withkcp., and all fields of the IKCPSEG structure will be prefixed withseg.. Usually the corresponding variable name or function parameter name in the source code is alsokcporseg.
This code simply writes the specified length of data to the KCP object named k1 and reads the data from the k2 object. KCP is configured in default mode.
The basic process can be simply described through pseudocode as:
/* 创建两个 KCP 对象 */
k1 = ikcp_create()
k2 = ikcp_create()
/* 向发送端 k1 写入数据 */
ikcp_send(k1, send_data)
/* 刷出数据,执行 kcp->output 回调 */
ikcp_flush(k1)
/* output 回调接收到带协议包头的分片数据,执行发送 */
k1->output(fragment_data)
/* 接收端 k2 收到输入数据 */
ikcp_input(k2, input_data)
/* 接收端刷出数据,会发送确认包到 k1 */
ikcp_flush(k2)
/* 发送端 k1 收到确认数据 */
recv_data = ikcp_recv(k1, ack_data)
/* 尝试读出数据 */
recv = ikcp_recv(k2)
/* 验证接收数据和发送数据一致 */
assert(recv_data == send_data)
In the sample code, the created KCP object is bound to the kcp_user_output function in addition to kcp.output which is used to define the behavior of the KCP object's output data. kcp.writelog is also bound to the kcp_user_writelog function for debugging printing.
In addition, since kcp.output callback cannot call other ikcp_input recursively (because it will eventually recurse to its own kcp.output ), all output data must be stored in an intermediate location, and then input into k2 after exiting the kcp.output function. This is the purpose of the OUTPUT_CONTEXT structure defined in the sample code.
Try running the sample code and you will get the following output (the content appended with the # sign is an explanation):
# k1.output 被调用,输出 1400 字节
k1 [RO] 1400 bytes
# k2 被调用 ikcp_input 输入数据
k2 [RI] 1400 bytes
# psh 数据推送分支处理
k2 input psh: sn=0 ts=0
# k2.output 被调用,输出确认包,数据长度24字节
k2 [RO] 24 bytes
# k1 被调用 ikcp_input 输入数据
k1 [RI] 24 bytes
# 序号 sn=0 被确认
k1 input ack: sn=0 rtt=0 rto=100
k1 [RO] 1400 bytes
k1 [RO] 1368 bytes
k2 [RI] 1400 bytes
k2 input psh: sn=1 ts=0
k2 [RI] 1368 bytes
k2 input psh: sn=2 ts=0
k2 [RO] 48 bytes
k1 [RI] 48 bytes
k1 input ack: sn=1 rtt=0 rto=100
k1 input ack: sn=2 rtt=0 rto=100
# k2 被调用 kcp_recv 取出数据
k2 recv sn=0
k2 recv sn=1
k2 recv sn=2
The output content is the debugging information printed built into the KCP code. The k1/k2 line prefix is additionally appended through kcp_user_writelog as a distinction.
The complete schematic diagram of the sending confirmation process of this code is described as (twice the size):
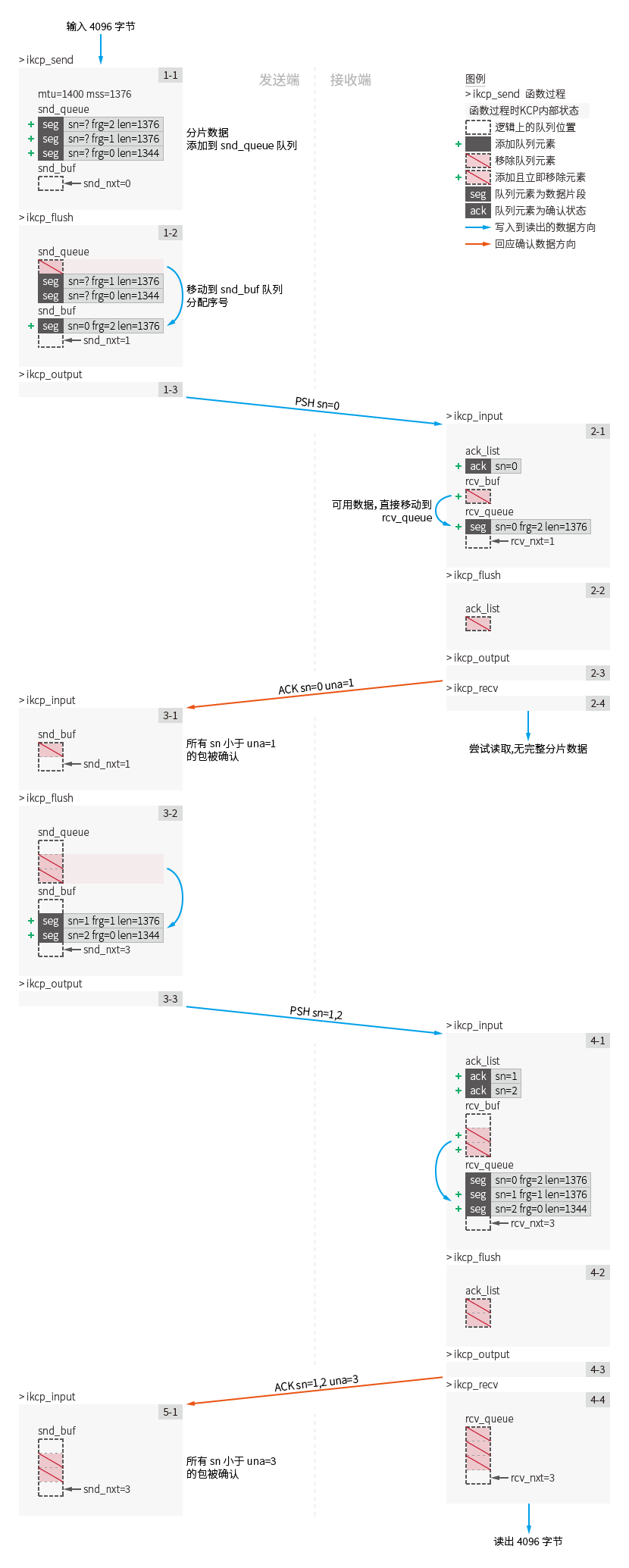
Call ikcp_send on k1: (Figure step 1-1)
Data with a length of 4096 is written to the sender. According to kcp.mss it is cut into three packets with a length of 1376/1376/1344, and seg.frg fragmentation marks of each packet are 2/1/0 respectively.
kcp.mtu maximum transmission unit defines the maximum data length received by ikcp.output callback each time. The default is 1400.
In the schematic diagram, the ikcp_output method will eventually call the
ikcp.outputfunction pointer. (ikcp.c:212)
The maximum message length of kcp.mss is calculated by subtracting the protocol overhead (24 bytes) from kcp.mtu . The default is 1376.
No kcp.output callback will be executed at this time, and all shard data will be allocated and recorded into the IKCPSEG structure and appended to the kcp.snd_queue queue (ikcp.c:528).
At this time, the kcp.snd_queue queue length of k1 is 3, and the kcp.snd_buf queue length is 0.
Call ikcp_flush on k1: (Figure step 1-2)
The specific calculation process of the window is ignored here. You only need to know that the value of the congestion window
kcp.cwndis 1 when k1 calls ikcp_flush for the first time.
Because of the congestion window limit, only one packet can be sent for the first time. The IKCPSEG object with the first data length of the kcp.snd_queue queue is moved to the kcp.snd_buf queue (ikcp.c:1028), and the value of the sequence number seg.sn assigned according to kcp.snd_nxt is 0 (ikcp.c:1036) , the seg.cmd field is IKCP_CMD_PUSH, Represents a data push package.
At this time, the kcp.snd_queue queue length of k1 is 2, and kcp.snd_buf queue length is 1.
In step 1-3, execute ikcp_output call (ikcp.c:1113) on the first sent data to send out the data packet [PSH sn=0 frg=2 len=1376] .
There are only four data command types: IKCP_CMD_PUSH (data push) IKCP_CMD_ACK (confirmation) IKCP_CMD_WASK (window detection) IKCP_CMD_WINS (window response), defined in ikcp.c:29
Call ikcp_input on k2: (Figure step 2-1)
Input the data packet [PSH sn=0 frg=2 len=1376] , parse the packet header and check the validity. (ikcp.c:769)
Analyze the type of data packet and enter the data push branch processing. (ikcp.c:822)
Record the seq.sn value and seq.ts value of the data packet to the confirmation list kcp.acklist (ikcp.c:828). Please note : the value of seq.ts in this example is always 0.
Add received packets to the kcp.rcv_buf queue. (ikcp:709)
Check whether the first data packet in kcp.rcv_buf queue is available. If it is an available data packet, it is moved to kcp.rcv_queue queue. (ikcp.c:726)
The available data packets in kcp.rcv_buf are defined as: the next data sequence number expected to be received (taken from kcp.rcv_nxt , where the next data sequence number should be seg.sn == 0) and the length of the kcp.rcv_queue queue is less than the received Window size.
In this step, the only data packet in the kcp.rcv_buf queue is directly moved to the kcp.rcv_queue queue.
At this time, kcp.>rcv_queue queue length of k2 is 1, and the kcp.snd_buf queue length is 0. The value of the next received data sequence number kcp.rcv_nxt is updated from 0 to 1.
Call ikcp_flush on k2: (Fig. Step 2-2)
In k2's first ikcp_flush call. Because there is data in the confirmation list kcp.acklist , the confirmation packet will be encoded and sent out (ikcp.c:958).
The seg.una value in the confirmation packet is assigned kcp.rcv_nxt =1.
This packet is recorded as [ACK sn=0 una=1] : It means that in the ack confirmation, packet sequence number 0 is confirmed. In una confirmation, all packets before packet number 1 are confirmed.
In step 2-3, kcp.output is called to send the data packet.
Call ikcp_recv on k2: (Figure Step 2-4)
Check whether the kcp.rcv_queue queue contains a packet with seg.frp value of 0 (ikcp.c:459). If it contains this packet, record the first packet seg.frp == 0 and the data of the packet before this packet. The total length is returned as the return value. If not, this function returns a failure value of -1.
Because kcp.rcv_queue only has the package [PSH sn=0 frg=2 len=1376] at this time, the attempt to read failed.
If it is in stream mode (kcp.stream != 0), all packets will be marked as
seg.frg=0. At this time, any packets in thekcp.rcv_queuequeue will be read successfully.
Call ikcp_input: on k1 (Figure step 3-1)
Input packet [ACK sn=0 una=1] .
UNA confirms :
Any package received will first attempt UNA confirmation (ikcp.c:789)
Confirmed and removed all packets in the kcp.snd_buf queue seg.sn value is smaller than the una value (ikcp:599) by confirming the seg.una value of the packet.
[PSH sn=0 frg=2 len=1376] is confirmed and removed from the kcp.snd_buf queue of k1.
ACK confirmation :
Analyze the type of data packet and enter the confirmation branch processing. (ikcp.c:792)
Match the sequence numbers of the confirmation packets and remove the corresponding packets. (ikcp.c:581)
When performing ACK confirmation in step 3-1, the kcp.snd_buf queue is already empty because the only packet [PSH sn=0 frg=2 len=1376] has been confirmed by UNA in advance.
If kcp.snd_buf queue header data is confirmed ( kcp.snd_una changes), the congestion window size cwnd value is recalculated and updated to 2 (ikcp.c:876).
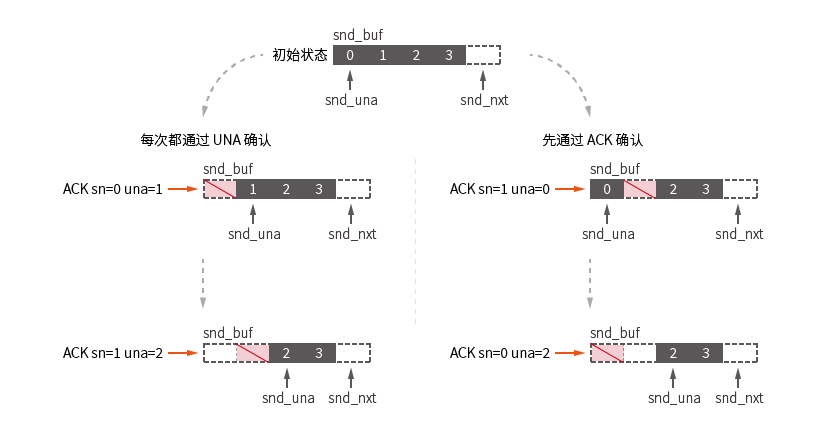
UNA / ACK confirmation diagram, this diagram additionally records the status of unmarked kcp.snd_una in the process diagram:
ACK acknowledgment will not work for acknowledgment packets arriving sequentially. For packets arriving out of order, the packet is individually removed after confirmation via ACK:
Call ikcp_flush on k1: (Figure step 3-2)
Just like step 1-2, the value of the new congestion window kcp.cwnd has been updated to 2, and the remaining two packets will be sent this time: [PSH sn=1 frg=1 len=1376] [PSH sn=2 frg=0 len=1344] .
In step 3-3, kcp.output will actually be called twice to send out data packets respectively.
Call ikcp_input: on k2 (Figure step 4-1)
Input packets [PSH sn=1 frg=1 len=1376] and [PSH sn=2 frg=0 len=1344] .
Each packet is added to the kcp.rcv_buf queue, it is available, and eventually all is moved to the kcp.rcv_queue queue.
At this time, the kcp.rcv_queue queue length of k2 is 3, and kcp.snd_buf length is 0. The value of kcp.rcv_nxt for the next packet expected to be received is updated from 1 to 3.
Call ikcp_flush on k2: (Figure step 4-2)
The acknowledgment information in kcp.acklist will be encoded into packets [ACK sn=1 una=3] and [ACK sn=2 una=3] and sent in step 4-3.
In fact, these two packets will be written to a buffer and a kcp.output call will be made.
Call ikcp_recv on k2: (Figure step 4-4)
There are now three unread packets in kcp.rcv_queue : [PSH sn=0 frg=2 len=1376] [PSH sn=1 frg=1 len=1376] and [PSH sn=2 frg=0 len=1344]
At this time, a packet with seg.frg value of 0 is read, and the total readable length is calculated to be 4096. Then all the data in the three packets will be read and written into the read buffer and success will be returned.
Need to pay attention to another situation : If the kcp.rcv_queue queue contains 2 user-sent packets with seg.frg value of 2/1/0/2/1/0 and is fragmented into 6 data packets, the corresponding It is also necessary to call ikcp_recv twice to read out all the complete data received.
Call ikcp_input: on k1 (Figure step 5-1)
Input acknowledgment packets [ACK sn=1 una=3] and [ACK sn=2 una=3] , and parse to seg.una =3. The package [PSH sn=1 frg=1 len=1376] [PSH sn=2 frg=0 len=1344] is confirmed and removed from the kcp.snd_buf queue through una.
All data sent has been acknowledged.
Window is used for flow control. It marks a logical range of the queue. Due to the processing of actual data, the position of the queue continues to move to the high position of the sequence number. Logically, this window will continue to move and expand and contract at the same time, so it is also called a sliding window .
This schematic diagram is another representation of steps 3-1 to 4-1 of the flow diagram in the "Basic Data Sending and Receiving Process" section. As operations outside the scope of steps, data directions are indicated by semi-transparent arrows.
All data is processed through the function pointed by the arrow and moved to a new location (twice the size of the image):
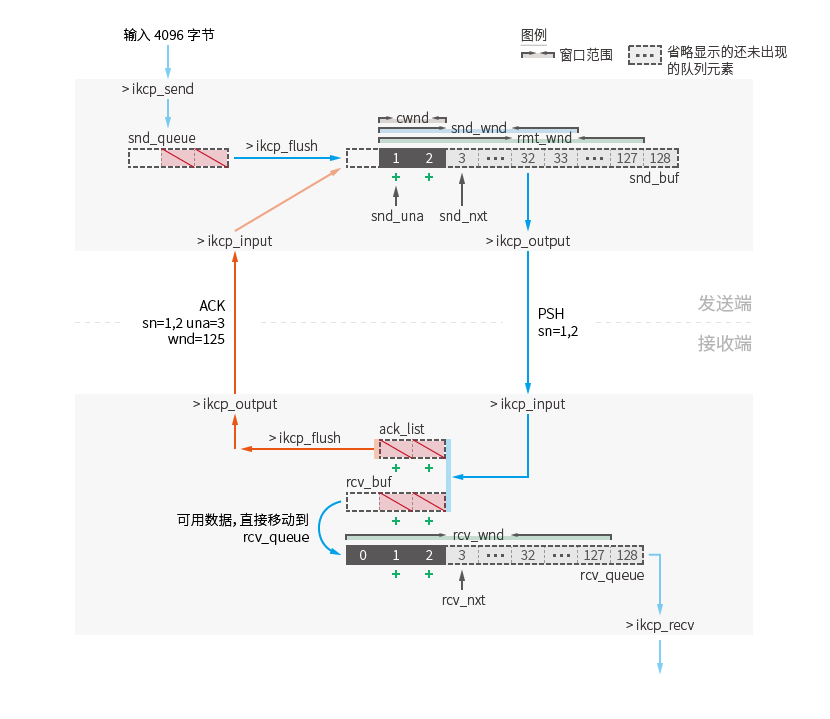
The data passed in by the ikcp_send function on the sending end will be directly stored in the kcp.snd_queue sending queue after data slicing processing.
every time ikcp_flush is called. The window size for this transmission will be calculated based on the sending window size kcp.snd_wnd , the remote window size kcp.rmt_wnd and the congestion window size kcp.cwnd The value is the minimum of the three: min( kcp.snd_wnd , kcp.rmt_wnd , kcp.cwd ) (ikcp.c:1017).
If the nc parameter is set to 1 through the ikcp_nodelay function and the flow control mode is turned off, the calculation of the congestion window value is ignored. The calculation result of the sending window is min( kcp.snd_wnd , kcp.rmt_wnd ) (ikcp.c:1018).
In the default configuration of only turning off the flow control mode, the number of data packets that can be sent for the first time is the default size value of kcp.snd_wnd 32. This is different from the basic sending and receiving process example, in which only one packet can be sent for the first time because flow control is enabled by default.
Newly sent data packets will be moved to the kcp.snd_buf queue.
For ikcp_send data, there is only a slice limit of 127 (i.e. 127*
kcp.mss=174752 bytes). There is no limit on the total number of packets in the send queue. See: How to avoid cache accumulation delays
kcp.snd_buf send buffer stores data that will be or has been sent.
Each time ikcp_flush is called, the sending window is calculated and the data packet is moved from kcp.snd_queue to the current queue. All data packets in the current queue will be processed in three situations:
1. First data sending (ikcp.c:1053)
The number of times a packet is sent will be recorded in seg.xmit . The processing of the first send is relatively simple, and some parameters seg.rto / seg.resendts for retransmission timeout will be initialized.
2. Data timeout (ikcp.c:1058)
When the internally recorded time kcp.current exceeds the timeout period seg.resendts of the packet itself, a timeout retransmission occurs.
3. Data crossing confirmation (ikcp.c:1072)
When the data end is spanned and the number of spans seg.fastack exceeds the span retransmission configuration kcp.fastresend , span retransmission occurs. ( kcp.fastresend defaults to 0, and when it is 0, it is calculated as UINT32_MAX, and span retransmission will never occur.) After a timeout retransmission, the current packet seg.fastack will be reset to 0.
The acknowledgment list is a simple record list that originally records sequence numbers and timestamps ( seg.sn / seg.ts ) in the order in which packets are received.
Therefore, in the schematic diagram of this article,
kcp.ack_listwill not have any blank element positions drawn. Because it is not a logically ordered queue (similarly, although the packet in thesnd_queuequeue has not yet been assigned a sequence number, its logical sequence number has been determined).
The receiving end buffers data packets that cannot be processed temporarily.
All data packets incoming from ikcp_input will arrive in this queue first, and the information will be recorded to kcp.ack_list in the original order of arrival.
There are only two situations where data will still remain in this queue:
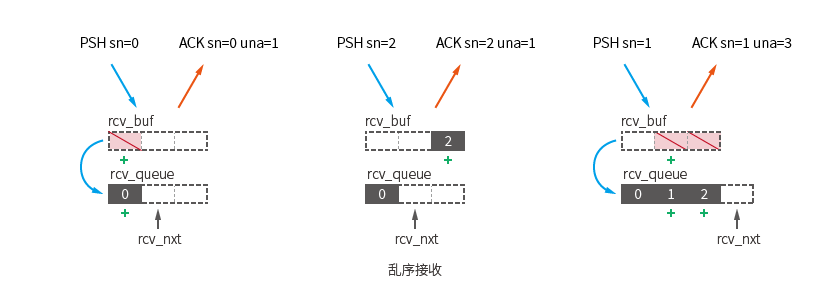
Here, the packet [PSH sn=0] is received first, which meets the conditions of available packets and moves to kcp.rev_queue .
Then the packet [PSH sn=2] was received, which was not the next packet expected to be received ( seg.sn == kcp.rcv_nxt ), causing this packet to stay in kcp.rcv_buf .
After receiving the packet [PSH sn=1] , move the two stuck packets [sn=1] [sn=2] to kcp.rcv_queue .
kcp.rcv_queue receive queue length reaches the receive window size kcp.rcv_wnd (ikcp_recv was not called in time).The receiving end stores data that can be read by the upper layer.
In streaming mode all available packets are read, in non-streaming mode fragmented data segments are read and assembled into the complete raw data.
After the read is completed, an attempt will be made to move data from kcp.rcv_buf to this queue (possibly to recover from a full receive window state).
The sending window kcp.snd_wnd value is a configured value, and the default is 32.
The remote window kcp.rmt_wnd is a value that will be updated when the sender receives a packet from the receiver (not just an acknowledgment packet). It records the available length (ikcp.c:1086) of the receiving end's receiving queue kcp.rcv_queue when the current data packet is sent by the receiving end. The initial value is 128.
The congestion window is a calculated value that grows algorithmically each time data is received via ikcp_input.
If packet loss and fast retransmission are detected when flushing data ikcp_flush, it will be recalculated according to the algorithm.
The position where
kcp.cwndis initialized to 1 is in the first ikcp_update call to ikcp_flush.
The receiving window kcp.rcv_wnd value is a configured value, and the default is 128. It limits the maximum length of the receive queue kcp.rcv_queue .
In this section, an improved version of kcp_optional.c based on the sample code in the "Basic Data Sending and Receiving" section is provided. You can further observe the protocol behavior by modifying the macro definition.
The sample code ends the process by specifying to write a specified number of fixed-length data to k1 and read it completely in k2.
Macros are provided to control specified functions:
The congestion window is recorded through the values of kcp.cwnd and kcp.incr . Since the unit recorded by kcp.cwnd is packet, additional kcp.incr is required to record the congestion window expressed in byte length units.
Like TCP, KCP congestion control is also divided into two stages: slow start and congestion avoidance:
The congestion window grows ; in the process of confirming the data packet, every time kcp.snd_buf queue header data is confirmed (effective UNA confirmation, kcp.snd_una changes). And when the congestion window is smaller than the recorded remote window kcp.rmt_wnd , the congestion window is increased. (ikcp:875)
1. If the congestion window is smaller than the slow start threshold kcp.ssthresh , it is in the slow start stage , and the congestion window growth is relatively aggressive at this time. The congestion window grows by one unit.
2. If the congestion window is greater than or equal to the slow start threshold, it is in the congestion avoidance stage , and the congestion window growth is relatively conservative. If kcp.incr increases mss/16 each time, 16 valid UNA confirmations are required before a unit congestion window is increased. The actual congestion avoidance phase window growth is:
(mss * mss) / incr + (mss / 16)
Since incr=cwnd*mss is:
((mss * mss) / (cwnd * mss)) + (mss / 16)
Equivalent to:
(mss / cwnd) + (mss / 16)
The congestion window grows incrementally for every cwnd and every 16 valid UNA acknowledgments.
Congestion window reduction : When the ikcp_flush function detects packet loss across retransmissions or timeouts, the congestion window is reduced.
1. When span retransmission occurs, the slow start threshold kcp.ssthresh is set to half of the unacknowledged sequence number span. The congestion window size is the slow start threshold plus the fast retransmission configuration value kcp.resend (ikcp:1117):
ssthresh = (snd_nxt - snd_una) / 2
cwnd = ssthresh + resend
2. When a packet loss timeout is detected, the slow start threshold is set to half of the current congestion window. Congestion window set to 1 (ikcp:1126):
ssthresh = cwnd / 2
cwnd = 1
Observe slow start 1 : Run the sample code with the default configuration and you will observe that the slow start process is quickly skipped. This is because the default slow start threshold is 2:
t=0 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
# 收到一个确认包且拥塞窗口小于慢启动阈值,incr 增加一个 mss
t=100 n=1 una=1 nxt=2 cwnd=2|2 ssthresh=2 incr=2752
# 开始拥塞避免
t=200 n=1 una=2 nxt=3 cwnd=2|2 ssthresh=2 incr=3526
t=300 n=1 una=3 nxt=4 cwnd=4|4 ssthresh=2 incr=4148
t=400 n=1 una=4 nxt=5 cwnd=4|4 ssthresh=2 incr=4690
...
t in the output content is the logical time, n is the number of times k1 sends data in the cycle, the value of cwnd=1|1 indicates that the 1 in front of the vertical bar symbol is the window calculated when ikcp_flush, that is, min(kcp. in flow control mode. snd_wnd, kcp.rmt_wnd, kcp.cwnd), the value of the following 1 is kcp.cwnd .
Observe the growth of the congestion window under the default configuration graphically: when in the congestion avoidance phase, the larger the congestion window, the smoother the growth of the congestion window.
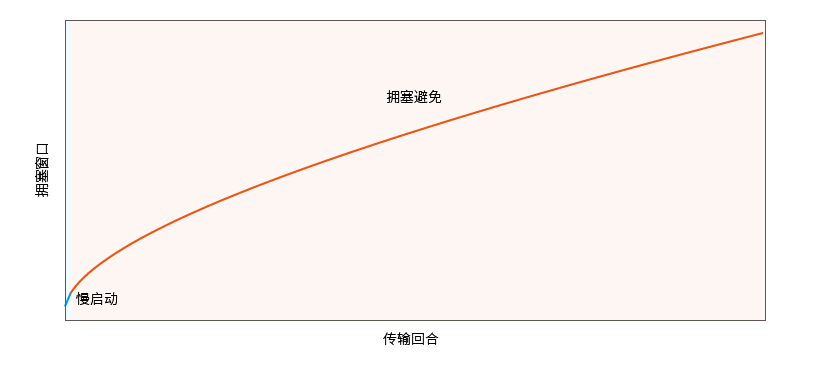
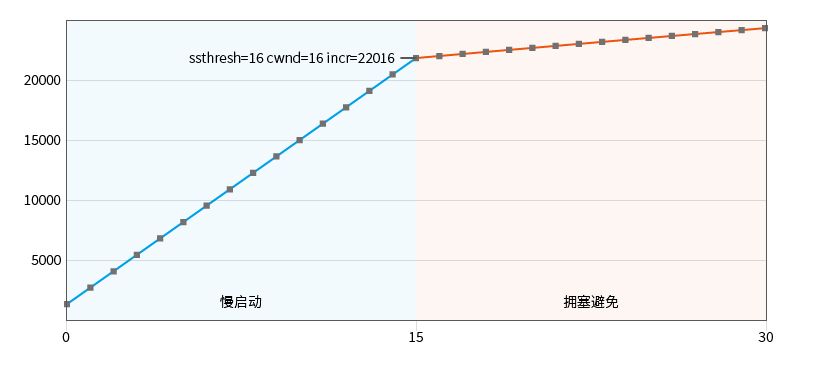
Observe slow start 2 : Adjust the sample configuration slow start threshold initial value KCP_THRESH_INIT to 16:
#define KCP_THRESH_INIT 16
t=0 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=16 incr=1376
t=100 n=1 una=1 nxt=2 cwnd=2|2 ssthresh=16 incr=2752
t=200 n=1 una=2 nxt=3 cwnd=3|3 ssthresh=16 incr=4128
t=300 n=1 una=3 nxt=4 cwnd=4|4 ssthresh=16 incr=5504
...
t=1300 n=1 una=13 nxt=14 cwnd=14|14 ssthresh=16 incr=19264
t=1400 n=1 una=14 nxt=15 cwnd=15|15 ssthresh=16 incr=20640
t=1500 n=1 una=15 nxt=16 cwnd=16|16 ssthresh=16 incr=22016
# 开始拥塞避免
t=1600 n=1 una=16 nxt=17 cwnd=16|16 ssthresh=16 incr=22188
t=1700 n=1 una=17 nxt=18 cwnd=16|16 ssthresh=16 incr=22359
...
By only intercepting a short period before the transmission round, it can be observed that the slow start also increases in a linear manner by default.
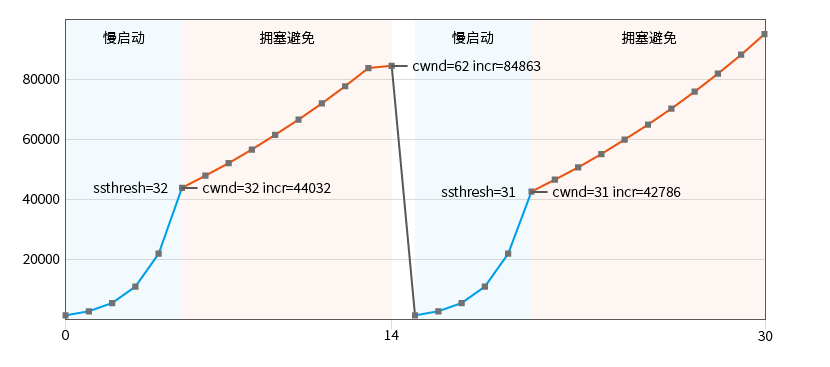
Observe turning off delayed acknowledgment : send as much data as possible, and turn off the delayed sending option ACK_DELAY_FLUSH , and simulate a packet loss:
#define KCP_WND 256, 256
#define KCP_THRESH_INIT 32
#define SEND_DATA_SIZE (KCP_MSS*64)
#define SEND_STEP 16
#define K1_DROP_SN 384
//#define ACK_DELAY_FLUSH
t=0 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=32 incr=1376
t=100 n=2 una=1 nxt=3 cwnd=2|2 ssthresh=32 incr=2752
t=200 n=4 una=3 nxt=7 cwnd=4|4 ssthresh=32 incr=5504
t=300 n=8 una=7 nxt=15 cwnd=8|8 ssthresh=32 incr=11008
t=400 n=16 una=15 nxt=31 cwnd=16|16 ssthresh=32 incr=22016
...
t=1100 n=52 una=269 nxt=321 cwnd=52|52 ssthresh=32 incr=72252
t=1200 n=56 una=321 nxt=377 cwnd=56|56 ssthresh=32 incr=78010
t=1300 n=62 una=377 nxt=439 cwnd=62|62 ssthresh=32 incr=84107
t=1400 n=7 una=384 nxt=446 cwnd=62|62 ssthresh=32 incr=84863
t=1500 n=1 una=384 nxt=446 cwnd=1|1 ssthresh=31 incr=1376
t=1600 n=2 una=446 nxt=448 cwnd=2|2 ssthresh=31 incr=2752
t=1700 n=4 una=448 nxt=452 cwnd=4|4 ssthresh=31 incr=5504
t=1800 n=8 una=452 nxt=460 cwnd=8|8 ssthresh=31 incr=11008
t=1900 n=16 una=460 nxt=476 cwnd=16|16 ssthresh=31 incr=22016
...
In this case, a classic graph of slow start and congestion avoidance is obtained. Packet loss was detected at the 15th transmission round (t=1500):
Turning off the delayed sending option means that the receiving data party will call ikcp_flush immediately after each execution of ikcp_input to send back a confirmation packet.
The slow start process at this time increases exponentially every RTT (Round-Trip Time, round trip time), because each acknowledgment packet will be sent independently, causing the sender's congestion window to grow, and because the congestion window grows, the number of packets sent within each RTT will increase. Pack doubled.
If confirmation is delayed, a confirmation package will be sent together. The process of increasing the congestion window will only be executed once each time the ikcp_input function is called, so merging multiple acknowledgment packets received will not have the effect of increasing the congestion window multiple times.
If the clock cycle interval is greater than RTT, it will increase exponentially every interval. The schematic diagram shows a possible situation:
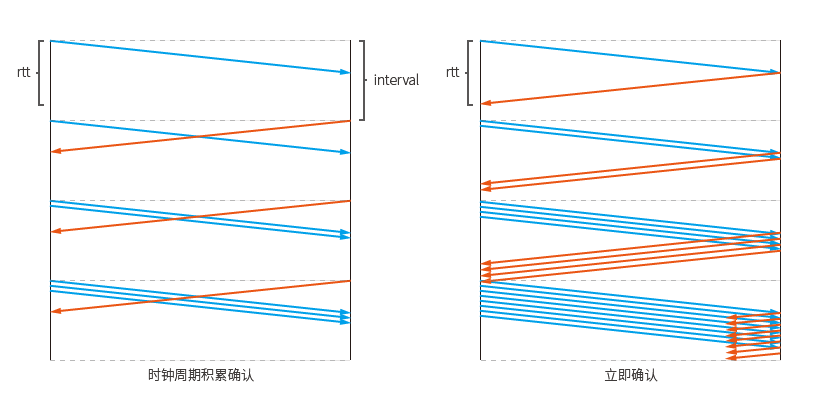
The premise of exponential growth is that the data sent next time can satisfy twice the number of data packets last time. If the data written to the sending end is insufficient, exponential growth will not be achieved.
It should be noted that even if the sample code sends an immediate confirmation, it only affects the way the receiving end sends a confirmation. The sender also needs to wait for the next cycle before processing these confirmation packets. Therefore, the time t here is for reference only. Unless the received packet is not processed and stored immediately in the actual network transceiver code, it must wait until the update cycle before responding.
Based on the characteristics of KCP, there must be a more direct way to make the congestion window larger, and directly turn off flow control to obtain more aggressive sending:
#define KCP_NODELAY 0, 100, 0, 1
#define SEND_DATA_SIZE (KCP_MSS*127)
#define SEND_STEP 1
t=0 n=32 una=0 nxt=32 cwnd=32|1 ssthresh=2 incr=1376
t=100 n=32 una=32 nxt=64 cwnd=32|2 ssthresh=2 incr=2752
t=200 n=32 una=64 nxt=96 cwnd=32|2 ssthresh=2 incr=3526
t=300 n=31 una=96 nxt=127 cwnd=32|4 ssthresh=2 incr=4148
You can also directly modify the congestion window value as needed.
Observe that the remote window is full : If the length of the sent data is close to the default remote window size and the receiving end does not read it out in time, you will find a period in which no data can be sent (note that in the sample code, the receiving end first sends the confirmation packet and then Read the content again):
#define KCP_NODELAY 0, 100, 0, 1
#define SEND_DATA_SIZE (KCP_MSS*127)
#define SEND_STEP 2
t=0 n=32 una=0 nxt=32 cwnd=32|1 ssthresh=2 incr=1376
t=100 n=32 una=32 nxt=64 cwnd=32|2 ssthresh=2 incr=2752
t=200 n=32 una=64 nxt=96 cwnd=32|2 ssthresh=2 incr=3526
t=300 n=32 una=96 nxt=128 cwnd=32|4 ssthresh=2 incr=4148
t=400 n=0 una=128 nxt=128 cwnd=0|4 ssthresh=2 incr=4148
t=500 n=32 una=128 nxt=160 cwnd=32|4 ssthresh=2 incr=4148
t=600 n=32 una=160 nxt=192 cwnd=32|4 ssthresh=2 incr=4690
t=700 n=32 una=192 nxt=224 cwnd=32|4 ssthresh=2 incr=5179
t=800 n=30 una=224 nxt=254 cwnd=31|4 ssthresh=2 incr=5630
When the remote window size kcp.rmt_wnd recorded in the receiver is 0, the probe wait phase (probe wait, ikcp.c:973) will be started in ikcp_flush. kcp.ts_probe will record a time initially 7000 milliseconds (recorded in kcp->probe_wait ).
When the time arrives, additionally encode a packet of type IKCP_CMD_WASK and send it to the receiving end (ikcp.c:994) to request the remote end to send back a packet of type IKCP_CMD_WINS to update kcp.rmt_wnd
If the remote window size is always 0, kcp->probe_wait increases by half of the current value each time, and then updates the waiting time. The maximum waiting time is 120000 milliseconds (120 seconds).
When the remote window size is not 0, the above detection status is cleared.
In this example, we do not wait for the initial 7 seconds before restoring the recorded remote window size. Because in the operation of ikcp_recv on the receiving end to read data, when the length of kcp.rcv_queue queue is greater than or equal to the receiving window kcp.rcv_wnd before reading the data (the reading window is full), a flag bit (ikcp .c:431) and send a packet of type IKCP_CMD_WINS (ikcp.c:1005) the next time ikcp_flush To notify the sending end to update the latest remote window size.
To avoid this problem, the data needs to be read out at the receiving end in a timely manner. However, even if the remote window becomes smaller, the sending window of the sender will become smaller, resulting in additional delays. At the same time, it is also necessary to increase the receiving window of the receiving end.
Try to modify the RECV_TIME value to a relatively large value (for example, 300 seconds), and then observe the sending of the IKCP_CMD_WASK packet.
As described in the kcp.snd_buf queue description, when calling ikcp_flush, all packets in the queue will be traversed, if the packet is not sent for the first time. Then it will check whether the packet has been crossed acknowledgment the specified number of times, or whether the timeout period has been reached.
Fields related to round trip time and timeout calculation are:
kcp.rx_rttval : smooth network jitter timekcp.rx_srtt : Smooth round trip timekcp.rx_rto (Receive Retransmission Timeout): retransmission timeout, initial value 200kcp.rx_minrto : Minimum retransmission timeout, initial value 100kcp.xmit : global retransmission countseg.resendts : retransmission timestampseg.rto : retransmission timeoutseg.xmit : retransmission countBefore discussing how the package calculates timeouts, let's first look at how the related fields of round-trip time and timeout are calculated:
Round trip time record : Each time an ACK confirmation packet is processed, the confirmation packet will carry the sequence number and the time when the sequence number was sent at the sender ( seg.sn / seg.ts ). When legal, the round trip time update process is executed.
The value of rtt is the round-trip time of a single packet, that is, rtt= kcp.current - seg.ts
If the smoothed round trip time kcp.rx_srtt is 0, it means that initialization is performed: kcp.rx_srtt is directly recorded as rtt, kcp.rx_rttval is recorded as half of rtt.
In the non-initialization process, a delta value is calculated, which represents the fluctuation value of this rtt and the recorded kcp.rx_srtt (ikcp.c:550):
delta = abs(rtt - rx_srtt)
The new kcp.rx_rttval is updated by the weighted value of the old kcp.rx_rttval and delta:
rx_rttval = (3 * rx_rttval + delta) / 4
The new kcp.rx_srtt is updated by the weighted value of the old kcp.rx_srtt and rtt, and cannot be less than 1:
rx_srtt = (7 * rx_srtt + rtt) / 8
rx_srtt = max(1, rx_srtt)
The new rx_rto is updated by the minimum value of the smoothed round-trip time kcp.rx_srtt plus the clock cycle kcp.interval and 4 times rx_rttval , and the range is limited to [ kcp.rx_minrto , 60000]:
rto = rx_srtt + max(interval, 4 * rttval)
rx_rto = min(max(`kcp.rx_minrto`, rto), 60000)
Ideally, when the network has only fixed delay and no jitter, the value of kcp.rx_rttval will approach 0, and the value of kcp.rx_rto is determined by the smooth round-trip time and clock cycle.
Smooth round trip time calculation diagram:
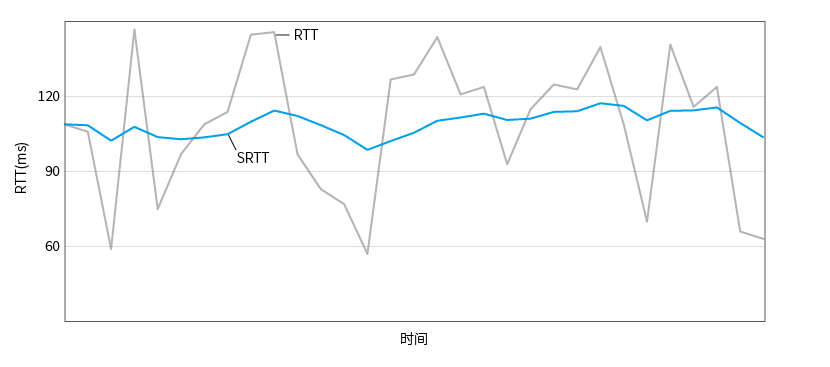
First contract delivery time (ikcp.c:1052):
seg.rto will record the kcp.rx_rto status, and the first timeout time of the data packet is seg.rto + rtomin milliseconds.
rtomin is calculated by kcp.rx_rto , if nodelay mode is enabled. rtomin is 0, otherwise kcp.rx_rto /8.
Timeout for nodelay not enabled:
resendts = current + rx_rto + rx_rto / 8
Enable nodelay timeout:
resendts = current + rx_rto
Timeout retransmission (ikcp.c:1058):
When the internal time reaches the timeout time seg.resendts of the data packet, the packet with this sequence number is retransmitted.
When nodelay mode is not enabled, the increment of seg.rto is max( seg.rto , kcp.rx_rto ) (double growth):
rto += max(rto, rx_rto)
When nodelay is enabled and nodelay is 1, increase seg.rto by half each time (1.5 times increase):
rto += rto / 2
When nodelay is enabled and nodelay is 2, kcp.rx_rto is increased by half each time (1.5 times increase):
rto += rx_rto / 2
The new timeout is after seg.rto milliseconds:
resendts = current + rx_rto
Retransmission across time (ikcp.c:1072):
When a data packet is crossed a specified number of times, a crossing retransmission is triggered. The crossing count is only accumulated once in ikcp_input (ikcp:872), and the merged acknowledgment packets will not be superimposed.
seg.rto is not updated when retransmitting across time, and the next timeout retransmission time is directly recalculated:
resendts = current + rto
Observe default timeout
Only send one packet, drop it four times, and observe the timeout and retransmission time.
For the default configuration, the initial value of kcp.rx_rto is 200 milliseconds, and the first timeout time is 225 milliseconds. Due to clock accuracy issues, timeout retransmission is performed at 300 milliseconds. After that, the timeout retransmission time is doubled each time.
#define SEND_STEP 1
#define K1_DROP_SN 0,0,0,0
t=0 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
...
t=300 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
...
t=700 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
...
t=1500 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
...
t=3100 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
Observe a 1.5x increase in RTO based on the package itself
#define KCP_NODELAY 1, 100, 0, 0
#define SEND_STEP 1
#define K1_DROP_SN 0,0,0,0
t=0 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
...
t=200 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
...
t=500 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
...
t=1000 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
...
t=1700 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
Watch 1.5x growth based on RTO
#define KCP_NODELAY 2, 100, 0, 0
#define SEND_STEP 1
#define K1_DROP_SN 0,0,0,0
t=0 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
...
t=200 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
...
t=500 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
...
t=900 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
...
t=1400 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
Observe span retransmissions
The acknowledgment packets processed by merging will not trigger span retransmission. The acknowledgments of packet [sn=0] and packet [sn=1] [sn=2] are discarded here and are merged, resulting in only one span. In the end, it was retransmitted through timeout.
#define KCP_NODELAY 0, 100, 2, 1
#define SEND_DATA_SIZE (KCP_MSS*3)
#define SEND_STEP 1
#define K1_DROP_SN 0
t=0 n=3 una=0 nxt=3 cwnd=32|1 ssthresh=2 incr=1376
t=100 n=0 una=0 nxt=3 cwnd=32|1 ssthresh=2 incr=1376
t=200 n=0 una=0 nxt=3 cwnd=32|1 ssthresh=2 incr=1376
t=300 n=1 una=0 nxt=3 cwnd=32|1 ssthresh=16 incr=1376
When sending data packets in two steps, the second group of packets will be crossed twice when performing ikcp_input confirmation, and [sn=0] will be accumulated and retransmitted during the next ikcp_flush.
#define KCP_NODELAY 0, 100, 2, 1
#define SEND_DATA_SIZE (KCP_MSS*2)
#define SEND_STEP 2
#define K1_DROP_SN 0
t=0 n=2 una=0 nxt=2 cwnd=32|1 ssthresh=2 incr=1376
t=100 n=2 una=0 nxt=4 cwnd=32|1 ssthresh=2 incr=1376
t=200 n=1 una=0 nxt=4 cwnd=32|4 ssthresh=2 incr=5504
t=300 n=0 una=4 nxt=4 cwnd=32|4 ssthresh=2 incr=5934
The article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivs 4.0 International License.
The code in the project is open source using the MIT license.
About the image font: Noto Sans SC


